- The paper demonstrates that a staged VLA training paradigm unifies multimodal data to enable robust robotic control across diverse embodiments.
- It outlines a five-stage curriculum integrating web-scale pretraining, extensive robotic demonstration data, and RL-based fine-tuning to boost long-horizon performance.
- Empirical results indicate significant improvements in task success rates and transferability, validating the framework's efficacy in complex, real-world robotics scenarios.
Green-VLA: Staged VLA Models for Generalist Robotics
Overview of the Green-VLA Paradigm
Green-VLA proposes a comprehensive, staged pipeline for training unified vision–language–action (VLA) models, targeting deployment on high-DoF humanoid robots but maintaining generalization across multiple robotic embodiments. The framework addresses deficits in heterogeneous data sources, multi-embodiment control unification, safe and instruction-faithful execution, and long-horizon policy robustness by integrating tightly curated data pipelines, architectural innovations, and RL-based alignment steps. At its core, Green-VLA’s model integrates web-scale vision-language grounding, large-scale robotics demonstrations across dozens of platforms, and staged embodiment-specific tuning and RL fine-tuning, establishing a practical blueprint for constructing robust generalist robotic controllers.
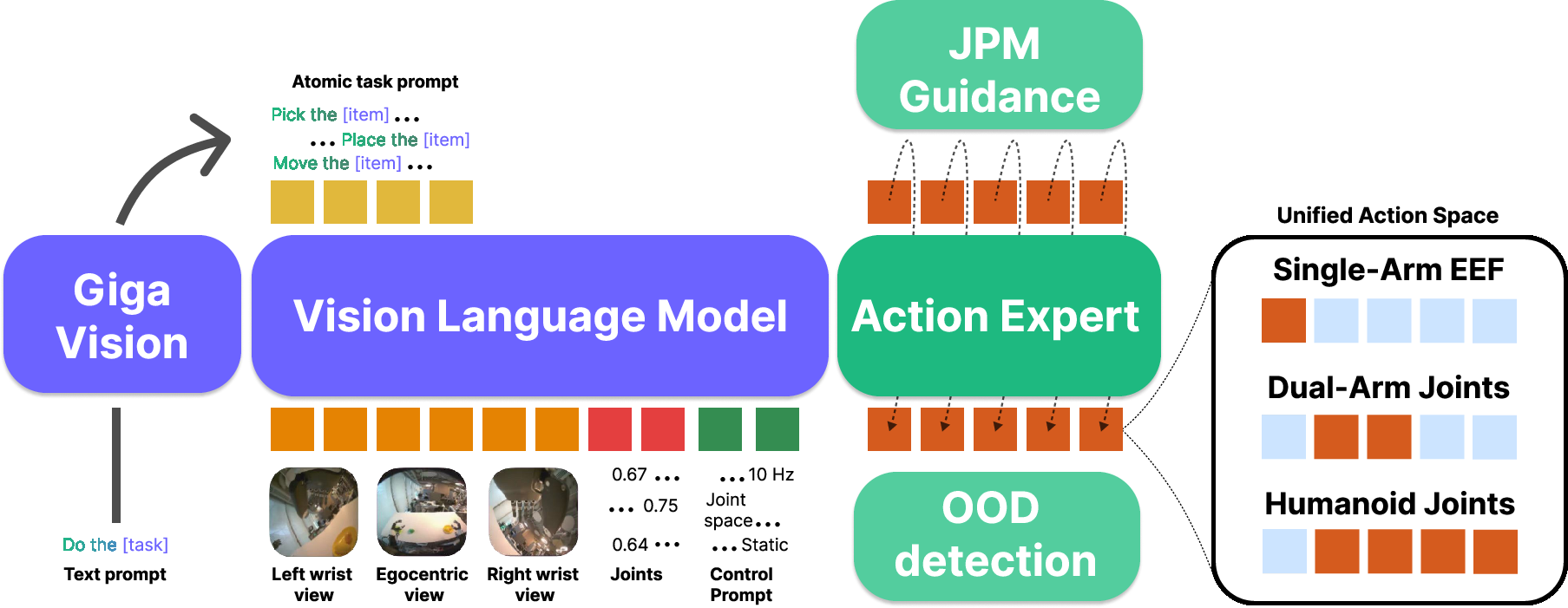
Figure 1: Green-VLA architecture. The model fuses multimodal natural language, visual, and proprioceptive input, leverages a high-level task planner for hierarchical decomposition and guidance, and interfaces with a flow-matching action expert within a unified action space.
