- The paper introduces a novel VLA model that integrates vision, language, and action synthesis for real-time robotic manipulation.
- It employs a two-stage training strategy with joint multimodal pre-training and diffusion transformer-based action generation to mitigate latency.
- Evaluation on simulated and real-world tasks demonstrates state-of-the-art performance and robust sim-to-real transfer under hardware limitations.
Vision-Language-Action Learning With Xiaomi-Robotics-0: Architecture, Training, and Real-Time Execution
Introduction and Motivation
Xiaomi-Robotics-0 introduces a vision-language-action (VLA) model framework that targets both high policy learning performance and real-time deployability for robotic manipulation. Central to this advance are architectural refinements, a robust pre-training/post-training regimen, and deployment strategies enabling responsive and reliable bimanual robot control even under hardware-limited, consumer-grade GPU settings. The model particularly addresses the challenge of inference-induced latency in large VLA networks, a bottleneck that historically hinders seamless robotic rollout and contributes to unsafe, discontinuous actuation.
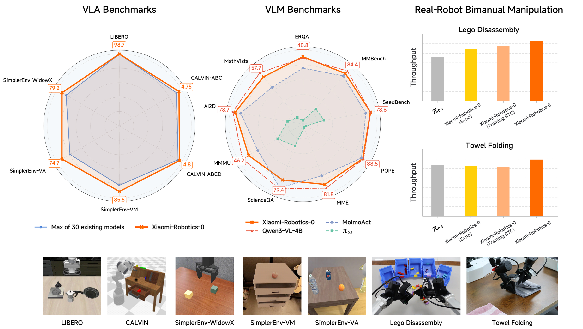
Figure 1: Xiaomi-Robotics-0 achieves state-of-the-art performance in three widely-used simulation benchmarks, high throughput on two challenging real-robot bimanual manipulation tasks, and matches its underlying VLM on standard vision-language benchmarks.
Data Composition and Multimodal Curation
The model's supervised corpus fuses large-scale cross-embodiment robot trajectories—aggregated from open-domain benchmarks (e.g., DROID, MolmoAct) as well as 738 hours of teleoperated data on bimanual Lego Disassembly and Towel Folding—with a vision-language corpus exceeding 80M curated samples. The vision-language data includes both general and robot-centric egocentric datasets, the latter annotated at pixel-level resolution using consensus from contemporary object grounding models (Grounded SAM, Grounding DINO 1.5, LLMDet). Task coverage spans visual grounding, VQA, image captioning, and embodied planning, with curation pipelines leveraging SOTA VLMs for label refinement, and generation of embodied question answering and task planning episodes from trajectory roots.
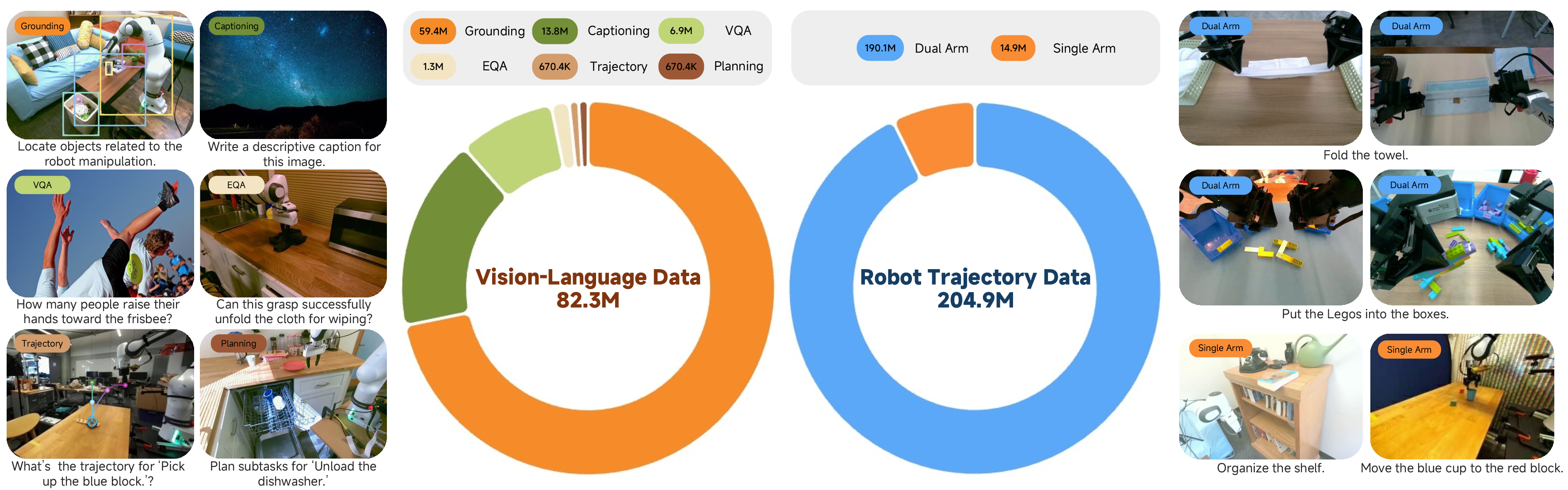
Figure 2: Xiaomi-Robotics-0 leverages both robot trajectory data and vision-language (VL) data during pre-training.
