ST4VLA: Spatially Guided Training for Vision-Language-Action Models
Abstract: Large vision-LLMs (VLMs) excel at multimodal understanding but fall short when extended to embodied tasks, where instructions must be transformed into low-level motor actions. We introduce ST4VLA, a dual-system Vision-Language-Action framework that leverages Spatial Guided Training to align action learning with spatial priors in VLMs. ST4VLA includes two stages: (i) spatial grounding pre-training, which equips the VLM with transferable priors via scalable point, box, and trajectory prediction from both web-scale and robot-specific data, and (ii) spatially guided action post-training, which encourages the model to produce richer spatial priors to guide action generation via spatial prompting. This design preserves spatial grounding during policy learning and promotes consistent optimization across spatial and action objectives. Empirically, ST4VLA achieves substantial improvements over vanilla VLA, with performance increasing from 66.1 -> 84.6 on Google Robot and from 54.7 -> 73.2 on WidowX Robot, establishing new state-of-the-art results on SimplerEnv. It also demonstrates stronger generalization to unseen objects and paraphrased instructions, as well as robustness to long-horizon perturbations in real-world settings. These results highlight scalable spatially guided training as a promising direction for robust, generalizable robot learning. Source code, data and models are released at https://internrobotics.github.io/internvla-m1.github.io/

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to better understand where things are and how to move to them when following human instructions. The authors introduce ST4VLA, a robot-learning method that connects what a model “sees” and “reads” (vision and language) with what it must physically “do” (actions). The big idea: first teach the model strong spatial skills (like pointing to objects, drawing boxes around them, and sketching motion paths), then use those skills to guide the robot’s movements.
What questions were the researchers trying to answer?
- Why do many robot models that understand pictures and text still struggle to act well in the real world?
- Can we train robots so they don’t “forget” where things are when learning how to move?
- If we make the model think more about space (who, what, where) before moving, will it do better on new tasks, new objects, or longer, multi-step jobs?
How did they do it?
The team designed ST4VLA as a “two-part brain,” a bit like a careful planner plus a quick driver:
- The Planner (System 2): Thinks carefully. It looks at images and instructions, figures out where key things are (like the apple and the box), and plans the route.
- The Action Expert (System 1): Acts quickly. It turns the plan into robot arm motions (like moving, grasping, and placing).
They trained this system in two stages:
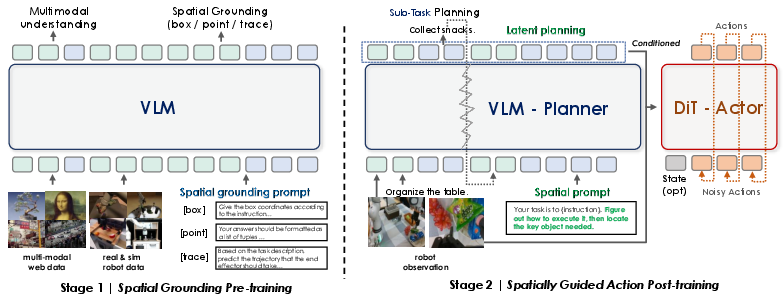
Stage 1: Spatial grounding pre-training
Think of this as giving the robot a good “sense of space” before it starts moving. The model learns to:
- Point to important spots (like the top of a can),
- Draw boxes around objects,
- Predict simple motion paths (trajectories).
It practices on a mix of internet images with captions and robot-specific data. This builds “spatial priors,” which you can think of as common-sense knowledge about where objects are and how they relate to each other.
Stage 2: Spatially guided action post-training
Now the robot learns to move—without losing its sense of space. The trick is “spatial prompting.” For example, after the instruction “put the apple in the drawer,” the prompt adds “figure out the key object and its location,” nudging the Planner to produce strong spatial clues that guide the Action Expert’s movements.
Two extra ideas help keep the learning stable:
- A tiny “querying” module connects the Planner to the Action Expert, turning the Planner’s thoughts into a compact, steady signal for the controller.
- The team softly limits how much the Action Expert’s learning can change the Planner (so the Planner doesn’t “forget” what it learned about space).
In everyday terms: first teach the robot to find things on a map; then, when it learns to drive, keep checking the map so it doesn’t get lost.
What did they find?
ST4VLA made robots much better at following instructions across different settings—simulations and real robots—and more robust to changes (like new objects, new phrasing, or different lighting/camera angles).
