xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity
Abstract: Scaling laws play a central role in the success of LLMs, enabling the prediction of model performance relative to compute budgets prior to training. While Transformers have been the dominant architecture, recent alternatives such as xLSTM offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime. We conduct a comparative investigation on the scaling behavior of Transformers and xLSTM along the following lines, providing insights to guide future model design and deployment. First, we study the scaling behavior for xLSTM in compute-optimal and over-training regimes using both IsoFLOP and parametric fit approaches on a wide range of model sizes (80M-7B) and number of training tokens (2B-2T). Second, we examine the dependence of optimal model sizes on context length, a pivotal aspect that was largely ignored in previous work. Finally, we analyze inference-time scaling characteristics. Our findings reveal that in typical LLM training and inference scenarios, xLSTM scales favorably compared to Transformers. Importantly, xLSTM's advantage widens as training and inference contexts grow.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper compares two kinds of AI models for language:
- Transformers (the common kind used in most chatbots today), and
- xLSTM (a newer kind that works more like a memory that gets updated step by step).
The authors study “scaling laws,” which are rules that tell you how a model’s quality changes when you give it more computer power, more data, or make it bigger. Their main message: xLSTM can reach similar or better quality than Transformers while using computer time more efficiently, especially when the input text (the “context”) is long.
The big questions the paper asks
To make the comparison fair and useful, the authors focus on three easy-to-understand questions:
- Training: If we spend the same amount of computing power to train, which type gets better results?
- Context length: What happens when the input is long, like a very long document? Does one type handle long text more efficiently?
- Inference (using the model): Which type is faster when you ask it a question, both for the first word it answers and for each word after that?
How they studied it (in everyday language)
Think of training a model like practicing for a sport:
- “Parameters” are the model’s internal settings (like a huge set of knobs you can tune).
- “Tokens” are chunks of text (like words or parts of words) it practices on.
- “Compute budget” (FLOPs) is the total amount of “workout effort” the computer spends.
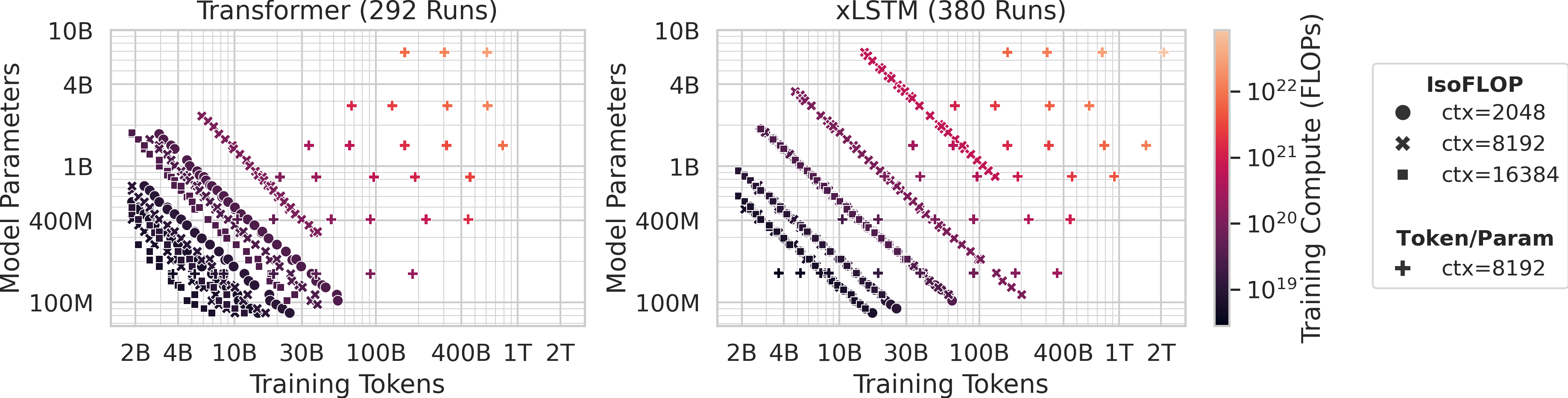
The team ran lots of training experiments:
- Model sizes ranged from small to medium-large (about 80 million to 7 billion parameters).
- Data sizes ranged from 2 billion to 2 trillion tokens.
- They used two ways to organize experiments:
- Token/Param: Pick a model size and vary how much data it sees.