Architecture and Training Paradigm
Model Structure
Xiaomi-Robotics-0 employs a mixture-of-transformers (MoT) architecture combining Qwen3-VL-4B-Instruct as the frozen VLM backbone for joint visual-linguistic encoding, and a 16-layer diffusion transformer (DiT) for action generation via flow-matching. The system receives as input: image observations, language instructions, and proprioceptive robot states; it emits a chunk of continuous actions for execution.
Pre-training
Training unfolds in two phases. Initially, the VLM is jointly optimized for both next-token prediction on VL data and N-choice action chunk prediction on robot trajectory data, where candidate actions are scored and supervised by a winner-takes-all L1 loss. Robot proprioception is embedded via MLPs, with token-level architectural modularity to support multi-candidate action and score outputs. Causal attention governs the temporal dynamics.
Subsequently, the VLM is frozen, and the DiT is optimized for flow-matching loss, conditioned on VLM-generated key-value caches—crucial to mitigate catastrophic forgetting and to decouple vision-language semantics from trajectory action learning. Temporal correlation is reinforced by structuring token input sequences with a learnable "sink" token, proprioceptive state tokens, and noisy action tokens whose RoPE positional indices explicitly disambiguate prefix versus trajectory-generated actions.
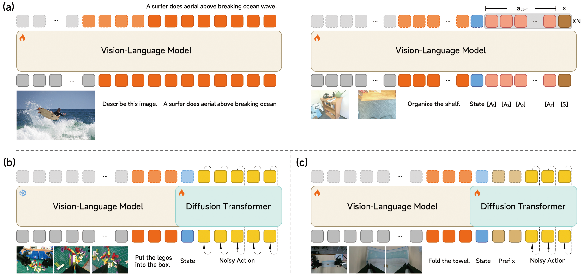
Figure 3: Multi-stage pre-training fuses VL and robot trajectory supervision, then freezes the VLM for DiT training via flow-matching; post-training enables asynchrony and action continuity.
Post-training and Asynchronous Execution
Standard synchronous chunked execution yields undesirable pauses during inference, directly undermining real-world deployment. Xiaomi-Robotics-0 incorporates advanced post-training to enable asynchronous execution: during action chunk generation, action tokens are prefixed with previously-executed actions, and a Λ-shaped attention mask is imposed to restrict spurious temporal shortcuts. Noisy action tokens are prevented from indiscriminate access to the action prefix except in the temporal vicinity, forcing the network to attend more strongly to fresh visual and linguistic cues for reactivity.

Figure 4: The Λ-shape attention mask restricts distant noisy action tokens from attending to clean action prefix tokens, thereby enforcing reliance on visual and language conditions.
During inference, the model supports seamless "stitching" of action chunks, aligning the prefix for each new prediction to the output tail of the prior chunk, and always maintaining a forward execution buffer sufficient to mask inference latency.