Here are some standout results (higher is better; “success rate” means how often the robot completes the task):
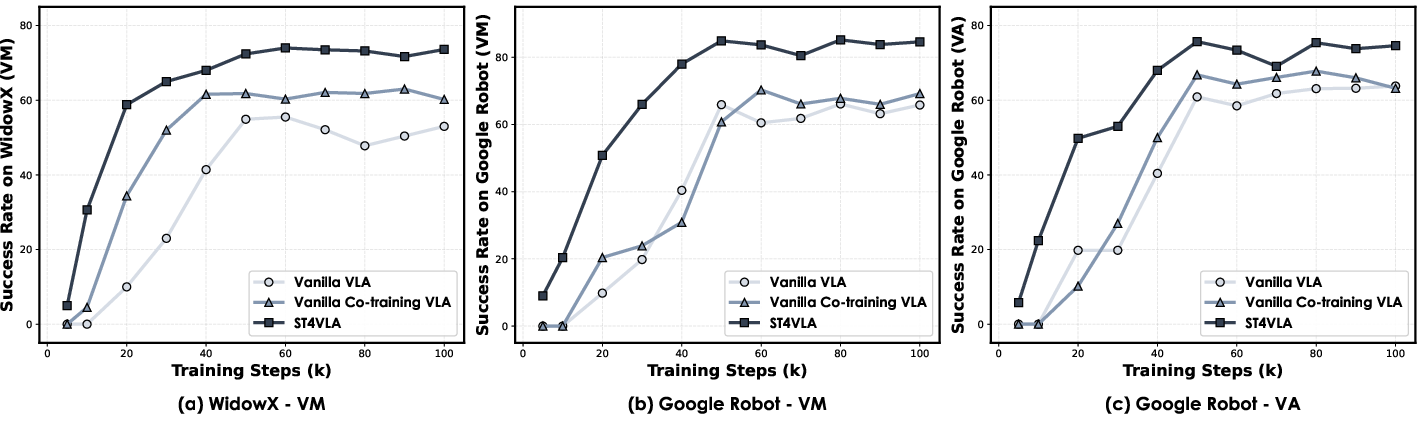
- On Google Robot tasks:
- Visual Matching average success improved from about 66% to about 85%.
- Variant Aggregation improved from about 64% to about 76%.
- On WidowX robot tasks:
- Average success improved from about 55% to about 73%.
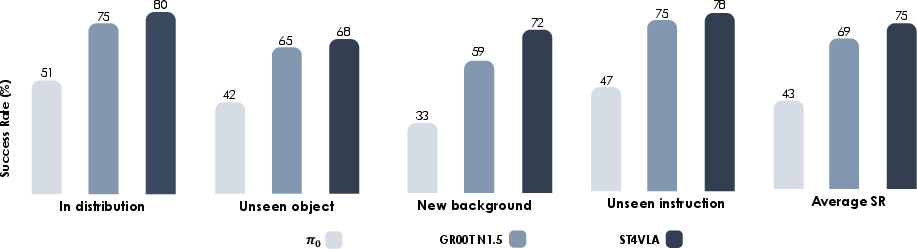
- In large-scale simulated pick-and-place (200 tasks), ST4VLA outperformed strong recent systems on all test types (same tasks, new objects, new backgrounds, new wording).
- In real-world pick-and-place with a Franka robot, ST4VLA achieved higher success across tough tests like:
- Unseen objects and backgrounds,
- New object positions and orientations,
- Paraphrased instructions (same goal, different words).