Staged Curriculum: Data Grounding to RL Alignment
Green-VLA operationalizes a five-stage training protocol:
- L0 – Base VLM: Image/video–text pretraining, without robot-action supervision, builds fundamental visual–linguistic priors.
- L1 – Web/Multimodal Physical Understanding: Exposure to web-scale spatial VQA instills knowledge of object affordances and task semantics.
- R0 – Robotics Pretraining: Unified training across an extensive, temporally and semantically aligned corpus of robotic demonstrations, spanning multiple embodiments.
- R1 – Embodiment SFT: Fine-tuning on high-quality, embodiment-specific datasets using hyperparameter search and inference optimizations.
- R2 – RL Alignment: Offline and online RL methodologies (e.g., IQL-based Q-critics, actor-critic noise distribution optimization) further align policies to task rewards and recover from BC saturation, especially for long-horizon or contact-rich tasks.
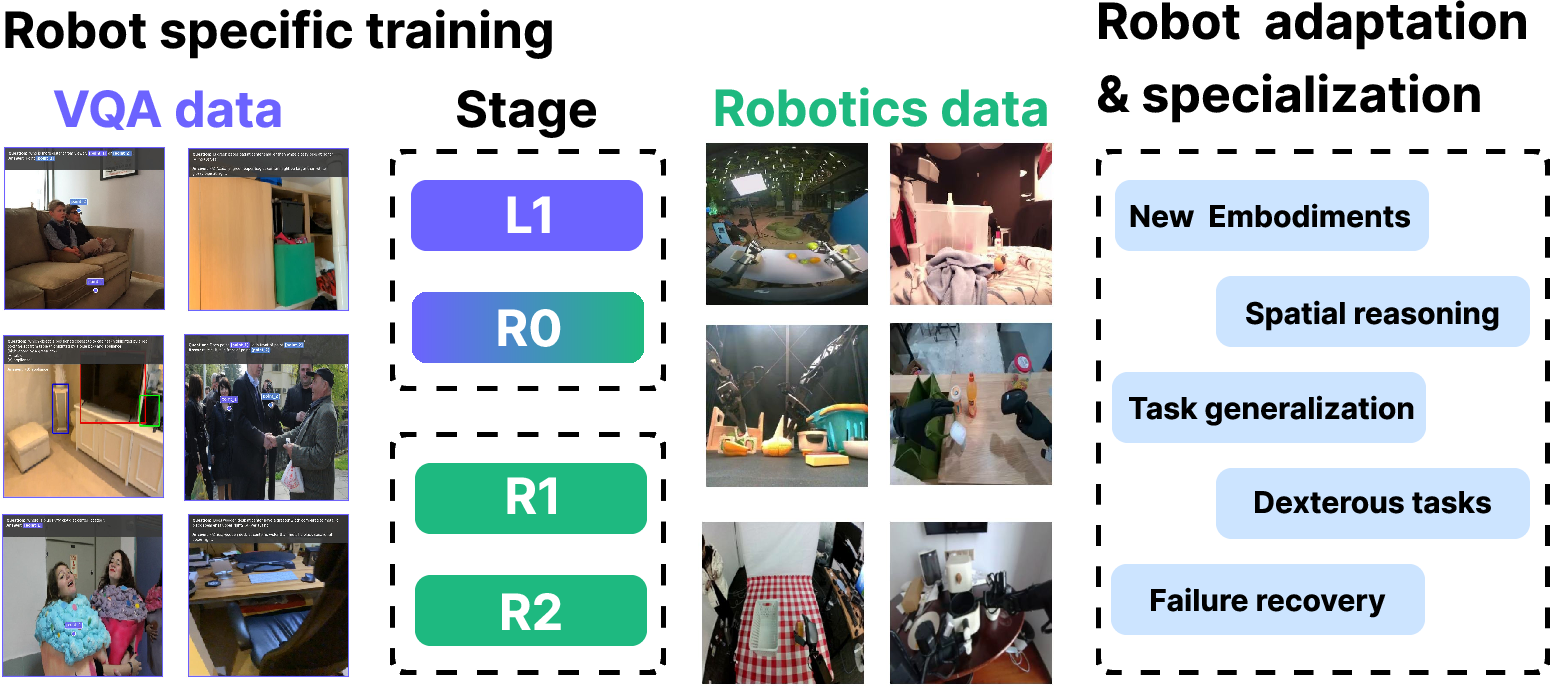
Figure 2: Green-VLA’s multi-stage process enables skill transfer, spatial reasoning, dexterous manipulation, and systematic failure recovery by leveraging staged multicorpus VQA and robotics data training.
