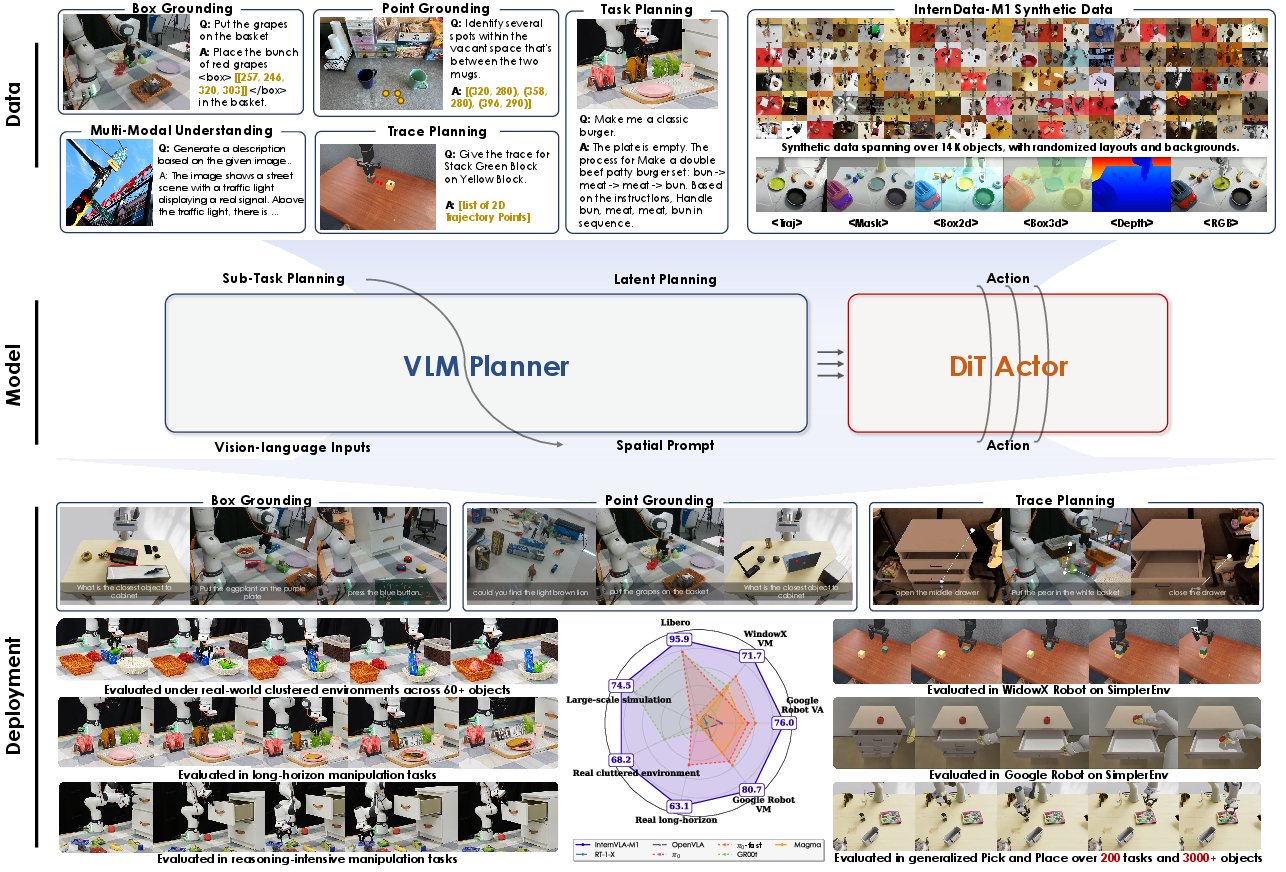
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
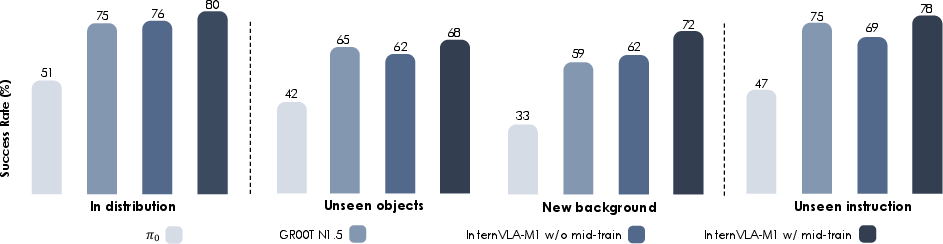
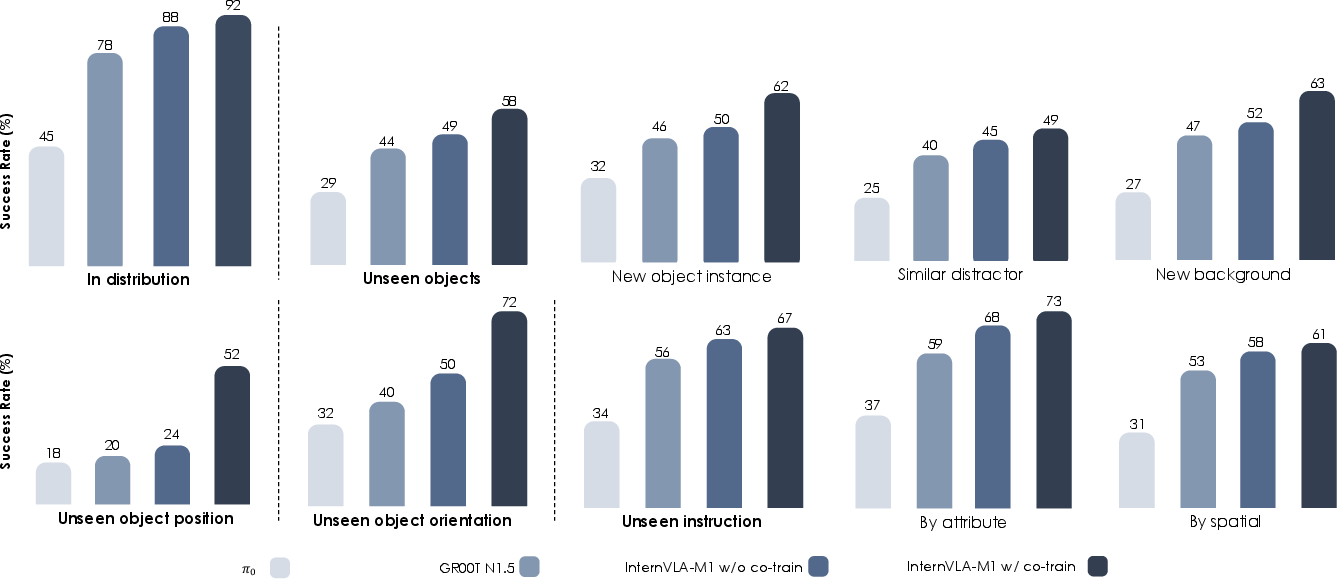
Abstract: We introduce InternVLA-M1, a unified framework for spatial grounding and robot control that advances instruction-following robots toward scalable, general-purpose intelligence. Its core idea is spatially guided vision-language-action training, where spatial grounding serves as the critical link between instructions and robot actions. InternVLA-M1 employs a two-stage pipeline: (i) spatial grounding pre-training on over 2.3M spatial reasoning data to determine where to act'' by aligning instructions with visual, embodiment-agnostic positions, and (ii) spatially guided action post-training to decidehow to act'' by generating embodiment-aware actions through plug-and-play spatial prompting. This spatially guided training recipe yields consistent gains: InternVLA-M1 outperforms its variant without spatial guidance by +14.6% on SimplerEnv Google Robot, +17% on WidowX, and +4.3% on LIBERO Franka, while demonstrating stronger spatial reasoning capability in box, point, and trace prediction. To further scale instruction following, we built a simulation engine to collect 244K generalizable pick-and-place episodes, enabling a 6.2% average improvement across 200 tasks and 3K+ objects. In real-world clustered pick-and-place, InternVLA-M1 improved by 7.3%, and with synthetic co-training, achieved +20.6% on unseen objects and novel configurations. Moreover, in long-horizon reasoning-intensive scenarios, it surpassed existing works by over 10%. These results highlight spatially guided training as a unifying principle for scalable and resilient generalist robots. Code and models are available at https://github.com/InternRobotics/InternVLA-M1.
First 10 authors:






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (the big idea)
This paper introduces InternVLA-M1, a robot system that can read instructions, look at the world, figure out where to act, and then move its body to do the task. The key idea is simple: teach the robot “where to act” first (spatial understanding), then teach it “how to act” (robot control), and keep both parts talking to each other. By doing this, the robot follows instructions better in both simulations and the real world.
What questions the paper tries to answer
Here are the main goals, in everyday words:
- How can a robot connect words (like “put the apple in the top drawer”) to the exact place in the real world where it should act?
