Parcae: Scaling Laws For Stable Looped Language Models
Abstract: Traditional fixed-depth architectures scale quality by increasing training FLOPs, typically through increased parameterization, at the expense of a higher memory footprint, or data. A potential alternative is looped architectures, which instead increase FLOPs by sending activations through a block of layers in a loop. While promising, existing recipes for training looped architectures can be unstable, suffering from residual explosion and loss spikes. We address these challenges by recasting looping as a nonlinear time-variant dynamical system over the residual stream. Via a linear approximation to this system, we find that instability occurs in existing looped architectures as a result of large spectral norms in their injection parameters. To address these instability issues, we propose Parcae, a novel stable, looped architecture that constrains the spectral norm of the injection parameters via discretization of a negative diagonal parameterization. As a result, Parcae achieves up to 6.3% lower validation perplexity over prior large-scale looped models. Using our stable looped architecture, we investigate the scaling properties of looping as a medium to improve quality by increasing FLOPs in training and test-time. For training, we derive predictable power laws to scale FLOPs while keeping parameter count fixed. Our initial scaling laws suggest that looping and data should be increased in tandem, given a fixed FLOP budget. At test-time, we find that Parcae can use looping to scale compute, following a predictable, saturating exponential decay. When scaled up to 1.3B parameters, we find that Parcae improves CORE and Core-Extended quality by 2.99 and 1.18 points when compared to strong Transformer baselines under a fixed parameter and data budget, achieving a relative quality of up to 87.5% a Transformer twice the size.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to build and train LLMs called Parcae. Instead of making models bigger (adding more parameters), Parcae gets better by “looping” the same block of layers multiple times. Think of it like reusing the same tool several times in a row to do more work, without buying a bigger tool. The big challenge: older looping methods were unstable (they could “blow up” during training). Parcae fixes that instability and shows clear, predictable rules (scaling laws) for how looping improves performance in training and at test time.
What questions does the paper ask?
- How can we safely reuse the same layers many times (looping) to boost quality without increasing the number of parameters?
- Why do earlier looped models sometimes become unstable (numbers explode, loss spikes)?
- Can we make looping stable and predictable, so we know how much benefit to expect when we add more loops during training or testing?
- Does looping give a better way to spend compute compared to only adding data or parameters?
How did they do it? (Methods in plain language)
First, a few key ideas in simple terms:
- Looping layers: Run the same middle part of the model again and again. More loops = more compute (FLOPs), but the model size (parameters) stays the same. FLOPs are just the number of tiny math steps the computer does.
- Residual stream: Imagine a running “memory” of the model through loops. If this memory grows too fast, training becomes unstable.
- Dynamical system: A set of rules that says how something changes step by step. Here, it describes how the model’s internal “memory” changes when you add more loops.
- Stability: Like a volume knob on sound. If the knob is set too high, the signal screeches out of control. In math, this “how much it grows” knob is called the spectral radius (a kind of stretch factor). If it’s greater than 1, things can explode.
What they did:
- They reinterpreted looping as a simple step-by-step system that updates the model’s internal state each loop. When they simplify this system, they can use classic control theory (the math of stability) to see when it blows up.
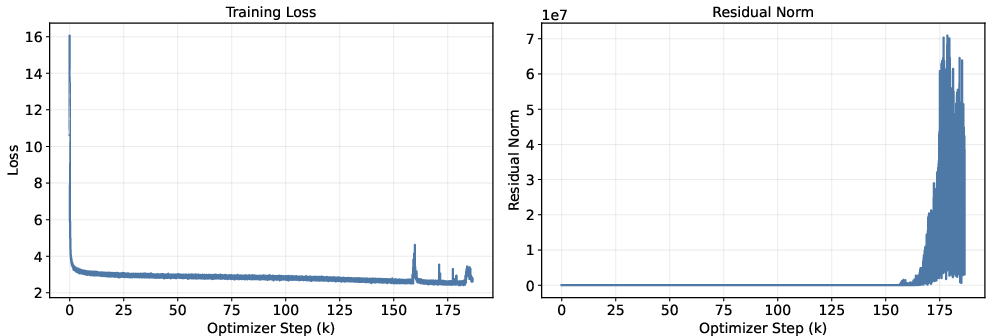
- They discovered earlier looped models could learn “stretch factors” above 1, which makes the internal numbers explode.
- They designed Parcae to prevent that. The trick: force the “stretch factor” to be less than 1 by using a special, safe setting for the dynamics. In practice:
- They parametrize the core update matrix so its “push” is always pulling inward (negative diagonal), which guarantees stability when turned into step-by-step updates. Picture a spring that always pulls you gently back toward center.
- They normalize the input to the loop (so it’s not too big or too small), further reducing spikes late in training.
- They change how loop counts are sampled during training: instead of giving every example in a batch the same number of loops, they vary it per sequence. This evens out randomness and reduces loss spikes.
