Hyperloop Transformers
Abstract: LLM architecture research generally aims to maximize model quality subject to fixed compute/latency budgets. However, many applications of interest such as edge and on-device deployment are further constrained by the model's memory footprint, thus motivating parameter-efficient architectures for language modeling. This paper describes a simple architecture that improves the parameter-efficiency of LLMs. Our architecture makes use of looped Transformers as a core primitive, which reuse Transformer layers across depth and are thus more parameter-efficient than ordinary (depth-matched) Transformers. We organize the looped Transformer into three blocks--begin, middle, and end blocks--where each block itself consists of multiple Transformer layers, and only the middle block is applied recurrently across depth. We augment the looped middle block with hyper-connections (Xie et al., 2026), which expand the residual stream into matrix-valued residual streams. Hyper-connections are applied only after each loop, and therefore add minimal new parameters and compute cost. Across various model scales, we find that our Hyper-Connected Looped Transformer (Hyperloop Transformer) is able to outperform depth-matched Transformer and mHC Transformer baselines despite using approximately 50% fewer parameters. The outperformance persists through post-training weight quantization, thus positioning Hyperloop Transformers as an attractive architecture for memory-efficient language modeling.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to build LLMs that takes up much less memory without losing (and sometimes even improving) performance. The authors combine two ideas—reusing the same layers multiple times (“looping”) and adding extra “shortcut” paths (“hyper-connections”)—to create “Hyperloop Transformers.” These models are designed to be more memory-friendly, so they can run better on devices like phones and laptops.
What questions were the researchers asking?
In simple terms, they wanted to know:
- Can we make LLMs that are smaller (fewer “parameters,” which are like the model’s memory) but still perform as well as bigger ones?
- Can this be done in a way that keeps speed and accuracy strong, even after compressing the model further (like shrinking file sizes)?
- Which design choices (how many loops, how many shortcut paths, etc.) give the best balance between size and quality?
How did they approach the problem?
Think of a Transformer (the core of many LLMs) like a factory assembly line for words:
- A typical Transformer has many steps (layers). Each step transforms the sentence representation a bit.
- More steps usually mean better results, but they also mean more memory.
Here’s what the authors changed:
- Reusing middle steps (looping):
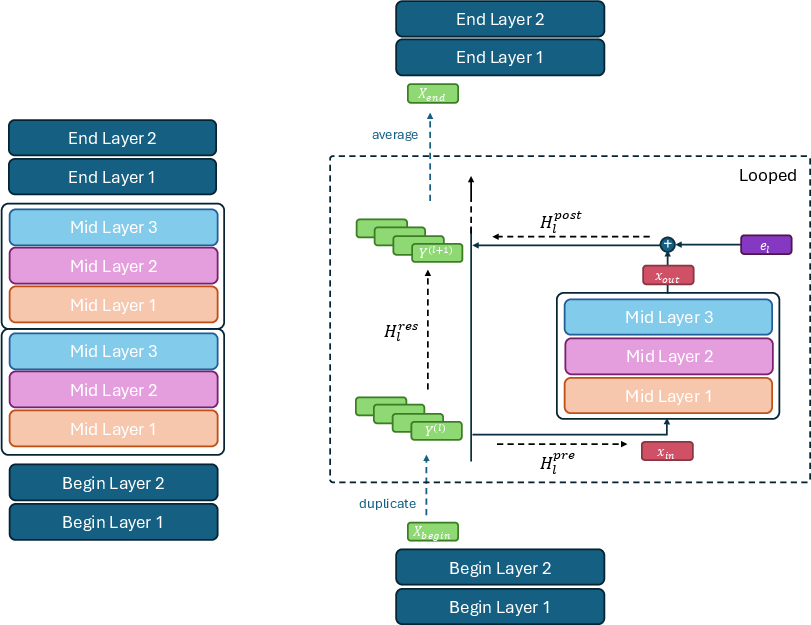
- They split the model into three parts: a begin block, a middle block, and an end block—like an introduction, body, and conclusion.
- Instead of building a super long model with lots of unique layers, they loop the middle block a few times. This is like running the same group of steps again and again.
- Reusing the same block saves a lot of memory because you don’t need a separate copy of those layers for every depth.
- Adding hyper-connections (extra shortcuts):
- Normally, information flows forward in one “stream,” like a single notebook passed down the line.
- Hyper-connections create several parallel streams—think of having multiple notebooks so different kinds of information can flow side by side.
