- The paper introduces a fixed-point analytic framework that uses axes of reachability, input-dependence, and geometry to assess looped transformer stability.
- The paper demonstrates that autonomous architectures lack input-sensitive fixed points, leading to failures in extrapolation and algorithmic reasoning.
- The paper empirically validates that outer-normalized recall models outperform fixed-depth models by ensuring stable convergence and scalable test-time computation.
Overview
"Stability and Generalization in Looped Transformers" (2604.15259) rigorously investigates the theoretical and empirical properties that govern the ability of looped (recurrent, weight-tied) transformer architectures to extrapolate beyond their training regime through variable compute at test time. The paper introduces a fixed-point-based analytic framework centered on three axes of model stability—reachability, input-dependence, and geometry—and demonstrates how architectural design choices, principally the presence and type of recall and outer normalization, manifest in a looped transformer's capacity for algorithmic generalization versus mere memorization. Both conceptual insights and strong empirical evidence are provided across complex reasoning tasks, with a particular focus on addressing overthinking and performance plateau when leveraging iterative inference.
Motivation and Theoretical Framework
Looped transformers have emerged as a promising alternative to chain-of-thought (CoT) and fixed-depth models for algorithmic reasoning tasks, with the unique hope that a single model's inference depth can be scaled adaptively—spending more iterations on harder examples—without modifying its weights. However, prior empirical evidence and practical deployment reveal critical obstacles: without careful architectural design, iterative inference can result in catastrophic instability or models that overfit to fixed iteration depths, thus losing all extrapolative power.
The authors formalize analysis around fixed points of the looped computation, arguing that trustworthy generalization requires the existence of fixed points that are:
- Reachable: Iteration dynamics must actually converge to fixed points (i.e., stability under iteration).
- Input-dependent: Fixed points must vary nontrivially with input, enabling meaningful, input-sensitive mappings rather than spurious constant solutions or trivial basin selection.
- Geometrically robust: Stability regions in parameter space must be well-behaved (ball-like rather than thin or anisotropic), ensuring that optimization can reliably reach and maintain these regions.
The authors differentiate between autonomous networks (state transition depends solely on the previous hidden state) and recall networks (each iteration also conditions on the original input). The importance of recall and its placement (external vs. internal) is theoretically grounded, as is the criticality of outer normalization for affording broader, well-behaved stability regimes.
Failures of Autonomous Looped Networks
The paper's analytical core exposes fundamental limitations in autonomous looped architectures:
- Under weak but generic transversality assumptions, the set of fixed points for an autonomous network is almost always a dimension-zero (i.e., countable) manifold.
- Input-dependence is severely restricted: in the absence of recall, the network's predictions correspond to selection among a finite set of fixed points—at best, classifying inputs into a fixed partition rather than supporting robust, algorithmic computation.
- An eigenanalysis of forward and backward dynamics at fixed points reveals no viable regime that simultaneously provides stable convergence and non-vanishing gradients for input influence. Strong contraction (all eigenvalues less than one) leads to vanishing dependence on input, while weaker contraction or expansion destabilizes learning and iteration.
(Figure 1)
Figure 1: We consider the best (hard accuracy) autonomous norm + LR configuration across each task, and plot its performance as a function of iteration count. The gray zone on each plot represents the maximum loops used in training. Our alpha = 1 progressive loss training largely prevents overthinking, with accuracy mostly conserved beyond the training iteration depth.
Empirically, these theoretical conclusions are validated: autonomous architectures maintain moderate in-distribution accuracy in some cases, but always fail on OOD distributions requiring increased iteration or input-sensitive reasoning. Particularly, they utterly fail at extrapolation when the input dimension changes between train and test—highlighted on the prefix-sums task.
Recall Architectures: Placement, Geometry, and Normalization
To overcome the autonomous case's deficiencies, architectural injection of recall is studied in depth. Two variants are defined:
- External recall: The recalled input state enters directly into the residual path.
- Internal recall (novel): Recall modulates only the feedforward update, not the hidden state directly.
Both architectures theoretically enable input-dependent fixed points, but in the absence of outer normalization, a detailed spectral analysis shows:
- External recall features a broader, more isotropic regime of fixed-point stability; thus, training is substantially less sensitive to parameter initialization and learning rate.
- Internal recall yields a highly anisotropic, narrow stability manifold: convergent fixed points are restricted to a tiny, "sliver-like" region (Figure 2). This renders the architecture fragile with respect to optimization and noise, especially for moderate or high learning rates.
These conclusions are supported quantitatively through a projection-based experiment.
(Figure 2)
Figure 2: Effect of LR on non-outer-normalized internal and external recall Jacobian spectral radius. Top is external recall, bottom is internal recall. Chess and prefix sums use (0.0001, 0.0003, 0.001); sudoku uses (0.0003, 0.001, 0.003).
Learning rate directly modulates the dominant eigenvalue (spectral radius) of the recall Jacobian, driving configurations into or out of the stable regime. Task-dependent behaviors emerge when these regimes are exited.
Crucially, outer normalization (post-norm or GRU-norm) fundamentally changes the landscape. Through a fixed-point and implicit function theorem analysis, the authors show:
- Outer normalization scales down the spectral radii of the fixed-point Jacobians, guaranteeing the existence and broad reachability of input-dependent fixed points. It directly ensures convergence and non-vanishing input gradients, which are mathematically derived as limiting formulas.