You can think of Parcae as: safe “loop engine” + consistent “fuel input” + smarter “practice routine” for different loop lengths.
What did they find, and why is it important?
Here are the main results:
- Stability: Parcae trains reliably without the “explosions” seen in older looped models. It is also less sensitive to tricky hyperparameter tuning (like the learning rate).
- Better quality at the same size: Compared to strong looped baselines and standard Transformers with the same parameter and data budgets, Parcae achieves:
- Up to 6.3% lower validation perplexity than prior looped models.
- On larger runs (up to 1.3B parameters), higher benchmark scores (e.g., +2.99 on “CORE” and +1.18 on “Core-Extended”) than same-size Transformers, reaching as much as 87.5% of the quality of a Transformer twice its size.
- Training scaling laws (how to spend your compute during training):
- Looping acts as a new, independent way to scale compute—separate from adding parameters or data.
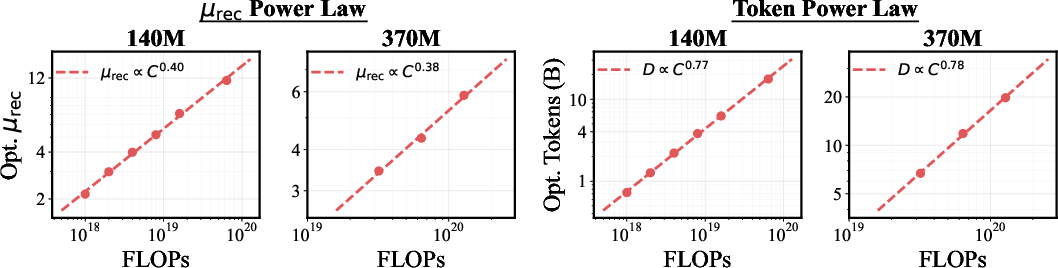
- Given a fixed compute budget, there’s an optimal mix: you should increase both the amount of data and the number of loops together. Their relationship follows predictable “power laws” (simple math curves): as compute grows, the best loop count and the best data amount increase in steady, repeatable ways.
- Test-time scaling laws (what happens if you run extra loops at inference):
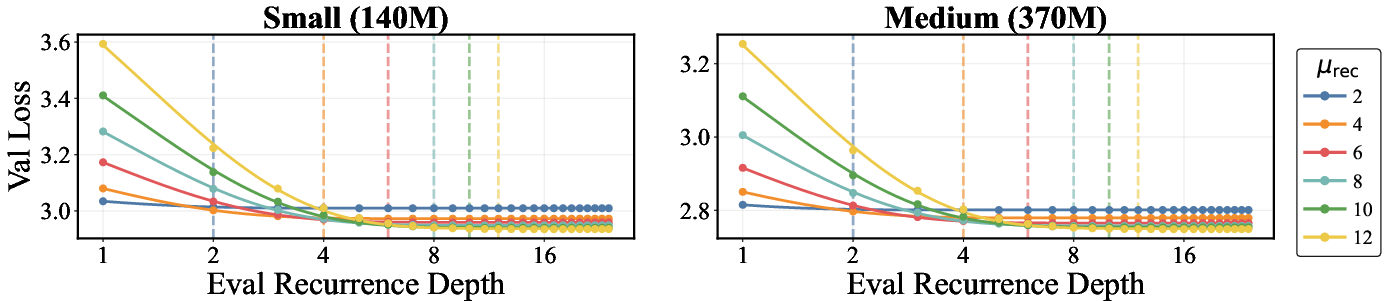
- Doing more loops at test time improves results but eventually levels off (saturates) in a predictable way—like an exponential curve flattening out.
- The “ceiling” you can reach at test time is mostly set by how much looping you trained with. If you trained shallow, you can’t keep gaining forever by looping more at test time.
