- The paper proposes SAP-VLA, a two-stage pretraining approach that aligns 2D visual cues with 3D physical action representations using human demonstration videos.
- The dual-encoder framework integrates pretrained vision-language models with a dedicated 3D encoder, achieving robust spatial grounding and improved robot manipulation performance.
- Empirical evaluations show high task success rates in simulation and real-world settings, highlighting the method's ability to bridge the perceptual-action gap.
Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
Problem Statement and Motivation
Vision-Language-Action (VLA) models, which incorporate visual inputs and language instructions to produce executable actions, have demonstrated substantial promise for robotic policy learning. However, current VLA models predominantly ground their action policies in 2D visual representations, which introduces a significant perceptual-action gap in environments that are inherently 3D. This impairs their ability to robustly ground actions in physical space, leading to suboptimal policy performance and limited generalization across tasks. The paper "Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos" (2512.13080) directly addresses this limitation by proposing a Spatial-Aware VLA Pretraining (SAP-VLA) paradigm. This approach explicitly aligns 2D visual observations with 3D physical action representations by leveraging large-scale annotated human manipulation videos for aligned spatial supervision.
Visual-Physical Alignment Framework
The proposed framework is structured into a multi-stage pipeline centered around extracting and utilizing 3D spatial and action annotations from human demonstrations. Starting from a pretrained vision-LLM (VLM) backbone, the authors extract 3D visual and 3D action annotations from a diverse corpus of human manipulation videos. The key insight is to use the natural correspondence present in human demonstrations—where 2D observations and resulting 3D actions are intrinsically aligned—as supervision for VLA models to acquire spatial awareness prior to direct robot policy learning.
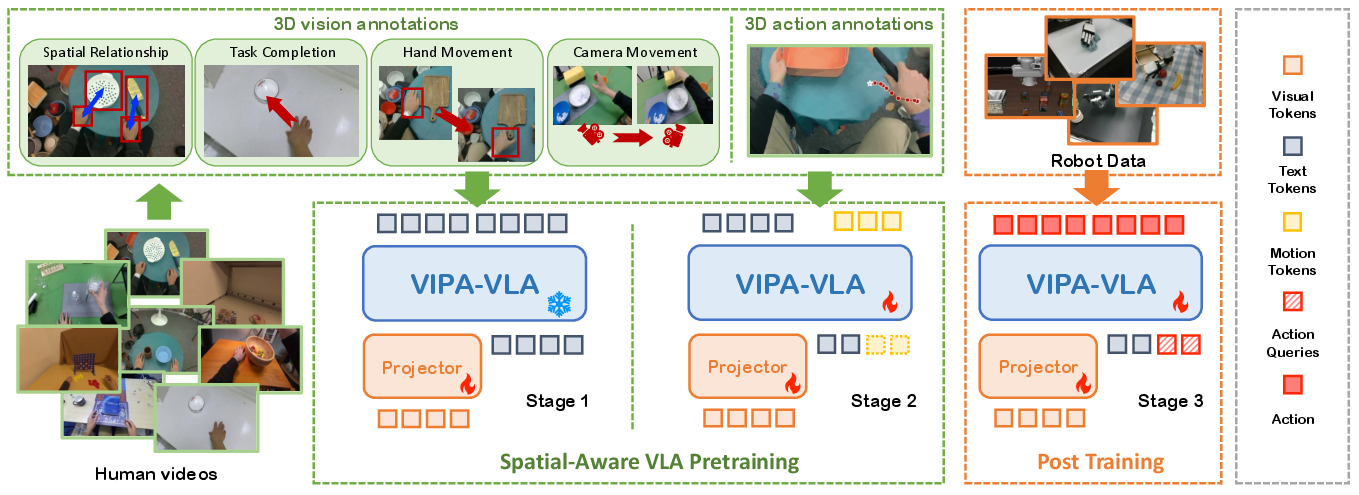
Figure 1: The Visual-Physical Alignment framework leverages human demonstration videos to extract 3D visual and action annotations, which are used for a two-stage pretraining process that grounds 2D perception in 3D spatial understanding before adaptation to robot tasks.
Crucially, the SAP-VLA framework comprises two core pretraining stages: (1) 3D Visual Pretraining, where models are trained to align 2D visual features with 3D spatial representations—using dual-encoder fusion—and (2) 3D Action Pretraining, where hand trajectory annotations from the videos provide rich motion supervision for learning physically grounded action priors. The final, adapted model is then post-trained on robot task data, inheriting this robust spatial grounding.