- Can separating “where to act” (spatial understanding) from “how to act” (motor control) make robots more reliable and general?
- Can we use lots of synthetic (simulated) data to scale up training, so the robot works well even on new objects and new scenes?
How the system works (methods, explained simply)
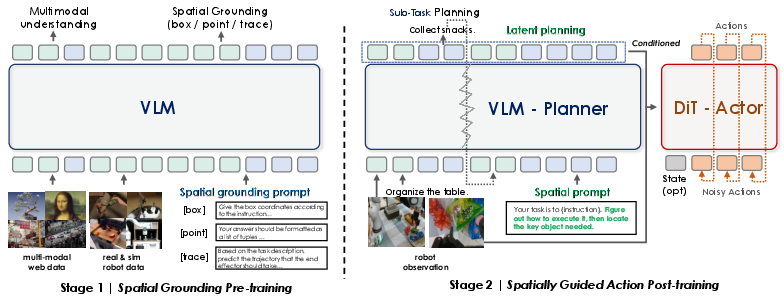
Think of InternVLA-M1 as a two-part team:
- A careful planner (System 2): This part reads the instruction, looks at the images, and decides “where things are” and “where to act.” It’s like a person who reads a recipe and points to the ingredients on the table.
- A fast doer (System 1): This part turns that plan into smooth arm movements. It’s like a skilled cook who chops, grabs, and places quickly and accurately.
To build this two-part team, the authors train the robot in two stages:
- Stage 1 — Learn “where to act” (spatial grounding pre-training)
- The planner is trained on over 2.3 million examples focused on spatial understanding.
- Three simple kinds of “pointing” are used:
- Points: like placing your fingertip on exactly where to click or grasp.
- Boxes: like drawing a rectangle around an object to select it.
- Traces: like drawing a squiggly line that shows a path to move along.
- This teaches the planner to match language (“put the green block on the yellow block”) with the exact places in images where actions should happen.
- Stage 2 — Learn “how to act” using the “where” knowledge (spatially guided action training)
- Now the planner’s “where to act” guidance is plugged into the action model (the doer), which learns robot motions from demonstrations.
- The trick they use is called spatial prompting: they add a short, helpful nudge to the instruction (for example, “Identify the key object and its location first”) so the planner reliably produces strong spatial cues before the robot moves.
- The two parts are co-trained together: the planner keeps improving its spatial reasoning while the action model learns smooth, correct movements. A tiny connector module helps pass the planner’s “plan” to the action model in a stable way.
Data to scale up learning:
- The team also builds a simulation engine to generate 244,000 high-quality pick-and-place episodes. Think of it like a video game that creates tons of practice tasks with different objects, lighting, and placements. This makes the robot good at handling new situations.
Analogy:
- Planner = your eyes and brain deciding what and where.
- Doer = your hands executing the moves.
- Spatial grounding (points/boxes/traces) = pointing, highlighting, and drawing a path on a photo to say “do it here, like this.”