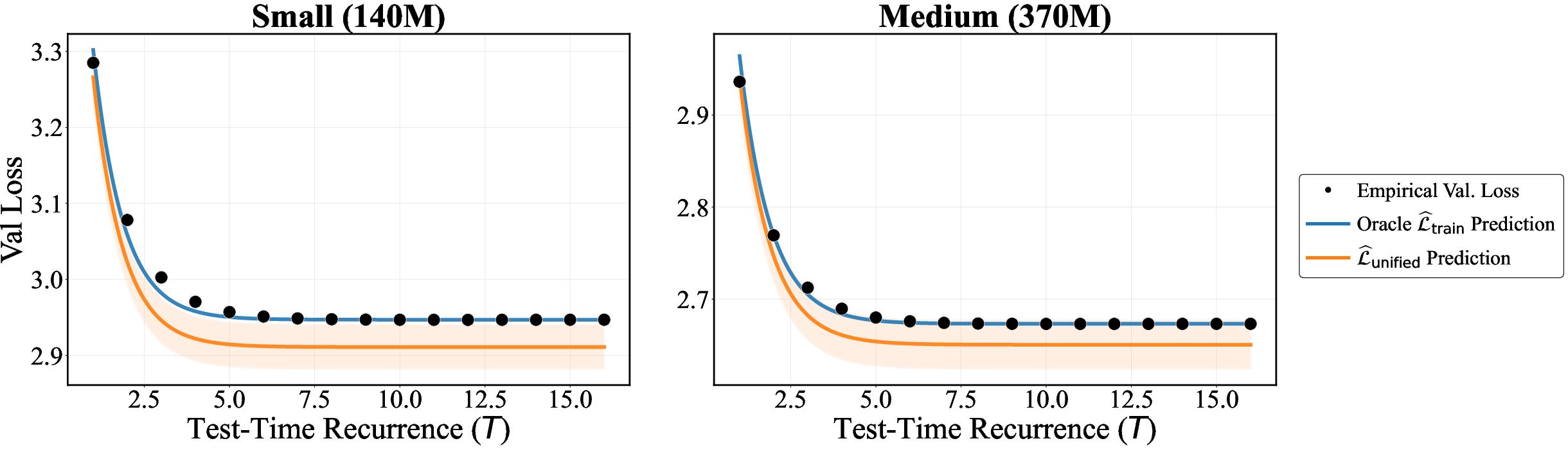
- Unified prediction: They combine the training and test-time laws into one simple formula that predicts performance. In their tests, this predicts results very accurately (within about 1% error), so you can plan compute and know what to expect.
Why it matters:
- You can get better models without growing memory-hungry parameter counts—useful for edge devices or cost-sensitive deployments.
- You get a reliable “recipe” for how to trade off loops, data, and compute, both when training and when serving the model.
What does this mean for the future?
- Efficient deployment: Parcae helps you squeeze more quality from the same-size model by spending extra compute on looping, which is great when memory is limited but compute is available.
- Predictable scaling: The clear scaling laws mean teams can plan their training (how much data vs. how many loops) and test-time budgets with fewer surprises.
- Better reasoning potential: Looped models often show benefits for reasoning. With Parcae’s stability, it’s safer to push looping further and explore adaptive compute (spending more loops only when needed).
- Next steps: Try even bigger training runs, explore different stability-preserving designs, and find ways to keep or improve quality with fewer test-time loops so responses stay fast.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased as concrete gaps that future work can address.
- Global stability of the full non-linear looped system remains unproven. The analysis linearizes the dynamics and constrains only; there is no rigorous guarantee (e.g., via contraction or Lyapunov analysis) that the full system with attention, MLPs, and residual connections remains stable under all training regimes and inputs.
- Expressivity vs. stability trade-off of diagonal . The negative diagonal parameterization stabilizes training but may constrain cross-dimension coupling; it is unclear how much function class is lost relative to full-rank stable parameterizations (e.g., low-rank-plus-diagonal, normal/skew-symmetric with damping) and what impact that has on downstream tasks.
- Discretization choices are underexplored. Only ZOH for and Euler for are used; the effects of alternative integrators (e.g., bilinear/Tustin, higher-order Runge–Kutta, learned step sizes, shared vs. per-dimension step sizes) on stability, optimization, and quality are not studied.
- Lack of theoretical link between the empirical exponential test-time decay and the underlying dynamics. The paper fits but does not derive this decay from model properties (e.g., spectral gaps, contraction rates), nor specify when/why this form should fail.
- Open question: tight conditions under which stability of the linear surrogate implies stability of the non-linear model. Formal sufficient conditions for boundedness/convergence of given constraints on , norms of , Lipschitz constants of the non-linear residual, and normalization choices are not provided.
- Prelude normalization (LN on ) is empirically helpful but theoretically opaque. It is unclear whether its benefit comes from conditioning control (bounded input gains), gradient variance reduction, or other mechanisms; alternative normalizers (RMSNorm, ScaleNorm) and placement (pre/post injection) are not ablated.
- Variance, bias, and sample-efficiency of the per-sequence depth sampling estimator are not analyzed. How many depth samples per batch are needed for a low-variance unbiased estimator of the objective, and how does this interact with learning rate and truncation length?
- Truncated backpropagation choice () lacks principled justification. The impact of truncation on long-range credit assignment, optimization speed, and final performance—relative to alternatives (e.g., implicit differentiation/deep equilibrium, Neumann/CG corrections, UORO/RTRL approximations)—is unclear.
- Distribution over depths is only Poisson-like and untruncated in the main recipe. The effect of alternative depth distributions (e.g., geometric, heavy-tailed) and curriculum schedules on test-time extrapolation, stability, and sample efficiency is not explored.
- No exploration of dynamic halting or token-level adaptive recurrence. The work fixes or samples global depth; it remains unknown whether integrating halting policies/routers (or per-token depth) with Parcae preserves stability and improves compute–quality trade-offs.
