- The paper introduces a multi-stage pretraining pipeline that transfers human manipulation priors to enhance robot vision-language-action manipulation.
- It integrates an autoregressive I2V model, trajectory-aware video modeling, and a robot-centric adaptation to predict coherent action sequences.
- Experimental results on three real-world tasks show success rates over 90%, demonstrating robust performance even in cluttered, distractor-rich environments.
RynnVLA-001: Leveraging Human Demonstrations for Enhanced Vision-Language-Action Robot Manipulation
Introduction and Motivation
RynnVLA-001 addresses the persistent challenge of data scarcity in Vision-Language-Action (VLA) models for robotic manipulation. While large-scale datasets have propelled advances in LLMs and VLMs, the collection of robot manipulation data remains labor-intensive and limited in scale. RynnVLA-001 proposes a multi-stage pretraining pipeline that exploits the abundance of ego-centric human manipulation videos to transfer manipulation priors to robotic agents. The approach is characterized by a curriculum that transitions from visual prediction to action-oriented modeling, culminating in a robot-centric VLA model with strong generalization and instruction-following capabilities.

Figure 1: The RynnVLA-001 training data pipeline integrates ego-centric video pretraining, human-centric trajectory-aware modeling, and robot-centric VLA modeling.
Multi-Stage Pretraining Pipeline
Ego-Centric Video Generative Pretraining
The first stage involves training an autoregressive transformer-based Image-to-Video (I2V) model on 12 million ego-centric human manipulation videos. The model is conditioned on an initial frame and a language instruction, and is tasked with predicting future frames. This stage is designed to capture the physical dynamics of manipulation from a first-person perspective, aligning the pretraining task with the downstream requirements of VLA models.
Human-Centric Trajectory-Aware Video Modeling
To bridge the gap between visual prediction and action generation, the second stage introduces joint prediction of future frames and human keypoint trajectories. Using datasets such as EgoDex, the model is finetuned to predict both visual tokens and compact trajectory embeddings (wrist keypoints) generated by a domain-specific ActionVAE. This multi-task objective enables the model to associate visual changes with underlying motion, facilitating transfer to robot action spaces.
Robot-Centric Vision-Language-Action Modeling
In the final stage, the pretrained model is adapted to robot-centric data. The architecture is extended to process dual-view visual observations (front and wrist cameras), robot state embeddings, and language instructions. The model predicts action embeddings, which are decoded by a robot-specific ActionVAE into executable action sequences. The action head is re-initialized to accommodate the kinematic differences between human and robot embodiments.
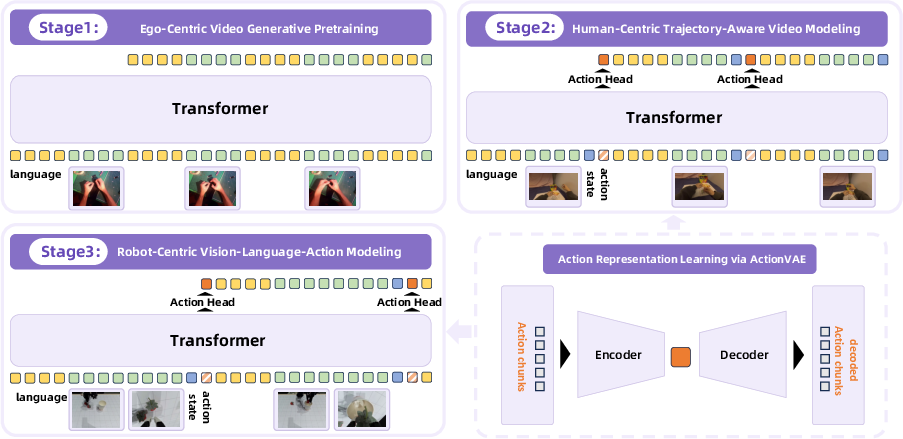
Figure 2: The RynnVLA-001 architecture and training stages, illustrating the progressive transfer from video prediction to trajectory-aware modeling and finally to robot-centric VLA.
ActionVAE: Compact Action Representation
A key innovation is the use of ActionVAE to encode action chunks into low-dimensional latent embeddings. This design choice addresses two issues: (1) it avoids the inefficiency and instability of single-step action prediction, and (2) it provides a smooth, temporally coherent representation of action sequences. Separate ActionVAEs are trained for human and robot domains, ensuring embodiment-specific encoding. During inference, the VLA model predicts an action embedding, which is decoded into a chunk of low-level actions for execution.
Data Curation and Annotation
The ego-centric video dataset is curated via a multi-stage pipeline: pose estimation is used to extract keypoints, videos are filtered for ego-centric perspectives (absence of facial keypoints, presence of hands), and concise language instructions are generated using Qwen2-VL-7B. This ensures that the pretraining data is both relevant and aligned with the downstream VLA task.
Experimental Evaluation
Task Suite and Baselines
RynnVLA-001 is evaluated on a suite of real-world manipulation tasks using the LeRobot SO100 arm: (1) pick up and place green blocks, (2) pick up and place strawberries, and (3) grab pen and put it into holder. Each task is tested under single-target, multi-target, and instruction-following-with-distractors settings.

