A Mechanistic Analysis of Looped Reasoning Language Models
Abstract: Reasoning has become a central capability in LLMs. Recent research has shown that reasoning performance can be improved by looping an LLM's layers in the latent dimension, resulting in looped reasoning LLMs. Despite promising results, few works have investigated how their internal dynamics differ from those of standard feedforward models. In this paper, we conduct a mechanistic analysis of the latent states in looped LLMs, focusing in particular on how the stages of inference observed in feedforward models compare to those observed in looped ones. To this end, we analyze cyclic recurrence and show that for many of the studied models each layer in the cycle converges to a distinct fixed point; consequently, the recurrent block follows a consistent cyclic trajectory in the latent space. We provide evidence that as these fixed points are reached, attention-head behavior stabilizes, leading to constant behavior across recurrences. Empirically, we discover that recurrent blocks learn stages of inference that closely mirror those of feedforward models, repeating these stages in depth with each iteration. We study how recurrent block size, input injection, and normalization influence the emergence and stability of these cyclic fixed points. We believe these findings help translate mechanistic insights into practical guidance for architectural design.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks inside special LLMs that “loop” their thinking. Instead of just moving forward through layers once, these models reuse the same set of layers again and again during one answer. The authors ask: when a model thinks in loops, what is it actually doing step by step, and how is that different from a normal (feedforward) model that goes through its layers only once?
What questions were the researchers asking?
In simple terms, they wanted to know:
- Do looped models settle into a steady “thinking routine” if you run the loop multiple times?
- Do the loops repeat a series of thinking stages (like gather → compress → combine → decide) similar to what normal models learn across depth?
- What design choices (like how many layers are in a loop, how you “nudge” the loop with fresh input each time, and how you normalize activations) make the loops stable and useful?
- Can these models keep behaving sensibly if you ask them to loop more times than they were trained to?
How did they study it?
Think of a LLM’s layers as a set of tools. A normal (feedforward) model uses each tool once in order: tool 1, tool 2, …, tool N. A looped model takes a small toolbox (say 4–12 tools) and reuses that same toolbox several times: toolbox → toolbox → toolbox. The authors peeked inside the model’s “internal notes” as it loops to see what changes.
Here are the key ideas and how they explain them:
- “Looped Transformer”: A Transformer where a fixed block of layers is applied repeatedly. This lets the model spend more “thinking steps” on harder problems at test time.
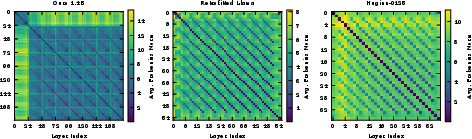
- “Attention patterns”: Inside each layer, attention heads decide where to “look” in the text (which previous words matter). The researchers compared these attention patterns across loops to see if they stabilize.
- “Fixed point” and “cyclic fixed point”:
- Fixed point: If you run the same block again and again, the internal state stops changing much—like practicing the same routine until you end up doing it the same way each time.
- Cyclic fixed point: The state doesn’t collapse to one spot, but cycles through a stable, repeating route—like following the same looped path every time.
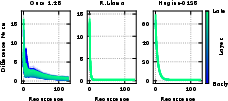
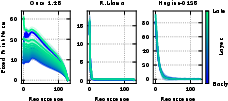
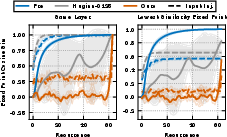
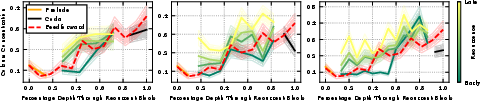
- “Stages of inference”: Prior work shows normal models go through phases across depth—for example: 1) lightly mixing information, 2) strongly compressing info (often focusing attention on a few “anchor” tokens), 3) combining details, 4) final decision steps. The authors measured a simple “mixing” score (called ColSum concentration) to see where attention mass is focused. High concentration = the model is focusing on fewer tokens (strong compression).
- What they actually did:
- Compared several looped systems, including:
- A model trained from scratch with loops (Ouro).
- A standard model retrofitted to loop (e.g., a Llama variant).
- Another looped model (Huginn-0125).