- Scaling-law external validity is limited. The training and unified test-time laws are fit at 140M–370M scales (and evaluated up to 1.3B), leaving uncertainty about the coefficients and form at much larger parameter/data/FLOP budgets and across domains.
- Sensitivity of scaling-law exponents to data distribution and task family is unknown. It is unclear if the observed power-law exponents () transfer to code, math, multilingual, long-context, or retrieval-augmented settings.
- Benchmark coverage is narrow for “reasoning” claims. Results emphasize Core/Core-Extended and Lambada; broader reasoning suites (e.g., GSM8K, MATH, BBH, MMLU-Pro), long-context tasks, and tool/use-of-memory tasks are needed to validate latent reasoning benefits.
- Comparative coverage of looped baselines is incomplete. The paper compares primarily to RDM and standard Transformers; rigorous isoFLOP comparisons against other looped variants (e.g., LoopFormer, Mixture-of-Recursions, hierarchical RMs, timestep-encoding methods) and equilibrium models are missing.
- Fairness and completeness of residual-normalization baselines are uncertain. The claim that residual normalization is unnecessary with Parcae would be stronger with broader sweeps (LN variants, tuned hyperparameters) and parity checks on compute and stabilization tricks.
- Hardware-level efficiency and latency trade-offs are not quantified. The paper argues parameter efficiency but does not report tokens/sec, latency per token, energy, or memory footprints (including KV-cache behavior) versus fixed-depth baselines as grows.
- Inference-time compute saturation lacks mitigation strategies. As rises, quality saturates; techniques to approach the training-law floor with fewer steps (e.g., learned step sizes, loop skipping, early-exit confidence, distillation across loops) are not developed.
- Interaction with inference accelerators is untested. Compatibility and benefits with speculative decoding, early-exit (LayerSkip), mixture-of-depths, or caching schemes are open questions.
- Robustness and safety dimensions are unaddressed. There is no evaluation of robustness to distribution shifts, adversarial prompts, noise, or safety/harms, nor analysis of whether looping exacerbates or mitigates such risks.
- Generalization across context lengths is unclear. How looping interacts with very long contexts (attention patterns, memory mechanisms, KV cache growth) and whether stability/quality persists at 32–128K tokens remains open.
- Impact of constraints on attention dynamics is not analyzed. How the stabilized injection changes attention head behaviors, induction patterns, or in-context learning mechanisms is unknown.
- Limited ablations on the number and placement of looped layers. Only “middle-third” looping is tested for Transformer-style models; the effect of looping early/late blocks, different loop unit sizes, or multi-stage/hierarchical loops remains unexplored.
- Interplay between parameters, data, and recurrence as three axes is only partially mapped. Joint optimization over (N, D, μ_rec) under real FLOP/latency constraints (and across regimes) is not solved and may shift the recommended exponents.
- Data dependence and tokenization effects are untested. Results rely on FineWeb-Edu/Huginn; how web-domain mix, dedup, tokenization, or curriculum influence the stability and scaling behavior of looping is unknown.
- Limits of “extreme looping” are not characterized. The behavior, stability, and returns when is pushed much higher (with or without truncation) are left open.
- Unified scaling law validation breadth is limited. The unified law is validated on the same family of models and data; testing its predictive accuracy across architectures, datasets, and training recipes is needed to claim generality.
- Reproducibility and sensitivity analyses are insufficient. Full training curves, seed variability, hyperparameter robustness (beyond learning-rate sweeps), and implementation details (optimizer states, clipping, schedulers) are not exhaustively documented.
Practical Applications
Immediate Applications
The following are concrete, deployable applications that can leverage Parcae’s stability fixes, compute–quality scaling laws, and looped architecture today.
- Memory-constrained deployment with a “compute dial”
- Sectors: software, mobile/edge devices, healthcare, education
- What: Deploy smaller-parameter Parcae models on devices with tight memory budgets and scale quality at inference by increasing recurrence
Twhen latency allows (e.g., “High Accuracy” mode). - Tools/products/workflows:
- API/runtime knob to set
Tper request (e.g., “quality boost” toggle). - Profiles for latency/quality trade-offs (e.g.,
T=2for real-time,T=8for higher accuracy). - Assumptions/dependencies:
- Acceptable latency/energy overhead from larger
T. - Models trained with sufficient training-depth (
μ_rec) to make test-time scaling useful (saturates otherwise). - Device thermal and battery budgets can tolerate added compute.
- Cloud inference cost/latency tiering without larger models
- Sectors: SaaS, customer support, finance, enterprise IT
- What: Use the same (smaller) Parcae model and allocate higher
Tfor premium/critical queries, avoiding loading larger models. - Tools/products/workflows:
- Routing policy: low
Tdefault; increaseTfor ambiguous/high-risk queries. - “Burst compute” tiers tied to SLOs and budgets.