- In this paper, these hyper-connections are only applied after each loop (not after every layer), keeping extra cost very small.
- They also use a simpler way to mix these streams (a lightweight “diagonal” mixer), which saves compute and still works well.
- Loop position “tags”:
- They add a tiny “loop position embedding” (like a loop number or tag) so the model knows which pass it’s on. That helps the model adjust its behavior across loops.
- Training and testing:
- They trained models at several sizes (around 240M, 1B, and 2B parameters in the normal baseline) on a large text dataset.
- They tested both general language quality (using a score called “perplexity”—lower is better) and performance on reading/QA benchmarks.
- They also tried “quantization,” which compresses weights into very small numbers (like turning high-resolution images into low-resolution ones). This drastically reduces memory again, and they checked whether the model still works well.
What did they find?
Here are the main results:
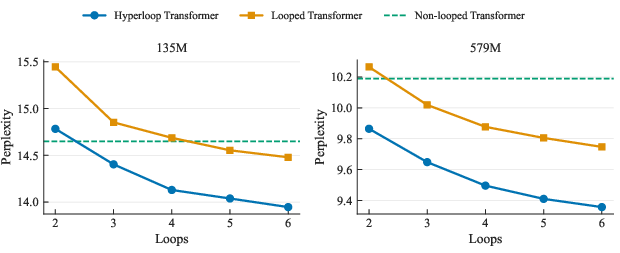
- Better performance with fewer parameters:
- Hyperloop Transformers matched or beat normal Transformers that had roughly twice as many parameters. In other words, they used about 50% less memory but still did as well or better.
- They consistently showed lower perplexity (better language modeling) across multiple model sizes.
- Keeps working after compression:
- After compressing the models to low-precision numbers (INT4), Hyperloop Transformers kept more of their performance than similar looped models without hyper-connections. That’s great for running on memory-limited devices.
- Minimal slowdown:
- Because hyper-connections are only used after each loop and use a simple mixer, training speed was almost the same as normal models (minimal overhead).
- Strong on downstream tasks:
- On tasks like reading comprehension and multiple-choice reasoning, the Hyperloop models generally scored best among the tested architectures.
- Design insights:
- More loops help up to a point (diminishing returns).
- A small number of hyper-connections (one per loop) worked best—adding them after every layer didn’t help.
- A few parallel streams (like 4) work well; adding many more gives only small gains.
- Their simpler mixer (diagonal) worked as well as or better than heavier, more complex mixers.
Why is this important?
- Runs on smaller devices:
- Using about half the parameters means models are much easier to store and run on phones, tablets, or laptops—places with limited memory.
- Cheaper and greener:
- Smaller models can be cheaper to deploy and may use less energy.
