Scaling Latent Reasoning via Looped Language Models
Abstract: Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped LLMs (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-LLM.github.io.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way to make LLMs “think” better without making them huge. Instead of asking a model to write out long reasoning steps in plain text (like chain-of-thought), the authors teach the model to think silently inside itself by looping the same set of brain-like layers several times per input. They call this a Looped LLM (LoopLM) and release models named Ouro (after the looping Ouroboros symbol). The big idea: reuse the same mental step multiple times, so the model can refine its understanding before answering.
Key Questions the paper asks
Here are the simple questions the researchers wanted to answer:
- Can looping the same layers (instead of adding more new layers) make small models perform like much bigger ones?
- Do more loops always help, and can the model learn to use more loops only when a question is hard?
- Are the improvements because the model knows more facts, or because it gets better at combining and using the facts it already knows?
- Does this inner (silent) reasoning make the model safer and more honest than writing out chain-of-thought?
How the approach works (in everyday language)
Think of solving a tough homework problem:
- In a normal model, it’s like reading the problem once through a long stack of different tools, then answering.
- In a LoopLM, it’s like using the same toolkit several times in a row, refining your understanding each pass. Each pass is a “loop,” and the model’s inner state is like your mental notes.
Here are the main parts, explained simply:
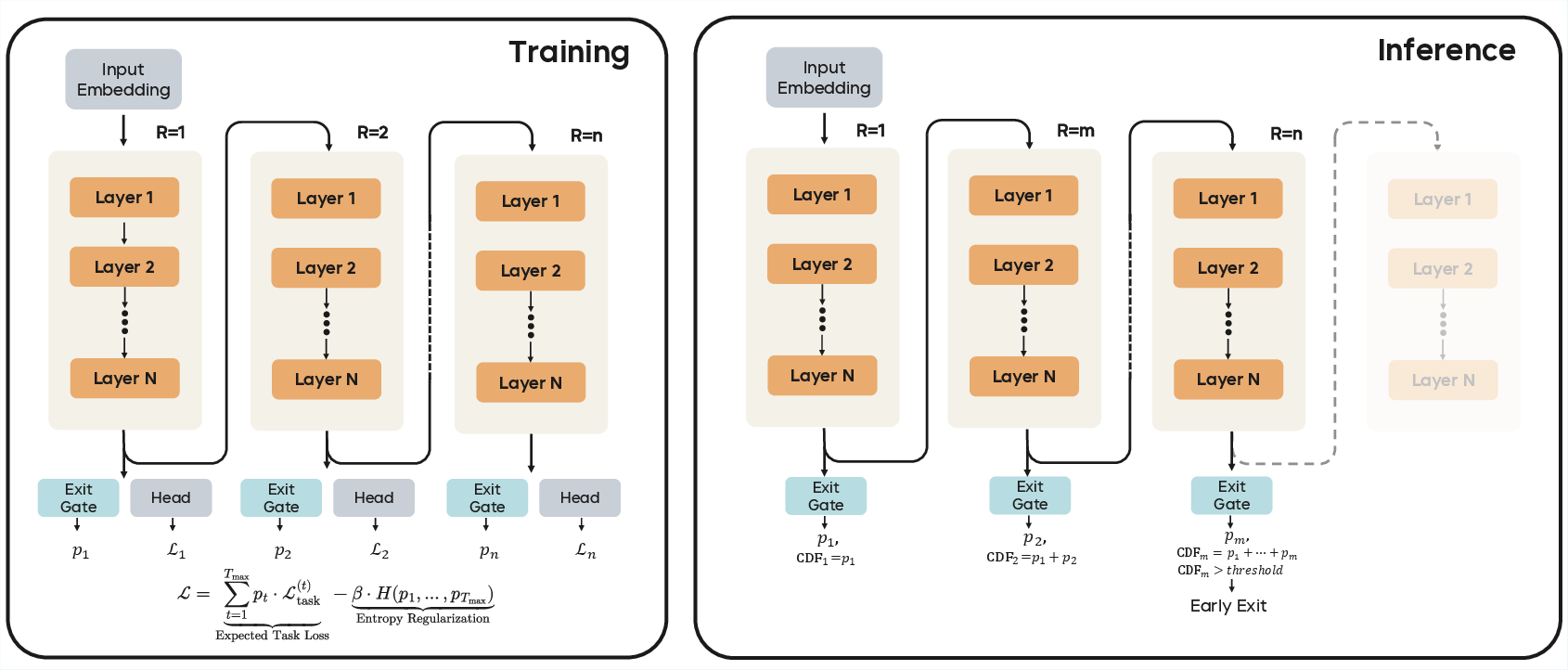
- Reusing the same layers: Instead of having, say, 48 different layers, the model has a smaller set of layers that it applies again and again. This saves “memory” (fewer parameters) but still lets the model think deeper by looping.