Each stage is essential:
- Early multimodal grounding (L1) yields generalizable scene and object representations.
- Multi-embodiment R0 pretraining imbues affordance and manipulation priors transcending single-robot idiosyncrasies.
- Embodiment-specific R1 avoids catastrophic forgetting and adapts high-level skills to new kinematics and control modalities.
- RL-based R2 fine-tuning crucially improves long-horizon chain completion and recovers from out-of-distribution states.
Curated, Scalable Data Pipeline
Green-VLA’s data framework is anchored in a unified, quality-controlled pipeline. For robotics (R0) pretraining, the mixture corpus exceeds 3,000 hours of manipulation demonstrations from open-source and proprietary datasets (e.g., AgiBotWorld, DROID, Galaxea, ALOHA, Fractal, with extensive self-collected Green Humanoid data). The diverse stream includes dual- and single-arm, dexterous and simple grippers, and both mobile and fixed platforms. To increase sample efficiency, data augmentations via bilateral symmetry (mirroring) and time-reversal for reversible skills are systematically applied.
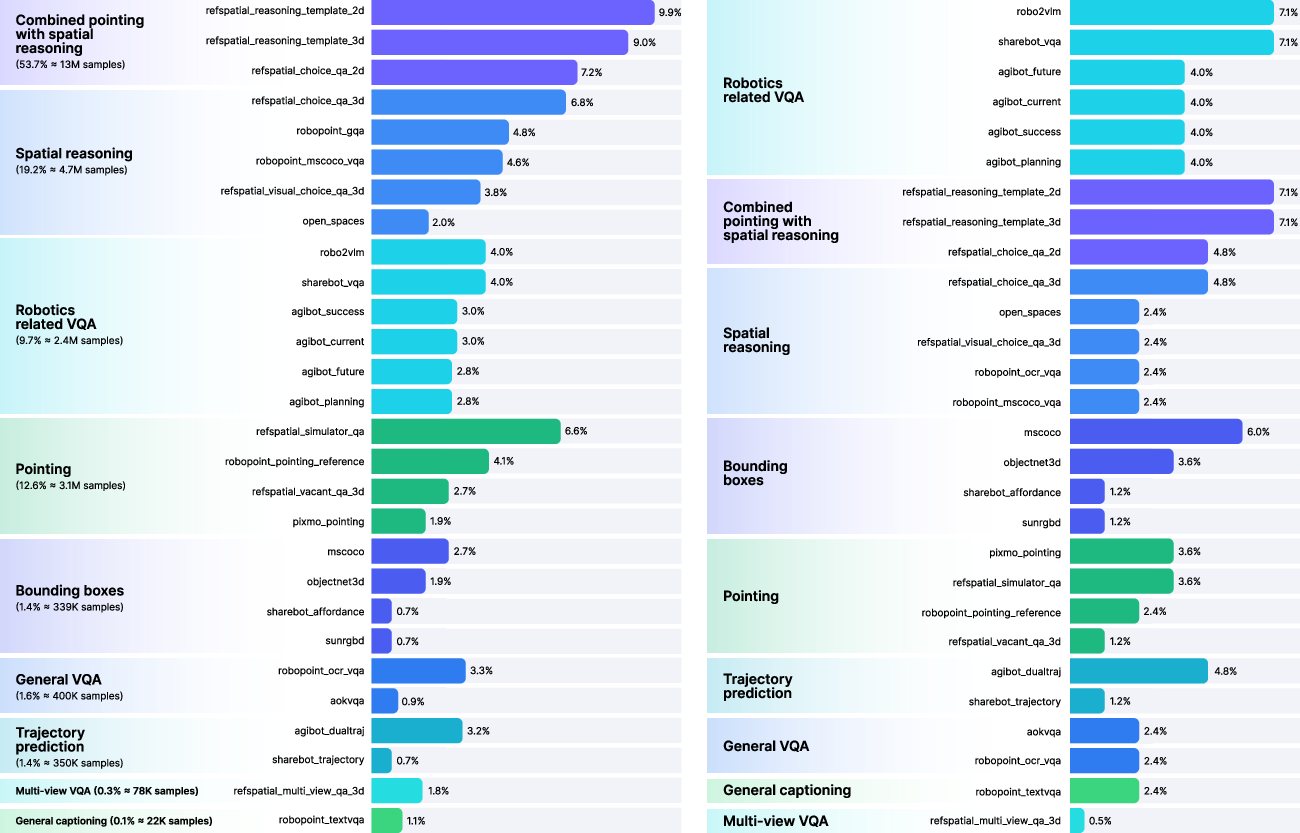
Figure 3: The multimodal L1 pretraining phase leverages a balanced, weighted mixture from VQA, spatial reasoning, pointing, and captioning datasets.
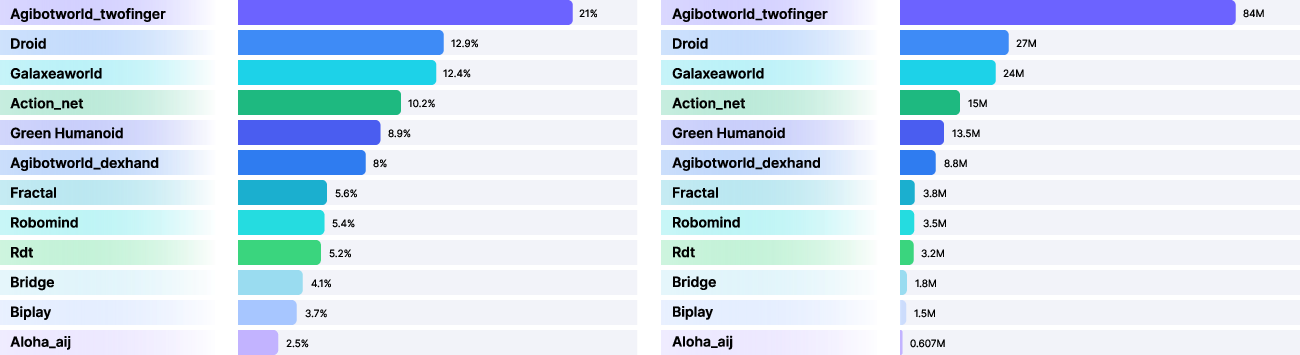
Figure 4: Robotics pretraining (R0) leverages sampling rate optimization and dataset temporal coverage to enhance cross-embodiment learning.
Data quality is enforced by the DataQA pipeline, which filters trajectories with respect to motion smoothness (tremble), frame sharpness, visual diversity (DINOv3 feature std), and state-space variance. Trajectories are temporally normalized using optical flow magnitude as a proxy for apparent motion, enabling motion scale consistency across datasets and robots.