Construction of Spatial-Aware Datasets
A major technical contribution is the curated dataset of human manipulation videos with precise 3D visual and action annotations. The video corpus brings together data from motion capture, VR, and pseudo-annotated sources, covering a wide variety of manipulation tasks and scenarios. All hand pose data are normalized to the MANO parametric hand model for consistent spatial representation.
3D visual annotations are constructed by integrating per-frame dense point cloud estimates (via models such as Cut3R), 2D object proposals (Gemini-2.5-flash and GroundingDINO), and hand pose localization. Scale calibration ensures physically consistent spatial representations across all frames and modalities. These 3D spatial features are then projected into standardized language-based VQA pairs, providing dense, linguistically grounded supervision between vision and physical space.
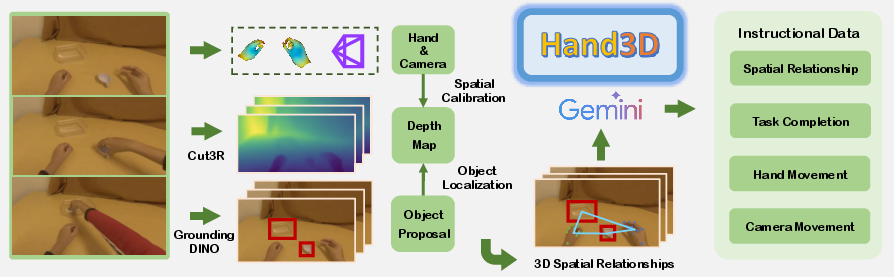
Figure 2: The dataset pipeline integrates point cloud estimation, object localization, and hand pose annotation to bridge 2D visual observations with action-relevant 3D spatial representations, forming the foundation for visual-physical alignment.
Additionally, 3D action annotations encode hand motion trajectories as discretized token sequences, providing explicit motion supervision aligned with linguistic task descriptions.
Model Architecture: Dual-Encoder Design
The model employs a dual-encoder architecture that integrates a semantic vision encoder (internally derived from large VLMs) with a dedicated 3D spatial encoder (Cut3R). These are fused using a learnable cross-attention layer, which enhances semantic (2D) representations with geometric (3D) features. Domain adaptation is further enabled by extending the LLM token vocabulary to include discretized motion tokens, corresponding to physical locations and trajectories in the space.
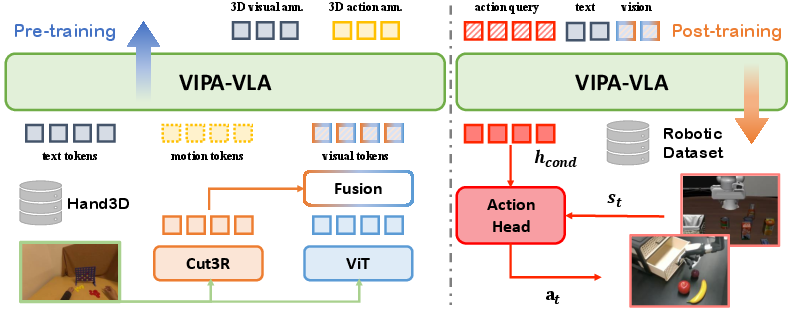
Figure 3: The dual-encoder model architecture fuses semantic vision and 3D spatial features via a cross-attention layer, aligns these fused features with textual and motion tokens in pretraining, and predicts actions posttraining through a flow-matching action head.
Spatial-Aware VLA Pretraining Strategy
The spatial-aware pretraining is performed in two progressive stages:
- Stage 1: Only the fusion layer is trained (with all pretrained backbones frozen) on 3D visual annotation-based VQA pairs. This solidifies correspondences between 2D and 3D representations at the feature level.
- Stage 2: Upon extending the LLM's token vocabulary, the model is further trained on 3D action annotations, learning to map fused visual-linguistic features to explicit 3D motion patterns via motion token prediction.
Critically, the methodology enables the acquisition of comprehensive visual-physical alignment using only human demonstrations, without reliance on large-scale robot-specific data in pretraining.
