- The paper introduces YOCO-U, using recursive efficient self-attention to scale depth without increasing parameter counts or global cache sizes.
- YOCO-U achieves a 62% reduction in training tokens and a 24.4% boost in accuracy on math benchmarks compared to non-recursive variants.
- The architecture attains 10× higher prefilling throughput and stable long-context performance, ensuring efficient inference for large language models.
Universal YOCO-U: Synergistic Efficient-Attention Recursion for Depth Scaling in LLMs
Architectural Innovations and Methodology
Universal YOCO (YOCO-U) is proposed as a scalable recursive architecture for autoregressive LLMs, combining two key components: the YOCO decoder-decoder framework and parameter-sharing recursive computation. The motivation is to address limitations in standard Transformers when scaling inference-time computation—particularly high cost and proliferation of per-layer KV caches—which compromise memory and throughput for long-context modeling.
YOCO-U splits the model into two half-depth blocks: a Self-Decoder and a Cross-Decoder. The core innovation is substituting the static Self-Decoder with a Universal Self-Decoder that applies T recursive iterations using shared parameters. These iterations are restricted to shallow, efficient self-attention layers employing local windowed attention (e.g., sliding-window attention), enabling the recursive block to increase representational depth without increasing the parameter count or the global cache size. The global KV cache, produced once by the Self-Decoder, remains constant regardless of recursion count, while only local windowed KV caches scale with T, thus keeping overall cache overhead negligible.
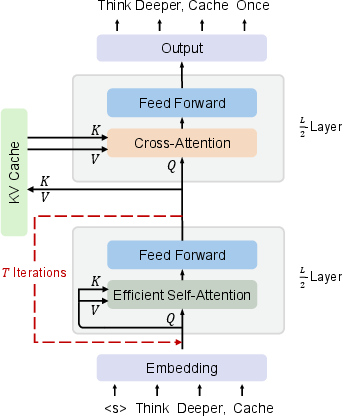
Figure 1: The YOCO-U architecture, depicting recursive efficient-attention computation in the Self-Decoder and constant global KV cache reuse in the Cross-Decoder.
Fundamentally, YOCO-U preserves the inference benefits of YOCO—linear-complexity pre-filling and constant global cache memory—while leveraging recursive computation in the shallow block for improved representational power. Importantly, recursion is not applied to global attention, so compute or memory scaling does not correspond to full quadratic increases as in standard looped Transformers.
Capability-Efficiency Tradeoff and Scaling Behavior
Extensive benchmarking demonstrates YOCO-U's favorable tradeoff of capability versus efficiency compared to both non-recursive YOCO and conventional recursive Transformer variants:
- When scaling training FLOPs, YOCO-U achieves lower loss (ΔL=0.033) at identical compute budgets, with negligible KV cache overhead. It also demonstrates superior token efficiency, requiring 62% fewer training tokens to reach comparable performance.
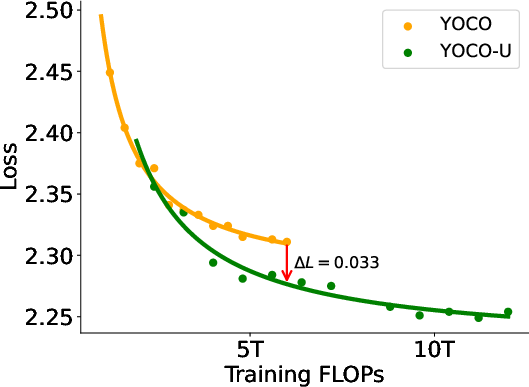
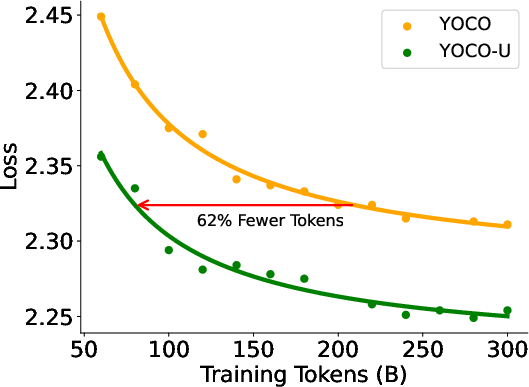
Figure 2: YOCO-U achieves lower loss at matched FLOPs, and improves token efficiency relative to non-recursive YOCO.