- Furthermore, normalization maps the iterates into compact, convex sets, aligning trajectories for improved optimization and facilitating path- and initialization-independence, a property empirically linked to improved algorithmic generalization.
Empirical Evaluations on Algorithmic Reasoning Benchmarks
The proposed theoretical analysis is validated with extensive experiments across three tasks requiring algorithmic reasoning: chess, sudoku, and prefix sums. Each is chosen for its challenging out-of-distribution generalization aspect (e.g., increased instance difficulty or sequence length).
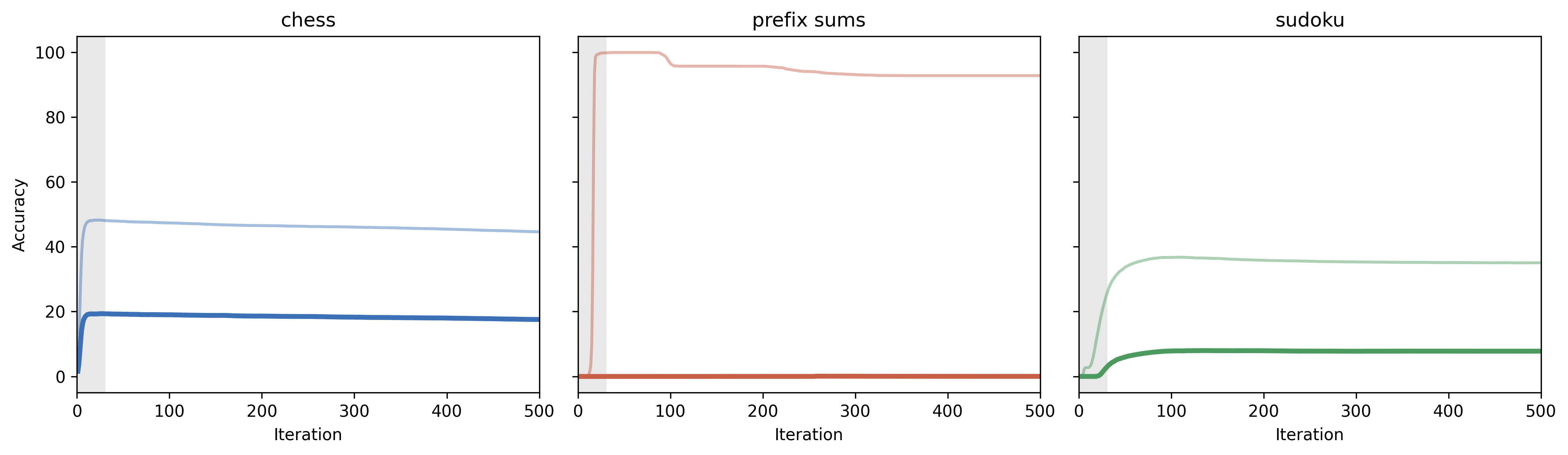
Figure 3: Validation and hard accuracy across problems.
Key empirical findings include:
- Outer-normalized recall models outperform other variants (autonomous, non-normalized recall, or fixed-depth) on virtually all tasks, and are the only models to maintain accuracy as problem difficulty or test-time iteration increases.
- Models absent outer normalization—regardless of recall placement—either degrade on OOD data or fail to find reachable, stable fixed points when learning rate is not extremely low.
- Interestingly, while internal recall is generally weaker without outer normalization, it can outperform external recall (notably on sudoku) once normalization is present—potentially due to differences in fixed-point encoding structure.
- Fixed-depth large models, despite large parameter capacity, do not match looped+normalized designs on the reasoning tasks tested, validating the looped paradigm for scalable test-time computation.
Implications and Future Directions
This work delivers both theoretical and empirical clarity to several open design questions in the literature on scalable, generalizing reasoning in neural architectures:
- Strong negative results for autonomous looped architectures suggest that any extrapolative or compositional reasoning work must, at a minimum, involve direct iterated conditioning on the input.
- Recall alone is insufficient for robust generalization unless combined with outer normalization, as geometric fragility and spectral pitfalls in the recurrence can dominate even with input injection.
- The axes of stability framework—reachability, input-dependence, and geometry—offers a principled lens to analyze, predict, and control the dynamics and generalization properties of recurrently applied neural operators, and could extend to broader classes of dynamical or equilibrium models.
Potential future directions include:
- Extending analysis beyond single-layer, small-scale models to deep or foundation-scale architectures.
- Mapping phenomena such as exponential token clustering and the interplay between recall placement and normalization-induced token collapse.
- Exploring further architectural and algorithmic modifications that guarantee not only necessary but sufficient conditions for robust algorithmic generalization on practical reasoning workloads.
Conclusion
"Stability and Generalization in Looped Transformers" (2604.15259) systematically explains and quantifies the architectural mechanisms that enable or impede looped transformers from scaling up test-time computation robustly. The primary technical contribution is the demonstration, both mathematically and empirically, that combining recall with outer normalization is required to obtain a broad regime of stable, input-sensitive fixed points, essential for generalization beyond the training regime. The axes of stability framework serves as a foundation for future work on scalable, generalizing neural computation and highlights key pitfalls for practitioners designing algorithmic or reasoning-capable architectures.