- Flexible future scaling:
- Looping offers a new way to scale capability (by doing more “passes” at test time) without growing the model’s stored size.
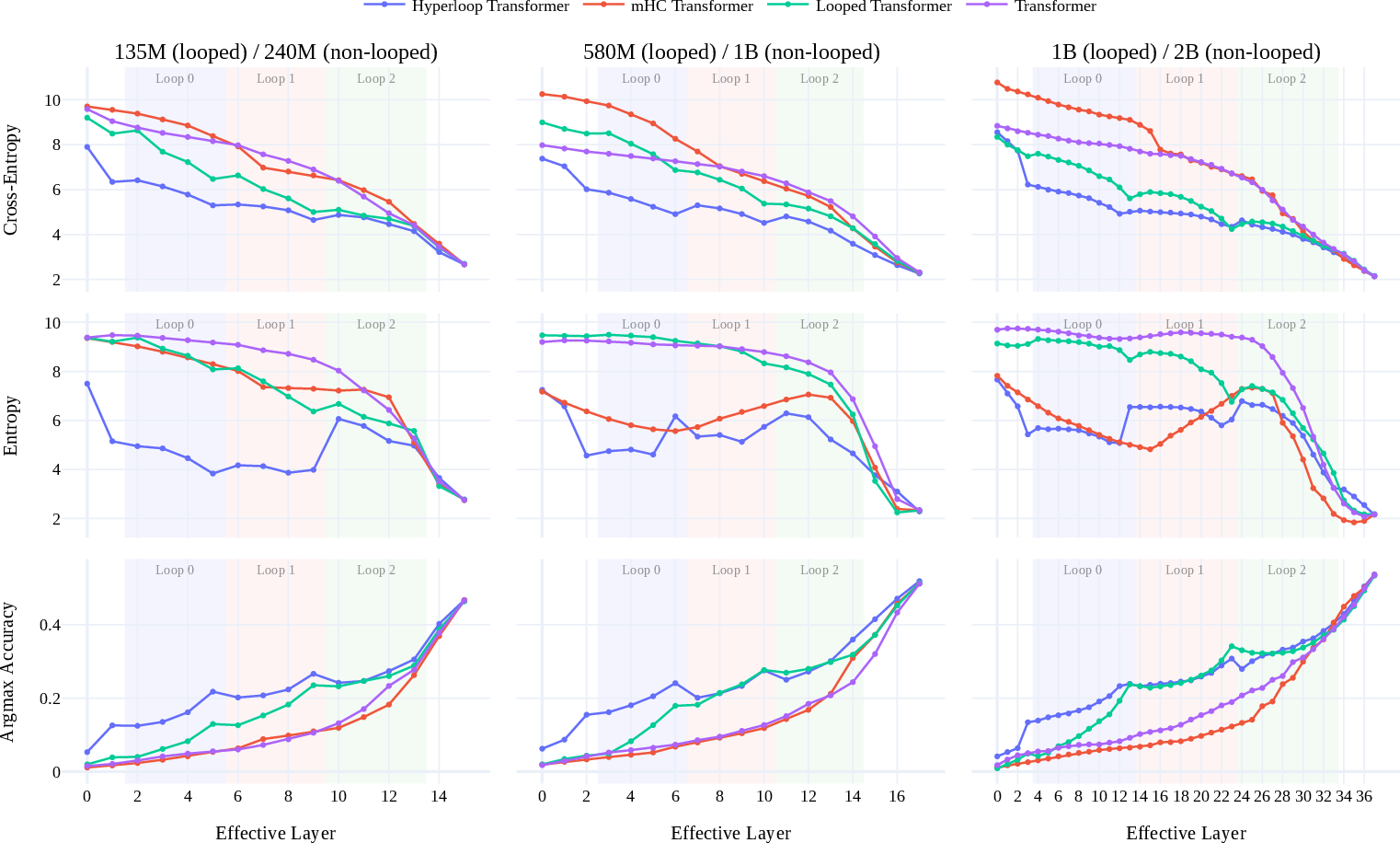
- The analysis suggests these models may also support early-exit strategies (stopping early if the model is confident), saving compute.
Bottom line
The Hyperloop Transformer is a simple, smart redesign that reuses layers and adds lightweight parallel “shortcut” paths. It delivers equal or better language performance using roughly half the parameters, stays strong after aggressive compression, and runs nearly as fast as standard models. This makes it a promising approach for bringing capable LLMs to memory-limited devices—and a useful direction for building efficient, scalable AI systems in the future.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Scaling to larger regimes: Verify whether the ≥50% parameter reduction at matched or better perplexity holds at larger scales (e.g., 7B–70B) and over trillion-token pretraining; report full compute-quality curves and scaling laws.
- Compute fairness and FLOPs matching: Re-run comparisons under strictly matched training and inference FLOPs (not just tokens or depth) to isolate architectural benefits from compute allocation differences.
- Inference-time KV-cache memory: Quantify how looping affects KV-cache size (do loops require multiple distinct KV sets per “unrolled” depth?) and whether parameter-memory savings translate into total inference memory savings at long context lengths.
- Latency and throughput tradeoffs: Benchmark end-to-end prefill/decoding latency and tokens/s (including FlashAttention and fused kernels) at parity perplexity against strong Transformer baselines on diverse hardware (A100/H100, consumer GPUs, mobile NPUs).
- Long-context performance: Evaluate length generalization and long-context benchmarks (e.g., LRA, LONG-Bench, 128k+ contexts), and test compatibility with GQA/MQA, sliding-window, or sparse attention variants.
- Early-exit and dynamic loops: Implement entropy- or confidence-based per-token early exiting and adaptive loop counts; characterize the compute–quality frontier and stability under dynamic recursion.
- Test-time loop scaling: Assess generalization to more (or fewer) loops at inference than used in training; explore sharing or conditioning of hyper-connection parameters to enable robust test-time scaling.
- Begin/middle/end budget allocation: Systematically search the optimal parameter split across begin/middle/end blocks at fixed depth and compute; quantify sensitivity and interactions with number of loops.