- Measured how similar attention patterns are across loops.
- Tracked how much the internal states change from one loop to the next (using distances and cosine similarities).
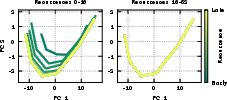
- Visualized the internal state’s “path” using dimensionality reduction (like PCA) to see if it cycles.
- Tested architecture tweaks:
- Input injection: giving the loop a small “fresh reminder” each time it starts a new pass, which helps stabilize behavior.
- Normalization styles: different ways to keep numbers from blowing up or shrinking too much.
- Block size: how many layers you repeat.
- Trained small looped models from scratch with a simple objective and a fixed number of loops to check if stages appear naturally (without fancy training tricks).
What did they find and why does it matter?
Here are the main takeaways:
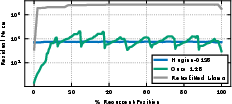
- Many looped models settle into a stable routine
- After a few loops, each layer’s attention pattern becomes very similar from loop to loop. This means the model’s “where to look” behavior stabilizes.
- Often the internal states follow a repeating cycle (a “cyclic fixed point”) across the layers in the block.
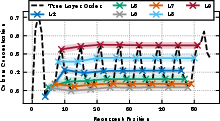
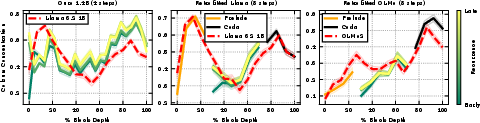
- Looped blocks repeat the same thinking stages each time
- The familiar stages seen in normal models (gather → compress → combine → decide) reappear inside each looped block.
- Over multiple loops, the model mostly re-enacts the “middle” stages, while the “beginning” and “ending” stages are handled once by extra layers before and after the loop (called prelude and coda).
- Architecture choices control stability
- Input injection (a small, fresh input each loop) helps the model converge to stable behavior.
- Certain normalization schemes allow the model’s internal signals to grow and compress in ways that create clear stages. Others (that normalize too aggressively) can prevent these stages from forming.
- Even randomly initialized looped models show a tendency toward cyclic behavior, suggesting the architecture itself encourages this.
- These stages can self-organize during training
- In small models trained from scratch (without training tricks that would bias them toward feedforward behavior), the stages still emerged. That hints that these stages are useful and naturally arise because they help with language modeling.
- Stability matters for generalization
- Models that truly converge to stable cycles keep their stages and attention behaviors even if you ask them to loop more times than they were trained for.
- Models that don’t converge can become unstable or drift when asked to do extra loops, which can hurt performance.
Why this matters:
- Understanding the “looped thinking” routines helps engineers design better, more reliable reasoning models.
- Stable loops mean you can spend more test-time compute (more loops) without breaking behavior.
- If looped blocks reliably repeat known stages, we can make those middle stages leaner or more efficient (e.g., sparser attention), saving compute.
What could this mean in the future?
- Better reasoning with flexible compute: You can give models more “thinking steps” when problems are hard, without retraining or risking weird behavior—if the architecture is designed for stability.
- Smarter design rules: Use input injection and the right normalization to get stable cycles and clear stages. Then optimize those stages (e.g., lighter middle layers) to save time and energy.
- Clearer windows into model behavior: Because looped models reuse the same block, it’s easier to see and study repeating thought patterns. That can transfer insights from standard models into looped ones.
In short, the paper shows that looped LLMs often settle into predictable, repeating thought patterns that mirror the stages of normal models—and that with the right design choices, these loops are stable, efficient, and effective for reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing or uncertain in the paper, framed so future work can address each item directly.
- Lack of formal convergence conditions: No analytical characterization of when cyclic fixed points emerge (vs. degenerate fixed points or non-convergent dynamics) as a function of normalization, residual scaling, activation types, and parameter norms.
- Distinct vs. degenerate fixed points: No theory predicting when each layer converges to distinct points along a limit cycle versus collapsing to the same fixed point (observed with pre-norm without input injection at random init).
- Convergence rates and dependence on architecture: No estimates of convergence speed to cyclic fixed points (or attention-pattern convergence) in terms of , , norm type (LayerNorm vs RMSNorm), residual scaling, and input-injection strength.
