SemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation (2511.10518v1)
Abstract: Vision-Language-Action (VLA) models have advanced in robotic manipulation, yet practical deployment remains hindered by two key limitations: 1) perceptual redundancy, where irrelevant visual inputs are processed inefficiently, and 2) superficial instruction-vision alignment, which hampers semantic grounding of actions. In this paper, we propose SemanticVLA, a novel VLA framework that performs Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation. Specifically: 1) To sparsify redundant perception while preserving semantic alignment, Semantic-guided Dual Visual Pruner (SD-Pruner) performs: Instruction-driven Pruner (ID-Pruner) extracts global action cues and local semantic anchors in SigLIP; Spatial-aggregation Pruner (SA-Pruner) compacts geometry-rich features into task-adaptive tokens in DINOv2. 2) To exploit sparsified features and integrate semantics with spatial geometry, Semantic-complementary Hierarchical Fuser (SH-Fuser) fuses dense patches and sparse tokens across SigLIP and DINOv2 for coherent representation. 3) To enhance the transformation from perception to action, Semantic-conditioned Action Coupler (SA-Coupler) replaces the conventional observation-to-DoF approach, yielding more efficient and interpretable behavior modeling for manipulation tasks. Extensive experiments on simulation and real-world tasks show that SemanticVLA sets a new SOTA in both performance and efficiency. SemanticVLA surpasses OpenVLA on LIBERO benchmark by 21.1% in success rate, while reducing training cost and inference latency by 3.0-fold and 2.7-fold.SemanticVLA is open-sourced and publicly available at https://github.com/JiuTian-VL/SemanticVLA
Sponsored by Paperpile, the PDF & BibTeX manager trusted by top AI labs.
Get 30 days free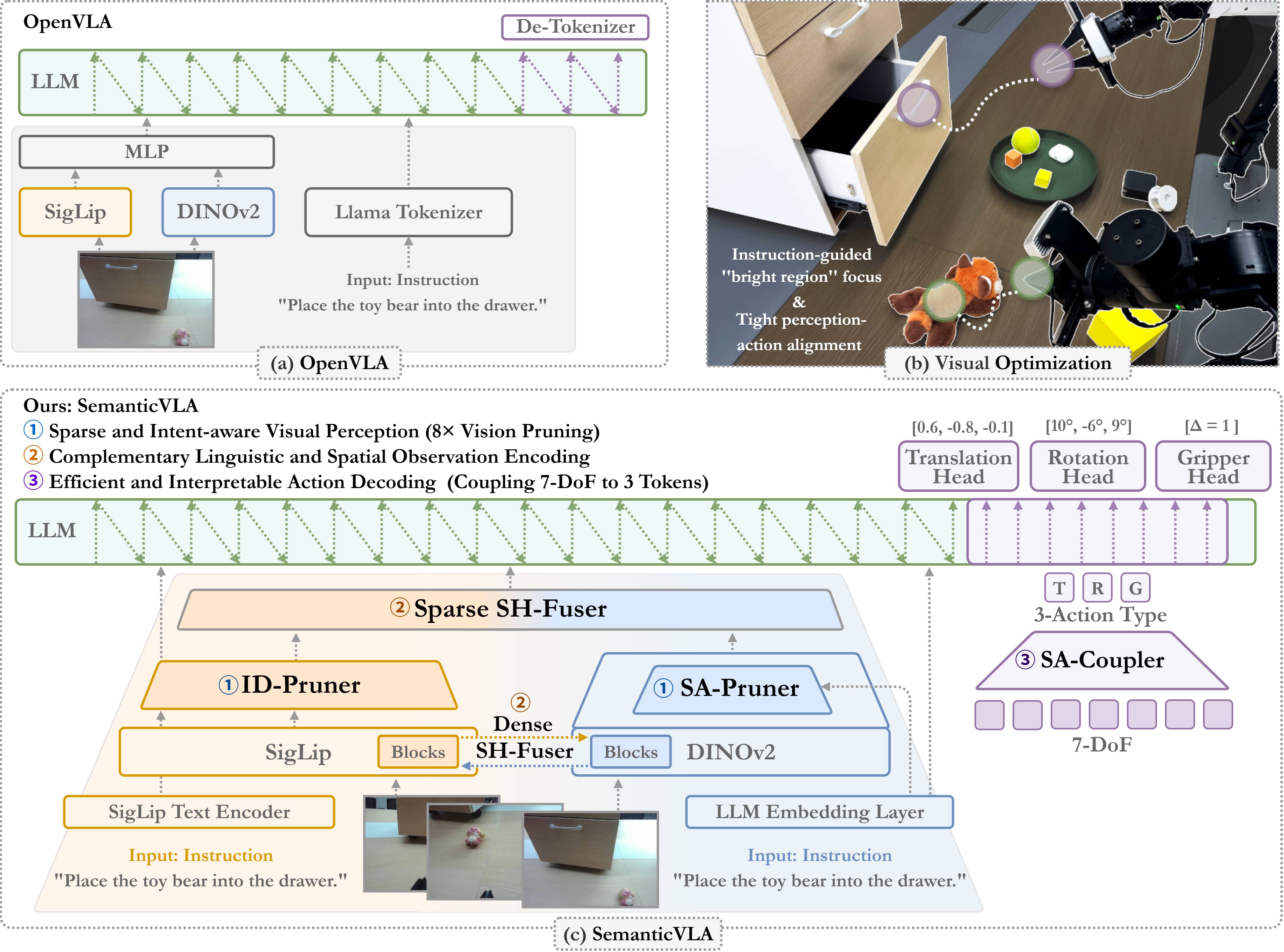




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SemanticVLA: A simple explanation for teens
What is this paper about?