What they found (main results and why they matter)
Across many tests, the spatially guided training clearly helps. Here are highlights:
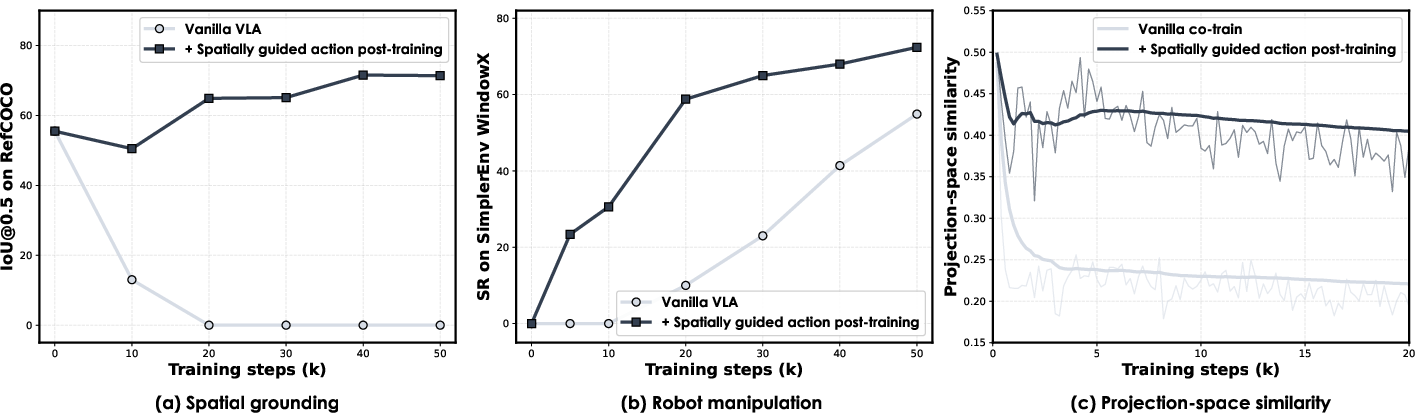
- In simulated benchmarks (SimplerEnv):
- On Google Robot tasks, the spatially guided version beats the non-guided version by around +14.6% on one set and +12.5% on another.
- On the WidowX robot set, it’s about +17% better.
- These tasks include things like picking cans, opening drawers, and placing items, often under changed lighting, camera angles, or textures—so they’re good tests of generalization.
- On LIBERO (another popular benchmark with a Franka arm):
- High success across different challenge types (spatial changes, new goals, longer multi-step tasks), with an average of about 95.9%.
- It handles long, multi-step tasks well, showing the planner-doer split works for complex procedures.
- In a large simulated pick-and-place suite (200 tasks, 3,000+ objects):
- After training with 244K synthetic episodes, performance improves by about +6.2% on average compared to strong baselines.
- It generalizes better to new objects, new backgrounds, and reworded instructions.
- In real-world pick-and-place with clutter:
- It improves by about +7.3% in general and by +20.6% on unseen objects and new setups when co-trained with synthetic data.
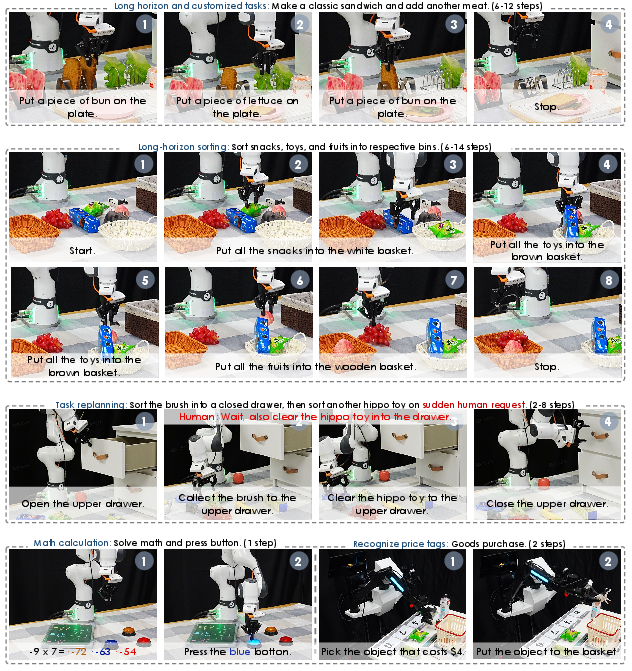
- It also performs better on long, reasoning-heavy tasks (like sorting items, using drawers, assembling sandwiches, simple math-to-button tasks), beating prior systems by over 10% in some cases.
Why this is important:
- Robots usually struggle to connect language like “top drawer” or “left of the box” to precise actions. By learning “where” separately and using it to guide “how,” InternVLA-M1 becomes more reliable and flexible in real settings, not just in demos.
What this could change (implications)
- A unifying principle for general robots: Separating “where to act” (spatial grounding) from “how to act” (control) is a powerful recipe. It lets the same “where” skills transfer across different robot bodies, while each robot only has to learn its specific “how.”
- Better scaling with simulation: The paper shows that a large, carefully built simulation pipeline can add huge amounts of useful practice, making robots better with new objects, layouts, and instructions—even before seeing them in real life.
- Toward general-purpose assistants: Stronger spatial reasoning plus robust actions means robots could follow everyday instructions in messy homes, labs, or warehouses more effectively—opening drawers, sorting items, or performing multi-step tasks with fewer mistakes.
- Future directions: Add more diverse tasks (navigation, tool use), more complex language, and more varieties of robots. The same “where first, then how” strategy should keep scaling.
In short: InternVLA-M1 teaches robots to think about place before motion. That simple shift—first learn to point, box, and trace “where,” then learn “how” to move—leads to big, consistent gains in both simulation and the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Embodiment transfer and breadth
- No evidence of zero/few-shot transfer to substantially different embodiments (e.g., mobile manipulators, humanoids, soft grippers, suction, underactuated hands) or to bimanual coordination; ARX LIFT2 is mentioned but quantitative results are absent.
- Unclear how well the “embodiment-agnostic” spatial priors transfer across robots with different kinematics, control spaces (joint/EE/operational), and encoders without robot-specific fine-tuning.
- No study on cross-sensor transfer (e.g., switching camera intrinsics/extrinsics, RGB→RGBD, different resolutions or latency).
- Spatial grounding representation limitations
- Spatial grounding is trained/evaluated primarily in 2D (points, boxes, 2D traces); there is no explicit 3D scene reasoning, multi-view 3D fusion, or 6-DoF pose grounding, limiting precise metric alignment with the robot frame.
- Absence of explicit depth/geometry signals (e.g., depth maps, meshes, occupancy, surface normals) in the VLM planner; unclear whether this hinders contact-rich or occluded manipulation.