- Basins of attraction: No study of how initial states (e.g., sequence content, position in the residual stream, or injected noise ) affect which fixed point/cycle is reached and how large those basins are.
- Non-fixed limiting behaviors: Only cursory mention of rare non-fixed behaviors (e.g., longer-period limit cycles, quasi-periodic or chaotic orbits); no taxonomy, prevalence, or conditions under which they arise.
- Theoretical status of the softmax bound: The Lipschitz argument for attention similarity lacks tight constants and operational criteria (e.g., how to verify and in practice across architectures).
- Role of positional encoding across recurrences: No analysis of how RoPE or absolute position embeddings interact with looping (e.g., whether position re-use or drift affects convergence or mixing stages).
- Input injection design space: Input injection is treated as a binary choice; no ablations on injection distribution, noise scale , projection sharing, per-recurrence vs per-layer injection, or token-wise vs sequence-wise injection.
- Norm-structure causality: The claim that Huginn’s repeated residual normalization suppresses “compression valleys” is not causally verified via trained-model ablations isolating only the norm change (holding all other factors constant).
- Prelude and coda roles: Limited mechanistic analysis of what prelude/coda layers compute and how they interact with the repeated “middle” stages, especially in retrofitted models versus models trained with recurrence from scratch.
- Head- and circuit-level functions: Stabilization is shown for attention patterns, but there is no head-wise or circuit-level identification (e.g., sink/induction heads) demonstrating whether the functions themselves stabilize and repeat.
- MLP dynamics under recurrence: No analysis of whether MLP subspaces/neurons stabilize or cycle across recurrences, and how that relates to compression and rank dynamics in middle stages.
- Task-level consequences of stages: The paper does not link the presence or stability of stages-of-inference to concrete task performance improvements (e.g., on GSM8K, MATH, long-context retrieval), beyond qualitative parallels.
- Generalization beyond studied benchmarks: Empirical evidence is limited to GSM8K (plus a brief HellaSwag appendix); no evaluation on broader reasoning tasks, multilingual data, long-context tasks, or structured reasoning benchmarks.
- Robustness to recurrence extrapolation: While some models degrade beyond train recurrences (e.g., Ouro), the paper does not provide a systematic, controlled evaluation across multiple tasks or a causal link between fixed-point stability and out-of-domain generalization.
- Scaling laws for looped stages: Small-scale training suggests self-organization, but there is no scaling study showing how stage formation changes with model size, data size, or training compute.
- Training dynamics and schedules: Little analysis of how recurrence schedules, curriculum (allowing 1 recurrence early), or loss decomposition (per-recurrence losses) shape the emergence and stability of stages.
- Multiple recurrent blocks (non-cyclic): The study excludes sequential recurrence with multiple distinct recurrent blocks; no extension of analysis or tools to that increasingly common design.
- Long-sequence effects: No exploration of how sequence length affects ColSum concentration, sink formation, and convergence properties; the entropy normalization by may complicate cross-length comparability.
- Sensitivity to perturbations: No tests of stability under input perturbations (e.g., prompt edits, adversarial tokens) or parameter noise (e.g., weight perturbations) at inference time across many recurrences.
- Halting/ponder policies: No integration with adaptive halting or test-time compute policies (e.g., ACT/PonderNet); unclear how cyclic fixed points interact with learned halting and overthinking avoidance.
- Practical stopping criteria: No actionable criterion (e.g., norm/cosine thresholds) to decide when to stop recurrences while preserving accuracy and avoiding compute waste.
- Computational trade-offs: No analysis of the compute–accuracy trade-off for recurrence counts, or how architectural choices (e.g., input injection) change inference cost per gain in performance or stability.
- Attention sparsity across stages: While the paper suggests stage-dependent sparsification opportunities, there is no quantitative exploration of head/row/column sparsity patterns within loops or their safety for pruning.
- Effects of optimization choices: No ablations on optimizer, learning rate schedules, weight decay, or norm epsilons and their interactions with recurrence stability and stage emergence.
- Dependence on pretrained vs from-scratch: The three pretrained models differ in training regimes; the paper does not control for these differences to isolate which training signals are essential for cyclic stage emergence.