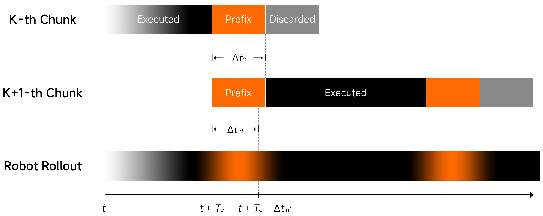
Figure 5: Two consecutive chunks are continuously stitched together during asynchronous robot rollout, ensuring uninterrupted execution.
Simulation and Real-World Experimental Evaluation
Benchmark Results
Xiaomi-Robotics-0 demonstrates strong numerical performance on flagship simulation benchmarks:
- LIBERO: Achieves an average 98.7% success rate, surpassing all baselines.
- CALVIN: Completes 4.80 and 4.75 out of 5 consecutive tasks per instruction chain on in-distribution (ABCD→D) and out-of-distribution (ABC→D) splits respectively, establishing clear performance gains in both long-horizon and zero-shot generalization.
- SimplerEnv: Outperforms prior models with 85.5% (visual matching), 74.7% (variant aggregation), and 79.2% (WidowX) average success rates, evidencing robust sim-to-real transfer across pronounced visual gaps.
On dexterous bimanual real-robot tasks (Lego Disassembly, Towel Folding), Xiaomi-Robotics-0 matches or exceeds baseline SOTA VLA models in both average success rate and throughput (units/time), with particularly pronounced improvements in task efficiency due to asynchronous execution and attention mask innovations. The model achieves >1.2 folded towels per minute—higher than synchronous and baseline asynchronous strategies—and demonstrates resilience to repeated failure loops via minimum shortcut exploitation in action prefixing.
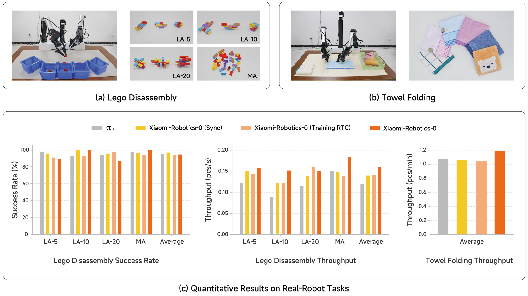
Figure 6: Left and center—experimental settings for Lego Disassembly and Towel Folding; right—quantitative success rate and throughput for tested methods.
Preservation of Vision-Language Capabilities
The dual-source pre-training paradigm ensures that Xiaomi-Robotics-0 retains the VL competence of its foundation model. Empirical assessment on ten canonical VL and embodied reasoning benchmarks validates complete preservation of generalist VL capabilities. On ERQA, Xiaomi-Robotics-0 marginally surpasses its progenitor Qwen3-VL-4B-Instruct; ablation confirms that omitting VL data in pre-training results in catastrophic forgetting, with VL performance collapsing to near zero.

Figure 7: Qualitative results on vision-language tasks demonstrate robust perception and reasoning.
Qualitative Analysis
Further visualization illustrates Xiaomi-Robotics-0's effective handling of complex multimodal queries, robust spatial grounding, and task-specific perception, with occasional minor failures in dense chart QA and rigorous format fidelity. Baseline comparisons highlight consistent reductions in hallucination and failure frequency.