This paper is about teaching robots to understand what they see, what we tell them to do, and how to move their arms and grippers to get tasks done. It introduces a system called SemanticVLA that helps robots focus on the important parts of an image and instruction, so they can act faster, smarter, and with less computer power.
What questions does the paper try to answer?
The authors focus on two big problems that current robot systems face:
- Robots waste time looking at every pixel in an image, even if most of it (like the background) isn’t useful for the task.
- Robots don’t always “connect the dots” between the instruction (like “put the red block in the blue box”) and the parts of the image that matter (where the red block and blue box actually are).
They ask: Can we make a robot’s vision and actions more efficient by:
- Keeping only the most useful visual information,
- Making sure the robot’s understanding of the instruction matches what it sees,
- And turning that understanding into clear, well-structured actions?
How does the method work?
Think of the robot as having a pair of smart eyes and a brain that plans actions. SemanticVLA teaches the robot to declutter what it sees and align it tightly with the instruction, then act efficiently. It has three main parts:
Before the list below, here’s a simple analogy: Imagine you’re cooking with a recipe. You don’t stare at every item in the kitchen—you quickly find the ingredients the recipe mentions, glance at where they are on the counter, and then decide how to chop, stir, or bake. SemanticVLA helps the robot do the same.
- Semantic-guided Dual Visual Pruner (SD-Pruner)
- Purpose: Remove visual “noise” and keep only the important bits.
- How it works:
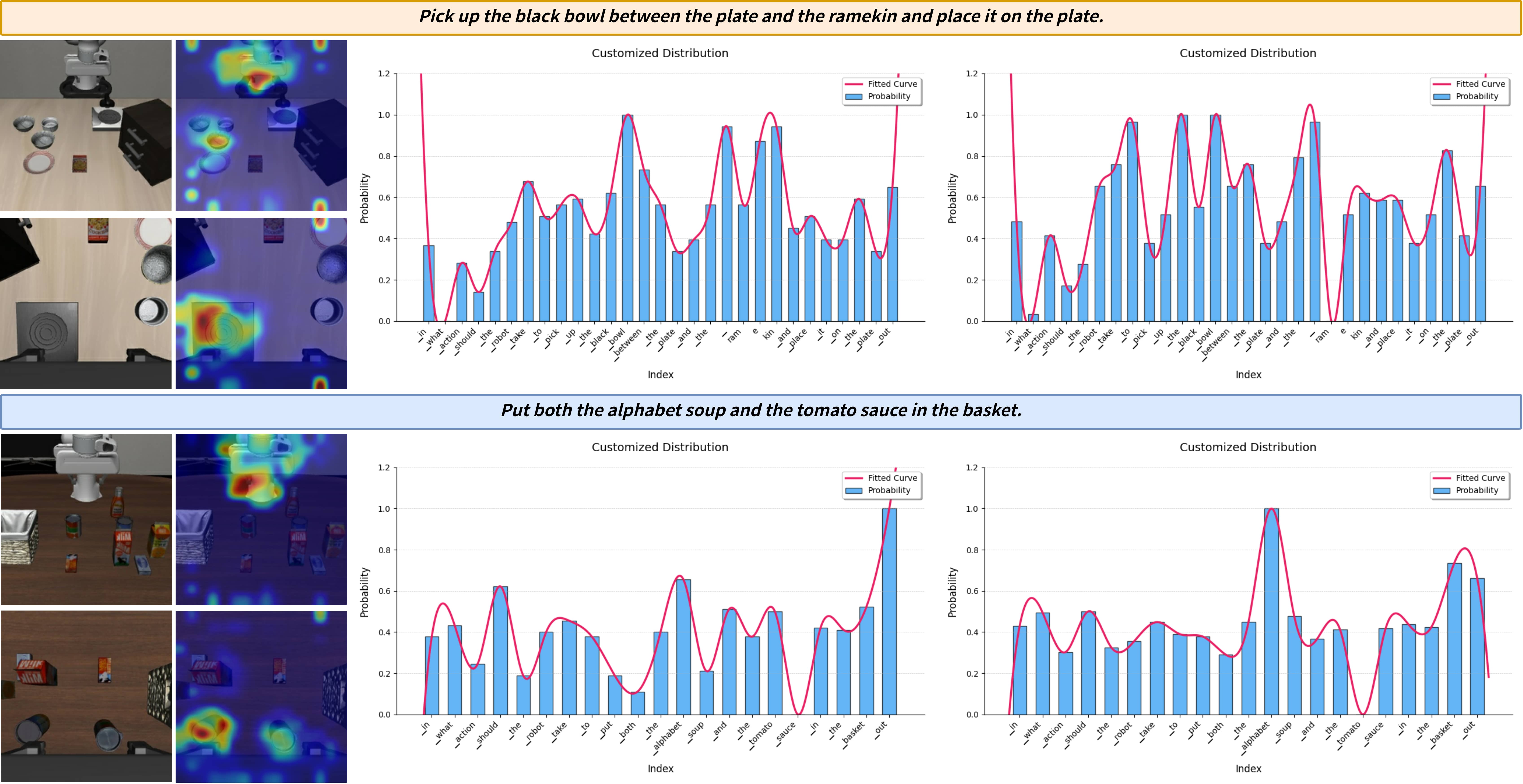
- Instruction-driven Pruner (ID-Pruner): This uses a model called SigLIP, which is good at connecting text and images. It scores how much each piece of the image relates to the instruction, like a spotlight that highlights “red block,” “blue box,” or “pull the drawer.” It keeps global clues from the instruction and the most relevant image regions (local anchors).