- Silent inner thoughts: The model improves its hidden representation with every loop, like editing a rough draft before anyone sees it.
- An early-exit “stoplight”: A small gate decides whether to continue thinking or stop and answer. Easy questions can stop early; hard ones can take more loops.
- Fair exploration of depth: During training, the model is encouraged to try different numbers of loops (not just stopping early by default). That’s like a teacher asking you to practice both quick answers and slow, careful thinking so you learn when each is needed.
- Two-stage training for the gate:
- Stage I: Train the whole model and the gate together, encouraging exploration of different loop depths.
- Stage II: Freeze the model, then train only the gate to stop when extra thinking no longer improves the answer (like learning to recognize, “Okay, I’ve got it now”).
- Practical scale: They trained on a huge amount of data (about 7.7 trillion tokens) and built two models—Ouro 1.4B and Ouro 2.6B—and then fine-tuned them for reasoning.
Main findings and why they matter
To make the results easy to scan, here are the key takeaways:
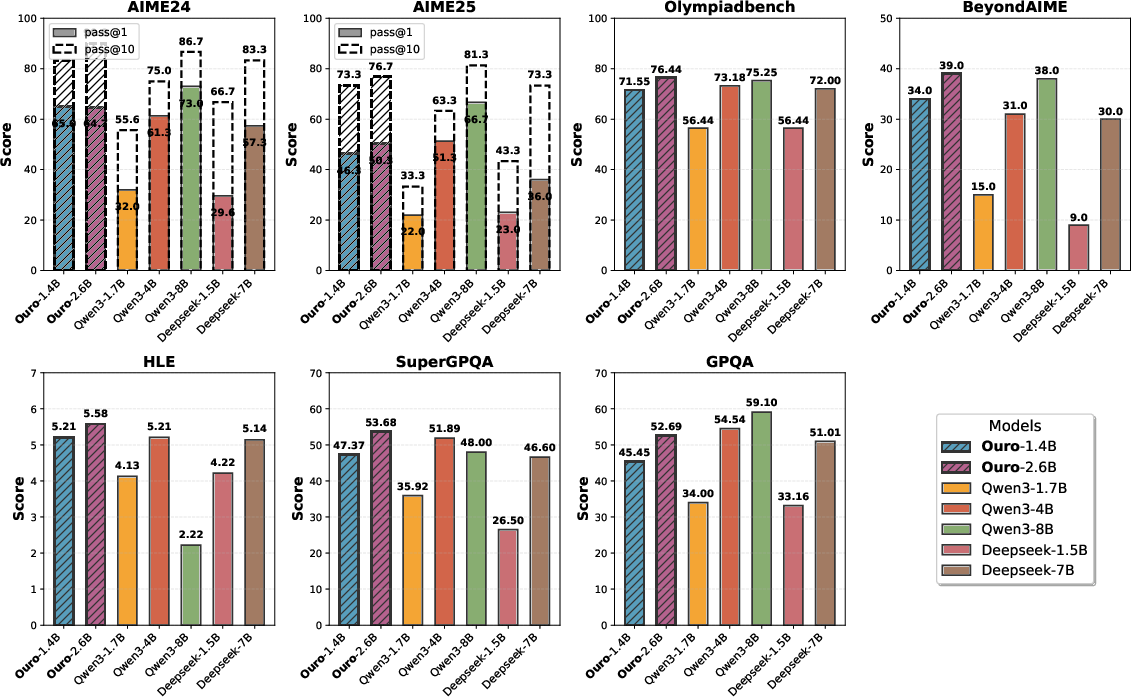
- Big performance from small models: The 1.4B-parameter LoopLM matches typical 4B models, and the 2.6B LoopLM matches or beats many 8B models (and sometimes even larger ones) on math, science, and general benchmarks. That’s about 2–3× better “skill per parameter.”