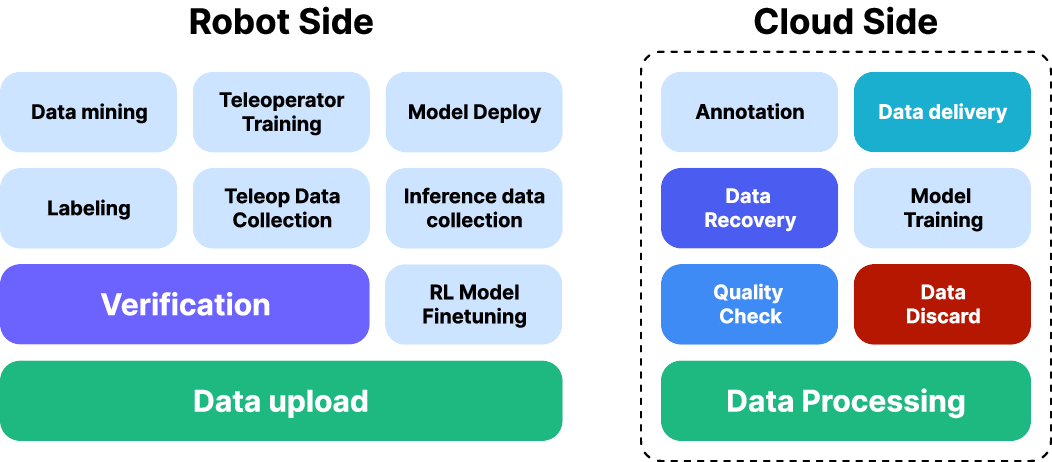
Figure 5: The robot data pipeline integrates teleoperation, automated QA, open-source mining, model training, and RL-based iterative refinement.
Unified Multi-Embodiment Action Space and Policy Structure
Crucial to robust policy transfer is the definition of a unified, semantically-indexed action space (Au), with embodiment-specific binary masks and explicit control-type prompts serialized into the model input token stream. This eliminates spurious penalty gradients and coordinate collision seen in naïve action vector padding across robots.
Action retargeting maps agent- and embodiment-specific commands to this shared action interface, supporting seamless control transfer, even between robots with different DoF or actuator modalities, by semantic alignment of primitives (e.g., gripper-to-dexterous-hand mapping).
Temporal scale conditioning is incorporated to allow the model to dynamically adjust between fine-grained manipulation and accelerated high-level motion within the same policy, induced by action speed factors sampled during training and controllable at inference.
Out-of-Distribution Detection and Guidance Augmentations
Safety and robustness are improved by equipping policies with episode progress estimation and an OOD detector based on Gaussian mixture modeling of state densities. Actions predicted to lead outside high-density regions are corrected via density gradient guidance, reducing failure rates in long episodic chains.
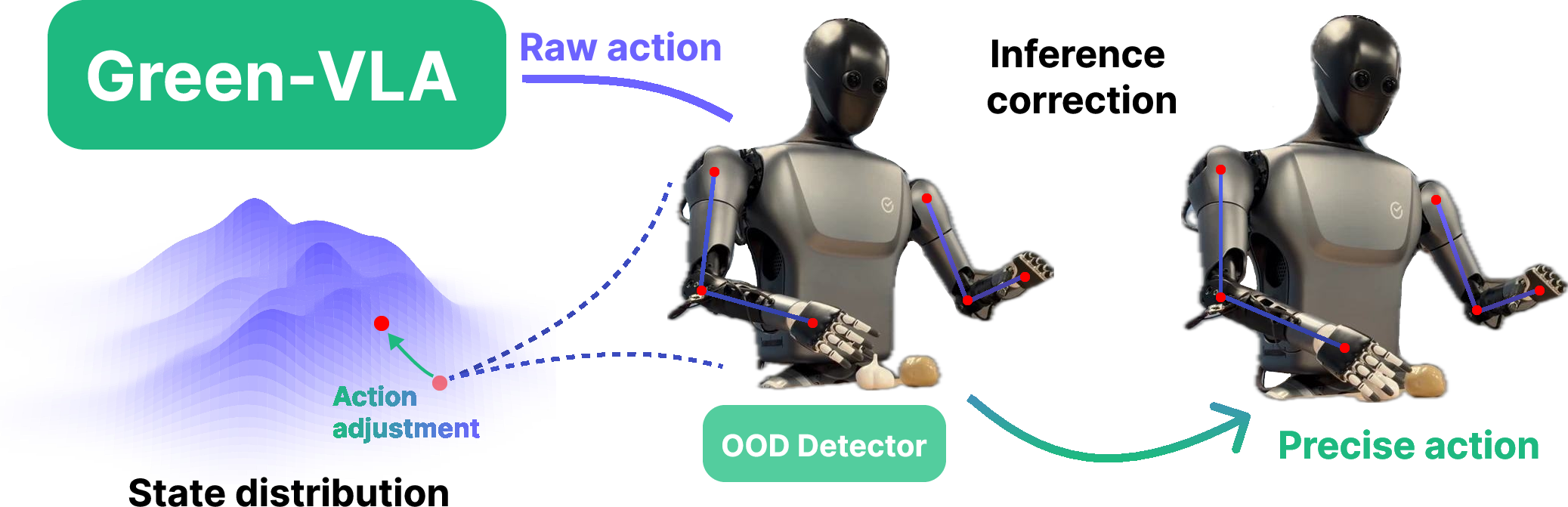
Figure 6: State density modeling via Gaussian mixtures enables OOD detection and correction for safer action around poorly covered state regions.