- On 11 mathematical reasoning benchmarks, YOCO-U consistently outperforms YOCO, exhibiting an average accuracy boost of 24.4%, demonstrating the orthogonality of recursive latent computation and explicit test-time scaling in mathematical reasoning.
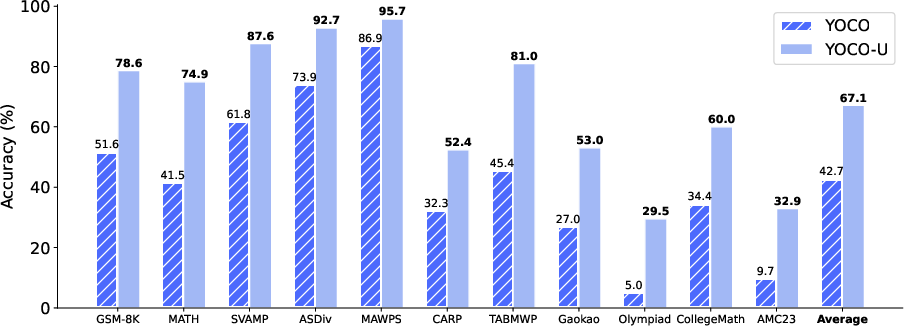
Figure 3: YOCO-U surpasses YOCO across all math benchmarks in accuracy, showing strong improvements in explicit and latent reasoning tasks.
- Long-context modeling is robust: evaluation of perplexity versus input length on book and code datasets reveals YOCO-U outperforms both Transformer and YOCO baselines; it maintains parity with RINS, a heavier recursive baseline, indicating effective utilization of long-range context with efficient-attention recursion.
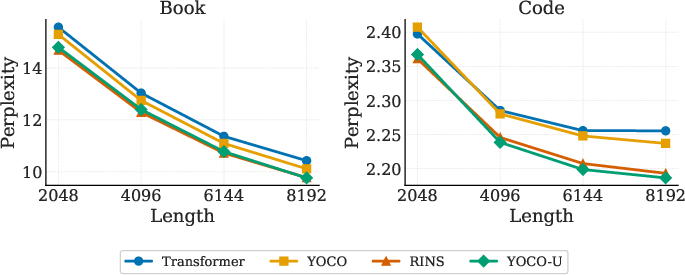
Figure 4: YOCO-U maintains lower perplexity with increasing input length, showing no degradation in long-context modeling compared to heavier recursive baselines.
Parameter and Loop Scaling
- YOCO-U demonstrates parameter scaling stability, achieving comparable performance with up to 50% fewer parameters while activated parameter count increases.
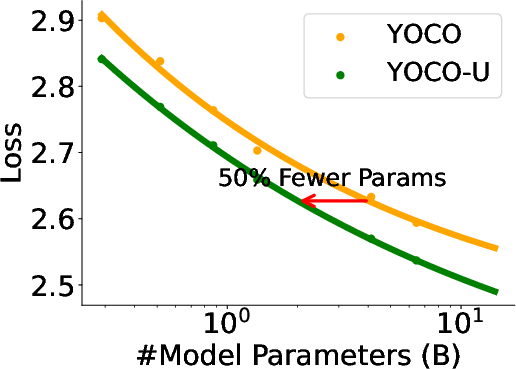
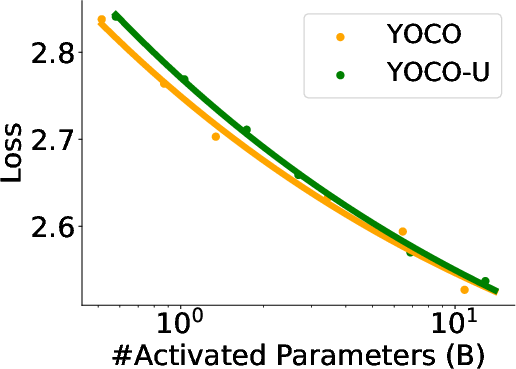
Figure 5: YOCO-U maintains performance with reduced parameter counts and scalable parameter utility as activation increases.
Inference Efficiency
Performance evaluations in high-throughput, memory-managed inference environments confirm:
- Prefilling throughput is 10× higher for YOCO-U than Transformer and 20× over RINS, even with additional depth.
- Decoding throughput sacrifices only 5% relative to YOCO, compared to the substantial throughput penalty in looped full-attention baselines.