- No evaluation of grounding for affordances at contact surfaces (grasp points, insertion axes, approach vectors) or force-aware goals.
- Prompting and planner–controller interface
- Spatial prompting relies on hand-crafted auxiliary phrases; sensitivity to prompt wording, length, and task-type is not analyzed. How robust is performance to prompt variations or prompt omissions per task domain?
- The querying transformer design (which layers to attend, number of tokens) and the gradient decay factor (e.g., 0.5) are set heuristically; no systematic sweeps quantify trade-offs between preserving VLM competence and improving control.
- Latent planning tokens are not made interpretable or validated for subgoal/content correctness; no diagnostics to detect when the planner grounds the wrong object or relation.
- Co-training schedule and optimization
- The ratio/schedule for alternating robot trajectories and spatial grounding data is not specified or ablated; optimal mixing policies and curriculum remain unknown.
- Projection-space Similarity (PSS) is used to argue better alignment, but the causal link to downstream success is not established; thresholds, confidence intervals, and reproducibility of the PSS–performance correlation are open.
- Simulation-to-reality (sim2real) gaps
- While camera calibration and domain randomization are used, there is no quantitative ablation of which randomizations (textures, lighting, clutter, camera drift) matter most for real performance.
- The simulation engine focuses on rigid pick-and-place with mesh-based grasp proposals (PointNetGPD), potentially biasing toward “easy” graspable geometries; transfer to deformables, tools, articulated mechanisms (beyond drawers), tight tolerances, and non-prehensile skills is untested.
- No analysis of dynamics mismatch (friction, compliance, contact models) and its effect on learned policies; no system identification or adaptation mechanisms are proposed.
- Task and benchmark coverage
- Evaluations are largely tabletop; there is no study on navigation+manipulation, long-reach tasks, or large workspaces with changing viewpoints.
- Long-horizon studies lack standardized metrics for plan quality, subgoal correctness, and recovery after failures; details on online re-planning frequency, memory/state tracking, or explicit progress monitoring are limited.
- Compositional generalization (e.g., novel object–attribute–relation combinations, counting “all” instances, multi-container constraints) is qualitatively discussed but not rigorously benchmarked.
- Real-world robustness and safety
- Robustness to heavy occlusions, extreme clutter, moving distractors, sensor noise/dropouts, and camera miscalibration is not quantified; failure modes are not systematically analyzed.
- No uncertainty estimation, OOD detection, or confidence-driven re-planning; the policy does not expose self-assessment to trigger safe fallback behaviors.
- Safety constraints and physical limit awareness (e.g., collision avoidance, force thresholds, human-in-the-loop overrides) are not integrated or evaluated.
- Modalities and perception fusion
- Only RGB is used; depth, tactile, force/torque, and audio are not incorporated; the benefits and costs of adding these modalities remain unclear.
- Multi-view fusion appears image-level; no explicit calibrated 3D fusion or learned canonicalization to a robot-centric frame is examined.
- Action modeling choices
- The action head is a diffusion (DiT) policy; there is no comparison with alternative heads (autoregressive, flow, hybrid MPC, policy–value architectures) or with model-based/action-constraint formulations for stability and sample efficiency.
- Effects of action chunk size and control rate on closed-loop stability/latency are not studied; end-to-end latency budgets (VLM ~10 FPS, chunking, KV caching) vs. control accuracy are not quantified.
- Data scale, bias, and license concerns
- The spatial grounding corpus mixes web and robotics data; potential dataset bias/leakage relative to evaluations (e.g., overlaps in objects/scenes/instructions) is not audited.
- Scaling laws (performance vs. amount/type of spatial grounding data) are not reported; guidance on marginal returns for boxes vs. points vs. traces is missing.
- Ethical/licensing implications of aggregated web datasets and synthetic assets are not discussed.
- Learning paradigm and continual adaptation
- The approach is fully supervised; there is no on-robot RL, self-improvement, or active data acquisition to close residual sim2real gaps or adapt to drift.
- Continual and lifelong learning (avoiding catastrophic forgetting across new tasks/robots) is not addressed; adapters, modularization, or gating strategies are not explored.
- Generality of language understanding
- Multilingual instructions, code-switching, and domain-specific jargon are not tested; robustness to ambiguous, underspecified, or contradictory instructions is unexamined.
- The scope of instruction rewrites (paraphrases) is narrow; no controlled benchmarks (e.g., compositional language tasks) are used to probe linguistic generalization.
- Reproducibility and statistical rigor
- Several baseline numbers are reimplemented; variance, confidence intervals, and statistical significance across seeds are often missing.
- Full hyperparameters for co-training schedules, prompt templates, data mixing ratios, and compute budgets are not exhaustively documented; replicability on different hardware is unverified.
- Efficiency and deployment constraints
- The ~4.1B-parameter system is validated on an RTX 4090; there is no evidence of deployment on resource-constrained platforms, nor of quantization/distillation for on-robot inference.
- Energy and cost footprints (training and inference) are not reported; trade-offs between model size and real-world performance are unknown.
- Interpretability and verification
- No tools are provided to visualize or verify spatial plans (e.g., attention maps, predicted subgoal heatmaps) or to debug grounding failures online.
- Formal guarantees (task constraints satisfaction, safety constraints) and plan verification against symbolic world models are not integrated.
- Extending the synthetic engine
- The data engine lacks generators for deformables (cloth, food), tool use, tight-tolerance assembly, liquids, and complex articulated objects beyond drawers; adding these domains could stress-test spatial priors and control.
- Automated difficulty curricula (progressively harder clutter, occlusions, distractors) and task diversity schedulers are not implemented or evaluated.
- Evaluation coverage gaps in the paper
- The long-horizon “reasoning” section cuts off and lacks complete quantitative results and comparisons; clarity on benchmarks, metrics, and baselines for those tasks is needed.
- Absolute success rates for some real-world regimes (e.g., “+20.6% improvement”) are reported without raw numbers or variance, limiting cross-paper comparability.
Practical Applications
Below is an overview of practical applications enabled by the paper’s findings, methods, and innovations. The items are grouped by immediacy and linked to sectors. Each bullet includes indicative tools/products/workflows and notes assumptions or dependencies that may affect feasibility.