- IsoFLOP: Keep total training effort the same, but trade off between making the model bigger vs. giving it more data.
They then fit simple mathematical curves (power laws) to predict how loss (a measure of mistakes; lower is better) depends on model size and data. They also measured real-world speed during use (inference):
- Time to First Token (TTFT): how long until the first answer word appears.
- Step time: how long for each next word.
Key idea about the two model types:
- Transformer “attention” compares many parts of the input with each other. If the input is longer, the cost grows roughly like “length squared” (quadratic). Imagine every student in a class comparing notes with every other student—this gets slow as the class grows.
- xLSTM updates a running memory as it reads. The cost grows roughly in a straight line with input length (linear). Imagine just taking notes as you read, one line at a time.
What they found (and why it matters)
Here are the main results, with a short reason why each is important:
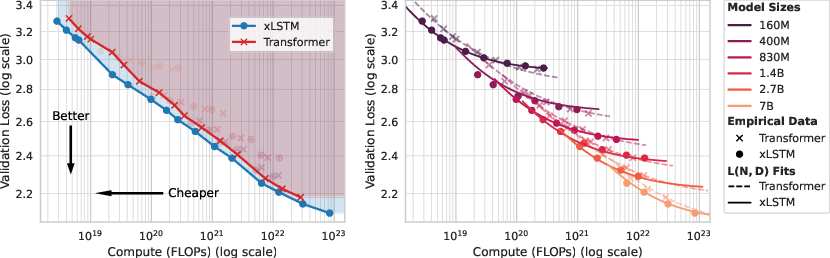
- xLSTM is Pareto-dominant in training cost vs. quality.
- Meaning: For the same training compute, xLSTM gets a better loss (makes fewer mistakes); for the same loss, it needs less compute.
- Why it matters: You can get more bang for your buck.
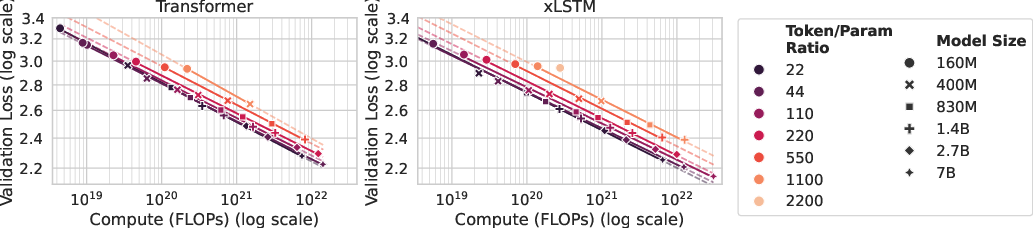
- In “over-training” (smaller models trained on lots of data), xLSTM keeps improving steadily.
- They show xLSTM follows the same kind of reliable power-law improvements seen in Transformers when you feed it more data.
- Why it matters: You can train small, fast xLSTMs on big datasets and still keep getting better results.
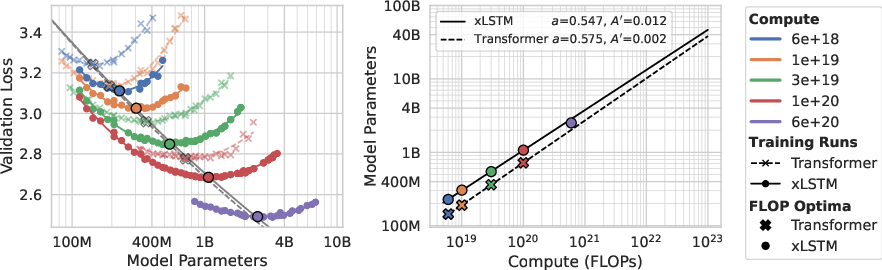
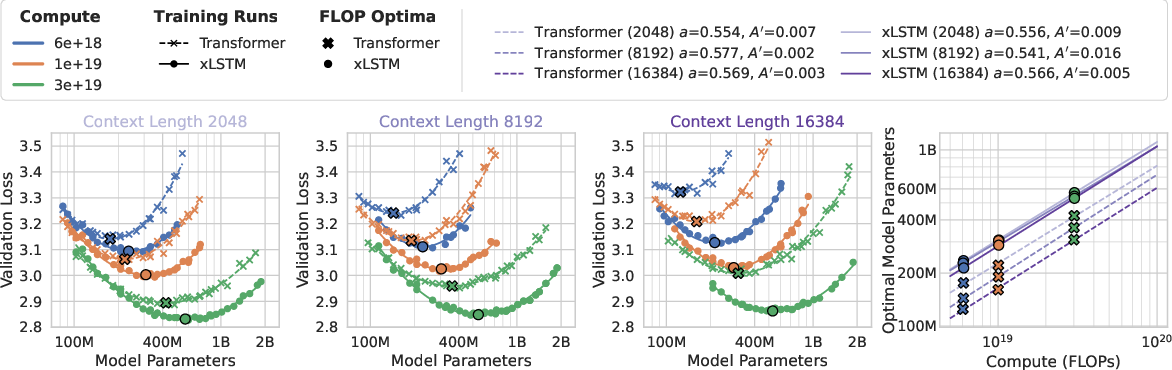
- Compute-optimal xLSTMs are larger than compute-optimal Transformers.
