A Systematic Study of Data Modalities and Strategies for Co-training Large Behavior Models for Robot Manipulation
Abstract: Large behavior models have shown strong dexterous manipulation capabilities by extending imitation learning to large-scale training on multi-task robot data, yet their generalization remains limited by the insufficient robot data coverage. To expand this coverage without costly additional data collection, recent work relies on co-training: jointly learning from target robot data and heterogeneous data modalities. However, how different co-training data modalities and strategies affect policy performance remains poorly understood. We present a large-scale empirical study examining five co-training data modalities: standard vision-language data, dense language annotations for robot trajectories, cross-embodiment robot data, human videos, and discrete robot action tokens across single- and multi-phase training strategies. Our study leverages 4,000 hours of robot and human manipulation data and 50M vision-language samples to train vision-language-action policies. We evaluate 89 policies over 58,000 simulation rollouts and 2,835 real-world rollouts. Our results show that co-training with forms of vision-language and cross-embodiment robot data substantially improves generalization to distribution shifts, unseen tasks, and language following, while discrete action token variants yield no significant benefits. Combining effective modalities produces cumulative gains and enables rapid adaptation to unseen long-horizon dexterous tasks via fine-tuning. Training exclusively on robot data degrades the visiolinguistic understanding of the vision-LLM backbone, while co-training with effective modalities restores these capabilities. Explicitly conditioning action generation on chain-of-thought traces learned from co-training data does not improve performance in our simulation benchmark. Together, these results provide practical guidance for building scalable generalist robot policies.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how to train smart robot “brains” that can see, read, and act to do many different hand-and-arm tasks (like picking up objects, pouring, or packing). These models are called Large Behavior Models (LBMs). The big idea is “co-training”: teaching the robot using its own action data plus other kinds of data (like pictures, text, and videos) without collecting tons more robot demonstrations. The authors test different kinds of extra data and training strategies to find what really helps robots handle new situations and follow natural language instructions.
What questions the paper asks
The researchers ask three main questions in simple terms:
- If we mix robot data with different kinds of extra data, which kinds help the robot work better when things change (new tasks, new objects, different lighting, etc.)?
- Does using several helpful data sources together make the robot even better?
- Does co-training create stronger “understanding” inside the model so it can quickly learn new, complicated tasks later with a bit of fine-tuning?
They also check two bonus ideas:
- Does co-training protect the model’s language-and-vision skills (so it still understands images and instructions well)?
- Does making the model explain its plan step-by-step (“chain-of-thought”) before acting actually improve performance?
How they did the study (in everyday language)
Think of the robot model like this:
- The “eyes and reading” part (a pretrained vision-LLM, or VLM) looks at images and reads instructions.
- The “muscles” part (an Action Flow Transformer) turns that understanding into movements for the robot.
They train this model in two ways:
- For continuous movements (like arm positions), they use “flow matching,” which is a method that teaches the model to transform a noisy, blurred version of the action into the clean, correct movement—like learning to unblur a motion path smoothly.
- For discrete tokens (like words or simplified action codes), they use regular next-token prediction (cross-entropy), the same way LLMs learn to predict the next word.
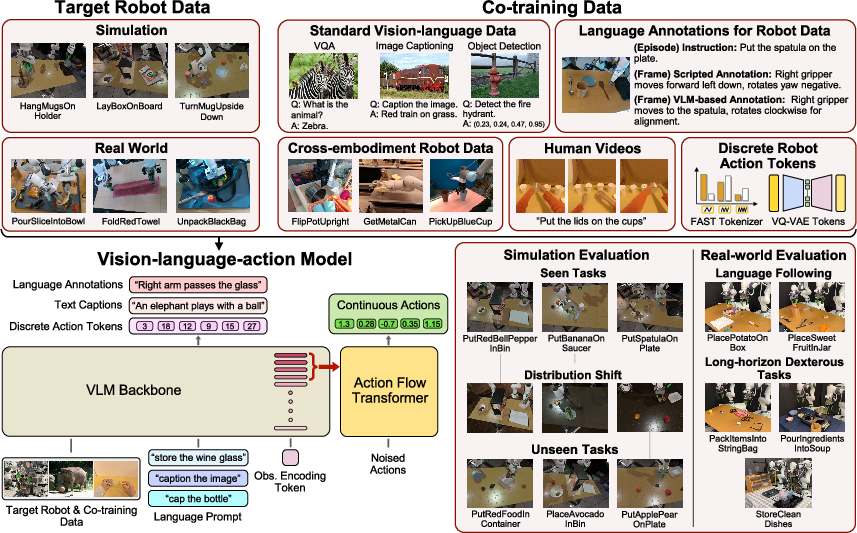
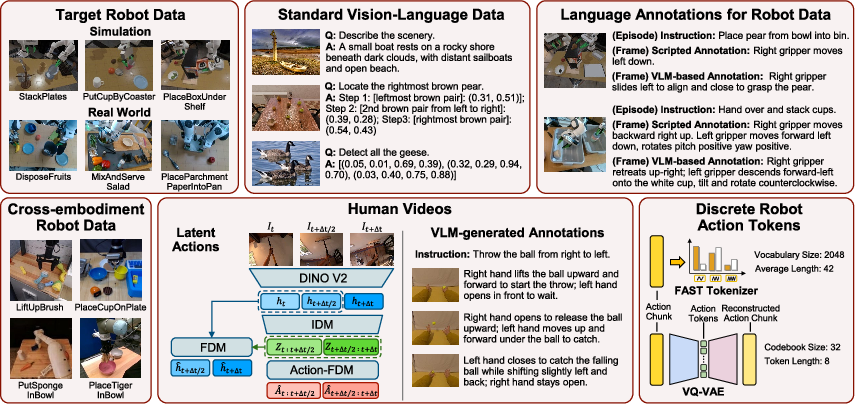
They try five kinds of co-training data:
- Standard vision-language data: big sets of images with questions and answers, spatial reasoning, and object pointing—teaching common sense and 3D understanding.