- Spatial-aggregation Pruner (SA-Pruner): This uses another model called DINOv2, which is great at understanding shapes and layout (geometry). It bundles nearby image patches into compact “summary tokens,” like neatly stacking similar items together, and lightly adjusts them based on the instruction so they stay relevant.
- Semantic-complementary Hierarchical Fuser (SH-Fuser)
- Purpose: Combine the two “eyes” (SigLIP for instruction alignment and DINOv2 for geometry) into one coherent picture.
- How it works: It fuses features at multiple levels—early and late—so the robot understands both what matters (semantics) and where it is (spatial structure). Think of it as overlaying the recipe instructions on a kitchen map and updating both as you go.
- Semantic-conditioned Action Coupler (SA-Coupler)
- Purpose: Turn the fused understanding into efficient actions.
- How it works: Instead of treating each small movement separately, it groups actions into three meaningful “control knobs”: translation (move), rotation (turn), and gripper (open/close). This makes decisions faster and easier to understand, like having three sliders to control the robot’s hand rather than seven separate dials.
A key idea throughout is “sparsification”: the robot keeps fewer but better visual tokens (small chunks of image information) and fewer action tokens, which saves time and computing power without losing what’s important.
What did they find, and why is it important?
In both simulations and real-world tests, SemanticVLA was more accurate and faster than strong existing systems.
- Better task success:
- On a popular robot benchmark called LIBERO, SemanticVLA beat a leading model (OpenVLA) by 21.1% in success rate.
- Overall success reached about 97.7% in simulation across tasks like spatial reasoning, object understanding, goal following, and long step-by-step tasks.
- In real robot tests (like placing objects, opening/closing drawers, and folding a T-shirt), it achieved up to 77.8% success, higher than other advanced methods tested.
- Much more efficient:
- It reduced training cost by about 3× and cut the time it takes to act (latency) by about 2.7×.
- It used far fewer visual tokens (often 8–16 times fewer) and fewer action tokens (3 instead of 7), leading to higher speed without losing accuracy.
Why this matters:
- Robots can run faster on cheaper hardware, which is crucial for real-world use (like homes, warehouses, hospitals).
- The system is more interpretable: you can see which instruction words and image regions guided the decision, which helps with debugging and safety.
- It handles cluttered, noisy scenes better, which is what real environments are like.
What could this lead to?
SemanticVLA points toward robots that:
- Follow complex instructions more reliably,
- Work efficiently in messy, changing environments,
- Are easier to trust because we can understand what they’re focusing on and why.
In the long run, these ideas could make everyday robots more practical—helping with household chores, assisting in small businesses, speeding up warehouse tasks, or supporting healthcare—while using less power and being easier to control and explain.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what the paper leaves uncertain, missing, or unexplored, formulated to guide concrete future work.
- Adaptive pruning policy design: The ID-Pruner relies on top-k/h token selection based on cosine similarity, but k, h, and sparsification ratio R are fixed. How to learn or adapt these hyperparameters online to task complexity, occlusion level, or instruction ambiguity without manual tuning?
- Robustness of instruction-to-vision similarity: The approach assumes SigLIP similarity faithfully captures semantic relevance. What happens under out-of-domain language, paraphrases, noisy/ambiguous instructions, or multi-sentence prompts? Quantify failure modes and propose calibration or confidence-aware gating.
- Sensitivity to misalignment and spurious correlations: Provide stress tests showing how ID-Pruner behaves when salient words (e.g., colors, shapes) are wrong, missing, or contradict the scene; measure error cascades into action decoding.
- Token selection granularity and spatial coverage: Hard pruning may drop context needed for collision avoidance or obstacle awareness. Study coverage guarantees and design mechanisms to preserve safety-critical peripheral context.
- Aggregation token design in SA-Pruner: The number and initialization of aggregation tokens (e.g., N/8) are heuristic. Explore learned token counts, placement, and training objectives (e.g., coverage/diversity losses) for geometry preservation under varying scene complexity.
- FiLM conditioning sufficiency: The SA-Pruner uses lightweight FiLM modulation for instruction relevance. Evaluate whether stronger cross-attention or multi-head conditioning improves semantic-geometry alignment without negating efficiency gains.
- Fusion architecture choices and placement: SH-Fuser uses MLP concat at selected depths, but the number/positions of fusion blocks and alternatives (cross-attention, gating, residual adapters) are not ablated. Systematically compare fusion strategies, quantify trade-offs, and derive design principles.
- Separate impact of Dense-Fuser vs. Sparse-Fuser: The paper reports combined gains but does not isolate the contributions of dense vs. sparse fusion. Provide ablations that tease apart their effects across task types (spatial, object, long-horizon).
- Theoretical or principled analysis of sparsification: Beyond FLOPs and SR, there is no formal analysis of representation fidelity or bounds on task-relevant information retained. Develop metrics/guarantees for semantic coverage and geometric completeness under pruning.