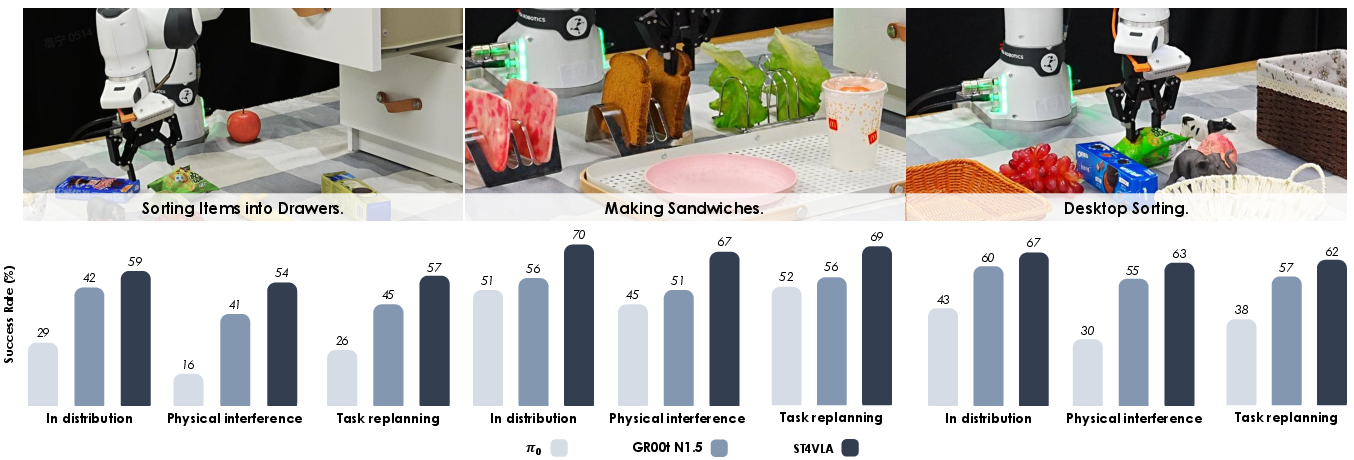
- In long-horizon tasks (like sorting a desk or making a sandwich), the Planner-then-Act design helped the robot split big goals into reliable steps, handle surprises, and replan when needed.
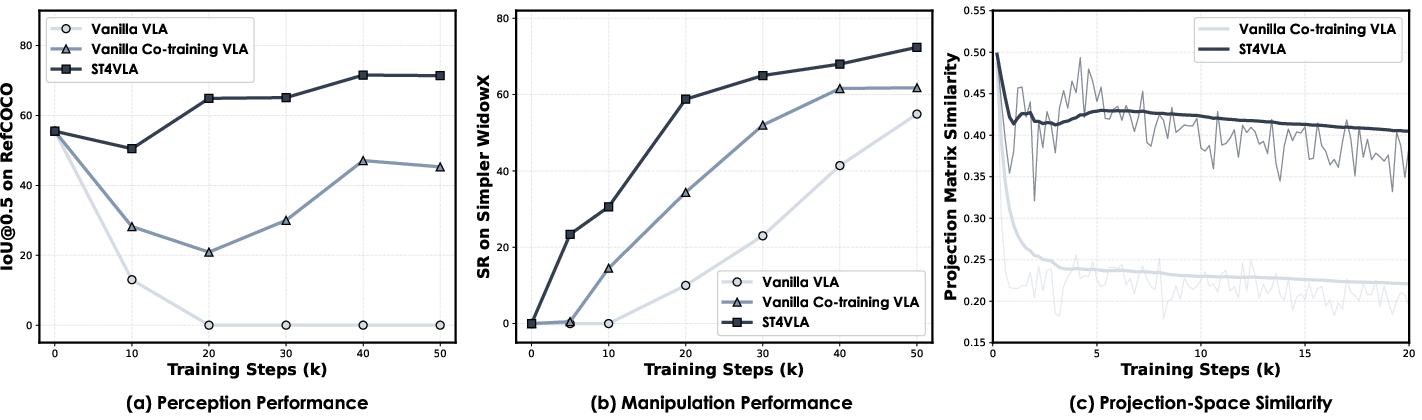
They also checked how the two goals—“see and locate” vs. “move and act”—interact during training. A simple measure of gradient alignment (think: are the two learning goals pushing in the same direction?) showed that spatial prompting makes these goals work together better, which matches the improved results.
Why is this important?
Robots often learn to move but lose track of where things are, or they rely on hand-designed rules that don’t scale to messy real life. ST4VLA shows a practical path to fix both problems:
- It preserves strong “where is what?” skills while learning “how to move,” so the robot stays grounded in the real world.
- It generalizes better—handling new objects, new instructions, and longer tasks—because it builds on reusable spatial common sense.
- It reduces the need for fragile, hand-coded steps by letting the model learn spatial reasoning and action together in a clean, data-driven way.
Key terms, simply explained
- Vision-LLM (VLM): A model that can look at images and read text, then understand both together.
- Vision-Language-Action (VLA): A model that not only understands images and text but also outputs actions for a robot.
- Spatial priors: The model’s “common sense” about where objects are and how they relate (e.g., the cup is on the table; the drawer is under the desk).
- Spatial grounding: Connecting words (like “apple”) to the exact place in the image where that thing is.
- Spatial prompting: Adding short hints to the instruction to make the model think carefully about “where” before it acts.