Figure 3: Evaluation tasks for RynnVLA-001, covering diverse manipulation scenarios and instruction-following with distractors.
Baselines include GR00T N1.5 and Pi0, both finetuned on the same robot data. RynnVLA-001 achieves substantially higher success rates across all tasks and settings, with average success rates exceeding 90% in most cases. Notably, the model maintains robust performance in the presence of distractors, indicating strong language grounding and visual discrimination.
Effectiveness of Pretraining
Ablation studies demonstrate that both stages of pretraining are critical. Models trained from scratch or initialized from generic image-text models (e.g., Chameleon T2I) perform significantly worse. The addition of trajectory-aware pretraining yields further gains, confirming the importance of explicitly modeling the transition from visual dynamics to action generation.
Model Design Ablations
- Image Resolution: Lowering the input resolution degrades performance due to VQGAN reconstruction artifacts, highlighting the importance of high-fidelity visual tokens.
- Action Representation: Predicting VAE-encoded action embeddings outperforms direct raw action prediction, yielding smoother and more consistent behaviors.
- Action Head Complexity: A single linear layer suffices for action decoding; deeper MLP heads introduce overfitting and reduce performance.
Video Generation and Instruction-Following
The pretrained I2V model generates plausible motion sequences from static images and text prompts, serving as an effective backbone for downstream VLA adaptation.

Figure 4: The I2V model generates temporally consistent video frames conditioned on an image and text prompt.
Instruction-following robustness is directly linked to the diversity of training data. Models trained without distractors fail to generalize in cluttered scenes, while the full RynnVLA-001 model achieves high success rates in such settings.
Sensor Configuration and Spatial Reasoning
The dual-camera setup (front and wrist cameras) is essential for robust manipulation. The front camera provides coarse localization and 3D projective context, while the wrist camera enables fine-grained adjustments. Disabling or altering the front camera's viewpoint leads to catastrophic failures in tasks requiring spatial reasoning or when targets are outside the wrist camera's field of view.

Figure 5: The front camera is critical for coarse localization; masking it leads to failure when targets are not visible to the wrist camera.

Figure 6: The front camera's 3D perspective is necessary for precise spatial reasoning; altering its geometry impairs task success.
Implications and Future Directions
RynnVLA-001 demonstrates that large-scale human demonstration data, when properly curated and integrated via a multi-stage curriculum, can significantly enhance the generalization and robustness of VLA models for robotic manipulation. The explicit modeling of the transition from visual prediction to action generation, combined with compact action representations, yields a system that outperforms prior state-of-the-art approaches in both success rate and instruction-following fidelity.
The results suggest several avenues for future research:
- Extending the approach to a broader range of robot embodiments and unstructured environments to assess generalization.
- Investigating the impact of more diverse camera configurations and sensor modalities.
- Exploring the integration of richer proprioceptive and tactile feedback for fine-grained manipulation.
- Scaling the approach to more complex, long-horizon tasks and multi-agent settings.
Conclusion
RynnVLA-001 establishes a new paradigm for VLA model pretraining by leveraging large-scale ego-centric human demonstrations and trajectory-aware modeling. The architecture, data curation, and action representation strategies collectively yield a model with superior manipulation capabilities and instruction-following robustness. The findings underscore the value of curriculum-based pretraining and embodiment-specific action encoding for advancing generalist robotic agents.