- Generalization across sensors and modalities: Experiments use RGB and proprioception only. Assess benefits of depth, stereo, event cameras, tactile/force feedback, or point clouds; extend pruning/fusion to multi-modal inputs and quantify gains in cluttered/low-light/transparent-object settings.
- Multi-view and temporal modeling: The approach appears frame-centric. Explore leveraging multi-camera views and explicit temporal dynamics (e.g., token tracking, memory modules) to stabilize long-horizon tasks and address occlusions.
- Closed-loop stability and replanning: The model predicts chunks of K actions in parallel, but the policy’s closed-loop behavior, replanning cadence, and stability under perturbations are not analyzed. Provide evaluations of recovery behaviors, control smoothness, and drift over long horizons.
- Choice and effect of chunk length K: No ablation on K (actions per chunk), its interaction with sparsification, or its effect on latency and success rate. Optimize K for different task classes and hardware constraints.
- Interpretability beyond attention maps: Claims of interpretability are supported by visualizations, but no quantitative metrics (e.g., localization accuracy, token-importance faithfulness, attribution robustness). Establish standardized interpretability measures for VLA pipelines.
- Safety evaluation and risk mitigation: There is no analysis of collision rates, near-misses, or safety constraints under pruning-induced perception loss. Incorporate safety monitors or conservative priors and report safety metrics alongside SR.
- Sample efficiency and data scaling: The model is evaluated on relatively large demonstration sets; no paper of performance with fewer demos or noisy teleoperation. Measure sample efficiency and propose semi/self-supervised or data augmentation schemes compatible with pruning.
- Domain shift and deployment on resource-limited hardware: All training uses 8× A800 GPUs; edge deployment on CPUs/Jetson-class devices and robustness to real-world distribution shifts (lighting, backgrounds) are not studied. Provide benchmarks and adaptation strategies for low-cost platforms.
- Cross-robot generalization: Real-world tests use AgileX Cobot Magic only. Assess transfer to robots with different kinematics, grippers, and control frequencies; analyze how SA-Coupler maps to heterogeneous action spaces.
- Action-space constraints and smoothness: SA-Coupler regresses continuous parameters but does not enforce kinematic limits, collision constraints, or trajectory smoothness. Integrate constraint-aware heads or differentiable controllers; report jerk/energy/contact metrics.
- Language coverage and multilingual/speech inputs: Instructions are textual and likely English; robustness to ASR errors, multilingual commands, and colloquial phrasing is untested. Evaluate and adapt ID-Pruner similarity under multilingual or spoken inputs.
- Failure case characterization: The paper lacks systematic error taxonomy (e.g., mislocalization, wrong action type, temporal misordering). Provide per-task failure analyses to guide targeted improvements.
- Fairness and reproducibility in baselines: Some baselines are reproduced; training data, hyperparameters, and decoding settings may not be perfectly matched. Release full training scripts/configs and add controlled comparisons to ensure fairness.
- Ablation of proprioception usage: The role and integration method of the robot state q are not examined. Evaluate how q contributes to success, and test alternative fusion mechanisms with perception tokens.
- Portability across encoders: The design hinges on SigLIP and DINOv2 specialization. Test substituting other vision-language encoders (e.g., Qwen-VL, LLaVA variants) and self-supervised backbones, and paper how specialization affects pruning effectiveness.
- Long-horizon task planning vs. action prediction: The method focuses on action decoding efficiency, but integration with explicit planners (e.g., task graphs, reflection/replanning loops) is not explored. Investigate hybrid planning-control schemes with SemanticVLA as a low-level policy.
- Hyperparameter and training stability: Details on optimizer, learning rates, and convergence behavior for the pruners/fuser are limited. Report training stability, variance across seeds, and sensitivity analyses.
- Energy/compute footprint and environmental impact: Efficiency is reported in FLOPs/latency, but not energy consumption or carbon footprint. Provide measurements to support sustainable deployment claims.
- Token economy under extreme sparsification: At R=32× performance drops; what minimal token budget preserves safety and task success? Develop adaptive minimums and fallback strategies when confidence is low.
- Online adaptation and lifelong learning: LIBERO targets knowledge transfer, but SemanticVLA’s ability to incrementally learn new objects/tasks without catastrophic forgetting is not evaluated. Propose continual learning mechanisms compatible with pruning/fusion.
- Task diversity and complexity: Real-world tasks are limited (placement, drawer, T-shirt). Evaluate on harder deformable manipulation (cables, bags), transparent/reflective objects, and human-robot interaction scenarios to stress semantic-grounding claims.
Practical Applications
Overview
Based on the paper’s findings and innovations—Semantic-guided Dual Visual Pruner (SD-Pruner), Semantic-complementary Hierarchical Fuser (SH-Fuser), and Semantic-conditioned Action Coupler (SA-Coupler)—the following applications translate the demonstrated efficiency (up to 3.0× lower training cost and 2.7× lower inference latency) and performance gains (e.g., 21.1% success-rate improvement over OpenVLA on LIBERO; 77.8% success in real-world tasks) into actionable use cases. Each item names relevant sectors, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These applications can be deployed now, leveraging reported simulation and real-world performance.
- Drop-in acceleration and robustness upgrade for existing VLA-based robot cells
- Sectors: manufacturing, logistics/warehousing, electronics kitting
- What: Replace OpenVLA/PD-VLA stacks with SemanticVLA or SemanticVLA-Lite to cut latency and GPU cost while improving success rate.