- Planner vs. Action Expert: The Planner thinks and locates; the Action Expert executes quick, precise movements.
Bottom line
ST4VLA teaches robots to first think about space—who, what, and where—and then move with confidence. This two-stage, two-part approach makes robots more reliable, more adaptable, and better at real-world tasks, bringing us closer to general-purpose robots that can follow everyday instructions in messy, changing environments.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions The following points identify concrete gaps and open questions that remain unresolved and could guide future research: - Scope across embodiments: The method is only validated on manipulation arms (Google Robot, WidowX, Franka). It is unknown whether spatially guided training transfers to mobile navigation, locomotion, bimanual manipulation, tool use, or contact-rich/deformable tasks. - Reliance on hand-crafted spatial prompts: Spatial prompting uses manually written phrases (e.g., “locate the key object”), but there is no sensitivity analysis to prompt wording, length, or language. How robust is performance to imperfect or adversarial prompts, multilingual prompts, or automated prompt generation? - Limited gradient-alignment analysis (PSS): Projection-Space Similarity is computed on a single attention layer of the LLM. It is unclear whether PSS generalizes across layers, scales with model size, or causally predicts downstream success. Can PSS be optimized directly (e.g., via regularization) and does that consistently improve control? - Gradient decay factor hyperparameter: The decay factor (e.g., 0.5) that attenuates gradient flow from the Action Expert to the VLM is not justified or ablated. What is the optimal schedule or adaptive scheme for gradient attenuation across tasks and training stages? - Querying transformer design choices: The number of cross-attention layers, which VLM layers to attend, query token count, and architectural size (8.7 MB) are fixed without ablation. How do these choices affect stability, latency, and generalization? - Action representation and control-loop details: The DiT-based Action Expert uses chunked actions, but control frequency, latency, closed-loop update rate, and safety constraints are not reported. How do real-time performance and edge compute limitations impact task success and safety? - 2D-to-3D grounding fidelity: Spatial priors (points, boxes, trajectories) are evaluated primarily in 2D metrics (e.g., RefCOCO-g IoU, point-Acc) and with A0 L2 trajectory distance. There is no analysis of 3D coordinate-frame alignment errors, camera-to-robot calibration robustness, or end-effector pose accuracy under varied extrinsics. - Robustness stress testing: Evaluations focus on visual appearance shifts and cluttered pick-and-place. Robustness to occlusions, dynamic/moving objects, severe miscalibration, sensor noise, lighting extremes, and adversarial distractors remains unquantified. - Long-horizon task decomposition: The planner-controller division is asserted (System 2 → System 1), but the mechanism for learning subtask boundaries, error recovery, and re-planning criteria is not specified. Is decomposition learned end-to-end, rule-based, or supervised, and how does it generalize to unseen multi-step workflows? - Data composition and potential leakage: Web-scale grounding data and robot-specific datasets are mixed, yet overlap, bias, and leakage (e.g., identical or near-duplicate scenes/objects across pretraining and evaluation) are not audited. What are the scaling laws and per-source contributions to final performance? - Fairness of baseline comparisons: Some baselines use different co-training steps, data sizes, or reimplementations (marked with “*”). A controlled study with matched data budgets, compute, and training schedules is needed to validate claimed gains. - Sample efficiency and RL integration: Training relies on large offline teleoperation/simulation datasets (e.g., 244K demos). It remains unclear whether spatial priors improve sample efficiency in low-data regimes, or how they interact with on-policy RL or self-play fine-tuning. - Perception–control trade-offs: While spatial grounding is preserved, the potential trade-off with peak manipulation performance is not quantified. Can stronger preservation (e.g., freezing more layers) hurt control optimality? What layer-freeze schedules balance perception retention and control quality? - Interpretability of latent planning tokens: The planner’s latent tokens are not decoded or visualized. Can these tokens be mapped to explicit spatial plans or verified (e.g., boxes/points/poses) to enable debugging, safety checks, or human-in-the-loop correction? - Generalization breadth of language understanding: Beyond paraphrases, compositional instructions (quantifiers, counts), relational constraints (e.g., “closest red mug”), temporal directives (“after opening, place…”) and multilingual commands are not systematically evaluated. - Safety, compliance, and force control: There is no discussion of force sensing, compliant control, collision avoidance policies, or formal safety guarantees during long-horizon tasks. How does the framework integrate tactile feedback or safety-critical constraints? - Multi-camera and persistent 3D scene memory: Inputs include wrist and third-person views, but persistent scene representations (e.g., 3D maps/graphs) for long-horizon grounding are not explored. Can spatial priors be extended to maintain scene memory and improve planning across extended interactions? - Ablations on model scale and backbone choice: The approach is instantiated with Qwen2.5-VL-3B and DINOv2. Whether larger/smaller backbones, different VLMs/vision encoders, or lightweight adapters (e.g., LoRA) change the effectiveness of spatial guidance is not studied. - Deployment constraints: Inference hardware, runtime, energy consumption, and scalability to on-robot compute are not reported. What is the minimal compute budget for real-time deployment while maintaining performance? - Failure taxonomy and diagnostics: The paper reports success rates, but does not categorize failure modes (e.g., mis-grounding vs. grasp failure vs. trajectory collision). A structured error analysis could inform targeted improvements in spatial grounding or action generation.