- Hyperparameter sensitivity: Map performance as a function of optimizer, LR schedules, regularization, and normalization variants (e.g., pre-/post-LN) to determine if Hyperloop requires different tuning than standard Transformers.
- Loop position embeddings: Ablate the necessity, form, and placement of loop embeddings (vector vs scalar, sinusoidal vs learned, shared vs per-layer) and measure effects on stability and performance.
- Hyper-connection design space: Explore beyond diagonal Hres to low-rank, structured sparse, or blockwise mixing; per-head vs shared Hres; and when (per-layer vs per-loop) to apply hyper-connections at larger scales.
- Number of streams n: Extend scaling studies of n (parallel residual streams) to larger models; derive compute/memory/performance tradeoffs and diminishing returns thresholds.
- Initialization of parallel streams: Test learned projections or orthogonalization to initialize streams (instead of naïve copying) to promote representational diversity and reduce cross-loop redundancy.
- Robustness to quantization: Evaluate additional methods (AWQ, SmoothQuant, QAT), activation and KV quantization, lower bit-widths (INT3/INT2), different group sizes, and calibration set sizes; report downstream task accuracy post-quantization, not only perplexity.
- KV-cache compaction for loops: Develop algorithms to reuse or compress K/V across loop iterations, mitigating potential KV explosion due to recursive depth.
- Distributed training compatibility: Study pipeline/tensor/sequence parallelism efficiency with looped weight sharing and hyper-connections; quantify communication overheads and memory fragmentation.
- Instruction/chat finetuning: Assess whether parameter-efficiency gains persist through SFT, preference optimization/RLHF, and multi-stage finetuning; measure stability and catastrophic forgetting.
- Broader downstream coverage: Add code (HumanEval/MBPP), math (GSM8K/MATH), knowledge (MMLU), and complex reasoning benchmarks; report few-shot and chain-of-thought settings.
- Comparison to alternative parameter-efficient baselines: Include ALBERT-style sharing, adapter/LoRA families (beyond a small LoRA rank sweep), residual-mixing methods (DenseFormer/DeepCrossAttention), and SSM/state-space models under matched compute.
- Training stability of loops: Characterize gradient dynamics, vanishing/exploding behavior, and the role of loop embeddings or gating in stabilizing training across deeper recursions.
- Regularization and normalization: Explore dropout in hyper-connections, stochastic depth across loops, alternative norms (RMSNorm vs LayerNorm variants), and their impact on convergence and generalization.
- Energy and on-device feasibility: Measure end-to-end on-device memory (weights + KV + activations) and energy/thermal behavior on representative mobile SoCs; validate the claimed suitability for edge deployment.
- Systems-level kernels: Provide or evaluate specialized kernels for hyper-connections (forward/backward), including fusion with attention/MLP to reduce overhead in practice.
- Multimodal and encoder–decoder extensions: Test applicability to vision-language and speech-text models, and to encoder–decoder architectures with cross-attention.
- Safety and robustness: Evaluate calibration, toxicity/harms, adversarial robustness, and OOD generalization; analyze whether looping or hyper-connections introduce new failure modes.
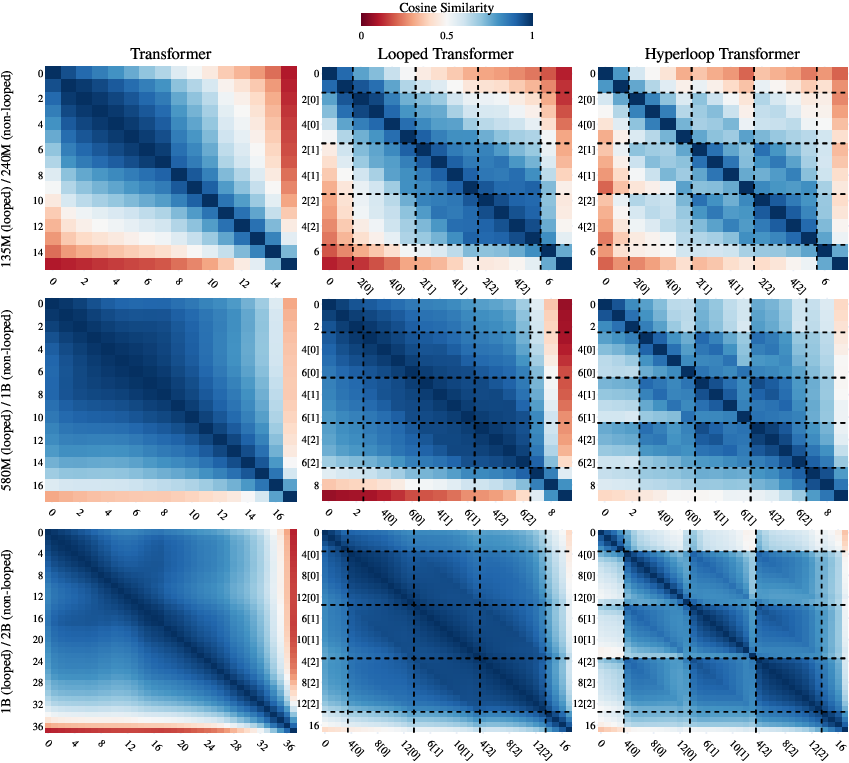
- Interpretability and mechanism: Perform mechanistic studies of information routing across parallel streams and loops (causal ablations, attention flow), and link representation similarity metrics to task performance.