- Tools/workflows: ROS 2 node integration; containerized deployment; TensorRT/ONNX export for encoders; Isaac Sim/Isaac ROS pipelines; CI for regression tests on token sparsity ratios.
- Assumptions/dependencies: Availability of SigLIP and DINOv2 weights; camera calibration; similar task distributions to training data; real-time GPU or edge module (e.g., Jetson) capacity.
- Natural-language-driven bin picking and kitting with fewer errors under clutter or occlusion
- Sectors: logistics/e-commerce fulfillment, contract manufacturing
- What: Use ID-Pruner to focus on instruction-relevant SKUs (“pick the blue widget from bin B3”), while SH-Fuser preserves spatial geometry for reliable grasping.
- Tools/workflows: WMS/ERP adapter that generates task instructions; SKU synonym dictionary; pose estimation and grasp planner downstream.
- Assumptions/dependencies: Domain-adapted fine-tuning for SKU appearance; high-quality RGB feed; stable lighting; text instruction clarity.
- Retail restocking and planogram compliance requiring drawer/shelf interaction
- Sectors: retail operations, merchandising audits
- What: Execute drawer opening, placement, and arrangement tasks demonstrated in the paper; use SA-Coupler for interpretable logs of translation/rotation/gripper actions for compliance tracking.
- Tools/workflows: Store map and planogram parser to natural-language tasks; compliance checkers; telemetry dashboards.
- Assumptions/dependencies: Shelf/drawer geometry variability; safe force limits; restricted customer interaction zones.
- Cobot-assisted flexible assembly and changeover with semantic action logging
- Sectors: small-batch manufacturing, high-mix/low-volume assembly
- What: Use SA-Coupler’s action-type tokens to log and audit fine motion primitives; quickly adapt to new instructions (e.g., “rotate 45° and insert peg”).
- Tools/workflows: Safety PLC integration; digital work instructions converted to language prompts; trajectory auditing tools keyed by action-type tokens.
- Assumptions/dependencies: Reliable grasp/tooling; safety-certified control stack; stable fixturing.
- Home service tasks: tidying, opening storage, laundry folding
- Sectors: home robotics, eldercare assistance
- What: Deploy SemanticVLA-Lite for low-latency household manipulation (drawers/doors, placing objects, clothing folding).
- Tools/workflows: Voice-to-text for instructions; on-device inference; fallback teleop.
- Assumptions/dependencies: Significant environment/domain variability; safety with fragile/unknown objects; robust voice/text interfaces.
- Lab robotics: drawer/incubator access and sample placement
- Sectors: life-science labs, biobanking, diagnostics
- What: Use instruction-aware sparsification for precise access to drawers/slots and consistent placement of plates/tubes.
- Tools/workflows: LIMS-to-instruction bridge; calibrated racks; contamination-aware gripper control.
- Assumptions/dependencies: Sterility constraints; accuracy tolerances; tool changers for specialized lab end-effectors.
- Shared autonomy and teleoperation assistance with low latency
- Sectors: field robotics, remote operations, manufacturing support
- What: Combine human intent (high-level instruction) with SA-Coupler’s modular control for smooth blending; faster response in edge-constrained links.
- Tools/workflows: Teleop UI overlays; authority allocation manager; explainability via action-type overlays.
- Assumptions/dependencies: Reliable comms; human-in-the-loop safety procedures; latency budgets.
- On-device/edge inference to reduce cost and energy
- Sectors: mobile manipulation, RaaS providers, sustainability-focused operations
- What: Run SemanticVLA-Lite on Jetson-class devices, enabled by 8×–16× token reduction; minimize cloud dependence.
- Tools/workflows: Quantization/INT8 pipelines; power monitoring; battery sizing models.
- Assumptions/dependencies: Edge hardware support for SigLIP/DINOv2 or equivalent; careful calibration of sparsification ratio vs. task difficulty.
- Cost-effective training for smaller labs and startups
- Sectors: academia, SMB robotics startups
- What: Leverage ~3× lower training FLOPs/cost to iterate on domain-specific datasets (e.g., LIBERO-like demos, in-house teleop data).
- Tools/workflows: Data collection via teleop; instruction templating; ablation utilities (vary sparsification ratio, fuser depth).
- Assumptions/dependencies: Sufficient demonstrations (tens to hundreds per skill); access to multi-GPU training (or longer single-GPU schedules).
- Perception acceleration middleware for VLM-based robot workloads
- Sectors: software tools for robotics, integrators
- What: Package SD-Pruner + SH-Fuser as a “semantic sparsification” module that sits between camera streams and any VLM policy to cut compute while preserving task-critical cues.
- Tools/workflows: ROS 2 perception node; APIs for token importance maps; monitoring of sparsity vs. success-rate curves.
- Assumptions/dependencies: Compatibility with target VLM backbones; validation on new camera modalities and FOVs.
Long-Term Applications
These require additional research, scaling, safety validation, or ecosystem development before broad deployment.
- Multimodal fusion beyond RGB: depth, tactile, force/torque, thermal
- Sectors: precision assembly, delicate handling (food/pharma), search-and-rescue
- What: Extend SH-Fuser to integrate tactile/force and depth for contact-rich tasks (press-fit, cable routing).
- Tools/workflows: Cross-sensor calibration; multimodal dataset collection; real-to-sim domain randomization.