Practical Applications
Below is an overview of practical applications that can be derived from the paper’s findings, methods, and innovations. The items are grouped by time horizon and framed with sector relevance, concrete use cases, plausible tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Generalist pick-and-place and sorting in structured environments (Sector: Robotics/Manufacturing/Logistics)
- Use cases: Kitting, bin-picking, SKU sorting, order consolidation, returns processing in warehouses and factories where layouts are semi-structured.
- Tools/workflows: ST4VLA pretrained checkpoints; a ROS 2 node that wraps the VLM Planner + DiT Action Expert; spatial prompting templates for task instructions; wrist + third-person camera setup; Isaac Sim pipelines to generate task-specific demos for quick post-training.
- Assumptions/dependencies: Static or semi-structured workcells; calibrated cameras; compatible end-effectors; GPU for inference (Qwen2.5-VL-3B + DiT Actor); limited diversity of objects at deployment compared to open-world scenarios.
- Rapid reconfiguration for new SKUs/products with minimal data (Sector: E-commerce/Manufacturing)
- Use cases: Onboarding new items for picking/placing or packaging without full reprogramming; robust to paraphrased instructions and object variants.
- Tools/workflows: Few-shot data collection (teleop or sim-to-real) + Stage 2 spatially guided post-training; prompt libraries (“identify target, localize container, plan placement”); PSS-based training diagnostics to monitor gradient conflicts.
- Assumptions/dependencies: Access to a small number of demonstrations; sim assets for look-alikes; object categories that are visually similar to pretraining distribution.
- Robust long-horizon task execution in facilities (Sector: Facilities/Enterprise Robotics)
- Use cases: Multi-step desk sorting, drawer organization, simple food prep in back-of-house (e.g., sandwich assembly), tool tidying in labs—where tasks can be segmented into atomic steps.
- Tools/workflows: Dual-system deployment (System 2 planner for latent plan tokens, System 1 controller for execution); subtask libraries; progress monitors to check step completion; fallback teleop.
- Assumptions/dependencies: Safe, controlled environments; reliable grasping hardware; pre-collected or simulated subtask demos for the local context; safety interlocks for human proximity.
- Spatially guided training as a plug-in to existing VLA stacks (Sector: Software/Robotics R&D)
- Use cases: Improve existing VLA policies by preserving spatial grounding during action finetuning; reduce overfitting to motor patterns.
- Tools/workflows: Querying transformer module (lightweight cross-attention bridge); gradient-decay factor on VLM backprop; Stage 1 spatial grounding pretraining loader that normalizes robot datasets into QA format; integration code with OpenVLA/π0-like pipelines.
- Assumptions/dependencies: Access to pretraining corpora (RefCOCO, RoboRefIt, Where2Place, A0, etc.); GPU training budget; permission to modify training recipes.
- Training diagnostics and evaluation protocols using Projection-Space Similarity (PSS) (Sector: Academia/ML Ops/Tools)
- Use cases: Quantify and reduce gradient conflicts between spatial grounding and action policy objectives; choose co-training schedules and hyperparameters systematically.
- Tools/workflows: PSS metric implementation; layer-wise probing scripts; dashboards for tracking PSS vs. task success; early-stopping and curriculum decisions guided by PSS.
- Assumptions/dependencies: Access to both spatial grounding and action mini-batches during training; willingness to compute gradient probes on selected layers.
- Sim-to-real dataset generation for manipulation (Sector: Simulation/Robotics Data)
- Use cases: Produce large-scale, task-specific pick-and-place datasets (e.g., 200+ tasks, thousands of objects) for tailored deployments; stress-test generalization (new objects, layouts, backgrounds, instructions).