- Dense language annotations for robot demos: short, step-by-step descriptions of what the robot is doing (made two ways: scripted rules and generated by a powerful VLM).
- Cross-embodiment robot data: demonstrations from many different robots and environments—teaching broadly useful manipulation patterns.
- Human videos: egocentric videos of people handling objects, used two ways:
- Latent action tokens (a compressed, discrete representation of motion from videos).
- VLM-generated motion descriptions for each video frame (language annotations of human hand actions).
- Discrete robot action tokens: turning robot actions into compact “codes” (using FAST or VQ-VAE) to see if abstracting actions helps generalization.
They test three training strategies:
- Single-phase co-training: train on target robot data and extra data together at once.
- Two-phase 1st-phase-only: first train on extra data, then specialize on target robot actions only.
- Two-phase full: first train on extra data, then continue training on both robot actions and extra data.
They run a very large evaluation:
- Data scale: about 4,000 hours of robot/human manipulation data plus 50 million vision–language samples.
- Models: 89 different policies tested.
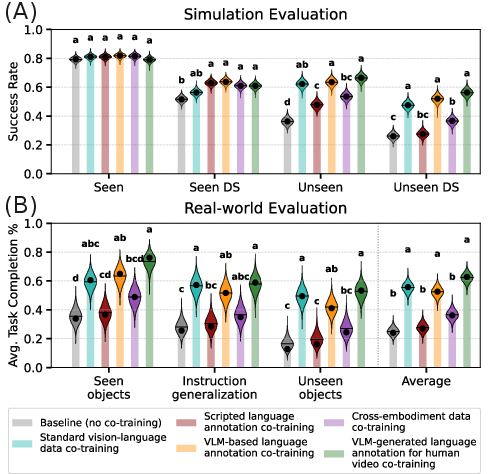
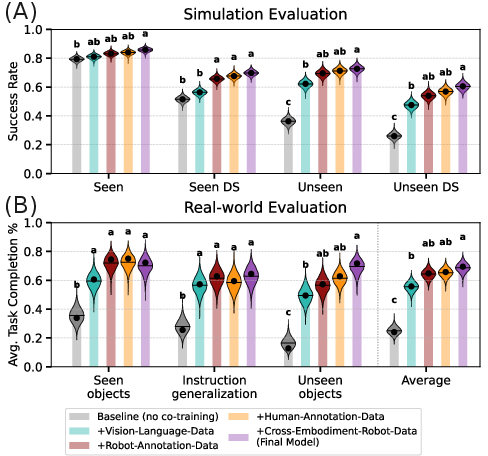
- Simulation: 58,000 rollouts on seen and unseen tasks, in normal and distribution-shifted conditions (lighting, textures, camera changes).
- Real robots: 2,835 rollouts testing language following and long, complex tasks fine-tuned with 200 demos each.