- Under the best way to spend a fixed training budget, the best xLSTM tends to have more parameters than the best Transformer.
- Why it matters: If you’re planning a training run, xLSTM lets you allocate your compute toward model size differently and still come out ahead on quality.
- As context length grows, xLSTM’s advantage grows.
- For long inputs, Transformers spend a lot more time on attention. xLSTM handles long inputs more efficiently.
- Why it matters: Long documents, long instructions, or long reasoning chains become practical and faster with xLSTM.
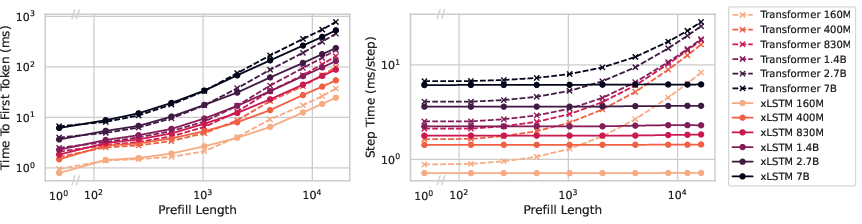
- Inference is faster with xLSTM, especially for long inputs.
- TTFT: For long contexts (like 16,000 tokens), xLSTM cuts the time to first token by about 30–50% compared to same-sized Transformers.
- Step time: xLSTM’s per-token speed stays steady as inputs get longer; Transformer gets slower.
- Why it matters: Lower latency and higher throughput mean faster, cheaper deployments—useful for chatbots, on-device AI, or any app where speed matters.
- A simple runtime model (based on how much math and memory the model needs) accurately explains the measured speeds.
- Why it matters: The speed gains aren’t just lucky—they’re expected from the underlying math of the two architectures.
Why this is important overall
- Better cost-performance: xLSTM can get better results for the same training cost and run faster during use.
- Long-context strength: As tasks need longer memory (long documents, multi-step reasoning), xLSTM’s benefits grow.
- Practical deployment: Faster response and lower compute can reduce costs and make AI more accessible on devices with limited memory or power.
Key terms explained simply
- Parameters: The model’s internal “settings” that it learns, like millions or billions of tiny dials.
- Tokens: Pieces of text (like words or word parts).
- Loss: A number that measures how often the model is wrong; lower is better.
- FLOPs: A way to count how much “math work” the computer does; more FLOPs means more compute effort.
- Context length: How much text the model reads at once (like how many tokens it can remember).
- Time to First Token (TTFT): How long until the model produces its first word of output.
- Step time: How long it takes to produce each additional word.
Takeaway
If you care about training efficiently and running models fast—especially on long inputs—xLSTM looks like a very promising alternative to Transformers. It keeps improving with more data, is more compute-efficient, and scales better as inputs get longer. This could help future LLMs become cheaper, faster, and more useful in real-world applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point indicates a concrete direction for future research.
External validity and evaluation scope
- Lack of downstream task evaluation: No assessment beyond cross-entropy (e.g., reasoning, coding, math, multilingual, safety, calibration), leaving it unclear whether xLSTM’s training/inference advantages translate into end-task gains.
- No long-context benchmark results: Claims about advantages at long context are not validated on established suites (e.g., LONG-Bench, RULER, L-Eval, SCROLLS), nor on retrieval-heavy or tool-use tasks.