- Assumptions/dependencies:
- Calibrated unified scaling curve to predict diminishing returns and cap
Twhere marginal gains flatten.
- Training stability hardening for looped/recurrent LMs
- Sectors: AI labs, model providers, academia
- What: Adopt Parcae’s negative-diagonal parameterization (constraining the spectral norm), discretization, and prelude normalization to avoid residual explosion and loss spikes.
- Tools/products/workflows:
- Add a “Parcae block” module (PyTorch/JAX) for
A,B,CandLN(P(s)). - Integrate spectral radius monitoring into training dashboards; alert on
ρ(·) ≥ 1. - Assumptions/dependencies:
- Modest engineering to modify existing training code.
- Validation that task-specific heads and optimizers remain compatible.
- Per-sequence depth sampling to reduce loss spikes
- Sectors: AI labs, open-source training stacks
- What: Replace per-microbatch depth sampling with per-sequence sampling to better approximate the expectation over depth and stabilize training.
- Tools/products/workflows:
- Dataloader and microbatching update to sample variable
Tper sequence. - Assumptions/dependencies:
- Minimal framework support required; small changes to data-parallel pipelines.
- Compute-optimal training planning via isoFLOP power laws
- Sectors: MLOps, research, model providers
- What: Use Parcae’s empirical power laws to co-scale data and recurrence (
μ_rec) at fixed FLOP budgets to minimize loss. - Tools/products/workflows:
- Training planner that recommends
(tokens, μ_rec)pairs per budget using fitsL ≈ E + X·N(μ_rec)^(-x) + Y·D^(-y). - Assumptions/dependencies:
- Fits must be re-estimated for your domains/datasets; laws validated on 140M–370M/1.3B scales in paper.
- QoS-aware adaptive inference
- Sectors: contact centers, legal/finance analysis tools, search and recommendation
- What: Dynamically select
Tper prompt based on time budget, uncertainty, or task complexity. - Tools/products/workflows:
- “Auto-T” controller using the exponential decay fit
L(T) = L∞ + Z·e^(−z·T)to chooseTuntil marginal gains fall below threshold. - Assumptions/dependencies:
- Confidence/uncertainty heuristics or a metamodel to trigger higher
T.
- Parameter-efficient model offerings
- Sectors: consumer apps, SMBs, on-prem deployments
- What: Offer 0.7–1.3B-class Parcae models to achieve quality comparable to larger Transformers, reducing memory footprint.
- Tools/products/workflows:
- Model cards reporting parameter count and “effective compute range” (
Tfrom 1 to tested maximum), with recommended defaults per task. - Assumptions/dependencies:
- Comparable training data and optimization to match paper’s gains; test-time compute must be acceptable.
- Edge robotics and planning with compute-time budgets
- Sectors: robotics, IoT
- What: Use low
Tfor time-critical steps; schedule higherTfor deliberative planning or between control cycles. - Tools/products/workflows:
- Planner adapter: schedule windows where
Tcan be raised without violating control-loop deadlines. - Assumptions/dependencies:
- Real-time system integration and careful latency accounting.
- Compliance- and privacy-friendly on-device assistants
- Sectors: healthcare, education, enterprise privacy
- What: Run smaller encrypted/on-device models; raise
Toffline for complex tasks while keeping data local. - Tools/products/workflows:
- Policy profiles: “privacy strict” (on-device, higher
Tallowed), “latency strict” (lowerT). - Assumptions/dependencies:
- Local compute capacity; task SLAs tolerate increased runtime for harder questions.
- Training and inference risk reduction
- Sectors: MLOps, safety/reliability
- What: Reduce catastrophic training failures (loss spikes) by enforcing stability constraints and depth sampling; predictable scaling reduces deployment surprises.
- Tools/products/workflows:
- Guardrails: hard checks on
ρ(·), input normalization, andμ_bwd ≈ ⌈μ_rec/2⌉in truncated backprop to maintain extrapolation. - Assumptions/dependencies:
- Proper instrumentation; willingness to adjust legacy recipes.
Long-Term Applications
These applications require further validation, scaling, or ecosystem development beyond the paper’s demonstrated scope.
- Standardized “compute-as-a-knob” pricing and SLAs
- Sectors: cloud AI platforms, APIs, marketplaces
- What: Expose
Tas a billable, verifiable control; customers pay for higherTin exchange for better expected quality. - Tools/products/workflows:
- Billing and metering tied to
Tor realized loop iterations; quality/latency tiers. - Assumptions/dependencies:
- Industry consensus and auditability of per-request compute; customer education.
- Hardware co-design for looped models
- Sectors: semiconductors, systems
- What: Accelerators optimized for weight reuse across loops (low memory, high arithmetic intensity), akin to SSM-style kernels.
- Tools/products/workflows:
- Kernel libraries for repeated block execution with minimal re-fetch overhead.