- Tools/workflows: Isaac Sim/Omniverse pipelines; GenManip-like scene randomization; unified QA formatting for Stage 1 data; auto-generation of spatial prompts for Stage 2.
- Assumptions/dependencies: Sim assets that resemble real objects; calibrated domain randomization; workflows for pose/trajectory export, and sim-to-real calibration.
- Educational labs and reproducible research templates (Sector: Education/Academia)
- Use cases: Course modules on VLA; assignments on spatial grounding vs. action alignment; benchmarking on SimplerEnv/LIBERO; ablation studies on prompting and gradient decay.
- Tools/workflows: Released code/models; scaffolded notebooks; datasets; evaluation harnesses for spatial grounding and manipulation.
- Assumptions/dependencies: Access to simulators and at least one tabletop robot platform in lab settings.
- Visual debugging and operator-in-the-loop tools (Sector: Robotics Operations)
- Use cases: Inspect planner’s predicted points/boxes/trajectories; adjust prompts; inject corrective spatial hints; trigger safe fallback.
- Tools/workflows: UI overlay of VLM Planner outputs; interactive spatial prompts; logging of step-wise latent plan tokens; action visualization.
- Assumptions/dependencies: Operator console; synchronized camera feeds; visualization hooks in the inference stack.
- Policy and benchmarking guidance for embodied AI programs (Sector: Policy/Standards/Consortia)
- Use cases: Incorporate spatial grounding metrics and long-horizon evaluation (e.g., in-distribution vs. unseen objects, poses, instructions) into procurement/testing standards for service robots.
- Tools/workflows: Test protocols based on SimplerEnv, LIBERO, and cluttered-scene pick-and-place; reporting templates for PSS and distribution-shift robustness; safety checklist tied to instruction-following.
- Assumptions/dependencies: Multistakeholder agreement on metrics; public, shareable benchmarks; controlled testbeds.
Long-Term Applications
- Home service robots for unstructured environments (Sector: Consumer/Assistive Robotics)
- Use cases: General tidying, laundry assist, dish sorting, household organization from natural language; robust to clutter, new objects, and variable layouts.
- Tools/workflows: Extended Stage 1 pretraining on home-scale visual/language corpora; additional sensing (depth, tactile); household-specific prompt libraries; online learning from user feedback.
- Assumptions/dependencies: Stronger safety and reliability guarantees; compute/energy efficiency for edge inference; privacy-preserving on-device processing; broader object diversity than current datasets.
- Hospital logistics and care support (Sector: Healthcare)
- Use cases: Supply/instrument fetching, medication delivery, basic room organization; assistants that follow spatially grounded verbal instructions from staff.
- Tools/workflows: Infection control–compliant hardware; high-integrity motion safety; electronic health record-integrated task queues; curated hospital-specific spatial grounding data; operator oversight.
- Assumptions/dependencies: Regulatory certification; rigorous risk management; sterile operation constraints; robust failure detection and handover to human staff.
- Retail execution and planogram compliance (Sector: Retail)
- Use cases: Shelf stocking and rearrangement by instruction; verifying and correcting planograms using spatial grounding; price tag placement; facing merchandise.
- Tools/workflows: Planogram-to-prompt translation; shelf scanning via multi-view cameras; cycle counting; integration with inventory systems.
- Assumptions/dependencies: Varied lighting and customer traffic; safe human-robot interaction; large category/brand diversity; frequent layout changes requiring continual learning.
- Flexible assembly and fixture-less manufacturing (Sector: Advanced Manufacturing)
- Use cases: Tolerant insertion/placement tasks with variable part presentation; fixture-less or low-fixture assembly guided by spatial priors and trajectory prediction.
- Tools/workflows: Tactile/force sensing fused with spatial grounding; real-time adaptation of trajectories; active perception; tight loop between System 2 planning tokens and System 1 control.
- Assumptions/dependencies: High-precision hardware; process capability targets; additional modalities (force/torque, depth) integrated into the training recipe; stringent cycle-time constraints.
- Outdoor mobile manipulation (Sector: Agriculture/Field Robotics/Construction)
- Use cases: Fruit/produce picking, debris sorting, material handling from language instructions with spatial references in changing conditions.
- Tools/workflows: Integration with navigation/SLAM; outdoor-hardened sensing; domain-adapted Stage 1 grounding (lighting, weather, plant/terrain variability).