What they found and why it matters
Big takeaways (in plain terms):
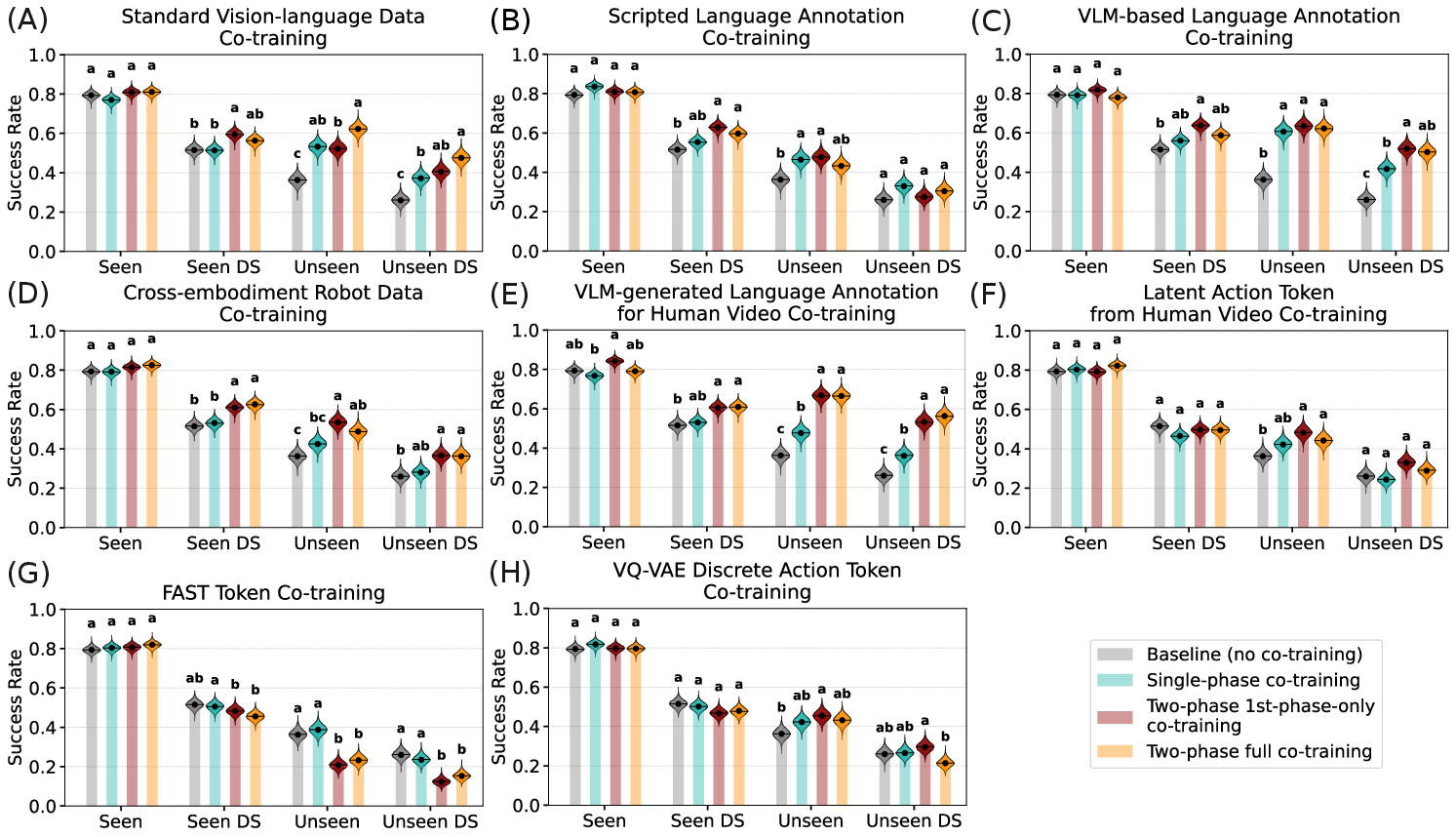
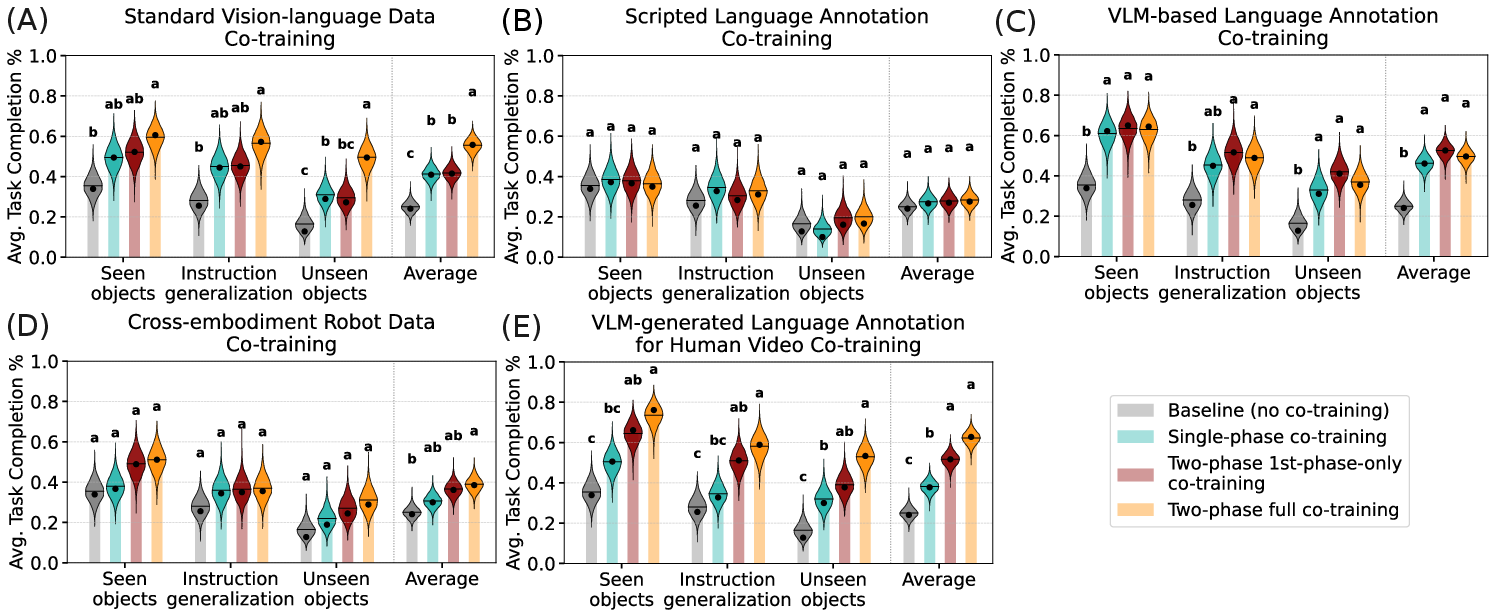
- Vision-language and cross-robot data help a lot: Mixing in standard VL data and cross-embodiment robot data consistently makes the robot better at handling new tasks, changes in appearance (like different lighting or distractors), and following varied language instructions. Training only on robot actions doesn’t hurt performance on known tasks, but it doesn’t prepare the model as well for surprises.
- Language annotations are powerful: Adding rich, frame-level language descriptions—both for robot demos and for human videos—boosts generalization. The VLM-generated descriptions (more diverse and context-aware) help more than simple scripted text.
- Discrete action tokens didn’t help (here): Converting actions to compact tokens (FAST, VQ-VAE) or using latent actions from videos did not give meaningful gains at this scale. FAST tokens even reduced generalization to new tasks. Latent actions helped only when there was very little robot data; as robot data grew, their benefit faded.
- Combining the good stuff compounds gains: Using several effective modalities together (standard VL data + robot language annotations + human video annotations + cross-embodiment robot data) gave consistent, cumulative improvements. Their final combined model reached about 72.6% success on unseen simulation tasks (up ~36.4% over the baseline) and ~69.4% average task completion for real-world language following (up ~45.3%).