For challenging, visually ambiguous cases (e.g., shelf picking of near-identical consumer items), the Joint Prediction Module (JPM) predicts 2D affordance points, lifts them into 3D workspace via camera calibration and depth, and then biases action generation toward the inferred physical target by pseudoinverse gradient-based guidance.
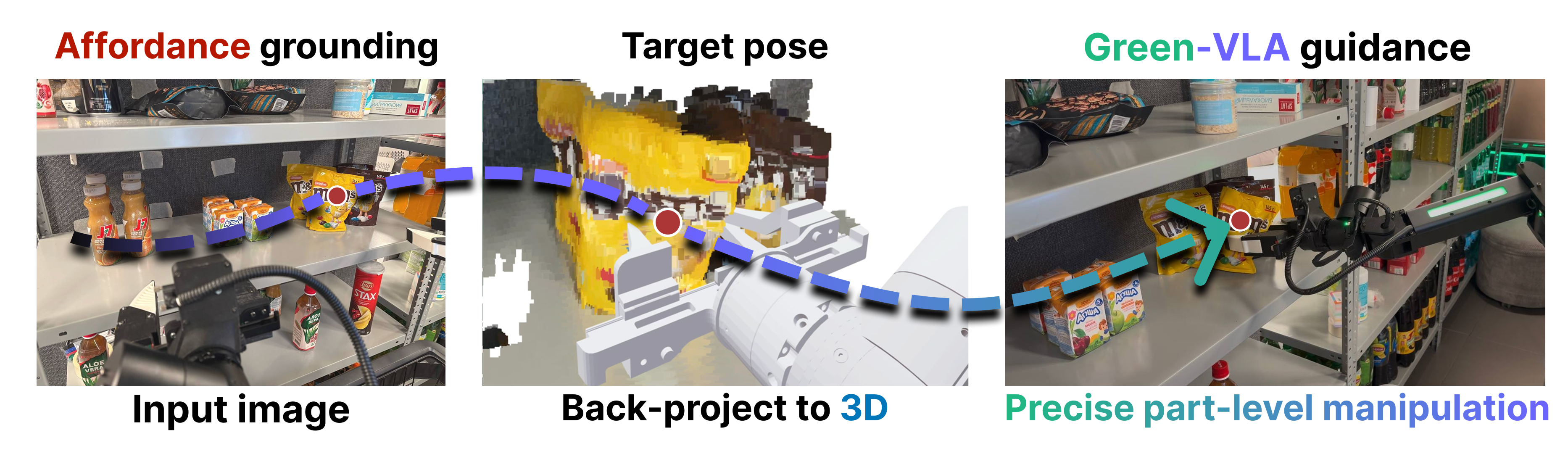
Figure 7: The JPM pipeline first grounds affordances in 2D, then lifts to 3D to initialize guided action towards linguistic targets.
Empirical Results Across Phases and Embodiments
Green-VLA is demonstrated on a broad spectrum of manipulation tasks, from standard pick-and-place benchmarks to bimanual table cleaning and humanoid upper body control. Benchmark results highlight robust zero-shot transfer across platforms and dramatic gains from RL-based R2 alignment.