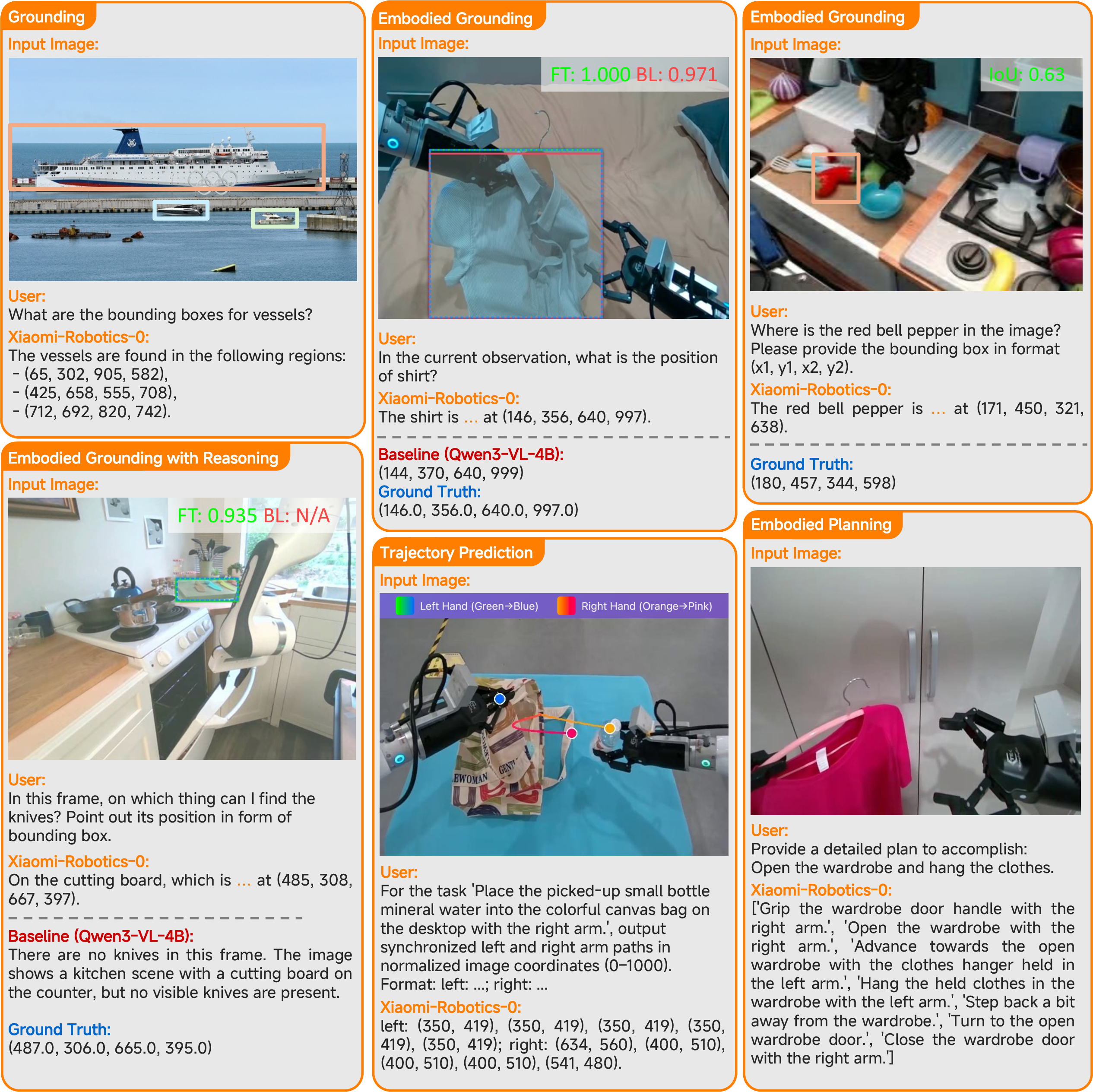
Figure 8: Additional qualitative results for VL and embodied reasoning task generalization.