- Random-init vs trained behavior gap: Architectural findings at random initialization are not verified post-training on the same architectures to confirm whether fixed-point regimes persist or change qualitatively.
- Role of token position and content: No per-token or per-position analysis of convergence (e.g., do sinks or fixed points vary across punctuation vs words, or early vs late positions).
- Effect of decoder-only vs encoder-decoder: All analyses focus on decoder-only LMs; no discussion of whether findings transfer to encoder-decoder or bidirectional models with recurrence.
- Safety/failure modes at high recurrences: No systematic search for pathological behaviors (e.g., oscillatory attention focusing on malicious tokens) as recurrence grows large.
- Theoretical links to expressivity: No formal connection between cyclic recurrence’s expressivity and the observed stages-of-inference, nor conditions where recurrence impairs/helps certain algorithmic tasks.
- Attribution to performance: No causal interventions (e.g., disrupting a detected stage) to demonstrate that repeated middle stages are necessary for measured performance gains in looped models.
- Geometry of latent orbits: PCA trajectories are shown, but no higher-dimensional characterization (e.g., orbit dimensionality, curvature, periodicity) or relation to attention/MLP subspaces.
- Positional drift across loops: Whether position encodings cause “time-step confusion” or require special handling when reapplying the same layers remains untested.
- Interaction with MoE and LoRA-style sharing: No exploration of how recurrence interacts with MoE routers/expert usage or partial parameter sharing (e.g., layer-wise LoRA in relaxed recursive transformers).
- Initialization schemes: No study of how different initializations (e.g., scaled variants, orthogonal, zero-centered attention bias) affect the emergence of cyclic fixed points during training.
- Practical guidance completeness: While input injection and norm choices are highlighted, the paper does not provide tested, end-to-end design recipes (with hyperparameters) that reliably yield stable, performant looped models across scales.
Practical Applications
Immediate Applications
The paper’s mechanistic insights into looped (recurrent-depth) Transformers enable deployable practices for designing, training, and operating reasoning-capable LLMs. The following applications are actionable with current tools and models.
- Bold name: Stage-stable looped LLM design guidelines (software/AI infrastructure)
- Use input injection and appropriate normalization (e.g., pre-norm or “sandwich” that avoids repeated residual normalization) to promote cyclic fixed points and preserve feedforward-like stages of inference inside recurrent blocks.
- Outcome: More reliable scaling of test-time compute without performance collapse when increasing recurrences.
- Tools/products/workflows: Architecture templates, configuration checklists for looped stacks, unit tests for recurrence stability.
- Assumptions/dependencies: Access to model architecture and training to adjust norms/input injection; stability correlates with performance as observed in cited works.
- Bold name: Test-time compute controllers based on convergence/stability (software/cloud ML; finance, healthcare)
- Halt or cap recurrences when attention patterns and layer-wise metrics (e.g., ColSum concentration) stabilize; increase recurrences only if convergence is not achieved.
- Outcome: Prevent overthinking, reduce costs, and improve reliability in regulated contexts.
- Tools/products/workflows: “Ponder controllers” that monitor per-recurrence metrics; adaptive halting in serving stacks (Triton/ONNX Runtime plugins).
- Assumptions/dependencies: Ability to expose attention or surrogate stability signals at inference; acceptable latency overhead for monitoring.
- Bold name: Recurrence-safe extrapolation policies (education, enterprise assistants, code copilots)
- Define safe operating ranges for number of recurrences (learned from training-time schedules) and fallback behaviors if stability is not reached (e.g., decrease recurrences, switch to base feedforward model).
- Outcome: Consistent user experience when users request “think longer” or “more steps.”
- Tools/products/workflows: Reasoning sliders with stability gating; fallback routing in LLM orchestration frameworks (LangChain, OpenAI Assistants).
- Assumptions/dependencies: Stability/performance relationship holds for target domain; observable convergence metrics.
- Bold name: Stage-aware efficiency optimizations (software/ML systems; energy efficiency)
- Apply attention sparsification and slimmer MLPs in middle-stage iterations where representations compress; cache stable attention and reuse across later recurrences.
- Outcome: Lower compute and energy for the same effective depth.