- Continual and test-time adaptation: Investigate whether looped/hyper-connected structures improve or hinder continual learning, adapters, or test-time training schemes.
- Theoretical foundations: Develop theory on expressivity, sample efficiency, and optimization for loop-level hyper-connections (e.g., why diagonal Hres can outperform doubly-stochastic mixing), and predict when gains should appear or vanish with scale.
Practical Applications
Immediate Applications
Below are deployable use cases and workflows enabled by the paper’s “Hyperloop Transformers” (looped middle block + loop-level hyper-connections, matrix-valued residual streams, minimal added compute), which achieve comparable or better quality with ~50% fewer parameters and remain robust under INT4 post-training quantization.
- Edge and on‑device language assistants (sector: consumer software, mobile, wearables)
- Use cases: offline summarization, translation, email drafting, note-taking, voice assistants on smartphones, tablets, AR glasses, and wearables where RAM is tightly limited.
- Why now: ~50% parameter reduction plus demonstrated INT4 weight-only GPTQ yields materially smaller memory footprint without sacrificing perplexity or task accuracy at 240M–2B scales.
- Tools/workflows: replace baseline Transformer blocks with Hyperloop blocks in mobile SDKs (Core ML, NNAPI, MediaPipe, ONNX Runtime Mobile). Ship INT4 weights. Provide a “loops” knob to meet latency targets.
- Assumptions/dependencies: availability of a PyTorch/ONNX implementation; INT4-supported kernels on device NPUs/GPUs; English-centric benchmarks may not reflect all languages.
- Enterprise edge deployments (sector: retail, call centers, field service, kiosks)
- Use cases: store-level query-answering, call transcript summarization at the edge, offline kiosks, factory floor terminals where Internet and memory are constrained.
- Why now: memory footprint is often the bottleneck in ruggedized/edge boxes; Hyperloop fits within smaller DRAM footprints and tolerates INT4 quantization.
- Tools/workflows: deploy as a local microservice with GPU-lite or CPU-only INT4 inference; batch-friendly hosting due to reduced memory per instance.
- Assumptions/dependencies: minimal Python/C++ bindings and ops for loop-level hyper-connections; reliability testing under low-power thermal constraints.
- Privacy-preserving, on‑device inference (sector: healthcare, finance, government/defense)
- Use cases: local document redaction, templated report drafting, interactive form completion without sending data to cloud.
- Why now: parameter and weight-size reductions make on-device feasible, lowering data exfiltration risk.
- Tools/workflows: PEFT/LoRA adapters on device; restrict updates to begin/end blocks while keeping looped middle frozen.
- Assumptions/dependencies: compliance review; domain fine‑tuning; careful evaluation—models are not certified for autonomous clinical/financial decisions.
- Cloud inference cost and capacity optimization (sector: AI platforms, MLOps)
- Use cases: host more model replicas per GPU; reduce VRAM fragmentation and checkpoint storage; lower cold-start memory in serverless LLM endpoints.
- Why now: halving parameter count typically halves weight memory, enabling higher batch sizes or cheaper GPU tiers; minimal throughput penalty observed.
- Tools/workflows: swap baseline 1B‑param models for ~580M Hyperloop equivalents in inference fleets; use modified GPTQ with loop-aware Hessian accumulation for INT4.
- Assumptions/dependencies: throughput/perplexity trade-offs validated on target workloads; INT4 kernels for all layers; memory bandwidth benefits realized in practice.