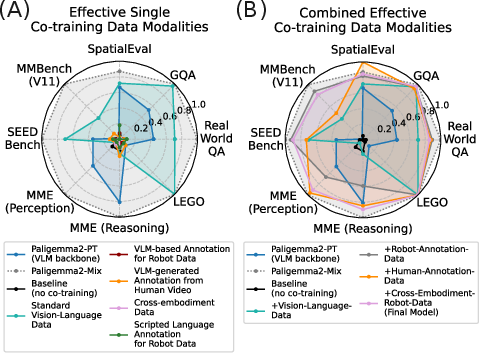
- Protecting the model’s “world understanding”: Training only on robot action data can weaken the VLM’s general vision-language skills. Co-training with effective modalities preserves and restores those skills, which shows up in standard vision-language benchmarks and in better robot policies.
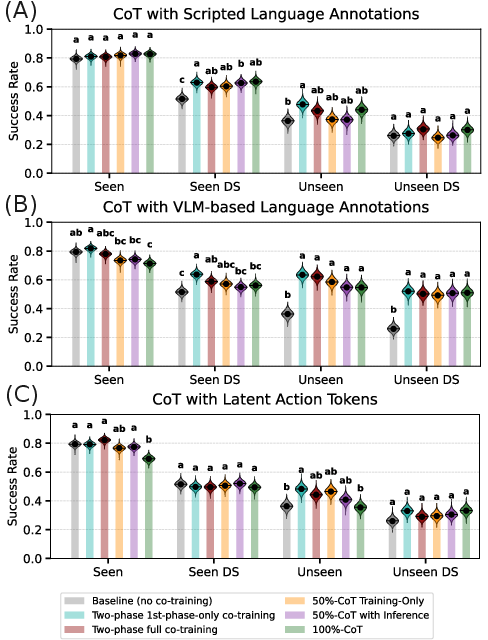
- Chain-of-thought didn’t help in this setup: Making the model output a step-by-step textual plan before generating actions did not improve performance in their simulation tests.
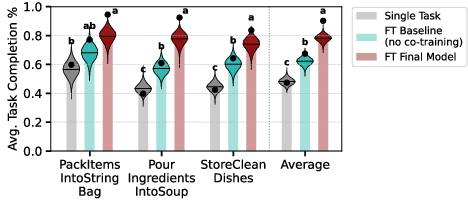
- Fine-tuning on long tasks is faster with co-training: Models trained with effective co-training adapted more efficiently to unseen, long-horizon dexterous tasks after fine-tuning with 200 demonstrations.
What this means going forward
This study gives practical guidance for building generalist robot policies:
- Mix in rich vision-language data and diverse robot experiences to boost generalization. It’s a strong way to fill the “data gap” without collecting huge amounts of new robot demos.
- Use language annotations (especially VLM-generated) to align actions with clear, flexible semantics—this improves language following and transfer to unseen objects and tasks.
- Don’t expect discrete action tokens to help by default; their usefulness may depend on much larger datasets or different setups.
- Keep co-training during later phases when the extra data brings knowledge the robot dataset doesn’t have (like diverse objects and environments in human videos). It helps avoid “forgetting” and keeps the model’s world understanding sharp.
- With better pretraining, robots can be fine-tuned quickly for new, complex jobs, making real-world deployment more efficient.
In short, co-training with the right kinds of data makes robot models smarter, more adaptable, and better at understanding both images and instructions—so they can handle new tasks and environments with less additional training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that emerge from the paper’s design choices, datasets, analyses, and evaluations. Each point is framed to be directly actionable for follow-up research.
- Generality across architectures:
- The study uses a single VLM backbone (PaliGemma2-3B-PT) and a single Action Flow Transformer head. It remains unknown whether conclusions about modality effectiveness and training strategies hold for larger/backbone-diverse VLMs (e.g., GPT-4o/4.1, Gemini 2.0, Qwen2-VL) or alternative action heads (autoregressive, hybrid continuous–discrete, diffusion variants) and control parameterizations (e.g., joint-space, impedance).
- Training objective design:
- Flow matching is the only continuous-action objective tested. The impact of alternative objectives (e.g., denoising diffusion, direct supervised regression with temporal consistency losses, policy parameterization via normalizing flows, auxiliary self-supervised objectives) on co-training effectiveness is not explored.
- Curriculum and weighting:
- Loss weights, masks, and batch ratios are “fixed based on ablations” but the paper does not expose a principled or adaptive curriculum. How to automatically schedule modalities across phases (e.g., bandit-based sampling, uncertainty-aware mixing, dynamic reweighting by gradient conflict measures) is unaddressed.
- Scale laws and data efficiency:
- No scaling-law analysis ties performance gains to data quantity/quality across modalities. It is unclear whether improvements follow predictable power-law trends, saturate at current scales (~4,000 hours robot/human + 50M VL), or require orders-of-magnitude more data.
- Negative results for discrete tokens:
- The study tests FAST and VQ-VAE tokens and finds limited or negative effects, but it does not exhaust the design space. Open questions include: can hierarchical tokenizations (skills/options), hybrid sequence–continuous heads, or task-conditioned codebooks avoid the observed generalization degradation? What token granularities/vocab sizes maximize transfer while minimizing overfitting to precise action mappings?
- Latent actions from human videos:
- Benefits only appear in low target-robot-data regimes and vanish at scale. It remains unclear whether improved embodiment alignment (e.g., spatial calibration beyond a reference triad, hand pose estimation mapped to EE frames, inverse dynamics priors) or richer temporal models (longer context windows, causal reasoning about contact events) would make latent action pretraining reliably useful.