- Assumptions/dependencies: Large domain shift from indoor training; mobility-platform safety; robust grasping of deformable/natural objects; better sample efficiency in the wild.
- Autonomy governance and auditing frameworks for embodied AI (Sector: Policy/Compliance/Insurance)
- Use cases: Independent verification of spatial grounding integrity after finetuning; audit trails of plan tokens and action trajectories; incident forensics; insurance underwriting.
- Tools/workflows: Standardized PSS-like diagnostics; “chain-of-spatial-proof” logging; conformance test batteries for unseen-object/pose/instruction scenarios; red-teaming protocols.
- Assumptions/dependencies: Industry-wide adoption of interpretability artifacts; standardized telemetry; secure data retention and privacy management.
- Low-latency, low-power deployment via model compression and distillation (Sector: Edge AI/Hardware)
- Use cases: Onboard inference on embedded GPUs/NPUs for mobile bases and battery-powered platforms; sub-50 ms control loops with spatial grounding preserved.
- Tools/workflows: Distillation of Qwen2.5-VL-3B to smaller VLMs; quantization-aware training; lightweight DiT variants; caching/planning-token reuse for repeated subtasks.
- Assumptions/dependencies: Acceptable accuracy drop from compression; hardware support for mixed precision; real-time scheduling and memory budgets.
- Cross-robot, cross-site fleet learning (Sector: Robotics Platforms/Cloud Robotics)
- Use cases: Centralized training that aggregates spatial grounding and action data from multiple sites/robots; federated updates; shared prompt libraries and plan-token vocabularies.
- Tools/workflows: Cloud orchestration; privacy-preserving aggregation; continuous evaluation against distribution-shift test suites; site-specific post-training adapters.
- Assumptions/dependencies: Networking and data governance; heterogeneous hardware abstraction; safety rollback mechanisms; robust multi-tenant isolation.
- Multi-modal co-pilots for human workers (Sector: Human-Robot Collaboration)
- Use cases: Workers issue natural-language commands with spatial references; the robot grounds, proposes plan steps, visualizes intended points/paths, and awaits approval before execution.
- Tools/workflows: AR overlays of predicted boxes/trajectories; interactive spatial prompts; shared autonomy control blending; learn-from-intervention loops.
- Assumptions/dependencies: Ergonomic UI; latency bounds for smooth collaboration; operator training; clear liability and handover protocols.
Notes on feasibility across the board:
- The paper’s dual-stage training and spatial prompting demonstrably improve robustness, generalization to unseen objects/instructions, and long-horizon execution in simulation and on real robots (Franka, WidowX, Google Robot). These results justify immediate use in controlled environments and pilot deployments.
- Scaling to less structured, safety-critical, or outdoor domains depends on additional sensing (depth/tactile), stronger safety cases, richer domain data, and model optimization for edge compute.
Glossary
- Action Expert: The module that specializes in producing embodiment-specific motor commands from spatial plans. "System 1 (the Action Expert) adopts a compact diffusion transformer {(DiT)~\cite{DiT} and a DINOv2 visual encoder~\cite{oquab2023dinov2} for embodiment-specific control."
- Affordance grounding: Linking objects to their actionable properties (e.g., graspable surfaces) in context. "thereby equipping the model with affordance grounding, localization, and trajectory reasoning."
- Chain-of-Thought reasoning: A reasoning style where models generate step-by-step plans before execution. "Inspired by Chain-of-Thought reasoning, many works train vision-language-action (VLA) models to first output textual plans, improving interpretability and long-horizon performance"
- Co-optimization: Simultaneously optimizing multiple objectives (e.g., perception and action) during training. "we track the co-optimization of spatial perception and manipulation success during training."
- Cross-attention module: An attention mechanism that allows query tokens to attend to representations from another sequence/module. "It is implemented as a -layer cross-attention module, where the query tokens selectively attend to intermediate layers of the VLM"
- Diffusion Transformer (DiT): A transformer architecture used in diffusion-based generative modeling and control. "adopts a compact diffusion transformer {(DiT)~\cite{DiT} and a DINOv2 visual encoder~\cite{oquab2023dinov2} for embodiment-specific control."
- DINOv2: A self-supervised visual encoder that provides robust image features for downstream tasks. "and a DINOv2 visual encoder~\cite{oquab2023dinov2} for embodiment-specific control."
- Embodied control: Control of physical robot actions grounded in real-world interactions. "bridges spatial understanding with embodied control through a novel two-stage training recipe"
- End-effector trajectories: Paths traced by the robot’s tool center point during manipulation. "(e.g., manipulator joints, end-effector trajectories, humanoid locomotion, or mobile navigation)."