- Robust INT4 quantization pipelines for looped models (sector: model compression tooling)
- Use cases: extend GPTQ to looped layers by aggregating activations across loop iterations during Hessian estimation (as in paper).
- Why now: paper’s method shows small degradation in INT4; practical for deployment today.
- Tools/workflows: patch GPTQ/calibration scripts; CI to verify loop-aware quantization on various loop counts and group sizes.
- Assumptions/dependencies: availability of calibration data; adherence to paper’s group-size/calibration settings or retuning for new domains.
- Parameter-efficient fine‑tuning and distribution (sector: model marketplaces, OSS)
- Use cases: distribute “small large” LLMs (e.g., ~580M) that match ~1B baselines in quality; lower bandwidth/storage for model hubs.
- Why now: Pareto improvement in performance per parameter simplifies shipping and caching.
- Tools/workflows: publish Hyperloop model variants with PEFT adapters; templated begin/middle/end partitions for consistent fine‑tuning.
- Assumptions/dependencies: community adoption of architecture; consistent tokenizer and RoPE settings across variants.
- On-device education apps (sector: education)
- Use cases: offline reading assistance, cloze practice, quiz generation, and low-latency feedback on student writing, especially in bandwidth-poor regions.
- Why now: memory footprint and INT4 resilience enable mid‑range devices to run useful LMs locally.
- Tools/workflows: integrate with app frameworks; per-lesson caching; fixed loop counts to meet latency budgets.
- Assumptions/dependencies: domain adaptation for pedagogy; accessibility and safety filters; multilingual tuning as needed.
- Lightweight RAG at the edge (sector: enterprise productivity, legal, support)
- Use cases: local retrieval-augmented generation over device or site data (docs, manuals) without cloud dependency.
- Why now: smaller LMs can pair with small FAISS/ScaNN indexes under memory caps.
- Tools/workflows: bundle compact retrievers; prompt templates optimized for smaller LMs; fixed or dynamic loops based on query complexity.
- Assumptions/dependencies: domain prompts; small retriever footprint; robust evaluation for hallucinations.
- Robotics and embedded systems (sector: robotics, IoT)
- Use cases: instruction following, status summarization, or natural-language interfaces on embedded compute (UAVs, service robots).
- Why now: tight VRAM/DRAM budgets; adjustable loops permit latency-quality trade-offs.
- Tools/workflows: compile with TensorRT/TVM; expose loop count as a real-time control parameter.
- Assumptions/dependencies: deterministic timing requirements; safety guardrails; integration with sensor pipelines.
- Academic replication and pedagogy (sector: academia)
- Use cases: teaching parameter-efficiency techniques; benchmarking looped models vs. baselines; analyzing residual-matrix behavior.
- Why now: paper’s methods work with off‑the‑shelf hyperparameters and standard datasets.
- Tools/workflows: PyTorch modules for begin/middle/end partitions; ablation scripts for loops/streams; logit-lens probes for loop boundaries.
- Assumptions/dependencies: reproducible seeds/data; release of reference implementation.
Long‑Term Applications
These opportunities require further research, scaling experiments, systems engineering, or ecosystem support before widespread deployment.
- Frontier-scale deployment with reduced memory footprint (sector: AI platforms, hyperscalers)
- Vision: 10B–100B+ Hyperloop models that sustain the ~50% parameter advantage while matching or exceeding baseline quality.
- Potential products: memory-optimized LLM families for multi-tenant serving; “lite” frontier variants for edge clusters.
- Dependencies: validation at scale; training stability across long schedules; distributed training support for looped layers.
- Dynamic early-exit and test‑time compute scaling (sector: software, MLOps)
- Vision: per-token or per-sequence adaptive loop counts controlled by entropy/uncertainty, saving compute when confidence is high.
- Potential products: inference controllers that modulate loops; SLAs with compute-aware decoding policies.
- Dependencies: robust early-exit criteria; latency predictability; evaluation of accuracy-regression trade-offs across tasks.
- Mixture-of-recursions and token‑adaptive loops (sector: research, high-performance inference)
- Vision: combine Hyperloop with dynamic recursive depths (per token) for finer-grained compute allocation.
- Potential products: “smart loop schedulers” embedded in decoders; energy-aware inference on mobile NPUs.
- Dependencies: training objectives for stability; scheduling heuristics; hardware-friendly control flow.
- Multimodal Hyperloop architectures (sector: vision-language, speech, XR)
- Vision: parameter-efficient VLMs/SLMs with looped middle blocks to keep VRAM within mobile/embedded budgets.