- KV cache memory overhead is nearly identical to YOCO; increases are negligible and dominated by local efficient-attention, not by global cache proliferation.
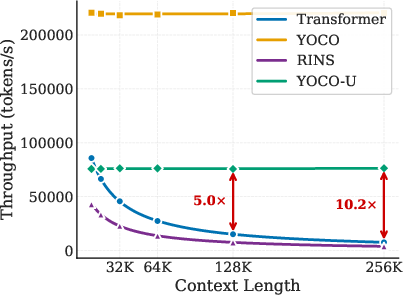
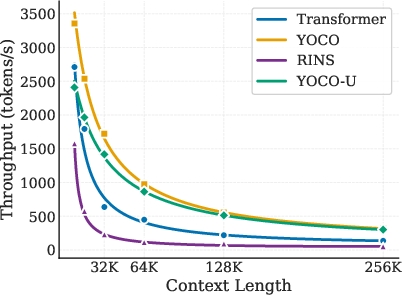
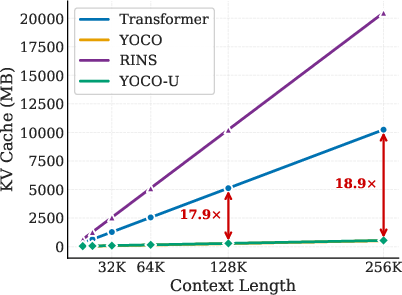
Figure 7: YOCO-U achieves competitive prefilling efficiency and minimal memory overhead compared to non-recursive YOCO and recursive RINS.
Representation Dynamics and Ablation Insights
Angular distance analysis between consecutive layers shows consistent recursive refinement within the Universal Self-Decoder, with diminishing marginal returns and sharp discontinuities at block interfaces, supporting the functional separation between recursive refinement and final decoding.
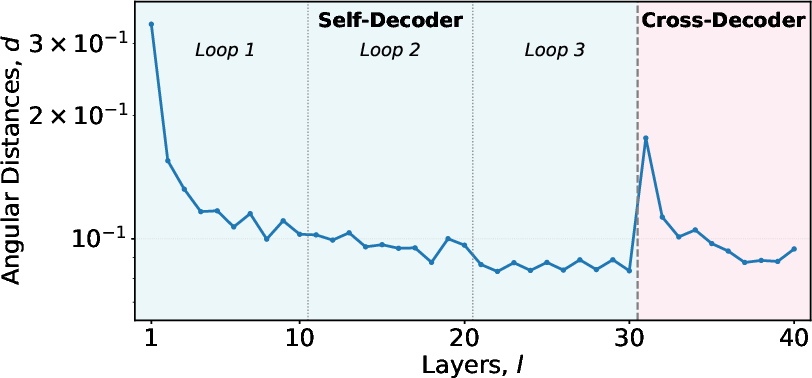
Figure 8: Angular distances validate that iterative refinement in the Universal Self-Decoder approaches a fixed-point, with block boundaries indicating functional transitions.
Ablation studies comparing recursion at different positions, depth versus width scaling, and KV cache management reveal that looping shallow blocks delivers greater improvement than looping deeper layers, and that computation depth contributes more to capability than parameter size or model layout.
Implications and Future Directions
YOCO-U exemplifies a scalable architecture balancing computational depth, memory efficiency, and inference throughput. Efficient depth scaling via parameter-sharing recursion in shallow efficient-attention blocks offers practical advantages for serving LLMs in long-context tasks within constrained hardware budgets. The capability-efficiency gains achieved by YOCO-U suggest the trajectory for future LLM architectures: decoupling depth scaling from memory overhead, hybridizing efficient-attention recursion with static global retrieval, and leveraging loop scaling for both training and inference workloads.
This architecture is well-suited for multimodal and agentic LLMs requiring real-time complex reasoning at scale. Investigating further hybrid recursion strategies and dynamic loop control, as well as integration into cross-modal models, are promising future directions for efficient, capable, and cost-effective foundation models.
Conclusion
Universal YOCO-U provides a robust, efficient framework for recursive depth scaling in LLMs, unifying efficient-attention recursion with constant global KV cache management. YOCO-U achieves superior scaling properties, improved token utility, and enhanced reasoning performance while maintaining inference efficiency and minimizing memory overhead. The synergy between partial recursion and efficient-attention architectures establishes a practical foundation for scalable LLM systems (2604.01220).