- Single data distribution: Results are based on DCLM-Baseline; robustness across diverse corpora (code, math, multilingual, speech-text, domain-specific datasets) is unknown.
- Tokenizer sensitivity: Only GPT-NeoX tokenizer is used; the effect of vocabulary size and tokenization choices on scaling (and relative architecture advantages) is unmeasured.
Fairness and breadth of architectural baselines
- Transformer baseline choice: The comparison uses dense multi-head attention Llama-2 style models; it omits stronger or more efficient Transformer variants (e.g., MQA/GQA, FlashAttention-2/3, fused/fp8 kernels, paged KV cache, ring/sequence parallel attention), which could alter the Pareto frontier.
- Missing comparisons to other linear-time or hybrid models: No head-to-head scaling comparisons with Mamba/SSMs, linear attention variants, Hyena/FastConv/FlashFFTConv, or hybrid models combining attention with xLSTM—limiting conclusions about xLSTM’s relative position among linear-time architectures.
- No evaluation of Mixture-of-Experts (MoE) baselines: Given MoE’s inference-efficiency benefits, it remains unclear whether xLSTM’s wins persist when compared against compute- and inference-optimized routed models.
Scaling ranges and extrapolation risk
- Limited scale: Experiments span 80M–7B parameters and 2B–2T tokens; the validity of fitted laws for ≥70B models and multi-trillion-token training remains untested.
- Extreme token/parameter ratios: Over-training analysis covers a specific set of values; behavior at very high (e.g., ≥5k–10k), or very low compute regimes, is not established.
- Ultra-long contexts: Context-dependent results are limited to 2k–16k; claims may not hold at 32k–1M token contexts where memory/precision and kernel limits emerge.
Context-length analysis confounds
- Non-comparable losses across context lengths: Authors note dataset distribution differences by context; compute-optimal conclusions across context lengths may be confounded. A controlled setup with identical documents/packing across is needed.
- Positional/temporal encoding effects: The interaction of positional methods (e.g., RoPE variants for Transformers, temporal embedding for xLSTM) with context scaling is not disentangled; potential gains/losses attributable to encoding are unknown.
Compute accounting and runtime modeling assumptions
- Roofline model simplifications: The runtime model assumes dominant FLOPs or memory phases with a constant overhead; sensitivity to kernel fusion, scheduling, and overlapping compute/memory (and their hardware-specific variability) is not analyzed.
- FLOP/MemOps estimates vs. real kernels: The theoretical accounting may diverge from highly optimized vendor kernels; calibration of coefficients across GPUs/TPUs/consumer cards is limited, and generalization across hardware is unverified.
- Absence of cost/energy modeling: No $ cost or energy/carbon accounting is reported, leaving economic/ecological implications of the scaling claims unquantified.
Inference benchmarking limitations
- Narrow inference setup: Primary figures use batch size 1 and single-GPU; large-batch prefill, heterogeneous/streaming batches, beam search, and cache-management strategies are not studied.
- No multi-GPU/cluster inference: Pipeline/tensor parallelism, cross-node latency, and KV/state sharding effects on TTFT and throughput are unexplored.
- Memory footprint under varied serving patterns: The comparative memory costs of Transformer KV caches vs. xLSTM state (prefill/generation, batch, long T) are not quantified; practical serving capacity limits and context-length ceilings remain unclear.
Training efficiency and systems considerations
- Wall-clock and utilization: Results are expressed in FLOPs and loss, not in actual training throughput, GPU utilization, or end-to-end wall-clock time—critical for practitioner decisions.
- Parallelism regimes: Impacts of data/tensor/sequence/pipeline parallelism on xLSTM vs. Transformer training efficiency (e.g., overlap, communication volume, activation checkpointing) are not investigated.
- Stability and precision: Numerical stability of xLSTM at scale and long contexts (gradient behavior, norm control) and sensitivity to mixed precision (fp8/bf16) are not reported.
Hyperparameter, recipe, and optimization sensitivity
- Recipe robustness: Sensitivity to optimizer choice, LR schedules, weight decay, normalization/regularization, dropout/label smoothing, gradient clipping, and activation functions is not systematically evaluated for both architectures.
- Architectural ablations: Depth/width trade-offs, head/dimension scaling (for Transformers), and cell/MLP ratios (for xLSTM) are not ablated—limiting prescriptive scaling rules.