- On the ALOHA table-cleaning task, Green-VLA (R0) displays a significant improvement in single-pick SR (69.5% vs. 35.6% for π0), and achieves more than a 2x speedup in average completion time.
- On the SimplerEnv Google Robot benchmark, R2 RL alignment yields a substantial SR increase, outperforming both behavior-cloning and fine-tuned baselines in several categories.
- In e-commerce shelf scenarios, the JPM-guided variant achieves a considerably higher top-1 SR on both in-domain and OOD SKUs compared to vanilla end-to-end policies.
- Humanoid robot experiments validate robust language-conditioned performance across diverse pick, place, handover, and multi-object sorting, with consistent task-following and rapid failure recovery in OOD configurations.

Figure 8: E-commerce shelf picking: Green-VLA with JPM guidance achieves top-1 SR superiority across in-domain (category/SKU) and OOD SKU evaluations.
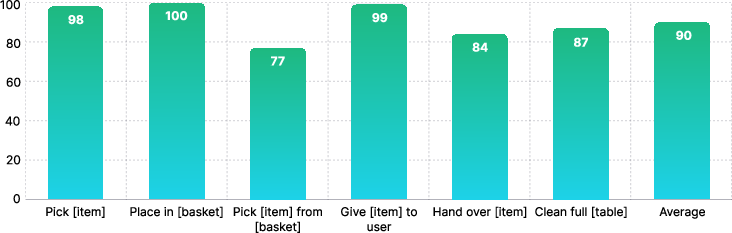
Figure 9: Quantitative evaluation of humanoid policies across core bimanual and full-table cleaning tasks, demonstrating high success both in- and out-of-domain.
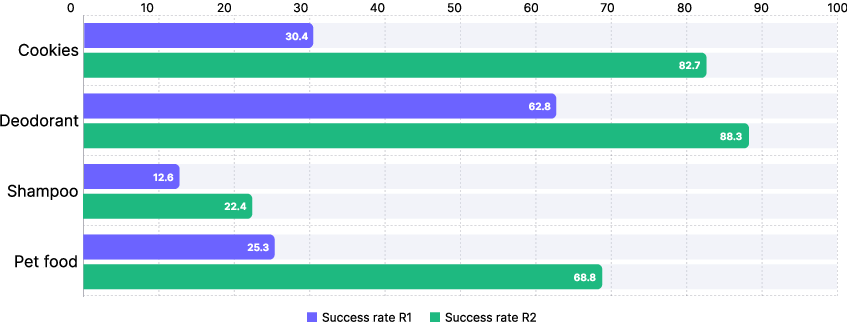
Figure 10: RL alignment (R2) leads to marked improvements for challenging e-commerce items following R1 adaptation.
Implications, Limitations, and Future Directions
Green-VLA substantiates that staged curricula, encompassing cross-source alignment, unified control spaces, selective adaptation, and RL fine-tuning, are critical for scaling generalist robotics beyond the limitations of language/vision scale alone. The staged approach mediates brittle cross-dataset transfer, resolves embodiment conflicts, and recovers long-horizon performance lost to BC saturation.
However, Green-VLA’s transferability remains bounded by the quality of retargeting mappings, residual dataset biases, and the breadth of skill coverage in the demonstration corpus. The full potential of the architecture will be tested as future work addresses several open directions:
- Integration of multilingual instruction following for broader deployment.
- Embodied memory and episodic replay for further long-horizon gains.
- Tight, low-latency linkage of symbolic high-level planning and real-time policy execution.
- Continuous online RL with safety-aware exploration for on-the-fly policy improvement.
Conclusion
Green-VLA demonstrates a scalable, practical architecture and curriculum for unified multimodal robotic control. The fusion of quality-assured data curation, semantically unified action spaces, targeted embodiment specialization, and conservatively tuned RL alignment yields policies with high task-following precision, robust generalization, and strong real-world transfer. This framework sets a compelling technical precedent for future generalist embodied agents that must operate reliably across morphology, modality, and mission.