- Assumptions/dependencies:
- Broad adoption of looped architectures; vendor investment.
- Adaptive token-level compute with learned halting/routers
- Sectors: software, research
- What: Combine Parcae with token-level halting/routers (e.g., mixture-of-recursions) to allocate loops where needed.
- Tools/products/workflows:
- Learned gate that adjusts
Tper token span; integration with speedup techniques. - Assumptions/dependencies:
- Additional research to ensure stability and training convergence at scale.
- Large-scale foundation models with looped cores
- Sectors: model labs, cloud AI
- What: Validate power laws and stability at 7B–70B+ with RLHF/SFT stacks; produce highly memory-efficient foundation models.
- Tools/products/workflows:
- Training pipelines that co-scale data and
μ_recper isoFLOP fitting; instruction tuning withT-aware policies. - Assumptions/dependencies:
- Significant compute budgets; unknowns around instruction-following and alignment in looped settings.
- Safety-critical deployments with compute governance
- Sectors: healthcare, finance, legal
- What: Allocate additional loops for high-stakes queries to reduce error rates; log
Tas part of risk/audit trails. - Tools/products/workflows:
- Policy engine: raise
Tfor flagged categories; attachTmetadata to outputs for audits. - Assumptions/dependencies:
- Domain validation and regulatory acceptance; well-calibrated error–compute trade-offs.
- Energy- and carbon-aware compute scheduling
- Sectors: energy, cloud, sustainability programs
- What: Adjust
Tin response to grid carbon intensity and datacenter load (e.g., increaseTduring green hours). - Tools/products/workflows:
- Scheduler integrating carbon signals; set
Ttargets based on sustainability policies. - Assumptions/dependencies:
- Reliable real-time carbon metrics; customer tolerance for variable latency.
- Federated/on-device swarms with coordinated compute budgets
- Sectors: IoT, telecom
- What: Distributed agents running small Parcae models adjust
Tbased on local constraints and task importance; coordinated via edge orchestration. - Tools/products/workflows:
- Policy sharing and
Tallocation protocols across devices. - Assumptions/dependencies:
- Robust coordination frameworks; security and privacy assurances.
- Cross-modal looped architectures and control-theoretic design
- Sectors: robotics, speech, multimodal AI
- What: Extend Parcae’s dynamical-systems parameterization to vision, audio, or policy networks where weight sharing and stability are crucial.
- Tools/products/workflows:
- Libraries to parameterize
A,B,Cwith modality-specific blocks and discretization choices. - Assumptions/dependencies:
- Empirical validation per modality; potential need for full-rank or alternative discretizations.
- Quantization + looping for ultra-low-memory deployments
- Sectors: embedded systems, wearables
- What: Combine 4–8 bit quantization with smaller Parcae models; use higher
Tto recover quality. - Tools/products/workflows:
- Quantization-aware training tuned for Parcae blocks; runtime that preserves loop stability under low precision.
- Assumptions/dependencies:
- Numerical stability of discretized dynamics under quantization; careful calibration.
- API-level “Auto‑T” planners integrated with dev tools
- Sectors: software engineering, MLOps
- What: IDE/CI integrations that raise
Tfor complex tasks (e.g., tests, refactoring) and lower it for fast iterations. - Tools/products/workflows:
- Developer-facing SDK with
Tpolicies based on task type and time budget. - Assumptions/dependencies:
- Accurate complexity heuristics; developer acceptance.
- Policy and reporting standards for inference compute
- Sectors: governance, compliance
- What: Require disclosure of parameter count and average/maximum
Tto improve transparency of model resource use and quality claims. - Tools/products/workflows:
- Model cards with “compute curves” and unified scaling-fit parameters; audits of per-request
T. - Assumptions/dependencies:
- Policymaker and industry collaboration; standardized metrics and benchmarks.
Notes across applications:
- The test-time benefit saturates with
Tand is bounded by the training-depth floor; practical systems should capTusing the learned exponential-decay fit. - Reported gains are validated up to ~1.3B parameters; extrapolation to much larger models requires further evidence.
- Stability depends on enforcing the negative-diagonal parameterization (constrained spectrum), proper discretization (e.g., ZOH/Euler), prelude normalization of inputs, and per-sequence depth sampling.
- Latency and energy costs rise with
T; success hinges on matchingTto task SLAs and device constraints.
Glossary
- Backpropagation Through Time (BPTT): A training technique for recurrent models that computes gradients through unrolled time steps. "truncated backpropagation through depth, analogous to BPTT"
- Discretization: The process of converting a continuous-time system into a discrete-time approximation for implementation and analysis. "constrains the spectral norm of the injection parameters via discretization of a negative diagonal parameterization."
- Eigenvalues: Scalars that characterize a linear transformation; in control, their magnitudes determine system stability. "A fundamental property of LTI systems is that their stability is determined by the eigenvalues of ."