- Data curriculum and packing: Effects of curriculum learning, length/batch packing policies, and deduplication/stringent filtering on scaling exponents and over-training behavior are untested.
Theoretical questions
- Universality claim: The observed “universal” relation between compute-optimal performance and model size across architectures is empirical; a theoretical explanation and boundaries of validity are missing.
- Inference-aware optimality for xLSTM: An explicit derivation of xLSTM-specific inference-aware scaling laws (analogous to Beyond Chinchilla for Transformers) is not provided; the optimal , , under serving demand distributions remains an open problem.
Transfer, fine-tuning, and alignment
- Post-pretraining adaptation: Effects of instruction tuning, RLHF/DPO, domain adaptation, and continual learning on the relative advantages of xLSTM vs. Transformer are unknown.
- Robustness and safety: No analysis of robustness to distribution shift, adversarial prompts, calibration, or safety behaviors; interactions with scaling are not addressed.
Reproducibility and implementation details
- Kernel maturity and portability: xLSTM’s performance depends on specialized kernels (e.g., TFLA); portability and performance consistency across frameworks/hardware stacks are not assured.
- Seed variance and uncertainty: Statistical variability (across random seeds) and confidence intervals for fitted exponents/coefficients are not reported, limiting confidence in extrapolations.
These gaps identify concrete next steps: broaden architectural and task baselines; control for context-length confounds; extend to larger scales and longer contexts; measure wall-clock, energy, and memory; develop inference-aware theory for xLSTM; and validate on production-like multi-GPU serving and diverse downstream tasks.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now using the paper’s findings, with sector tags and notes on feasibility. They leverage the demonstrated advantages of xLSTM—linear-time complexity with context length, lower time-to-first-token (TTFT), lower per-token step time, and predictable scaling laws—at model sizes up to 7B parameters and context windows up to 16k tokens.
- Cost-efficient LLM serving with long prompts (software, enterprise, cloud)
- What: Replace or augment Transformer-based services (chat, copilots, summarization) with xLSTM models to cut TTFT and step time—especially for long prompts (8k–16k) and long histories/session contexts.
- Benefits: Lower latency, higher throughput per GPU, reduced serving costs, improved user experience for long-context interactions.
- Tools/products: xLSTM inference servers; throughput-optimized serving stacks; HF Transformers-compatible xLSTM models; inference scaling dashboards using the paper’s roofline-informed runtime model.
- Assumptions/dependencies: Quality parity on target tasks must be validated; performance gains depend on kernel maturity and hardware; batch-size effects beyond the paper’s single-GPU setup require benchmarking.
- Long-context RAG with less chunking and vector-store overhead (software, legal, finance, research)
- What: Use xLSTM’s linear scaling to accept larger retrieved contexts per query, reducing aggressive chunking and re-ranking cycles in RAG pipelines.
- Benefits: Better recall/precision trade-offs, fewer retrieval calls, simpler prompt engineering, lower end-to-end latency.
- Tools/products: RAG connectors tuned for xLSTM; prompt-assembly layers that target 8k–16k contexts; observability that measures retrieval vs. reasoning time.
- Assumptions/dependencies: Data governance and document access; long-context quality must be validated on domain-specific corpora.
- Repo-scale coding assistants for medium/large codebases (software engineering, DevOps)
- What: Use xLSTM to process long files and repository-wide context (history, multi-file references) with lower TTFT and steady generation step times.
- Benefits: Improved cross-file reasoning, faster code exploration, fewer context truncation errors.
- Tools/products: IDE extensions with xLSTM backends; repo-indexers that pass larger context windows; CI assistants that review long diffs.
- Assumptions/dependencies: Code-domain instruction tuning; license-compliant training data; integration with developer tools.
- Contact center and sales ops with full-call histories (customer support, CRM)
- What: Feed long transcripts and prior interactions (multi-session) into xLSTM for summarization, QA, and suggestion generation without quadratic slowdowns.
- Benefits: Lower TTFT for “first reply,” faster iterative suggestions, better personalization across long histories.
- Tools/products: CRM plugins using xLSTM; agent-assist dashboards that keep days/weeks of context in prompt.
- Assumptions/dependencies: Data privacy controls; domain fine-tuning for dialog; stable latency under production batching.
