- The paper introduces a hierarchical framework that decouples high-level semantic reasoning from low-level motor execution using explicit Chain-of-Thought steps.
- It employs a two-stage training approach—supervised CoT fine-tuning and GRPO reinforcement—that achieves a ~5% improvement on key VLN benchmarks.
- The system integrates multimodal perception with real-world deployment, demonstrating robust navigation and manipulation in dynamic environments.
MobileVLA-R1: Reinforcing Vision-Language-Action for Mobile Robots
Motivation and Framework Overview
MobileVLA-R1 presents a unified hierarchical framework for vision-language-action (VLA) reasoning and control in mobile robots, with an explicit focus on bridging the core semantic–control gap prevalent in current approaches. The framework introduces structured Chain-of-Thought (CoT) action plan generation conditioned on natural language instructions and rich multimodal observations (including RGB, depth, and point cloud data). This design decouples high-level semantic reasoning from low-level motor execution, resulting in improved interpretability and control robustness.
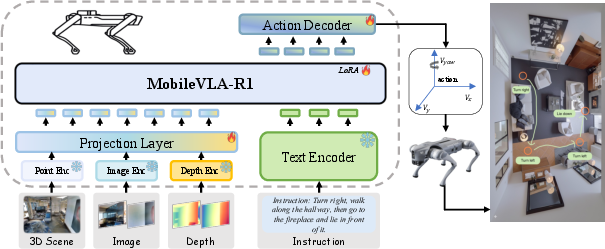
Figure 1: Architecture of MobileVLA-R1, demonstrating end-to-end processing of language and multimodal sensory input to generate continuous robotic locomotion actions.
Instead of directly mapping language to actions, MobileVLA-R1 predicts explicit reasoning steps before decoding them into executable control sequences, enabling flexible and environment-adaptive execution. Training proceeds in two stages: (1) supervised alignment on a large-scale, multi-granularity CoT dataset (MobileVLA-CoT) and (2) Group Relative Policy Optimization (GRPO) reinforcement learning for policy refinement.
Chain-of-Thought Data Engine and Dataset Construction
Central to the proposed method is the construction of MobileVLA-CoT, a dataset synthesizing step- and episode-level reasoning traces for embodied navigation and control. The CoT Data Engine leverages Gemini-2.5-Flash to generate structured, multi-stage reasoning linked to both visual inputs and action targets.

Figure 2: Pipeline for CoT Data Engine, illustrating integration of navigation instructions, visual data, structured prompts, and LMM-based annotation generation.
Three complementary datasets are provided:
- MobileVLA-CoT-Episode: High-level summarization and plan representation.
- MobileVLA-CoT-Step: Local, executable action specification with reasoning.
- MobileVLA-CoT-Nav: Long-horizon navigation traces.
Rigorous semi-automatic verification ensures the logical consistency, safety, and structural adherence of annotations. This large-scale resource enables effective supervised alignment of reasoning and execution.
Two-Stage Training: Supervised CoT Alignment and GRPO
MobileVLA-R1’s training strategy is structured in two sequential phases:
- Supervised CoT Fine-tuning (SFT): The model is initialized from NaVILA and fine-tuned on the CoT corpus, ensuring structured, interpretable reasoning in the prescribed > …<answer>…</answer> format. This stage establishes semantic alignment and enables coherent long-horizon language grounding.
- Reinforcement Learning with GRPO: To improve action fidelity and long-horizon execution, Group Relative Policy Optimization is applied. Unlike traditional reward optimization (e.g., PPO), GRPO operates on groupwise, normalized, and clipped advantage functions, integrating task-specific movement, action, and format rewards with KL regularization to stabilize policy updates.