- Tools/products/workflows: Kernel toggles by stage, low-rank middle-stage MLPs, recurrent caching policies.
- Assumptions/dependencies: Access to stage/metric readouts; model retraining or fine-tuning may be needed to preserve accuracy with sparsity.
- Bold name: Retrofitting existing LLMs with recurrence (software, research)
- Introduce cyclic recurrence with shared weights and input injection to pretrained models to unlock reasoning gains and enable test-time compute scaling.
- Outcome: Improved reasoning without significantly increasing parameters.
- Tools/products/workflows: Fine-tuning pipelines that tie layer weights cyclically; adapters for input injection.
- Assumptions/dependencies: Model license and weights available; fine-tuning budget; compatibility of base architecture.
- Bold name: Monitoring and interpretability dashboards for looped models (industry, academia)
- Track cyclic trajectories, attention heatmaps across recurrences, and ColSum concentration to diagnose stability and stages of inference.
- Outcome: Faster debugging and safer deployment of looped models.
- Tools/products/workflows: Lightweight probes and visualization panels integrated into training/inference logs.
- Assumptions/dependencies: Ability to export/inspect intermediate states; privacy constraints for sensitive inputs.
- Bold name: OOD and failure detection via instability signals (healthcare, finance, legal)
- Use divergence from cyclic fixed points or drifting attention as an indicator of out-of-distribution inputs or reasoning failure; trigger human review or conservative responses.
- Outcome: Risk-aware deployment in safety-critical domains.
- Tools/products/workflows: Stability-based routing/alerts in decision support systems.
- Assumptions/dependencies: Validation that instability correlates with errors on the target data; governance for escalation paths.
- Bold name: On-device/edge reasoning with controllable compute (mobile, robotics, IoT)
- Trade off latency/energy vs. reasoning strength by varying recurrences, with stability-based early halting on-device.
- Outcome: Practical reasoning capabilities on constrained hardware.
- Tools/products/workflows: Mobile runtimes exposing recurrence controls; per-iteration budget schedulers.
- Assumptions/dependencies: Efficient kernels for attention and MLP; platform support for partial unrolling/weight tying.
- Bold name: Training recipes that avoid undesired norm regimes (ML engineering, research)
- Prevent repeated residual normalization that suppresses stage formation; choose norm schemes that allow residual growth necessary for compression/sink formation.
- Outcome: Models that learn robust stages of inference within recurrent blocks.
- Tools/products/workflows: Training configs, ablation harnesses to test norm/input-injection choices.
- Assumptions/dependencies: Replicability of observed behaviors across scales and datasets.
- Bold name: Academic benchmarks for stage/stability characterization (academia)
- Standardize evaluation using ColSum concentration and attention similarity across recurrences to compare looped architectures.
- Outcome: Reproducible measurement of reasoning-oriented inductive biases.
- Tools/products/workflows: Open-source benchmark suites and metrics packages.
- Assumptions/dependencies: Community adoption; alignment on metric definitions.
Long-Term Applications
These opportunities leverage the paper’s mechanistic findings but require additional research, scaling, or co-design with hardware and governance.
- Bold name: Stage-aware architectural co-design (software, compilers, hardware)
- Specialize kernels and memory layouts per stage (e.g., sparse attention in mid-stages, heavier mixers early/late); compile-time scheduling of cyclic blocks.
- Outcome: Substantial latency and energy reductions at scale.
- Tools/products/workflows: Graph compilers that detect and optimize cyclic fixed-point regions; stage-tagged IRs.
- Assumptions/dependencies: Stable stage boundaries across tasks; hardware vendor support.
- Bold name: Formal halting and safety guarantees for looping (policy, regulated sectors)
- Certify halting criteria using Lipschitz bounds and convergence tests; mandate reporting of test-time compute policies and stability metrics.
- Outcome: Trustworthy deployment in healthcare, aviation, and finance.
- Tools/products/workflows: Compliance toolkits, test suites for convergence; model cards including recurrence profiles.
- Assumptions/dependencies: Mature theoretical bounds and accepted standards; regulator buy-in.