- E-discovery and regulatory document review (legal, compliance, finance)
- What: Process long filings/contracts or multi-document dossiers in a single pass to extract risks, obligations, and inconsistencies.
- Benefits: Fewer passes, reduced chunk stitching, improved consistency; time/cost savings at scale.
- Tools/products: Long-context contract analyzers; risk-summary pipelines; obligation extractors.
- Assumptions/dependencies: Legal-domain validation; auditability and traceability; governance over sensitive data.
- EHR summarization and longitudinal patient narratives (healthcare)
- What: Summarize multi-visit records and write longitudinal clinical notes with long-context xLSTM to maintain continuity and reduce truncation.
- Benefits: Better continuity-of-care summaries; lower latency in on-prem settings.
- Tools/products: On-prem clinical summarization services; physician-facing assistants with long patient timelines.
- Assumptions/dependencies: HIPAA/GDPR compliance; clinical fine-tuning; institutional IT integration and validation.
- On-device or near-edge assistants with long-session memory (mobile, embedded, IoT)
- What: Run 1–7B xLSTM models on edge GPUs/NPUs where memory and latency are constrained, enabling longer “short-term memory” with lower TTFT.
- Benefits: Privacy, offline capability, reduced cloud dependency.
- Tools/products: Mobile/edge runtimes with quantized xLSTM; session memory managers optimized for recurrent state.
- Assumptions/dependencies: Efficient kernels on target hardware; quantization/distillation pipelines; battery/thermal constraints.
- Time-series and log analysis over long windows (security, AIOps, energy)
- What: Apply xLSTM to long-horizon logs/metrics for anomaly detection, incident summaries, and trend explanations.
- Benefits: Model longer windows without quadratic cost; faster incident triage.
- Tools/products: SIEM/SOAR integrations; observability copilot that ingests long traces; grid/SCADA log analysis.
- Assumptions/dependencies: Domain-specific evaluation; secure data handling; integration with existing telemetry stacks.
- Training-budget planners that include inference costs (MLOps, academia)
- What: Use the paper’s IsoFLOP and parametric loss fits to compute-optimize xLSTM training with inference cost constraints; over-train smaller models to cut serving costs.
- Benefits: Better ROI on pretraining; predictable loss vs. compute; more accurate context-length-aware planning vs. 6ND proxy.
- Tools/products: “xLSTM Scaling Planner” calculators; AutoML sweeps over token-per-parameter ratios with inference-aware objectives.
- Assumptions/dependencies: Target data/domain match; reliable loss-transfer from validation to downstream tasks; access to large token corpora.
- Sustainability reporting and procurement guidance (policy, enterprise IT)
- What: Prefer linear-time LLMs in procurement and architecture reviews for long-context workloads to lower energy consumption and carbon intensity.
- Benefits: Reduced energy/KWh per request; aligns with sustainability KPIs.
- Tools/products: Internal guidelines for model selection; cost/CO2 calculators using the paper’s FLOPs/memops runtime model.
- Assumptions/dependencies: Comparable task performance; standardized energy metering in inference pipelines.
- Methodological baselines for academic scaling-law studies (academia)
- What: Adopt xLSTM as a linear-complexity baseline in scaling-law experiments; replicate IsoFLOP sweeps and parametric fits including context-length dependence.
- Benefits: More complete scaling maps; avoids misestimation from 6ND-only proxies.
- Tools/products: Open-source code/data from the paper; reproducible notebooks for loss-surface fitting and runtime roofline modeling.
- Assumptions/dependencies: Reproduction fidelity; compute access; dataset comparability.
Long-Term Applications
These opportunities require further research, scaling, kernel maturity, or validation on broader downstream tasks, but are natural extensions of the paper’s results—especially as contexts and model sizes grow.
- Million-token context assistants and retrieval-light workflows (software, research, education)
- What: Build assistants that read entire books/courses, large codebases, or multi-quarter project histories in one pass, leveraging linear-time growth.
- Potential products: “Whole-repo copilots,” “full-course tutors,” long-context literature-review engines.
- Assumptions/dependencies: Efficient memory/state management; kernel/hardware improvements; strong long-context grounding/recall behavior beyond 16k; training data and pretraining budgets at scale.
- Long-horizon reasoning with test-time compute scaling (software, research, robotics)
- What: Combine xLSTM’s faster per-step generation with reasoning tokens (chain-of-thought, tree search, sampling) to get more “thinking” per time budget.