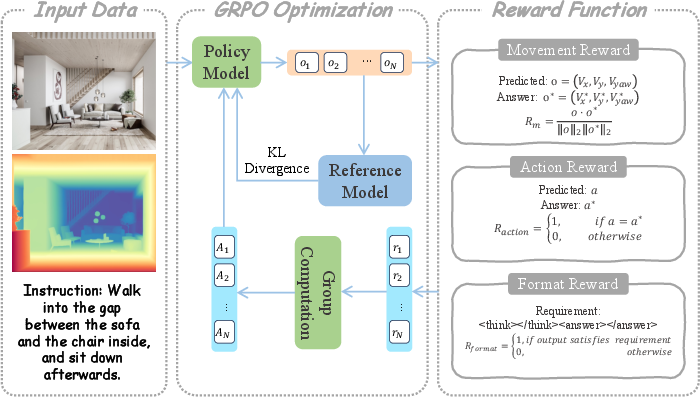
Figure 3: RL policy pipeline in MobileVLA-R1 — multiple responses are generated per input, and groupwise normalized rewards jointly align policy updates, with a KL-divergence term enforcing conservative updates.
This two-stage paradigm yields a policy that is robust, highly aligned with both high-level instruction semantics and low-level actuation.
Multimodal Perception and Real-World Integration
The architecture incorporates modality-specific encoders for RGB (NaVILA), depth (DepthAnything V2), and 3D structure (Point Transformer v3). Multimodal fusion via a lightweight projection module precedes the LLaMA3-8B language backbone, with adaptation enforced through parameter-efficient tuning (LoRA).
In practice, MobileVLA-R1 is evaluated on the Unitree Go2 quadruped with integrated LiDAR, RGB-D sensing, and on-board GPU for real-time inference. Sensory streams are fused and transmitted for centralized or hybrid inference, with action commands relayed back for continuous execution.
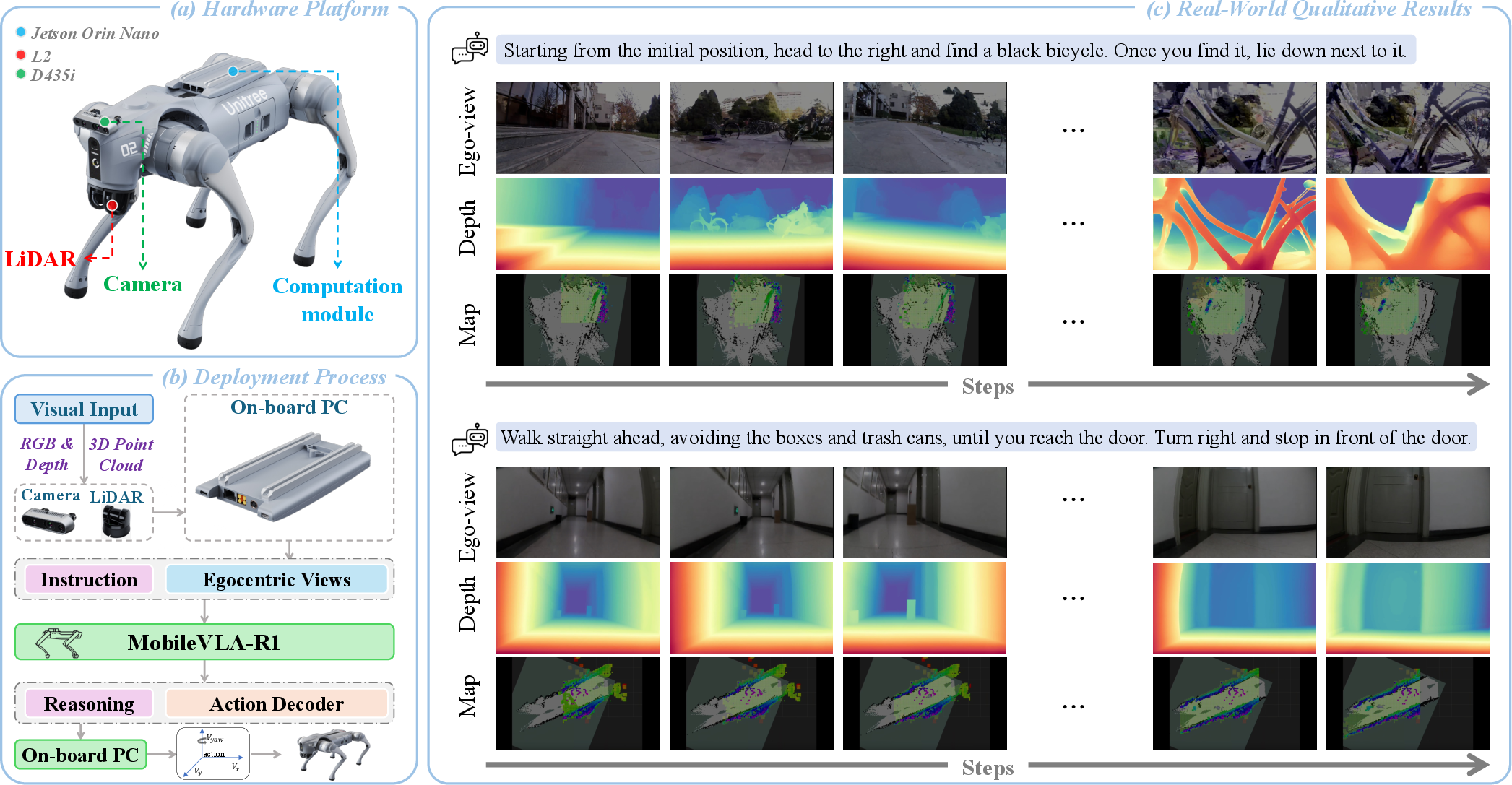
Figure 4: (a) Hardware stack for real-world testing, (b) real-time inference and actuation flow, (c) deployment result highlighting complex language-driven spatial reasoning.
Quantitative and Qualitative Results
Vision-Language Navigation (VLN)
On R2R-CE and RxR-CE benchmarks, MobileVLA-R1 delivers a ~5% improvement in success rate over strong state-of-the-art baselines, along with superior navigation error (NE), SPL, and nDTW metrics. This demonstrates not just better instruction interpretation but also improved path efficiency and spatial reasoning.
Quadruped Manipulation (QUARD)
On six QUARD tasks (grouped by Easy, Medium, Hard), the system achievess the highest average success rate (0.73) and strong consistency across both locomotion and manipulation tasks, surpassing MoRE and QUART by notable margins.
Real-World Deployment
In real indoor and outdoor environments, MobileVLA-R1 exhibits high robustness, with marked reductions in navigation error and improved success rates on both simple and complex tasks, outperforming both the GPT-4o and NaVILA baselines.