Immediate Applications
- Generalizable clustered pick-and-place in fulfillment and warehousing (sector: robotics, logistics, retail)
- What: Bin sorting, order consolidation, returns triage, and decluttering in variable tabletop scenes with unseen SKUs and layout shifts.
- How: Deploy InternVLA-M1 with spatial prompting and co-training on synthetic InternData-M1 to handle visual shifts and novel objects; use the dual-system “Planner-Actor Bridge” and action chunking for real-time control.
- Tools/workflows: Spatial Prompt Library; ROS/Isaac integration; ArUco-calibrated multi-camera setup; DINOv2-based perception; diffusion policy actor.
- Assumptions/dependencies: Stable grasping hardware (e.g., Robotiq gripper), accurate camera calibration, collision safety policies; tasks primarily rigid-object, tabletop manipulation; on-prem GPU (e.g., RTX 4090) or optimized edge inference.
- Kit preparation and light assembly in manufacturing cells (sector: manufacturing, industrial automation)
- What: Sorting parts into trays, staging components by “where to place” directives, opening/closing drawers, and layered assembly sequences analogous to the paper’s “sandwich” tasks.
- How: Use spatial grounding (boxes/points/traces) to localize parts and containers; System 2 planner decomposes multi-step instructions into atomic actions, executed by diffusion policy actor.
- Tools/workflows: Latent Plan Query Transformer; task libraries with spatial cues; co-training with synthetic trajectories to expand pose coverage.
- Assumptions/dependencies: Repeatable fixture setups, safety interlocks (light curtains, force limits), PLC/ROS bridging; limited deformables and high precision fixturing when necessary.
- Store shelf restocking and price verification (sector: retail operations)
- What: Restock items to specified shelf locations and verify price labels by instruction (e.g., “place all snacks on the middle shelf; pick the item priced at 7”).
- How: Combine OCR-capable VLM (from general QA data) with spatial grounding; leverage the “Goods Purchase” exemplar to align numeric cues with actions.
- Tools/workflows: Shelf layout prompts; pose-robust camera placements; JSON/XML coordinate outputs for HMI audits.
- Assumptions/dependencies: Lighting and texture variability handled via synthetic co-training; safe human–robot co-working protocols; real-world OCR quality thresholds.
- Laboratory sample handling and rack organization (sector: healthcare, biotech, lab automation)
- What: Place vials/tubes into racks or boxes by label/class; move items to designated zones; basic drawer operations.
- How: Pre-mapped rack geometry and point grounding; spatial prompts to elicit relation-aware placement (“nearest empty slot”, “back row left”).
- Tools/workflows: Calibrated multi-view cameras; point/box grounding QA datasets; domain-specific prompt templates.
- Assumptions/dependencies: Non-sterile manipulation (sterility requires additional hardware/process), rigid containers, safety and compliance oversight.
- Desk and kitchen assistance in controlled environments (sector: service robotics, daily life)
- What: Sorting toys/snacks, arranging items into boxes, following recipe-like sequences (layered placements).
- How: Deploy InternVLA-M1 on a fixed-base arm with two RGB views; leverage spatial prompting and long-horizon planning tested in the paper (sorting, drawers, recipes).
- Tools/workflows: Household prompt packs; instruction paraphrase handling; real-time replanning under perturbations.
- Assumptions/dependencies: Controlled clutter, rigid objects, sufficient workspace access; edge inference or local GPU; user safety constraints.
- Rapid policy bootstrapping via synthetic co-training (sector: robotics engineering, MLOps)
- What: Cut down teleoperation demands by mid-training on InternData-M1 (244K episodes), then fine-tune with limited real demos.
- How: Adopt the paper’s post-pre-training stage; alternate co-training on spatial grounding and robot trajectories to align perception and control (higher Projection-space Similarity).
- Tools/workflows: Data synthesis pipeline (GenManip + Isaac Sim); scene-graph validation; renderer–physics decoupling for throughput.
- Assumptions/dependencies: Quality and coverage of asset libraries (14K objects, textures, lights); sim-to-real calibration fidelity; target robot kinematics close to training distribution.
- Cross-robot skill transfer with an embodiment-agnostic spatial prior (sector: robotics platforms, OEMs)
- What: Port language-conditioned manipulation across Franka, WidowX, and similar arms by reusing the VLM planner and adapting the action head.
- How: Keep spatial priors fixed; retrain or fine-tune the diffusion actor per embodiment; plug-and-play querying transformer for latent plans.
- Tools/workflows: Robot-specific action adapters; standardized observation spaces; ROS drivers.
- Assumptions/dependencies: Consistent camera intrinsics/extrinsics; adequate demonstrations for the new embodiment; actuator limits and compliance tuning.
- Spatial grounding as a productized capability (sector: software, robotics tooling)
- What: Offer “where-to-act” services: point, box, and trace prediction APIs for downstream controllers.
- How: Wrap Qwen2.5-VL planner with spatial QA endpoints; export coordinates in JSON/XML to external planners/PLC/HMI.
- Tools/workflows: Lightweight microservice; SDKs for ROS/Unity/Isaac; prompt templates for affordance and free-space grounding.
- Assumptions/dependencies: Latency budgets compatible with 10 FPS VLM; robust prompt engineering; domain generalization may require fine-tuning.
- Curriculum and benchmarking for academia (sector: education, research)
- What: Use InternData-M1 and spatial QA corpora to teach spatial grounding, co-training, and dual-system optimization; replicate SimplerEnv/LIBERO results.
- How: Course modules on latent planning, gradient alignment, and sim-to-real; public models/datasets for assignments.
- Tools/workflows: Open-source code; standardized evaluation on SimplerEnv/LIBERO; PSS diagnostics (SVD-based).
- Assumptions/dependencies: GPU access; robot simulators or low-cost manipulators; adherence to dataset licensing.
- Safety-aware deployments via stepwise execution and monitoring (sector: policy, enterprise safety)
- What: Gate multi-step actions (e.g., open drawer → place → close) with progress checks; log spatial predictions for audit.
- How: Use System 2 planner to structure verifiable steps; require “pass” on each step before proceeding; maintain action logs with predicted bounding boxes/points.