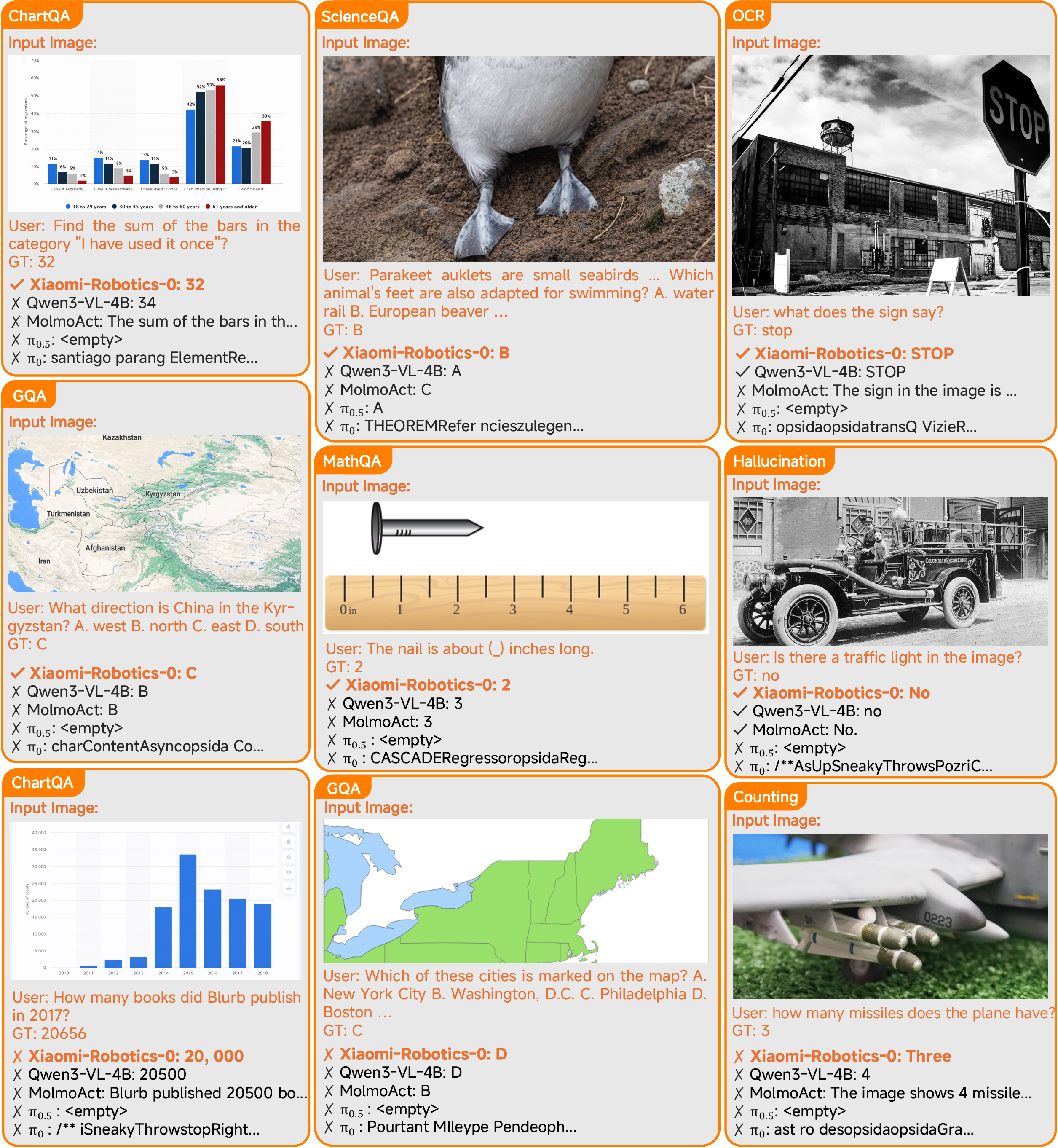
Figure 9: Comparative analysis on vision-language and reasoning tasks, including challenging error cases relating to dense numerical chart reading.
Implications and Future Directions
Xiaomi-Robotics-0 advances the integration of high-capacity vision-language reasoning with scalable, low-latency action synthesis in physically embodied settings. The adopted training and deployment strategies—including joint multimodal pre-training, mix-of-expert architectures, flow-matching, and asynchronous rollout via masked attention—present a template for further progress in VLA learning. Practical impact extends to affordable and robust generalist robotics, especially under realistic compute constraints. Theoretically, the work demonstrates that strong VL priors can be preserved through judicious co-training and architectural decoupling.
Anticipated directions include expanding the robot trajectory data corpus for broader embodiment/skill coverage, further optimizing inference for edge-grade hardware, and investigating lifelong learning dynamics in embodied environments without VL performance degradation.
Conclusion
Xiaomi-Robotics-0 establishes new SOTA results in both simulated and real-world robotic benchmarks while achieving seamless, real-time policy execution on modest hardware. Its end-to-end pipeline—anchored by robust multimodal data curation, two-stage training, and innovative attention masking—illustrates a mature engineering solution to the VLA latency-reactivity tradeoff. The open-sourcing of code and model weights further encourages reproducibility and rapid adoption within the robotics and embodied AI research community.