- Potential products: Planning agents, complex multi-step tool-use systems, robotics task planners with extended horizons.
- Assumptions/dependencies: Reasoning supervision, safety controls, and evaluation; alignment techniques for deep deliberation.
- Privacy-first, on-device professional assistants (healthcare, legal, finance, government)
- What: Run specialized xLSTM models locally (hospital, law firm, bank, agency) for long-context analysis of sensitive data without cloud exposure.
- Potential products: On-prem copilots for EHRs, legal matter management, regulatory filings.
- Assumptions/dependencies: Hardware accelerators at the edge; robust domain instruction tuning; certification and compliance audits.
- Hybrid and MoE architectures with linear-time cores (software, research)
- What: Mix xLSTM cores with sparse attention or experts to capture rare patterns while keeping inference linear w.r.t. context length.
- Potential products: Frontier models that preserve long-context speed while improving accuracy on global dependencies.
- Assumptions/dependencies: Routing/training stability; inference system design; compiler/kernel support.
- Policy frameworks for energy-aware AI deployments (policy, cloud, sustainability)
- What: Introduce standards that factor asymptotic complexity (linear vs. quadratic) into public procurement and energy labeling for LLM services.
- Potential products: “Green AI” certifications; incentives for linear-time long-context deployments.
- Assumptions/dependencies: Accepted measurement protocols (per-request energy/carbon); neutrality across vendors.
- Scientific and biomedical sequence modeling over very long inputs (science, biotech)
- What: Use linear-complexity sequence models for genomics, proteomics, and climate/hydrology time series where context length is a bottleneck.
- Potential products: Genome-scale annotators, long-time climate analyzers, wearable-stream models.
- Assumptions/dependencies: Domain datasets and labels; multimodal extensions; rigorous validation.
- Enterprise-wide consolidation of LLM serving fleets (enterprise IT, cloud)
- What: Migrate long-context workloads to linear-time architectures to reduce GPU count and improve capacity planning.
- Potential products: Fleet optimizers that simulate TTFT/throughput using roofline models; dynamic routing to xLSTM for long-context requests.
- Assumptions/dependencies: Mixed-traffic routing strategies; SLO management; gradual migration playbooks.
- Education at scale with offline/low-bandwidth support (education, public sector)
- What: Deploy long-context teaching assistants on school devices that can maintain multi-lesson memory without cloud dependence.
- Potential products: Local classroom copilots; curricula ingestion tools; longitudinal student portfolio analysis.
- Assumptions/dependencies: Device procurement; content licensing; fairness and safety evaluation.
- Security and operations “memory” over months of telemetry (security, AIOps)
- What: Maintain rolling, very long windows of logs/alerts for contextual threat hunting and root-cause analysis without prohibitive latency.
- Potential products: “Memory copilot” for SOC/NOC; timeline reconstruction tools.
- Assumptions/dependencies: Secure data lakes; continuous fine-tuning; evaluation on adversarial settings.
- Training orchestration co-designed with inference economics (MLOps, finance)
- What: Portfolio-style optimization of training runs (overtraining small models vs. compute-optimal larger models) under serving cost and SLA constraints.
- Potential products: Budget planners that couple scaling-law fits with demand forecasts and price-performance curves.
- Assumptions/dependencies: Accurate demand modeling; dynamic pricing of compute; evolving model families and kernels.
Notes on Cross-Cutting Assumptions and Dependencies
- Task transferability: The paper evaluates cross-entropy loss on DCLM-Baseline and does not audit a wide range of downstream tasks; validate quality per domain.
- Inference benchmarking: Results are from controlled, single-GPU experiments; multi-GPU, batching, and production kernels may shift realized gains.
- Kernel maturity and hardware support: Performance depends on optimized recurrent kernels (e.g., xLSTM/mLSTM implementations) and vendor compiler support.
- Data quality and licensing: Overtraining strategies rely on large, high-quality, legally usable corpora.
- Model ecosystem: Fine-tuning recipes, safety/alignment, quantization, and tool-use integrations need to be robust for enterprise/regulated deployments.
- Context distribution shift: Losses are not directly comparable across different context lengths; real workloads may differ from pretraining distributions.