- Tools/workflows: Compliance dashboard; event logging; rollback/retry policies.
- Assumptions/dependencies: Defined safety envelopes; emergency stop and force limits; certified risk assessments for human–robot interaction.
Long-Term Applications
- Whole-home generalist assistant across rooms (sector: service robotics, smart homes)
- What: Extend spatial grounding and instruction following beyond tabletop manipulation to mobile navigation, cabinet access, laundry sorting, and dish loading.
- How: Add locomotion/navigation modules under the same dual-system paradigm; expand priors to 3D mapping and affordances for doors/drawers/appliances.
- Tools/workflows: Mobile base integration; multimodal mapping; extended synthetic assets for full-home scenarios.
- Assumptions/dependencies: Robust sim-to-real transfer for mobile platforms; comprehensive safety standards; significant additional training.
- Hospital logistics and bedside assistance (sector: healthcare)
- What: Medication caddy stocking, instrument fetching, room tidying, and non-contact button pressing guided by natural language.
- How: Domain-tuned spatial prompts for sterile workflows; stepwise verification in long-horizon tasks; integration with clinical HMI.
- Tools/workflows: Compliance-grade audit trails; recipe/task libraries; fail-safe recovery policies.
- Assumptions/dependencies: Strict regulatory compliance (FDA/IEC 60601), infection control, reliability under high-stakes settings; robust perception of medical packaging and devices.
- Deformable and transparent object handling in logistics/manufacturing (sector: robotics, materials handling)
- What: Bagging, packaging, cable routing, handling shrink-wrap/transparencies where classical vision struggles.
- How: Extend spatial priors and action policies with dedicated datasets and tactile/force sensors; model affordances for deformables.
- Tools/workflows: Multisensor fusion (RGB-D, tactile); deformation-aware synthetic data; advanced grasp planners.
- Assumptions/dependencies: New data regimes, sensor suite upgrades, and more complex controllers; higher compute and control loop demands.
- Agricultural picking and sorting (sector: agriculture)
- What: Fruit/vegetable harvesting and sorting by grade, following spatial layouts and relational cues (ripeness bins, defect trays).
- How: Train priors for outdoor visual shifts (seasonal, lighting); add grippers suited to delicate produce; field-ready hardware.
- Tools/workflows: Domain-specific synthetic farms; weather/illumination augmentations; field calibration protocols.
- Assumptions/dependencies: Robust outdoor perception; compliance with farm safety; high tolerance to occlusion, deformability, and variability.
- Construction site material staging and tool delivery (sector: construction)
- What: Move and stage parts/tools to specified zones, support prefabrication stations with instruction-based placement.
- How: Combine spatial grounding with hazard-aware planning; use mobile manipulation and multi-view sensing.
- Tools/workflows: BIM integration; zone-based prompts; hazard/obstacle maps.
- Assumptions/dependencies: Strong safety frameworks; ruggedized hardware; dynamic environment modeling.
- Factory “generalist operator” across multiple workcells (sector: Industry 4.0)
- What: A single policy that adapts to varied fixtures and tasks by language and spatial cues, reducing task-specific programming.
- How: Standardize a spatial-prior service across cells; retrain action heads per embodiment; introduce policy orchestration.
- Tools/workflows: Centralized model registry; cell adapters; orchestration for multi-robot fleets.
- Assumptions/dependencies: Broad, high-quality datasets per cell; governance of updates and drift; interlocks with PLCs.
- Cloud robotics service for natural-language spatial control (sector: software, cloud)
- What: Offer VLM planner as a cloud API; edge devices subscribe for “where-to-act” + latent plan tokens, local actors execute.
- How: KV caching and chunking for latency; secure telemetry; tiered SLAs for industrial users.
- Tools/workflows: Cloud inference endpoints; SDKs; on-device safety wrappers.
- Assumptions/dependencies: Network latency constraints; data privacy; uptime guarantees; cost management.
- Regulatory standards for synthetic+real co-training and auditability (sector: policy, standards)
- What: Formal guidelines on mixing synthetic and real data, documentation of spatial prompts, and stepwise execution logs for certification.
- How: Define benchmark suites (e.g., SimplerEnv/LIBERO derivatives), reporting of PSS/alignment metrics, and traceable JSON/XML outputs.
- Tools/workflows: Conformance tests; audit packages; dataset provenance records.
- Assumptions/dependencies: Multi-stakeholder standards bodies; longitudinal safety evidence; harmonization across regions.
- Edge deployment via distillation/quantization (sector: embedded AI, robotics hardware)
- What: Shrink the 4.1B-parameter system for low-power arms and mobile platforms without losing spatial grounding fidelity.
- How: Knowledge distillation from InternVLA-M1; quantization-aware training; selective layer freezing for the planner.
- Tools/workflows: Distillation pipelines; mixed-precision runtimes; hardware-aware schedulers.
- Assumptions/dependencies: Acceptable accuracy–latency trade-offs; hardware support (Tensor Cores/NPUs); careful validation to avoid safety regressions.
- Human–robot collaboration with natural language plus spatial pointing (sector: HRI, education, workplaces)
- What: Workers or students specify tasks by speech and pointing/gestures; robot grounds the instruction and acts safely.
- How: Fuse language with visual spatial cues (points/boxes/traces); maintain stepwise checks and shared autonomy modes.
- Tools/workflows: Gesture capture; multimodal prompts; collaboration policies.
- Assumptions/dependencies: Robust multimodal sensing; clear HRI protocols; user training and consent.
- Multi-robot fleet orchestration with shared spatial priors (sector: robotics platforms)
- What: Different robots (arms, mobile bases) reuse a common planner while specializing local actors, enabling coordinated tasks.
- How: Central spatial grounding server; per-robot action adapters; synchronization via shared latent plans.
- Tools/workflows: Fleet manager; synchronization APIs; cross-embodiment datasets.
- Assumptions/dependencies: Stable time sync; consistent camera calibration across robots; conflict resolution and safety at scale.
These applications leverage the paper’s core innovations—spatially guided pre-training, dual-system VLM–actor design, spatial prompting, and scalable synthetic data generation—to move instruction-following robots toward robust, general-purpose capability. The feasibility of each application hinges on hardware readiness, safety protocols, dataset coverage, calibration fidelity, and compute budgets appropriate to the deployment setting.