- Assumptions/dependencies: High-quality multimodal sensors; robust fusion training; latency budgets with added modalities.
- Bimanual mobile manipulation in dynamic human environments
- Sectors: hospitals, hospitality, facility services
- What: Combine mobile base + dual arms with instruction-aware sparsification to handle long-horizon chores (delivery, room turnover).
- Tools/workflows: Global-local planner coupling; speech instructions; people-aware safety zones.
- Assumptions/dependencies: Complex safety certification; robust navigation-manipulation coordination; variable lighting/occlusions.
- Surgical and medical-assistive robots with interpretable action semantics
- Sectors: healthcare, rehabilitation
- What: Use SA-Coupler for traceable, semantically structured motion logs that support clinical audit and safety layers.
- Tools/workflows: Surgeon-in-the-loop control; haptics; regulatory-grade logging.
- Assumptions/dependencies: Strict regulatory approvals; ultra-high reliability; domain datasets and specialty instruments.
- Disassembly and high-precision recycling for circular economy
- Sectors: e-waste recycling, remanufacturing
- What: Instruction-aligned focus on specific fasteners/components; geometry-aware manipulation for delicate removal.
- Tools/workflows: CAD-to-instruction mapping; torque/visual feedback loops; component classifiers.
- Assumptions/dependencies: Fine-grained annotated datasets; specialized tooling; variable device designs.
- Agricultural manipulation under occlusion and deformability
- Sectors: agriculture (harvest, pruning, thinning)
- What: ID-Pruner and SA-Pruner synergy helps target partially occluded produce and manage deformable plants.
- Tools/workflows: Outdoor-ready sensors; season-specific fine-tuning; soft grippers.
- Assumptions/dependencies: Weather/lighting variability; safety around humans; crop diversity.
- Standardization and policy: energy-efficient embodied AI and safety reporting
- Sectors: policy/regulation, sustainability compliance
- What: Establish token-sparsity metrics and action-type logs as standard evidence for energy efficiency and safety audits.
- Tools/workflows: Benchmarking suites (LIBERO-like) extended with power meters; compliance dashboards.
- Assumptions/dependencies: Multi-stakeholder consensus; reproducible methodologies; vendor cooperation.
- Multi-robot collaboration via semantic token sharing
- Sectors: intralogistics, construction, inspection
- What: Share instruction-aligned sparse tokens across robots to coordinate tasks (handoffs, joint lifts) with minimal bandwidth.
- Tools/workflows: Token exchange protocols; task allocation via semantic priorities; edge mesh networks.
- Assumptions/dependencies: Reliable comms; synchronization; cross-platform token compatibility.
- Foundation model services and SDKs for Robotics-as-a-Service
- Sectors: software platforms, integrators
- What: Offer a hosted fine-tuning service and on-prem SDK that exposes SD-Pruner/SH-Fuser/SA-Coupler as modular APIs with profiling and auto-tuning of sparsification ratio.
- Tools/workflows: MLOps pipelines; usage-based billing; fleet telemetry.
- Assumptions/dependencies: Data privacy agreements; domain adaptation cost; long-term support.
- Extending instruction-aware sparsification to drones and AR assistants
- Sectors: inspection (drones), wearable AR for technicians
- What: Apply SD-Pruner to prioritize instruction-relevant regions for real-time guidance or visual search.
- Tools/workflows: On-device pruning for monocular/thermal feeds; voice-to-instruction; AR overlays of salient regions.
- Assumptions/dependencies: Different motion/observation dynamics; domain shifts; limited onboard compute.
- Safety layers built on interpretable action types and formal verification
- Sectors: high-stakes automation (nuclear, chemical plants), autonomous labs
- What: Use SA-Coupler’s explicit translation/rotation/gripper channels to enforce formal safety constraints and perform run-time verification.
- Tools/workflows: Constraint solvers; runtime monitors; incident replay using semantic logs.
- Assumptions/dependencies: Mature formal methods; high-fidelity plant models; rigorous certification paths.
Notes on Feasibility and Dependencies
- Data and domain adaptation: Performance depends on demos/instructions representative of deployment tasks; some sectors require specialized datasets (e.g., medical, recycling).
- Hardware: While training used multi-GPU servers, deployment is feasible on edge with SemanticVLA-Lite; careful quantization and profiling recommended.
- Sensors and calibration: Robustness requires well-calibrated cameras and, for future multimodal use, synchronized depth/tactile/force sensors.
- Licensing and IP: Ensure compatible licenses for SigLIP, DINOv2, and any derived checkpoints; verify open-source compliance for commercial use.
- Safety and compliance: For human-facing or regulated domains, add safety-certified controllers, force/torque limits, and human-in-the-loop reviews; leverage SA-Coupler’s interpretability for audits.
- Instruction interfaces: Natural-language clarity matters; consider constrained vocabularies or confirmation prompts in high-risk tasks.
- Monitoring and auto-tuning: Maintain dashboards for token sparsity vs. success rate; auto-tune sparsification ratios per task complexity to balance speed and accuracy.
Glossary
- Affine transformation parameters: Scale and shift parameters applied to features for conditioning; for example, in FiLM modulation. "produce affine transformation parameters (scale and shift )"
- Aggregation tokens: Auxiliary tokens that collect and compress spatial information within a transformer. "zero-initialized aggregation tokens"
- Autoregressive action decoding: A sequential decoding strategy where each action depends on previously generated actions. "their reliance on autoregressive action decoding introduces substantial efficiency bottlenecks."