- Potential products: on‑device captioning/transcription for AR glasses; in-vehicle assistants with local ASR+LLM.
- Dependencies: adapting hyper-connections to cross-modal blocks; GPU/NPU kernels; dataset availability.
- Federated and on-device continual learning (sector: privacy tech, personalized AI)
- Vision: personalize only begin/end (or hyper-connection) parameters on-device; share minimal updates in federated setups.
- Potential products: privacy-first personalization kits; rapid incremental learning with tiny update payloads.
- Dependencies: catastrophic forgetting mitigation; secure aggregation; regulatory compliance.
- Hardware-software co‑design and specialized kernels (sector: semiconductors, systems)
- Vision: fused kernels for loop-level hyper-connections, memory-efficient depth unrolling, and cache-friendly layout for residual matrices.
- Potential products: accelerator primitives for matrix-valued residuals; compiler passes for loop-aware scheduling.
- Dependencies: vendor collaboration; kernel libraries; benchmarks showing end-to-end gains.
- Quantization-aware training and low-bit extensions (sector: compression tooling)
- Vision: 3–4 bit weight‑activation quantization for looped models with minimal degradation; per-loop calibration strategies.
- Potential products: QAT recipes specialized for looped layers; loop-aware post-training quantizers for INT3/INT2.
- Dependencies: stability at larger scales; calibration protocols; support for mixed-precision attention.
- Distillation pipelines targeting Hyperloop students (sector: model compression, OSS)
- Vision: distill larger teachers (baseline or MoE) into compact Hyperloop students to maximize parameter-efficiency and privacy.
- Potential products: distillation toolkits with loop-aware loss terms; teacher–student recipes for begin/middle/end partitioning.
- Dependencies: data curation; aligning loop position embeddings; task-generalization studies.
- Energy and sustainability policy frameworks (sector: policy, ESG)
- Vision: guidelines encouraging parameter- and memory-efficient architectures for government and public-sector AI deployments.
- Potential products: procurement checklists including “memory per task-quality” metrics; incentives for on-device/offline solutions.
- Dependencies: standardized benchmarks for memory/quality; lifecycle carbon analyses; verification criteria.
- Safety, verification, and interpretability for looped models (sector: safety research)
- Vision: formal analyses of looped dynamics; safe early-exit policies; mechanistic insights using matrix-valued residuals.
- Potential products: certifiable early-exit thresholds; alignment probes tied to loop positions.
- Dependencies: interpretability tools for looped depth; red-teaming across dynamic compute regimes.
- Low-connectivity public services and digital public goods (sector: govtech, NGOs)
- Vision: deploy capable, offline LMs for citizen services (form assistance, local-language guidance) where connectivity is limited.
- Potential products: multilingual, memory-lean civic assistants on shared terminals or mobile devices.
- Dependencies: inclusive multilingual training; cultural/contextual evaluation; governance and accountability frameworks.
- In-vehicle and industrial control assistants (sector: automotive, manufacturing)
- Vision: manuals/query assistance, anomaly explanation, and operator guidance running locally in constrained compute environments.
- Potential products: local copilots for assembly lines or vehicle HMIs with dynamic loop counts to meet real-time requirements.
- Dependencies: real-time bounds; safety certification; domain-specific fine‑tuning.
Cross-cutting Assumptions and Dependencies
- Scalability and generality: Results are shown at ~240M–2B and one overtrained 136M setting; parity at 10B+ remains to be demonstrated.
- Kernel and framework support: Loop-level hyper-connections need efficient kernels across CUDA, ROCm, Metal, mobile NPUs, and deployment runtimes.
- Quantization support: INT4 robustness is demonstrated with GPTQ modifications; production use may require QAT or richer calibration for new domains.
- Data and language coverage: Benchmarks are primarily English; multilingual and domain-specific performance require validation.
- Safety and compliance: For regulated sectors, these models must be paired with appropriate guardrails, human oversight, and domain evaluation.