Glossary
- A0 ManiSkill subset: A subset of the ManiSkill benchmark providing object-centric robot trajectories used to train spatial and motion understanding. "This category integrates the A0 ManiSkill subset~\cite{a0}, the InternData-M1 waypoint dataset, and the MolmoAct dataset~\cite{molmoact} to enable precise end-effector trajectory prediction."
- Action Expert: The low-level controller module that generates embodiment-specific motor commands conditioned on the planner’s outputs. "It adopts the diffusion policy~\cite{chi2023diffusionpolicy} (86 M) as the Action Expert (System 1, the fast executor), which effectively models embodiment-specific control."
- Affordance grounding: Linking objects to their actionable properties or possible interactions in the scene. "Core spatial priors such as object recognition, affordance grounding, visual trajectory reasoning, relative localization, and scaling provide transferable knowledge across robotic platforms."
- Affordance recognition: Detecting or classifying the actionable properties of objects from visual inputs. "All robot datasets are reformatted into a unified QA-style structure covering bounding-box detection, trajectory prediction, affordance recognition, and chain-of-thought reasoning."
- ArUco markers: Fiducial markers used for precise camera calibration and pose estimation. "we calibrate all cameras using ArUco markers, ensuring that their intrinsic and extrinsic parameters match those of real-world cameras, thus maintaining consistent viewpoint geometry."
- Box QA: A visual question answering format focused on predicting bounding boxes that ground language to image regions. "Box QA. We curate a diverse collection of multimodal grounding datasets, including RefCOCO~\cite{yu2016modeling, mao2016generation}, ASv2~\cite{wang2024all}, and COCO-ReM~\cite{singh2024benchmarking}, sourced from InternVL3~\cite{chen2024internvl, internvl3}."
- Chain-of-thought reasoning: Explicit multi-step reasoning traces used to improve complex task understanding. "All robot datasets are reformatted into a unified QA-style structure covering bounding-box detection, trajectory prediction, affordance recognition, and chain-of-thought reasoning."
- Co-training: Jointly training on heterogeneous datasets (e.g., trajectories and grounding) to align perception and control. "Co-training with spatial grounding data. Training alternates between robot trajectory data and grounding data."
- Cross-attention module: A transformer mechanism where query tokens attend to intermediate features to extract relevant information. "It is implemented as a -layer cross-attention module, where the query tokens selectively attend to intermediate layers of the VLM (e.g., attends only to the final layer)."
- Delta end-effector space control: Controlling actions by predicting changes in the end-effector pose rather than absolute positions. "All models, including baselines, are trained and executed using delta end-effector space control in real-world experiments."
- Delta joint space control: Controlling actions by predicting incremental changes in robot joint angles. "Both our model and all baseline models are trained using delta joint space control."
- DiT Actor: A Diffusion Transformer-based action head that generates control commands conditioned on planner tokens. "as the condition to the action expert (instantiated as a DiT Actor) to execute as a fast System 1 controller."
- Diffusion policy: A policy that models action sequences via diffusion processes, enabling robust control generation. "It adopts the diffusion policy~\cite{chi2023diffusionpolicy} (86 M) as the Action Expert (System 1, the fast executor), which effectively models embodiment-specific control."
- DINOv2: A high-performance visual encoder used to extract image features for downstream robotics tasks. "This expert is built on the DINOv2 visual encoder~\cite{oquab2023dinov2} (21 M) and a lightweight state encoder (0.4 M), forming a compact visionâaction model."
- Dual-supervision: Training with both multimodal (perception) and action (control) losses to co-adapt modules. "Dual-Supervision. The dual-system architecture supports both multimodal supervision and action supervision during training."
- Dual-system: A two-part architecture with a slow, deliberative planner (System 2) and a fast, reactive controller (System 1). "InternVLA-M1\ is a dual-system, end-to-end VLA framework pre-trained on large-scale spatial grounding data collected from diverse sources."
- Embodiment-agnostic spatial prior: Spatial understanding that is independent of specific robot morphology, transferable across platforms. "an embodiment-agnostic spatial prior, which functions as a bridge between textual instructions and embodiment-specific motor commands, offers a promising foundation for scalable robot learning."
- End-effector trajectory: The path traced by the robot’s tool center point during manipulation. "In addition to high-resolution images, the renderer produces rich intermediate outputs, such as object bounding boxes and 2D end-effector trajectories."
- FlashAttention: An optimized attention algorithm that accelerates transformer inference and reduces memory usage. "With FlashAttention, the VLM component achieves inference speeds of approximately 10 FPS."
- Foundation models: Large-scale pretrained models with broad generalization across tasks and modalities. "Large multimodal foundation models~\cite{llavaov, chen2024internvl, bai2025qwen2, clip, siglip} have demonstrated strong generalization by leveraging web-scale visionâlanguage alignment and instruction-following corpora."
- GenManip: A scalable simulation pipeline for generating diverse robotic manipulation data. "we build a highly scalable, flexible, and fully automated simulation pipeline on top of GenManip~\cite{gao2025genmanip} and Isaac Sim~\cite{isaac}."
- Intersection over Union (IoU): A metric measuring overlap between predicted and ground-truth regions. "From left to right: (a) spatial grounding performance ([email protected] on RefCOCO-g);"
- InternData-M1: A large, synthetic instruction-following dataset used for pre/post-training and co-training. "we incorporate the InternData-M1 dataset, generated via scalable synthetic data generation as \Cref{sec: synthetic data engine}"
- Isaac Sim: NVIDIA’s robotics simulator used for physics-accurate data generation and evaluation. "we build a highly scalable, flexible, and fully automated simulation pipeline on top of GenManip~\cite{gao2025genmanip} and Isaac Sim~\cite{isaac}."
- KV caching: Caching transformer key/value states to speed up autoregressive inference. "Action execution can be further accelerated via chunking and KV caching."
- Latent planning tokens: Hidden tokens produced by the planner that encode spatially grounded plans to condition the controller. "generates latent planning tokens via spatial prompting as the condition to the action expert (instantiated as a DiT Actor) to execute as a fast System 1 controller."