- Human video modality breadth:
- Only egocentric human videos are used. The contribution of exocentric views, multi-view human datasets, or robot-perspective synthetic humans (rendered with the robot’s cameras) to transferable action representations is not studied.
- Chain-of-thought (CoT) conditioning:
- The explicit CoT approach is evaluated on a single simulation benchmark and one CoT training scheme. It is unknown whether structured plans (e.g., graphs/constraints), tool-augmented CoT (retrieval, programmatic checkers), or different conditioning probabilities p improve action grounding. Real-world CoT evaluation is absent.
- Representation–performance link:
- The paper reports that co-training preserves/recovers VLM visiolinguistic ability (benchmarked in appendix), but does not quantify how specific benchmark subskills (spatial grounding, compositional reasoning, counting, referring expressions) correlate with policy gains. Establishing causal/predictive links would guide dataset curation.
- Catastrophic forgetting and specialization:
- The study notes erosion of visiolinguistic understanding when training solely on robot data. However, it does not map the forgetting dynamics (which layers/capabilities degrade, how fast, under what mixtures) nor test mitigation techniques (e.g., elastic weight consolidation, L2-SP, adapter isolation, replay buffers with VL data).
- Language coverage:
- All experiments use English instructions. Multilingual co-training, code-switching, and cross-lingual transfer (e.g., instruction following in low-resource languages) are not evaluated.
- Sensory modality gaps:
- Co-training only uses vision and language. The effect of adding tactile/force/torque/audio streams (and their language annotations) on robustness, contact-rich manipulation, and long-horizon planning is unknown.
- Distribution shifts and robustness scope:
- DS tests primarily involve appearance changes (lighting, textures, distractors, camera settings). Unexplored DS dimensions include physical/dynamics shifts (mass/friction variations), severe occlusions, clutter densities, deformable/transparent objects, and tool-use domain shifts.
- Embodiment generalization at inference:
- Cross-embodiment data improves target-embodiment generalization, but zero-shot deployment on non-target robots is not evaluated. Can a single policy co-trained as described operate across arms/grippers without fine-tuning (or with minimal adaptation), and what mappings are required?
- Long-horizon generalization without heavy fine-tuning:
- Real-world dexterous tasks require ~200 demonstrations per task. Few-shot (e.g., 1–10 demos), instruction-only, or plan-conditioned adaptation is not studied. Sample efficiency limits and the role of co-training in reducing demonstrations remain open.
- Failure-mode analysis:
- The paper reports aggregate performance but lacks a granular taxonomy of failures (perception errors, grounding mistakes, mislocalized grasps, planning/order errors, recovery issues). A detailed error analysis could identify which modalities address which failure types.
- Annotation quality and cost:
- Dense language annotations rely on GPT-5 and heuristic scripts; their noise profiles, biases, and cost–benefit tradeoffs are not quantified. It is unknown how cheaper models, synthetic captions, or human-in-the-loop QA impact transfer and whether active curation (selective re-annotation) improves returns.
- Data mixture confounds:
- Although a compute-rich ablation is provided for latent/VQ tokens, broader confounds remain: equalization of training steps, optimizer states, learning rate schedules, and freezing strategies across modalities is not fully controlled. A stricter accounting would isolate genuine signal vs. extra compute.
- Real-time and system constraints:
- Inference latency, throughput, and memory footprint under real robot control are not reported. Whether co-training introduces unacceptable delays or instability in closed-loop control is unknown.
- Safety and reliability:
- The work does not analyze safety, collision avoidance, failure recovery, nor robustness to sensor glitches or calibration drift. Co-training’s impact on safe exploration and error escalation remains unexplored.
- Reproducibility and openness:
- Key datasets (TRI Target-Ramen, curated OXE subset, human video annotations) and exact training recipes may be proprietary or partially unavailable. Without public releases, independent validation of the co-training claims remains difficult.
- Ethical and bias considerations:
- Potential biases introduced by internet VL data and VLM-generated annotations (e.g., object category stereotypes, cultural/linguistic skew) are not audited. The downstream effects on task selection and failure behavior in diverse environments are unknown.
Practical Applications
Immediate Applications
Below are concrete, deployable ways to apply the paper’s findings across sectors. Each item lists the sector(s), a suggested tool/product/workflow, and feasibility notes.
- [Robotics, Software/AI Platforms] Adopt two-phase co-training recipes to improve generalization and language following in manipulation policies
- What to do now:
- Phase 1: Pretrain with standard vision–language (VL) datasets (e.g., spatial reasoning, grounding) plus cross-embodiment robot data; optionally add dense language annotations for target-robot trajectories (scripted + VLM-based).
- Phase 2: Continue training on target-robot continuous actions while maintaining VL and human-video language annotation co-training to prevent visiolinguistic forgetting.
- Tools/products/workflows:
- “VL Infusion” pretraining module for VLA backbones.
- Co-training scheduler that implements single- vs multi-phase compositions.
- Action Flow Transformer + flow matching training template.
- Assumptions/dependencies:
- Access to VL corpora emphasizing spatial reasoning (e.g., RoboPoint, RefSpatial).
- Cross-embodiment datasets (e.g., Open X-Embodiment subsets).
- Compute capacity for multi-phase training on 3B-class VLM backbones.
- [Logistics, Manufacturing, Retail] Improve manipulation robustness to distribution shifts (lighting, textures, layouts) and unseen tasks
- What to do now:
- Integrate standard VL and cross-embodiment co-training into existing pick-and-place and kitting pipelines to handle varied SKUs, packaging, and workstation changes.