- Binned tokens: Discrete token representations of continuous action dimensions, typically one per degree of freedom. "discretizes 7-DoF actions into 7 independent binned tokens"
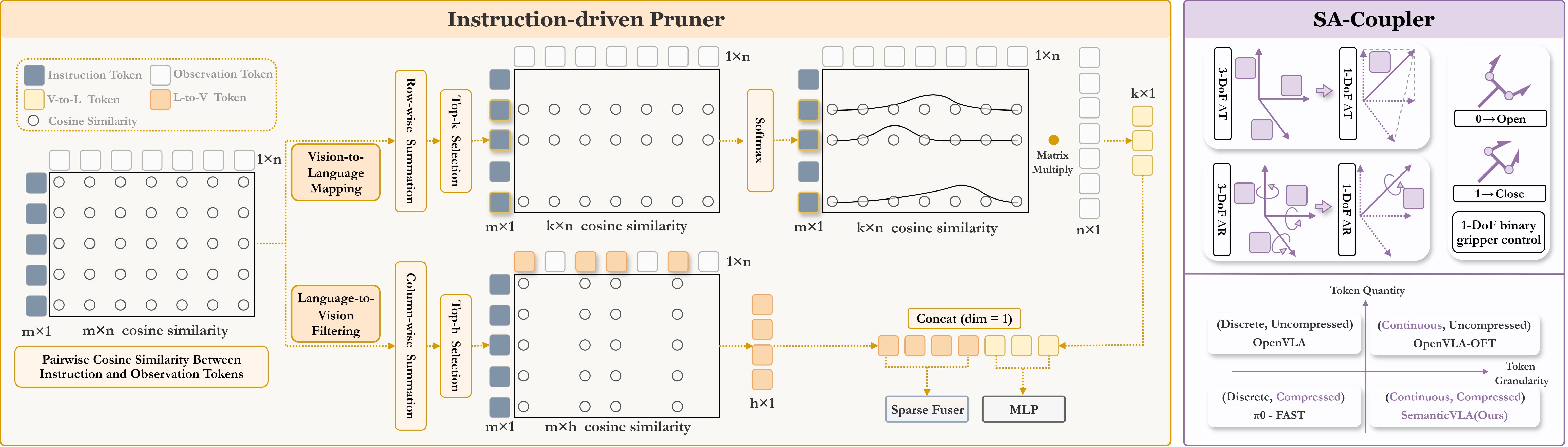
- Cosine similarity matrix: A matrix of cosine similarities measuring alignment between instruction and visual tokens. "Cosine Similarity Matrix Construction."
- Degrees of Freedom (DoF): The number of independent motion parameters in a control action. "3-DoF translation, 3-DoF rotation, and gripper control"
- DINOv2: A self-supervised vision transformer used to capture robust, dense geometric features. "a DINOv2-based spatial encoder that captures dense geometric features via SA-Pruner."
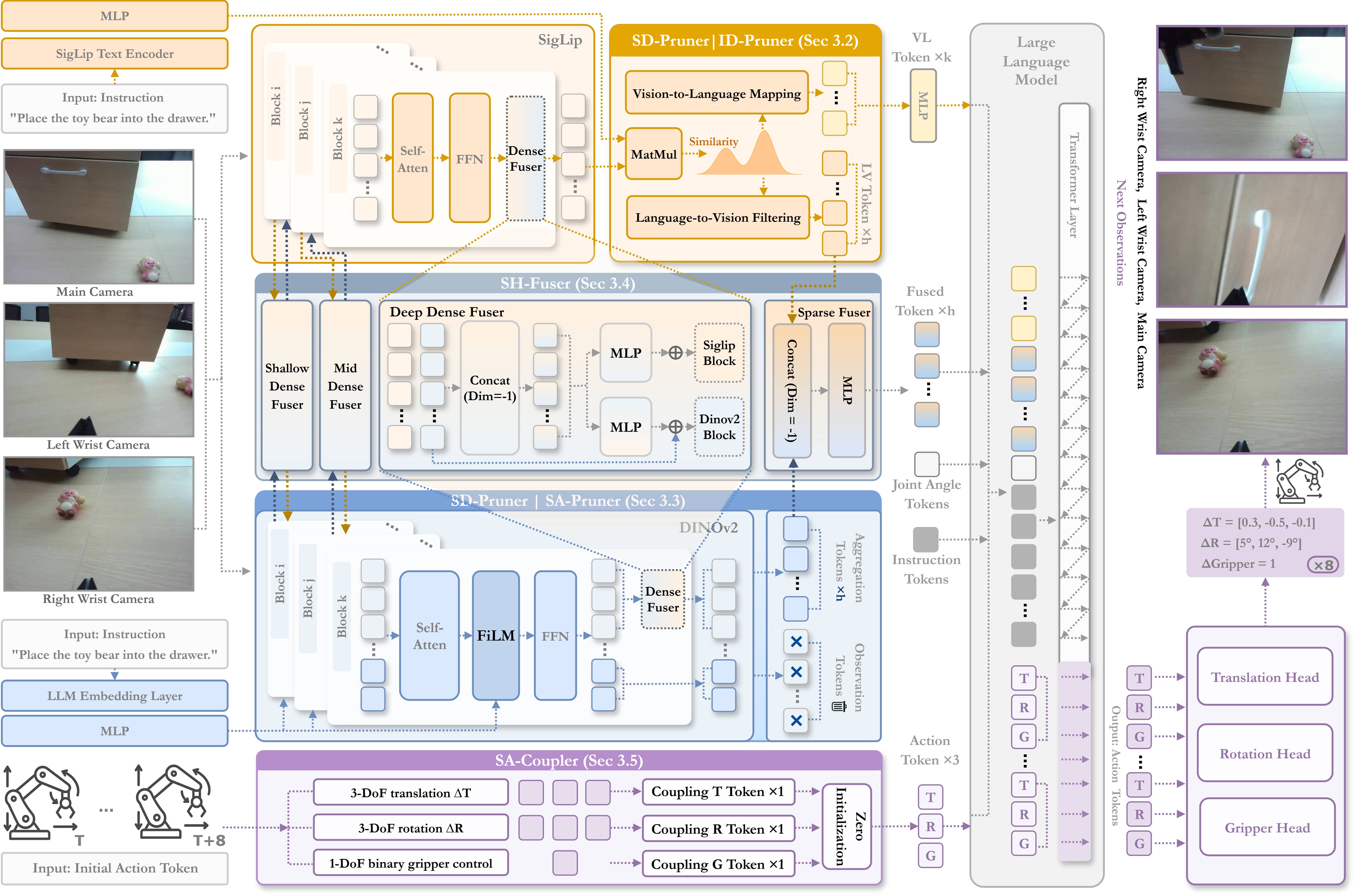
- FiLM: Feature-wise Linear Modulation; applies learned scale and shift to features conditioned on instructions. "further modulated via FiLM~\cite{perez2018film} to reflect instruction relevance"
- Flow-matching: A generative modeling mechanism used as an alternative to diffusion for action prediction. "leverage diffusion or flow-matching mechanisms for high-frequency action prediction."
- Gripper control: Control of the robot end-effector’s open/close state as part of the action vector. "and gripper control"
- Instruction grounding: Aligning language instructions with visual semantics to guide perception. "SigLIP~\cite{siglip} for instruction grounding and DINOv2~\cite{dinov2} for spatial geometry"
- Instruction-driven Pruner (ID-Pruner): A pruning module that filters visual tokens based on instruction-visual similarity to retain salient cues. "Instruction-driven Pruner (ID-Pruner) extracts global action cues and local semantic anchors in SigLIP;"
- Language-to-Vision Filtering: A pathway that selects visual regions most responsive to the overall instruction. "Language-to-Vision Filtering enhances local semantic anchors from complete visual inputs"
- LLM: A generative model used for reasoning and decoding actions from multimodal inputs. "visual input to the LLM as a composite token set"
- LIBERO benchmark: A standardized suite for evaluating robot manipulation and transfer learning performance. "SemanticVLA surpasses OpenVLA on LIBERO benchmark by 21.1\% in success rate,"
- Long-horizon tasks: Multi-stage tasks requiring extended sequences of actions and reasoning. "on three challenging long-horizon tasks"