Figure 5: Representative real-world executions showcasing accurate spatial reasoning, targeted interaction, and robust obstacle avoidance.

Figure 6: Outdoor deployment sequences, demonstrating strong generalization and successful long-horizon reasoning in unconstrained environments.

Figure 7: Additional outdoor trials highlight precise, safety-aware navigation and context-aware actuation in complex terrains.
Reward Design and Ablation
Reward ablations confirm the necessity of integrating movement, action, and format rewards during GRPO training. Omitting any component results in degradation of navigation and control metrics, highlighting the complementary roles of trajectory-alignment, decision consistency, and parseability in embodied policy optimization.
Practical and Theoretical Implications
MobileVLA-R1 demonstrates the practical viability of combining structured CoT-based reasoning with continuous multimodal control for real-world robotic agents. The separation of reasoning and actuation provides transparency and diagnostic capacity, facilitating robust, interpretable policy learning. The demonstrated gains suggest that explicit CoT alignment paired with reward-regularized RL can close the gap between high-level semantic goal formation and the demands of physical actuation in partially observable, dynamic environments.
The strong results on previously challenging benchmarks suggest theoretical advancements in embodied alignment: MobileVLA-R1's design supports compositional generalization and offers a scalable pathway for future foundation models targeting complex, open-ended VLA tasks.
Conclusion
MobileVLA-R1 constitutes an authoritative advance in the unified treatment of vision-language-action for mobile robots, introducing a reasoning-aligned, hierarchical control framework with explicit interpretability and deployment-proven robustness. The two-stage SFT + GRPO regime, combined with large-scale, multimodal CoT supervision, yields strong empirical and qualitative gains in navigation, manipulation, and adaptation. Future developments will revolve around further policy generalization, more efficient architectures, expanded action spaces, and lifelong/self-supervised learning strategies, toward resilient, general-purpose embodied AI.