- Bold name: Hardware acceleration for recurrent depth (semiconductors, cloud)
- Design accelerators that cache and reuse stable attention/value projections across recurrences; optimize for weight-tied execution.
- Outcome: Cost-effective “deep” reasoning with small parameter footprints.
- Tools/products/workflows: SRAM layouts for cyclic reuse; ISA support for loop primitives.
- Assumptions/dependencies: Sufficiently predictable stability; economic incentives for new silicon.
- Bold name: Stage-conditioned tool use and retrieval (enterprise software, RAG)
- Trigger external retrieval, calculators, or planners only in early/mixing stages; suppress in stable compressed stages to reduce chatter and cost.
- Outcome: More precise, cheaper tool-augmented reasoning.
- Tools/products/workflows: Orchestrators that read stage signals to gate tools.
- Assumptions/dependencies: Robust stage detection online; well-calibrated triggers.
- Bold name: Neuro-symbolic looped reasoners (robotics, planning, scientific discovery)
- Treat each recurring stage as an algorithmic subroutine (parse → mix → compress → decide), composing them with symbolic controllers.
- Outcome: More reliable multi-step planning and theorem-like reasoning.
- Tools/products/workflows: Hybrid planners that modulate recurrence depth per subtask.
- Assumptions/dependencies: Stable stage semantics; interfaces between symbolic and cyclic latent states.
- Bold name: Training objectives that encourage stable stages (research)
- Incorporate stability regularizers (e.g., attention similarity across recurrences) or stage-aware auxiliary losses to improve extrapolation to unseen recurrences.
- Outcome: Models robust to variable test-time compute.
- Tools/products/workflows: Loss components for convergence; curriculum schedules without single-recurrence bias.
- Assumptions/dependencies: Avoiding collapse of functional diversity across layers; no performance regressions.
- Bold name: Automated stage-aware model compression (ML tooling)
- Prune and quantize middle-stage layers more aggressively; distill recurrent blocks while preserving cyclic trajectories.
- Outcome: Smaller, faster looped models with preserved reasoning skill.
- Tools/products/workflows: Distillation recipes that match stage metrics and cyclic fixed points.
- Assumptions/dependencies: Reliable surrogates for reasoning quality; task transferability.
- Bold name: Domain-specific looped LLMs with certified extrapolation (law, medicine, finance)
- Train looped models that maintain stage behavior under extended recurrences; certify stability and document operating envelopes.
- Outcome: High-stakes assistants that can “think longer” safely.
- Tools/products/workflows: Domain validation suites measuring stability vs. accuracy.
- Assumptions/dependencies: Domain datasets; governance processes.
- Bold name: Stage-aware evaluation ecosystems (academia, standards bodies)
- Benchmarks that score both answer quality and stability under increased recurrences, across domains and OOD shifts.
- Outcome: Better model selection for real-world reliability.
- Tools/products/workflows: Multi-recurrence leaderboards; profile visualizations of cyclic trajectories.
- Assumptions/dependencies: Community consensus on metrics; scalable inference budgets.
- Bold name: Data curation to induce beneficial stage formation (research, data engineering)
- Construct curricula and datasets that promote clear stage separation and stable cyclic behavior.
- Outcome: Faster training and more robust reasoning dynamics.
- Tools/products/workflows: Data selection pipelines that monitor stage metrics during training.
- Assumptions/dependencies: Causal link between data properties and stage emergence; generalization across tasks.
Glossary
- approximate fixed point: A practical estimate of a fixed point obtained after a finite number of iterations instead of infinite convergence. Example: "its 'approximate fixed point' - the residual stream after that layer in the 128th recurrence."