- Parallel decoding: Generating multiple actions concurrently in a single forward pass to improve efficiency. "accelerates parallel decoding via action type coupling"
- Proprioceptive state: The robot’s internal sensing of its own configuration and motion. "represents the robot's current proprioceptive state (e.g., joint angles and end-effector pose)"
- Register design: The use of dedicated register-like tokens to aggregate information within transformer models. "Inspired by the register design in previous work"
- Semantic-complementary Hierarchical Fuser (SH-Fuser): A fusion module combining dense spatial and sparse semantic features across encoders. "Semantic-complementary Hierarchical Fuser (SH-Fuser) fuses dense patches and sparse tokens across SigLIP and DINOv2 for coherent representation."
- Semantic-conditioned Action Coupler (SA-Coupler): A structured action-head design that maps perception to semantic action types (translation, rotation, gripper). "Semantic-conditioned Action Coupler (SA-Coupler) replaces the conventional observation-to-DoF approach"
- Semantic-guided Dual Visual Pruner (SD-Pruner): A dual-branch pruner that jointly sparsifies SigLIP and DINOv2 features guided by task semantics. "Semantic-guided Dual Visual Pruner (SD-Pruner) performs:"
- SigLIP: A language-image pretraining model used for instruction-aware visual encoding and grounding. "instruction-aware encoding via SigLIP-based Instruction-driven Pruner"
- Sparse-Fuser: The late-stage fusion component that merges salient tokens from pruned streams into a compact representation. "Sparse-Fuser merges the salient outputs from both pruning paths,"
- Spatial-aggregation Pruner (SA-Pruner): A module that compacts DINOv2’s spatial features into geometry-rich task-adaptive tokens. "Spatial-aggregation Pruner (SA-Pruner) compacts geometry-rich features into task-adaptive tokens in DINOv2."
- Token pruning: The process of removing non-essential tokens to reduce computation while retaining salient information. "greatly improves computational efficiency (through token pruning)"
- Vision-Language-Action (VLA): Models that map visual inputs and language instructions to robotic actions. "Vision-Language-Action (VLA) models have advanced in robotic manipulation,"
- Vision-to-Language Mapping: A pathway aligning visual patches to key instruction tokens to extract global action cues. "Vision-to-Language Mapping preserves global action cues"
Collections
Sign up for free to add this paper to one or more collections.