- Euler schemes: Numerical methods for discretizing differential equations using first-order approximations. "with ZOH and Euler schemes"
- Huber loss: A robust loss function less sensitive to outliers, combining L1 and L2 behaviors. "using the Huber loss"
- Injection parameters: Model parameters governing how input signals are injected into a recurrent update. "large spectral norms in their injection parameters."
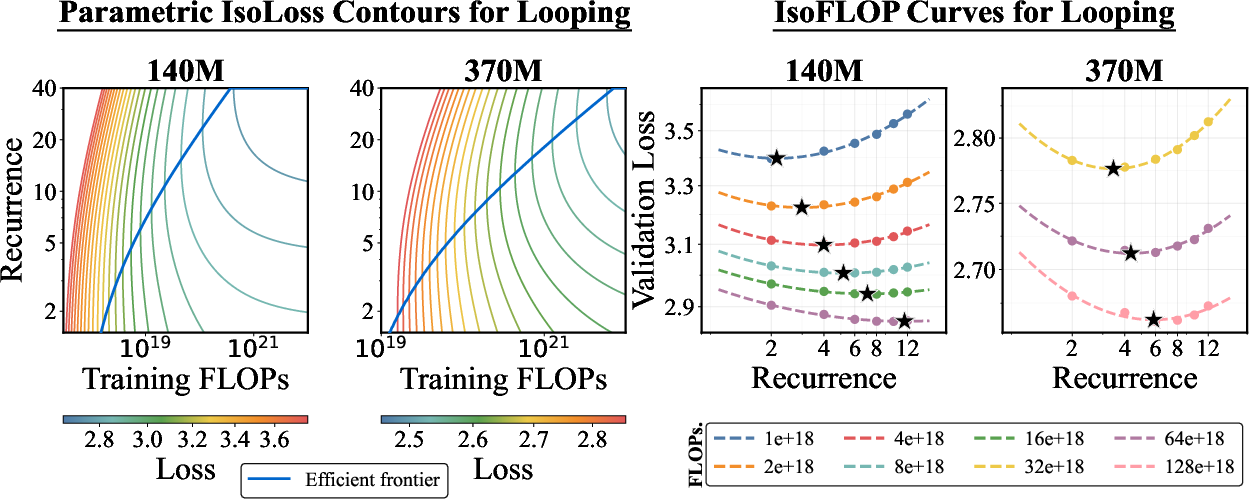
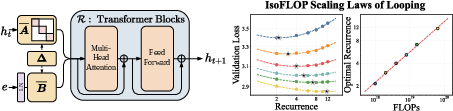
- isoFLOP: An experimental setting where different configurations are compared under an equal FLOP budget. "scaling laws for looping in a parameter-matched isoFLOP setting"
- L-BFGS: A limited-memory quasi-Newton optimization algorithm used for fitting parametric models. "using L-BFGS to minimize."
- Layer normalization: A normalization technique that stabilizes activations by normalizing per-feature across a layer. "where denotes layer normalization, multi-head attention, and feed-forward networks."
- Linear Time-Invariant (LTI) systems: Dynamical systems with linear dynamics that do not change over time. "In control theory, LTI systems are formalized through first-order differential equations"
- Looped architectures: Models that reuse a block of layers multiple times by looping activations through it. "A potential alternative is looped architectures, which instead increase FLOPs by sending activations through a block of layers in a loop."
- Marginally stable: A stability regime where a system neither converges nor diverges, often oscillating. "LTI systems fall into three regimes: stable (bounded and convergent), marginally stable (oscillatory), and unstable (explosive and divergent)."
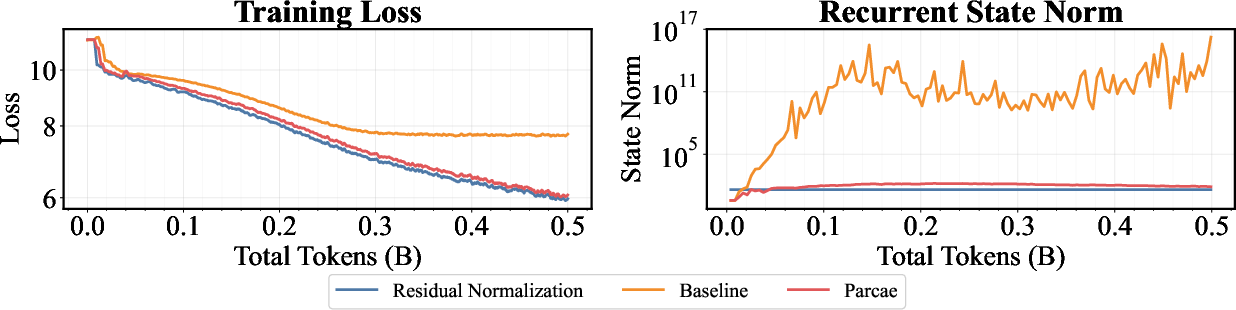
- Negative diagonal parameterization: Constraining a matrix to be diagonal with negative entries to ensure stable eigenvalues. "constrains the spectral norm of the injection parameters via discretization of a negative diagonal parameterization."