- Tools/products/workflows:
- “DS Robustness Benchmark Suite” mirroring the paper’s DS tests.
- Pretrained “Language-Guided Manipulation Pack” for packing, sorting, bin picking.
- Assumptions/dependencies:
- Calibrated camera pipelines and stable perception input quality.
- Inference safety interlocks for high-variance test conditions.
- [Home Service Robotics, Consumer Devices] Enable language-following and unseen-object handling in household tasks
- What to do now:
- Deploy co-trained VLAs with VL + human-video language annotations to support instructions like “put the writing tools in the cup” or “place the glass next to the bowl,” generalizing beyond trained object sets.
- Tools/products/workflows:
- “Household Language Command Library” with paraphrase-robust intents.
- Routine-specific fine-tuning kits (e.g., dish-stowing, laundry sorting).
- Assumptions/dependencies:
- Onboard or edge compute for VLM inference.
- Home environment variability (camera placement, clutter) managed via DS-tuned policies.
- [Healthcare, Assistive Robotics] Faster personalization for Activities of Daily Living (ADLs)
- What to do now:
- Fine-tune the co-trained base model with ~200 demonstrations for new long-horizon tasks (e.g., preparing a tray, organizing medical supplies), leveraging the paper’s rapid adaptation result.
- Tools/products/workflows:
- “Rapid Dexterity Fine-tuning Kit” with data capture, rubric-based QA, and rollout evaluation.
- Assumptions/dependencies:
- Strong safety protocols, fail-safes, and clinician oversight.
- Patient privacy and HIPAA-compliant data collection.
- [Academia, Research Labs] Standardize data pipelines and evaluation to accelerate reproducible robot learning
- What to do now:
- Implement dense language annotation pipelines for robot trajectories (scripted + VLM-generated), and use human videos with VLM annotations as an auxiliary VL modality.
- Replicate the paper’s statistical analysis (CLD, Bayesian uncertainty) and DS benchmarks.
- Tools/products/workflows:
- Open-source “Dense Annotation Service” for per-frame action captions.
- Evaluation harness with seen/unseen tasks and rubric-based real-world scoring.
- Assumptions/dependencies:
- Licenses and governance for using human video datasets.
- Reviewer/curator time for rubric QA and annotation quality checks.
- [Software/MLOps, Robotics Vendors] Preserve visiolinguistic capability during policy training
- What to do now:
- Monitor VLM backbone capabilities with standard VL, spatial, and multimodal reasoning benchmarks before/after each phase; avoid training exclusively on robot data to prevent degradation.
- Tools/products/workflows:
- “VLM Capability Monitor” integrated into CI for training runs.
- Assumptions/dependencies:
- Benchmark alignment with target tasks; periodic recalibration of metrics.
- [Product Strategy, R&D Management] Prioritize effective co-training modalities; de-emphasize discrete action tokenization in high-data regimes
- What to do now:
- Focus on standard VL, cross-embodiment robot data, and VLM-based annotations (robot trajectories + human videos).
- Avoid FAST/VQ-VAE token co-training unless in severely low robot-data regimes; latent actions only help when robot data is scarce.
- Tools/products/workflows:
- Portfolio allocation dashboards tracking performance per modality and cost.
- Assumptions/dependencies:
- Access to cross-embodiment data; robust VLM annotation quality.
- [Policy & Governance, Compliance] Establish governance for human-video use in co-training
- What to do now:
- Create consent, licensing, and de-identification checklists for egocentric video usage; document provenance in model cards.
- Tools/products/workflows:
- “Data Provenance & Consent Tracker” for co-training assets.
- Assumptions/dependencies:
- Institutional review, jurisdictional legal constraints, dataset-specific T&Cs.
- [Education, Workforce Development] Curricula and capstone projects on co-training for generalist robot policies
- What to do now:
- Teach two-phase co-training patterns, flow matching for continuous control, and negative results (e.g., explicit CoT conditioning not helping in this benchmark).
- Tools/products/workflows:
- Lab-in-a-box courseware with curated data, training configs, and DS tests.
- Assumptions/dependencies:
- Compute quotas for students; faculty support for dataset ethics modules.
- [Testing/QA, Safety Engineering] Robustness and long-horizon evaluation as a deployment gate
- What to do now:
- Adopt the paper’s DS scenarios and long-horizon task rubrics as part of pre-deployment acceptance testing.
- Tools/products/workflows:
- “Robotics Reliability Dashboard” aggregating DS success rates and task completion scores.
- Assumptions/dependencies:
- Testbed availability; alignment of rubrics with operational risks.
Long-Term Applications
These applications are feasible with further research, scaling, or ecosystem development.
- [Robotics Ecosystem, Standardization Bodies] Cross-embodiment generalist policies and shared data standards
- Opportunity:
- Vendor-agnostic policies that transfer across robot morphologies with minimal adaptation; standardized schemas for co-training data (VL + robot + human video annotations).
- Tools/products/workflows:
- “Cross-Embodiment Data Lake” consortium; open annotation ontologies for spatial reasoning and action semantics.
- Assumptions/dependencies:
- Broad industry participation; IP/data-sharing frameworks; interoperability from sensors to action spaces.
- [Consumer Robotics, Smart Home] Continual learning at the edge without forgetting language and spatial reasoning
- Opportunity:
- On-device or on-robot continual co-training with scheduled VL refresh to prevent visiolinguistic drift while adapting to user-specific homes.