- End-to-end policy learning: Training a single model to map inputs directly to actions without manual task decomposition. "limits the potential for end-to-end policy learning."
- Gradient conflicts: Incompatible gradient directions from different losses that hinder joint learning. "naïve co-training with spatial data introduces gradient conflicts between spatial grounding and action objectives."
- Gradient decay factor: A scalar used to attenuate backpropagated gradients to protect certain model components. "we introduce a gradient decay factor within the querying transformer."
- Gradient matrices: Matrices of parameter gradients computed for different objectives or batches, used to analyze optimization alignment. "{we quantify the alignment between the two objectives using similarity between gradient matrices.}"
- Hierarchical robotic systems: Architectures that separate high-level planning from low-level control using intermediate representations. "Prior work has approached this challenge through hierarchical robotic systems"
- Isaac-Sim: A high-fidelity robotics simulation platform used to generate large-scale datasets and evaluations. "we construct a large-scale simulation benchmark in Isaac-Sim by GenManip"
- Latent planning tokens: Internal token representations produced by a planner that encode spatially informed plans. "generates latent planning tokens via spatial prompting"
- LIBERO: A language-conditioned manipulation benchmark suite built on a Franka arm. "We further evaluate {ST4VLA} on the LIBERO simulation suite"
- Long-horizon manipulation: Tasks requiring many sequential steps, planning, and robustness over extended durations. "Demonstration and results of long-horizon instruction-following manipulation tasks."
- Moore–Penrose pseudoinverse: A generalized matrix inverse used for least-squares solutions and defining projectors. "Using the Moore--Penrose pseudoinverse ,"
- Next-token prediction: A language modeling objective where the model predicts the next token given context. "where the VLM backbone is updated via next-token prediction on image-prompt pairs"
- Projection-Space Similarity (PSS): A metric that measures alignment between gradient subspaces of different objectives. "We introduce Projection-Space Similarity (PSS)~\cite{raghu2017svcca}, a method to quantify the alignment between the optimization dynamics of the multimodal grounding objective and the action policy objective."
- Querying transformer: A lightweight transformer that maps variable-length embeddings to fixed query tokens via cross-attention. "we adopt a lightweight querying transformer (8.7 MB) conditioned on the latent spatial grounding embeddings produced by the VLM Planner."
- SimplerEnv: A simulation suite for instruction-following tasks with controlled visual variations. "establishing new state-of-the-art results on SimplerEnv."
- Spatial grounding: Learning to localize and link language to spatial targets such as points, boxes, and trajectories. "spatial grounding pre-training"
- Spatial prompting: Appending prompts that elicit spatial reasoning and grounding from a VLM during training. "we employ spatial prompting during post-action training stage."
- Spatial priors: Prior knowledge about spatial structure and relations that guides perception and control. "Core spatial priors, such as object recognition, affordance grounding, visual trajectory reasoning, and relative localization, provide transferable and generalizable knowledge for robotic manipulation."
- System 1: The fast, reactive controller component that executes embodiment-specific actions. "System 1 (the Action Expert) adopts a compact diffusion transformer {(DiT)~\cite{DiT} and a DINOv2 visual encoder~\cite{oquab2023dinov2} for embodiment-specific control."
- System 2: The slow, deliberative planner component that reasons and produces spatially grounded plans. "System 2 (the VLM planner) employs as a multimodal encoder to capture spatial and semantic priors"
- Teleoperation datasets: Collections of human-controlled robot trajectories used to train action policies. "large-scale teleoperation datasets~\cite{open_x_embodiment, khazatsky2024droid, bu2025agibot, wu2024robomind, starvla2025} to directly learn robot control."
- Trajectory prediction: Inferring future motion paths for objects or the robot to guide manipulation. "bounding-box detection, affordance recognition, and trajectory prediction."
- Vision–Language–Action (VLA): Models that map visual and textual inputs to executable robot actions. "{ST4VLA}, a dual-system VisionâLanguageâAction framework that leverages Spatial Guided Training"
- Vision–LLMs (VLMs): Models that jointly process images and text to perform multimodal understanding. "Large visionâLLMs (VLMs) excel at multimodal understanding"
- Visual trajectory reasoning: Understanding and reasoning about motion paths from visual inputs. "visual trajectory reasoning"
Collections
Sign up for free to add this paper to one or more collections.