In summary, the paper’s evidence that xLSTM is Pareto-dominant in loss vs. compute and scales linearly in inference with context length enables immediate wins in long-context, latency-sensitive deployments, and sets the stage for long-term advances in million-token contexts, on-device privacy-preserving assistants, and energy-aware AI policy and infrastructure.
Glossary
- attention mechanism: Component in Transformers that computes pairwise token interactions, often the computational bottleneck. "the attention mechanism inflicts computational costs during training and inference that are quadratic in terms of context length."
- Chinchilla-optimal: Informal reference to the compute-optimal scaling prescription from Chinchilla work; used as a baseline for data/parameter ratios. "much higher than ``Chinchilla-optimal'', which incurs higher inference speeds due to smaller models."
- compute-optimal training: Strategy choosing model and data sizes that minimize loss for a fixed training compute budget. "establish the notion of compute-optimal training, which refers to the optimal choice of and for a given compute budget "
- context length: Number of tokens processed as input at once (sequence length). "offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime."
- cross-entropy loss: Standard language modeling objective measuring prediction quality per token. "xLSTM models are Pareto-dominant in terms of cross-entropy loss over Transformer models"
- IsoFLOP approach: Scaling-law fitting method that compares models along curves of equal training compute. "For the IsoFLOP approach a set of compute budgets is defined and for each budget the values of and are varied such that the constraint is fulfilled."
- KV cache: Stored key/value representations from attention used to speed up autoregressive decoding. "i.e.~the KV cache for Transformer models or the mLSTM cell states for xLSTM."
- linear time-complexity: Computation that scales linearly with sequence length, advantageous for long contexts. "self-attention with quadratic time-complexity in Transformer versus recurrent mLSTM dynamics with linear time-complexity in xLSTM."
- logits: Pre-softmax scores output by the model used to sample or select the next token. "compute the logits for the first token to be generated"
- MemOps: Count of memory read/write operations (bytes moved), used to model runtime alongside FLOPs. "MemOps (App.~\ref{app:acc_memops})"
- Mixture-of-Experts: Architecture that routes inputs to a subset of specialized sub-networks to increase parameter count without proportional compute. "such as the widely considered Mixture-of-Experts method \citep{shazeer:17outrageously}."
- mLSTM: A multiplicative LSTM cell variant used as the recurrent building block in xLSTM. "it alternates mLSTM layers with position-wise feedforward MLP layers."
- over-training regime: Training with more tokens per parameter than compute-optimal, often to reduce inference costs for smaller models. "so-called over-training regime, i.e.~on more tokens than would be optimal in terms of pre-taining compute."
- parametric fit approach: Method fitting a functional form (typically power laws) to loss as a function of parameters and data. "the parametric fit approach and the IsoFLOP approach"
- Pareto-dominant: Strictly better on at least one metric without being worse on others compared to alternatives. "xLSTM models are Pareto-dominant in terms of cross-entropy loss over Transformer models"
- Pareto frontier: Set of solutions that are non-dominated across trade-off metrics (e.g., loss vs. compute). "we visualize the Pareto frontier by connecting the data points for xLSTM and Transformer."
- power law: Relationship where a quantity varies as a power of another (e.g., loss vs. compute). "these scaling laws take the form of power laws"
- prefill: Inference stage that processes the prompt to produce the first token and caches states. "In the prefill stage the LLMs process the prompt, compute the logits for the first token to be generated, and store the intermediate internal representations of the prompt"
- quadratic time-complexity: Computation scaling with the square of sequence length, typical of full self-attention. "and their performance advantage grows with context length due to Transformersâ quadratic time complexity."
- roofline model: Performance model relating FLOPs, memory bandwidth, and operational intensity to predict runtime bounds. "based on the roofline model."
- scaling laws: Empirical rules describing how performance changes with model size, data, or compute. "Scaling laws play a central role in the success of LLMs"
- self-attention: Mechanism where tokens attend to each other to mix sequence information in Transformers. "dense multi-head self-attention Transformer architectures"
- step time: Time per generated token during the autoregressive decoding stage. "the key performance metric is the step time, i.e. how long it takes to obtain the next token given the current (potentially batched) sequence."
- time to first token (TTFT): Latency from submitting a prompt to receiving the first generated token. "the key performance metric is the time to first token (TTFT)."
- token-to-parameter ratio: Number of training tokens per model parameter, used to characterize training regimes. "token-to-parameter ratios of "
Collections
Sign up for free to add this paper to one or more collections.