Empirical Evaluation
Simulation Benchmarks
Evaluation on the LIBERO and RoboCasa simulation benchmarks demonstrates that models pretrained with the proposed SAP-VLA approach generalize robustly to diverse and challenging environments despite not seeing any robot data during pretraining. Numerically, the model achieves 92.4% average success on LIBERO (single-view) and 96.8% in two-view configuration, outperforming most spatially-aware VLA baselines and closely matching the performance of strong robot-pretrained models (e.g., π-series and GR00T). On RoboCasa, the framework achieves 45.8% average success, with notable improvements (+9.9%) in spatially challenging tasks (Doors/Drawers).
Real-World Robotic Manipulation
For real robot tasks, the approach yields superior success: e.g., in the Wipe-Board task, it achieves 83% sub-task and 60% whole-task completion, compared to 43% and 10% for the InternVL3.5 baseline, respectively. Generalization to unseen environments also shows strong sub-task completion robustness (44% and 83% vs baseline 42% and 40%) and substantial whole-task improvements. Qualitative examples confirm that the model maintains spatial grounding, accurately localizes objects, and executes multi-step manipulations reliably.

Figure 4: Qualitative results of the spatial-aware VLA model performing real robot tasks, demonstrating accurate spatial reasoning and robust multi-step manipulation in varied real-world scenarios.
Failure analysis indicates that residual errors predominantly concern fine motor execution, not high-level spatial reasoning, contrasting with baseline models that fail due to poor 2D-3D correspondence.

Figure 5: Typical failure cases for both the spatial-aware VLA model and InternVL-3.5 baseline, highlighting errors in fine manipulation (ours) versus spatial localization (baseline).
Ablation and Spatial Reasoning Analysis
Ablation studies establish that both the dual-encoder architecture and spatial-aware pretraining are necessary for maximum performance; removing either degrades LIBERO average accuracy by 1–2%, and 3.7% if both are absent.
Spatial reasoning evaluation on held-out 3D-VQA pairs shows that after pretraining, the model's direction accuracy improves to 1.82/3 versus 1.22/3 for InternVL3.5, and average distance error reduces from 0.18m to 0.12m. This demonstrates effective 3D spatial understanding acquired solely from human video supervision.
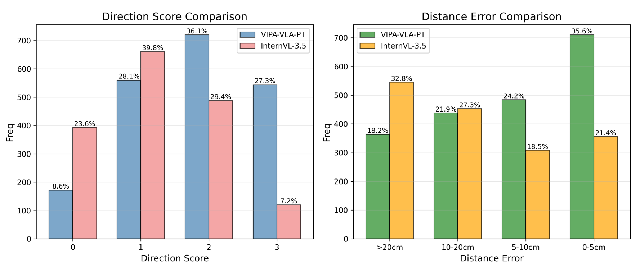
Figure 6: Distribution of direction and distance errors comparing the SAP-VLA pretraining to InternVL3.5, evidencing significant improvements in spatial prediction fidelity after alignment.
Predicted trajectories from action annotation pretraining further illustrate that the model learns to produce smooth, affordance-aligned motions consistent with instruction, whereas ground-truth trajectories are more noisy due to natural human variation.

Figure 7: Qualitative visualization of predicted (blue) versus ground-truth (red) motion trajectories, showing goal-directed, physically grounded movement after pretraining.
Theoretical and Practical Implications
The SAP-VLA approach fundamentally shifts the pretraining paradigm for VLA models from robot-only or synthetic-data-centric to one that leverages abundant and diverse human video data with explicit 3D annotation. This inductively equips downstream policies with strong spatial priors prior to any robot-specific adaptation. From a theoretical standpoint, it directly bridges the perception-action gap, demonstrating that rich 2D–3D correspondence learned from non-robotic sources can yield policy representations with high sample efficiency and robust generalization. Practically, this pretraining reduces the data requirements for robot-specific finetuning and improves transferability to novel environments, spatial configurations, and manipulation strategies.
Future directions may include combining human- and robot-data pretraining for further synergistic gains, integrating this alignment with more advanced 3D perception modules, and scaling to broader classes of embodied agents and tasks.
Conclusion
The paper establishes that spatial-aware pretraining, using explicit visual-physical alignment derived from human manipulation videos, is an effective and scalable strategy for enhancing the 3D reasoning and action grounding capabilities of VLA models (2512.13080). The proposed dual-encoder design and progressive pretraining, validated across simulated and real-world tasks, provide a viable foundation for future generalist robotic systems. As robotics continues to demand robust transfer and spatial reasoning, such paradigms are likely to become increasingly central to the field.