- Tools/products/workflows:
- “On-Device Co-training Scheduler” balancing robot data with periodic VL refresher episodes.
- Assumptions/dependencies:
- Efficient VLM/VLA distillation or sparse updates; privacy-preserving data handling.
- [Healthcare, Elder Care] Personalized long-horizon assistance with minimal demonstrations
- Opportunity:
- Rapidly configure multi-step care routines (e.g., meal prep, medication organization) with small curated demo sets plus strong VL co-training priors.
- Tools/products/workflows:
- Clinician-in-the-loop programming interfaces that convert care protocols into language + demonstration bundles.
- Assumptions/dependencies:
- Regulatory approvals; rigorous validation; fail-safe dexterous manipulation under safety constraints.
- [Autonomous Warehousing, Flexible Manufacturing] Zero- or few-shot adaptation to new SKUs and fixtures
- Opportunity:
- Exploit VL and cross-embodiment co-training to handle frequent reconfigurations with near-zero downtime.
- Tools/products/workflows:
- “SKU Onboarding Workflow” that uses VL prompts and a handful of demos to deploy new manipulations on multiple robot types.
- Assumptions/dependencies:
- High-fidelity perception; closed-loop recovery behaviors for long-horizon tasks.
- [Public Policy, Regulation] Governance frameworks for foundation robot models trained on human videos
- Opportunity:
- Standards for consent, bias assessment, and safety auditing specific to embodied foundation models.
- Tools/products/workflows:
- Audit toolkits that track data sources, annotation methods, and robustness to distribution shifts.
- Assumptions/dependencies:
- Multi-stakeholder agreements; harmonization across jurisdictions.
- [Research, Multimodal AI] Expanding co-training beyond vision–language to tactile/force and audio
- Opportunity:
- Incorporate haptics and force signals into co-training to improve dexterity and contact-rich tasks; integrate audio cues (e.g., pouring, snapping).
- Tools/products/workflows:
- “Multisensory Co-training Suite” with synchronized tactile/force, audio, and VL annotations.
- Assumptions/dependencies:
- New sensors and synchronized data capture; learning objectives that blend flows across modalities.
- [Planning & Reasoning, LLM Integration] Revisit chain-of-thought (CoT) for planning–acting interfaces
- Opportunity:
- Although explicit CoT conditioning did not help here, future architectures may combine higher-level planning CoT (LLM) with low-level action generation (ActionFT) through better interfaces and training curricula.
- Tools/products/workflows:
- Hierarchical planners that serialize plans into compact, action-groundable traces fed to the action head.
- Assumptions/dependencies:
- More reliable plan grounding; datasets that link plans to action outcomes.
- [Sustainability, Cost Engineering] Compute- and data-efficient co-training policies
- Opportunity:
- Optimize co-training to maximize gain-per-compute by prioritizing modalities shown to yield the largest returns (standard VL, VLM-based annotations, cross-embodiment), with dynamic curricula.
- Tools/products/workflows:
- Auto-curriculum schedulers that tune phase lengths and data ratios based on validation gains.
- Assumptions/dependencies:
- Predictive metrics for generalization; MLOps for adaptive training.
- [Education at Scale] Shared benchmarks and open “co-training-ready” corpora for global robotics labs
- Opportunity:
- Globalized curricula where students train generalist policies using standardized VL + cross-embodiment datasets and robust DS benchmarks.
- Tools/products/workflows:
- Cloud-hosted training sandboxes with fair-use datasets and reproducible configs.
- Assumptions/dependencies:
- Funding for shared compute; clear licenses for educational use.
- [Data Services, Tooling Vendors] Commercial annotation and curation offerings
- Opportunity:
- Provide turnkey services for dense robot trajectory annotations and human-video action captions optimized for VLAs.
- Tools/products/workflows:
- API-based “VL Annotation Service” with QA dashboards and spatial reasoning templates.
- Assumptions/dependencies:
- Stable VLM APIs/models; cost-effective QA for scale.
Notes on cross-cutting dependencies and caveats:
- Compute and data scale matter: the reported gains come from thousands of hours of data and millions of VL samples; benefits of certain modalities (e.g., latent actions) diminish as target robot data grows.
- Modality selection should be task- and resource-aware: discrete action token co-training (FAST/VQ-VAE) showed no improvements or even regressions at the reported scale; use sparingly in low-data regimes.
- Safety and evaluation are integral: adopt DS robustness tests and rubric-based long-horizon evaluations; track backbone VL capability to avoid catastrophic forgetting.
- Legal and ethical data use: human-video sources require clear consent, de-identification, and documentation of provenance.
Glossary
- Action chunk: A contiguous window of low-level robot actions treated as a single unit during training. "given an action chunk , a FM timestep , and sampled noise "
- Action Flow Transformer (ActionFT): The model’s action-generation head that predicts continuous robot actions conditioned on multimodal embeddings. "The ActionFT follows the diffusion transformer design introduced in~\cite{barreiros2025careful}."
- Bayesian uncertainty estimates: Quantitative measures of uncertainty derived from Bayesian analysis of model performance. "Bayesian uncertainty estimates are reported for individual strategies, with posterior uncertainty visualized as violin plots overlaid on bar charts."
- Chain-of-thought (CoT): Explicit intermediate reasoning traces produced by the model to guide subsequent action generation. "explicitly conditioning action generation on chain-of-thought traces learned from co-training data does not improve performance in our simulation benchmark."
- Codebook: The discrete set of embeddings used by vector-quantized models to represent inputs. "We compress action chunks into 8 discrete tokens with codebook size 32 using a VQ-VAE"
- Compact Letter Display (CLD): A multiple-comparison visualization that labels statistically indistinguishable groups with shared letters. "Compact Letter Display (CLD)~\cite{piepho2004algorithm} for comparison."