- LIBERO: A language-conditioned manipulation benchmark built on a Franka arm with diverse suites. "LIBERO is a language-conditioned manipulation suite built on a Franka arm with diverse scenes and expert demonstrations."
- Long-horizon: Tasks spanning multiple steps and requiring extended planning and reasoning. "Moreover, in long-horizon reasoning-intensive scenarios, it surpassed existing works by over 10\%."
- MolmoAct: A dataset containing multimodal action supervision for trajectory and manipulation learning. "This category integrates the A0 ManiSkill subset~\cite{a0}, the InternData-M1 waypoint dataset, and the MolmoAct dataset~\cite{molmoact} to enable precise end-effector trajectory prediction."
- Open-X Embodiment (OXE): A collection of diverse teleoperation datasets used for training robotic policies. "we post-train {InternVLA-M1} on a subset of Open-X Embodiment (OXE) (including fractal_rt_1 and bridge_v1), with co-training on spatial grounding data"
- Pixmo-Points: A point-annotation dataset for training precise spatial localization. "For precise point localization, we integrate multiple datasets, including the Pixmo-Points dataset~\cite{pixmo2024}"
- Point QA: A VQA-style format focusing on predicting specific 2D points that ground language to locations. "Point QA. For precise point localization, we integrate multiple datasets, including the Pixmo-Points dataset~\cite{pixmo2024}, the RoboPoint dataset~\cite{yuan2024robopoint}, the RefSpatial dataset~\cite{zhou2025roborefer}, and a point subset extracted from the InternData-M1 dataset"
- Projection-space Similarity (PSS): A measure of alignment between gradient subspaces of different training objectives. "we compute the Projection-space Similarity (PSS)~\cite{raghu2017svcca} using Singular Value Decomposition (SVD)."
- Qwen2.5-VL-3B-Instruct: A multimodal vision-LLM used as the planner’s encoder. "InternVLA-M1\ employs the Qwen2.5-VL-3B-instruct~\cite{qwen25vl} as the multimodal encoder for System 2, which is to capture spatial priors."
- Query tokens: Learnable tokens that attend to backbone representations to extract task-relevant features. "mapping variable-length input tokens into a fixed set of learnable query tokens."
- Querying transformer: A lightweight transformer that converts planner embeddings into fixed query tokens for the action expert. "we adopt a lightweight querying transformer (8.7 MB) conditioned on the latent planning embeddings produced by the VLM Planner."
- RefCOCO: A referring expressions dataset for grounding language to image regions via bounding boxes. "We curate a diverse collection of multimodal grounding datasets, including RefCOCO~\cite{yu2016modeling, mao2016generation}, ASv2~\cite{wang2024all}, and COCO-ReM~\cite{singh2024benchmarking}"
- RoboPoint: A dataset emphasizing point-level grounding for robot-centric spatial tasks. "the RoboPoint dataset~\cite{yuan2024robopoint}"
- RoboRefIt: A robotics-focused dataset for language-to-vision grounding tailored to manipulation. "and the RoboRefIt dataset~\cite{vlgrasp}, a specialized dataset for robotics grounding"
- Scene graph solver: A component that constructs and validates spatial layouts and relations between objects in simulation. "the system rapidly generates scene layouts via a scene graph solver and computes candidate grasps based on object meshes"
- Spatial grounding: Aligning linguistic instructions with concrete locations or regions in visual inputs. "Stage 1 (spatial grounding pre-training): the VLM is trained on large-scale multisource multimodal spatial grounding data to learn embodiment-agnostic spatial priors."
- Spatial prompting: Adding auxiliary spatial cues to the instruction to elicit structured spatial reasoning in the planner. "Spatial prompting. Before predicting actions, we prepend a spatial cue to the task instruction to elicit structured reasoning about object relationships and task constraints."
- Spatial priors: Prior knowledge about spatial relationships, object locations, and trajectories that generalizes across tasks. "Core spatial priors such as object recognition, affordance grounding, visual trajectory reasoning, relative localization, and scaling provide transferable knowledge across robotic platforms."
- System 1 controller: The fast, reactive control module that executes actions using the planner’s guidance. "to execute as a fast System 1 controller."
- System 2 reasoner: The slow, deliberative planner that performs high-level spatial and task reasoning. "functioning as a slow but reliable System 2 reasoner"
- Teleoperated datasets: Collections of robot demonstrations operated by humans, used for supervised policy learning. "Teleoperated datasets~\cite{open_x_embodiment, bu2025agibot, wu2024robomind, khazatsky2024droid} provide valuable supervision"
- Trajectory MAE: Mean Absolute Error metric applied to predicted trajectories versus reference waypoints. "A0-maniskill~\cite{gu2023maniskill2} (evaluated using trajectory MAE, measuring mean absolute error between predicted and reference waypoints)."
- Variant Aggregations (VA): A SimplerEnv task set evaluating robustness under variations in textures and colors. "Variant Aggregations (VA)"
- Visual Matching (VM): A SimplerEnv task set evaluating matching under viewpoint and lighting changes. "Google Robot-VM (visual matching under viewpoint and lighting changes)"
- Visionâlanguage alignment: Learning correspondence between images and text representations at scale. "Large multimodal foundation models~\cite{llavaov, chen2024internvl, bai2025qwen2, clip, siglip} have demonstrated strong generalization by leveraging web-scale visionâlanguage alignment and instruction-following corpora."
- Vision-LLMs (VLM): Models that process and integrate visual and textual inputs for reasoning. "visionâLLMs (VLMs)"
- Visionâlanguageâaction (VLA): Frameworks that connect visual and linguistic understanding to action generation. "We propose {InternVLA-M1}, a dual-system, end-to-end visionâlanguageâaction (VLA) framework."
- Visual Question Answering (VQA): Tasks where models answer natural-language questions about images. "including image captioning, visual question answering (VQA), optical character recognition (OCR), knowledge grounding, and creative writing"
- Where2Place: A benchmark evaluating point predictions for placing objects in feasible free space. "Where2Place~\cite{yuan2024robopoint} (evaluated by accuracy of predicted points with respect to ground-truth free space)"
Collections
Sign up for free to add this paper to one or more collections.