- Nonlinear time-variant dynamical system: A dynamical system whose evolution rules are nonlinear and can change over time. "recasting looping as a nonlinear time-variant dynamical system over the residual stream."
- Parabolic fit: Fitting a quadratic function to data to identify optima or trends. "Using a parabolic fit, we extract the optimal and token budget at each FLOP level"
- Pareto frontier: The set of configurations that achieve the best possible trade-offs (e.g., loss vs. compute). "Pareto Frontier of Looping."
- Parametric function: A model defined by adjustable parameters used to fit empirical relationships. "We also fit a parametric function"
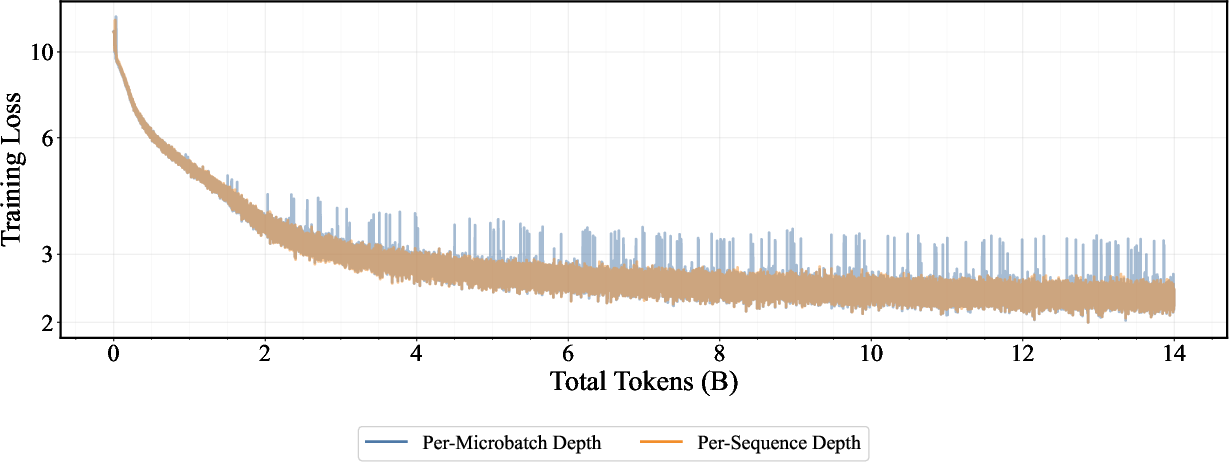
- Per-sequence depth sampling: Sampling different loop depths independently per sequence within a batch during training. "we introduce a per-sequence depth sampling algorithm within a micro-batch"
- Perplexity: A common metric for LLMs measuring how well a probability distribution predicts a sample. "up to 6.3\% lower validation perplexity"
- Post-Norm: A transformer design where normalization is applied after the residual addition in a block. "residual normalization (e.g., Post-Norm)"
- Pre-Norm: A transformer design where normalization is applied before the core block operations. "Pre-Norm looped models diverge"
- Residual normalization: Applying normalization within residual pathways to stabilize training dynamics. "residual normalization (e.g., Post-Norm) to correct this instability"
- Residual stream: The sequence of residual states updated across layers or loops in a model. "a nonlinear time-variant dynamical system over the residual stream."
- Saturating exponential decay: A performance curve that improves with more compute but approaches an asymptote exponentially. "following a predictable, saturating exponential decay."
- Scaling laws: Empirical relationships that characterize how performance scales with compute, data, or parameters. "Scaling laws have established that model performance improves predictably with increased FLOPs"
- Spectral norm: The largest singular value of a matrix, bounding how much it can amplify vectors; used to assess stability. "constrains the spectral norm of the injection parameters"
- Spectral radius: The largest magnitude among a matrix’s eigenvalues, determining stability of discrete systems. "divergent runs learn a spectral radius of "
- Stochastic depth: A technique that randomly skips layers (or loop steps) during training to improve generalization or enable adaptive compute. "implicit stochastic depth"
- Truncated backpropagation through depth: Limiting gradient propagation to a fixed number of looped steps to control memory and variance. "truncated backpropagation through depth, analogous to BPTT"
- Zero-order hold (ZOH): A method for discretizing continuous systems by assuming inputs are piecewise constant over each step. "zero-order hold (ZOH) would yield"
- Prelude norm: A normalization applied to the input embedding before it conditions the recurrent loop to improve stability. "and the prelude norm further improves quality across all "
Collections
Sign up for free to add this paper to one or more collections.