- Compositional generalization: The ability to recombine known skills or concepts to perform novel tasks. "compositional generalization (e.g., generalizing from training demonstrations of placing object A on C and object B on D to placing object A on D)."
- Cross-embodiment robot data: Demonstrations collected across different robot morphologies and setups used to learn generalizable behaviors. "cross-embodiment robot data, which encompasses manipulation demonstrations across varied robot morphologies and environments."
- Cross-entropy (CE) loss: A standard classification loss used for training discrete token predictions. "the model is optimized to minimize the cross-entropy (CE) loss between the ground-truth token sequence and the predicted logits "
- Diffusion transformer: A transformer architecture used to model and generate sequences within diffusion-style training frameworks. "The ActionFT follows the diffusion transformer design introduced in~\cite{barreiros2025careful}."
- Distribution shift (DS): Changes in the data distribution at test time, such as different lighting or textures, that challenge model robustness. "under nominal and distribution shift (DS) conditions"
- Drake: A robotics simulation and dynamics toolkit used to build the evaluation benchmark. "built on top of Drake~\cite{tedrake2019drake}."
- Egocentric human videos: First-person video recordings used to expose models to rich visual and action contexts. "Large-scale egocentric human videos that expose models to diverse visual contexts, object interactions, and motion patterns beyond robot trajectories."
- End effector: The robot manipulator’s tool (e.g., gripper) that interacts with objects. "These annotations capture the robot's end effector translational movement, rotational changes, and gripper state transitions."
- Family-wise error rate (FWER): The probability of making one or more false discoveries when performing multiple statistical tests. "Co-training strategies not sharing any CLD alphabet are significantly different in average performance at 5\% family-wise error rate (FWER)."
- FAST tokens: Near-lossless discrete encodings of continuous action sequences produced by the FAST tokenizer. "We employ FAST~\cite{pertsch2025fast} to convert continuous action chunks into a compressed, near-lossless sequence of discrete tokens."
- Flow matching (FM): A training objective that learns a vector field to transform noise into data for continuous action prediction. "the model is trained with flow matching (FM)~\cite{lipman2022flow, liu2022rectified} as the learning objective."
- Flow vector: The learned vector field that maps noised inputs toward data during flow matching. "where and are the ground-truth and predicted flow vector, respectively."
- Latent action tokens: Discrete tokens inferred from video frames that abstract human or robot motions. "extracting discrete latent action tokens from a sequence of frames;"
- Latent actions: Compact, learned representations of actions derived from visual sequences, used for co-training. "Latent action three-phase co-training: (i) train on latent actions from all video data, (ii) train on all robot data for continuous actions, and (iii) train on {TRI}{Target}-Ramen."
- Observation encoding token: A special token appended to the text that aggregates visiolinguistic context for action prediction. "we introduce a special observation encoding token into the backbone’s vocabulary"
- Open X-Embodiment: A large multi-robot dataset used to provide diverse manipulation demonstrations. "Open X-Embodiment dataset~\cite{o2024open}"
- Open-world generalization: The capability to handle novel, unconstrained scenarios not seen during training. "in semantic and spatial understanding and in open-world generalization."
- PaliGemma2-PT: A pretrained vision-language backbone model used as the policy’s multimodal encoder. "PaliGemma2-PT (google/paligemma2-3b-pt-224~\cite{steiner2024paligemma})."
- Posterior means: Expected values of performance metrics under the Bayesian posterior distribution. "Dots and horizontal lines indicate empirical and posterior means, respectively."
- Rollout: A full execution of a policy in simulation or the real world to assess performance. "58,000 simulation rollouts and 2,835 real-world rollouts."
- Spatial referring tasks: Tasks that require grounding and reasoning about spatial relationships and targeted locations. "Both datasets provide annotations tailored for spatial referring tasks"
- Vector quantization: A discretization technique mapping continuous inputs to entries in a finite codebook. "vector quantization-based methods (e.g., VQ-VAE~\cite{van2017neural})"
- Vision-language (VL) data: Multimodal datasets pairing images with text used to impart world knowledge and spatial reasoning. "standard vision-language data"
- Vision-language-action (VLA) models: Policies that integrate visual and textual inputs to generate robot actions. "vision-language-action models (VLAs)~\cite{kim2024openvla, zitkovich2023rt, driess2023palm, black2024pi0visionlanguageactionflowmodel,intelligence2025pi05visionlanguageactionmodelopenworld, team2025gemini, bjorck2025gr00t} are a representative subclass of LBMs that integrate visual and linguistic inputs for action generation."
- Vision-LLM (VLM) backbone: The multimodal encoder initialized from a pretrained VLM that provides representations for action prediction. "We adopt a VLA architecture (Fig.~\ref{fig:main_overview}) composed of a pretrained VLM backbone and a flow transformer action head (ActionFT)."
- Visiolinguistic embedding: A unified embedding that encodes both visual and textual context (and optionally CoT traces) for conditioning action generation. "the resulting visiolinguistic embedding (encoding images, task prompts, and CoT traces) is extracted to condition the ActionFT for continuous action prediction."
- VQ-VAE: Vector-Quantized Variational Autoencoder used to discretize continuous actions into compact tokens. "We compress action chunks into 8 discrete tokens with codebook size 32 using a VQ-VAE~\cite{van2017neural} on both {TRI}{Target}-Ramen and OXE-Ramen."
Collections
Sign up for free to add this paper to one or more collections.