- attention sink: A phenomenon where a few positions (often the first token or punctuation) accumulate disproportionate attention mass across layers. Example: "this metric captures the well-studied attention sink ... behavior"
- chain-of-thought (CoT) prompting: A prompting strategy that elicits step-by-step reasoning in LLMs by asking them to generate intermediate reasoning steps. Example: "chain-of-thought (CoT) prompting"
- ColSum Concentration: An entropy-based metric that quantifies how concentrated the received attention is across tokens (columns) in an attention matrix. Example: "we quantify our study of mixing behavior through the ColSum Concentration metric"
- cyclic fixed point: A limiting behavior where a cycle of layers maps latent states through a repeating orbit of distinct fixed states, one per layer in the cycle. Example: "Cyclic recurrent blocks reach cyclic fixed points"
- cyclic recurrence: Reusing a fixed sequence of layers repeatedly in a cycle to add recurrent depth. Example: "we analyze cyclic recurrence"
- dot product self-attention: The standard attention mechanism computing attention weights via scaled dot products between queries and keys. Example: "the dot product self-attention mechanism"
- fixed point: A stable state x such that further application of a function leaves it unchanged (f(x) = x). Example: "convergence to a fixed point"
- Frobenius norm: A matrix norm computed as the square root of the sum of the squares of all entries; used to compare attention matrices. Example: "Frobenius norm between attention patterns at different depths"
- input injection: Adding an external input into each recurrence (often via concatenation and projection) to encourage stability and convergence. Example: "this is known as input injection"
- latent space: The internal vector space of hidden representations where model states evolve across layers/recurrences. Example: "a consistent trajectory in latent space"
- Lipschitz constant: A bound on how much a function’s output can change relative to changes in its input; used to analyze stability. Example: "a Lipschitz constant of the row-wise softmax"
- logit lens: A technique that projects intermediate hidden states directly to vocabulary logits to analyze model predictions across depth. Example: "cyclic behavior in logit lens prediction throughout recurrent blocks"
- Looped Transformers: Transformer architectures that repeatedly apply the same block(s) to increase effective depth via recurrence. Example: "Looped Transformers are Transformers that utilize 'recurrence in depth'"
- mixing (attention): The extent to which attention at a layer integrates information from earlier tokens versus focusing locally. Example: "Mixing in this context refers to the extent to which the attention mechanism incorporates information from previous tokens at each layer."
- PCA (principal component analysis): A dimensionality reduction technique that projects data onto principal components for visualization or analysis. Example: "reduced to two dimensions by computing PCA"
- position-wise MLP: The feedforward component in a Transformer block applied independently to each token position. Example: "a position-wise MLP"
- prelude and coda layers: Non-recurrent layers placed before (prelude) and after (coda) the recurrent block in a “sandwich” architecture. Example: "we refer to these as prelude and coda layers respectively"
- pre-norm: A normalization scheme where layer normalization is applied before the attention/MLP sublayers within a block. Example: "We compare pre-norm (used by the retrofitted recurrent models)"
- recurrence in depth: Reapplying layers along depth to repeatedly transform the same latent states, increasing compute without increasing parameters. Example: "utilize 'recurrence in depth'"
- recurrent block: A (possibly multi-layer) block whose weights are shared and applied multiple times in sequence. Example: "the recurrent block"
- residual stream: The sequence of hidden states passed between blocks through residual connections. Example: "we refer to the intermediate hidden-state matrices ... as the residual stream"
- row-stochastic: A matrix whose rows each sum to one; attention matrices are row-stochastic due to softmax normalization. Example: "since A is row-stochastic"
- row-wise softmax: Applying softmax independently to each row of a matrix; in attention, it normalizes each query’s attention weights. Example: "the row-wise softmax"
- sandwich block structure: An architectural pattern with prelude layers, a recurrent core, and coda layers forming a “sandwich.” Example: "we refer to this as a sandwich block structure"
- sandwich norm structure: A normalization design that normalizes within and/or around sublayers in a patterned “sandwich” arrangement. Example: "use a 'sandwich' norm structure"
- spectral norm: The largest singular value of a matrix; used to bound operator behavior and stability. Example: "Spectral or Frobenius norms"
- stages of inference: Distinct phases across depth where layers exhibit qualitatively different attention/mixing behaviors. Example: "stages of inference"
- test-time computation: Additional compute spent during inference (e.g., more recurrences) to improve performance on difficult inputs. Example: "Test-time computation broadly refers to giving a model the ability to expend additional computational cycles at inference"
- weight-tied Transformer models: Models where the same layer weights are reused across multiple applications (e.g., recurrences), enforcing shared behavior. Example: "weight-tied Transformer models often tend towards consistent behavior"
Collections
Sign up for free to add this paper to one or more collections.