These applications leverage the paper’s core advances—looped middle blocks, loop-level hyper-connections with minimal overhead, parameter-efficiency, and robust low-bit quantization—to enable useful deployments today and chart a path for scalable, memory-efficient AI systems.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient-based updates to improve training stability. "AdamW as our optimizer"
- BF16: A 16-bit floating-point format (bfloat16) that preserves exponent range of FP32 with reduced precision for efficient training/inference. "mixed precision with BF16 weights"
- Birkhoff polytope: The set of all doubly stochastic matrices; useful for representing permutations as convex combinations. "on the Birkhoff polytope"
- calibration set: A small dataset used to compute statistics for quantization or other post-training adjustments. "a calibration set of 1024 sequences"
- Chinchilla-optimal: Refers to compute-optimal scaling of tokens vs parameters suggested by Chinchilla scaling laws. "the Chinchilla-optimal token count"
- cosine decay learning rate schedule: A training schedule where the learning rate decreases following a cosine curve after warmup. "cosine decay learning rate schedule"
- depth-wise RNN: Viewing stacked or looped depth as a recurrent dimension, treating depth steps like time steps in an RNN. "depth-wise RNN"
- doubly stochastic: A square matrix whose rows and columns each sum to one with nonnegative entries. "is doubly stochastic"
- DRAM: Dynamic Random-Access Memory; main system memory whose bandwidth/latency can impact model inference. "memory (DRAM)"
- early-exit: An inference strategy that stops computation early when sufficient confidence is reached to save compute. "early-exit-style inference strategies"
- entropy-regularized objective: A training objective augmented with entropy terms to encourage uncertainty calibration or smoother distributions. "an entropy-regularized objective"
- GPTQ: A post-training, Hessian-informed weight quantization method for large models. "using GPTQ to INT4"
- Hessian estimation: Approximating second-order curvature (Hessian) information of the loss, often to guide quantization or optimization. "the Hessian estimation for a looped layer"
- Hyper-Connected Looped Transformer (Hyperloop Transformer): The proposed architecture that combines looped Transformers with hyper-connections applied at loop boundaries. "Hyper-Connected Looped Transformer (Hyperloop Transformer)"
- hyper-connections: Mechanisms that expand and mix multiple residual streams via learned transformations between blocks or layers. "hyper-connections"
- INT4: 4-bit integer precision used for aggressive weight-only quantization to reduce memory footprint. "INT4 models"
- language modeling head: The final projection layer mapping hidden states to vocabulary logits for next-token prediction. "via the language modeling head"
- log-normal Poisson distribution: A count distribution where the Poisson rate is log-normally distributed, used to sample variable loop counts. "sampled from a log-normal Poisson distribution"
- logit lens: An analysis technique that maps intermediate hidden states through the LM head to inspect token-level predictions. "logit lens-style analysis"
- LoRA: Low-Rank Adaptation; adds trainable low-rank updates to frozen weights to adapt models efficiently. "using LoRA"
- loop position embedding: An embedding that encodes the index of the current loop iteration to inform the model of depth step. "loop position embedding"
- Looped Transformers: Transformers that share parameters across depth by reusing layers multiple times. "Looped Transformers"
- manifold-constrained hyper-connections (mHC): A hyper-connection variant that constrains mixing matrices (e.g., via Sinkhorn) to lie on structured manifolds. "manifold-constrained hyper-connections"
- Mixture-of-Experts (MoE): Architectures that route tokens to a subset of expert subnetworks to scale parameters sparsely. "mixture-of-experts"
- NVLink: A high-speed interconnect for GPUs that increases bandwidth for multi-GPU training/inference. "with NVLink"
- Pareto frontier: The set of solutions that optimally trade off multiple objectives (e.g., performance vs efficiency). "Pareto frontier"
- perplexity: A standard metric for LLMs measuring how well a probability distribution predicts a sample. "from a perplexity standpoint"
- post-training quantization: Converting trained model weights to lower precision without retraining to reduce memory and latency. "Post-training quantization of a model's weights"
- residual stream: The pathway carrying additive skip connections through Transformer blocks, here potentially expanded to multiple streams. "residual stream"
- RoPE embeddings: Rotary Position Embeddings; encodes positions by rotating query/key vectors in attention. "RoPE embeddings"
- Sinkhorn-Knopp algorithm: An iterative normalization procedure to project a matrix to the set of doubly stochastic matrices. "Sinkhorn-Knopp algorithm"
- SwiGLU: A gated MLP activation (Swish-Gated Linear Unit) that improves Transformer performance over vanilla ReLU/GeLU. "SwiGLU MLP layers"
- universal Transformers: Transformers that share parameters across layers and iterate to refine representations, akin to recurrence. "universal Transformers"
- weight-only quantization: Quantization methodology that reduces weight precision while keeping activations in higher precision. "the weight-only quantization setting"
Collections
Sign up for free to add this paper to one or more collections.