- Better at using knowledge, not just storing it: Both looped and standard models store about the same amount of raw knowledge per parameter, but the looped models are better at combining facts and doing multi-step reasoning. In other words, looping helps “how to think,” not just “how much you know.”
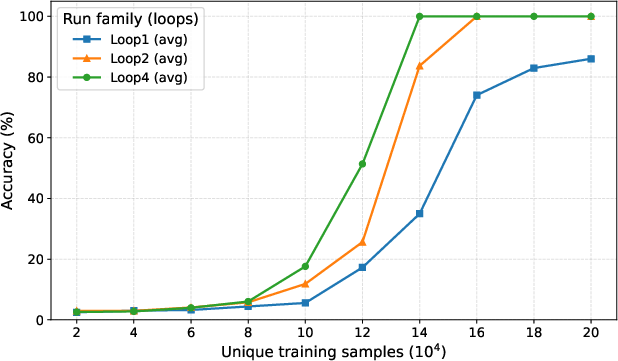
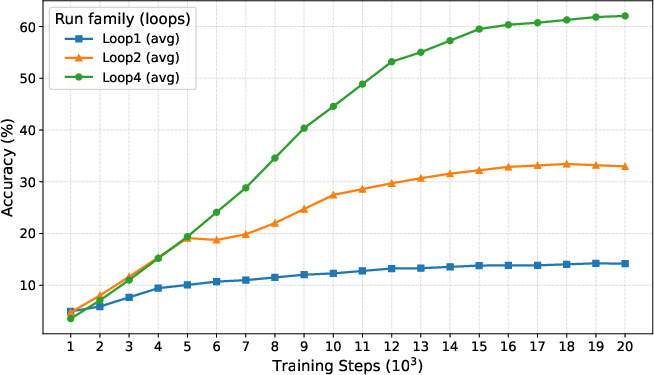
- Adaptive compute works: The gate learns to spend more thinking loops on hard inputs and fewer on easy ones, saving time and cost without losing accuracy.
- Safer and more faithful: With more loops, the models tend to produce fewer harmful outputs in tests, and their inner updates are more closely tied to the final answer. This is different from chain-of-thought, which can sometimes look like a made-up explanation after the fact.
- Efficient reasoning without long outputs: Because the model reasons internally, it doesn’t need to print long chains of text, which keeps context shorter and speeds things up.
What this could change (implications)
- A new “third axis” for scaling: Instead of only making models wider (more parameters) or feeding them more data, we can also make them “think deeper” by adding loops. This can deliver big gains without huge hardware.
- Cheaper, faster deployment: Smaller models that think better are easier to run on regular servers or even edge devices, lowering costs and improving access.
- Less reliance on long chain-of-thought prompts: If models can reason well inside, we may not need to force them to write long explanations, which can slow them down and bloat the context.
- More honest reasoning: Internal, step-by-step refinement that aligns with the final answer can reduce “post-hoc” explanations and make models’ thinking more trustworthy.
In short, this paper shows that teaching models to think by looping their own layers—deciding how long to think based on the problem—can make small models act like much bigger ones, reason more reliably, and do it all more safely and efficiently.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise list of the paper’s key unresolved issues. Each point targets what is missing, uncertain, or left unexplored, and is framed to be actionable for future research.
Architecture and Training
- Lack of theoretical analysis of convergence and stability for recurrent depth with weight sharing, especially beyond 4–8 loop steps.
- No characterization of when tied-weight recurrence is equivalent (or inferior) to untied deeper transformers in terms of expressivity and optimization.
- Insufficient detail and ablation on the upcycling method (layer stacking to 48 layers): initialization strategy, transfer stability, and performance impact versus training from scratch.
- Training instability at 8 loops is reported but not systematically addressed; methods such as auxiliary losses, spectral normalization, residual scaling, or gradient surgery are not evaluated.
- No exploration of alternative loop schedules (e.g., curriculum on loop depth, dynamic loop count during pre-training) and their impact on generalization and stability.
- Missing sensitivity analysis of key hyperparameters (learning rates, β for entropy/KL, batch size scaling, norm/activation choices) on loop robustness and final capability.
- No study of looped depth scaling laws (loss vs. tokens vs. loops) to determine saturation points and optimal compute allocation across axes.
Adaptive Computation and Gating
- The gate training in Stage II uses a hand-tuned improvement threshold and slope (τ, k); there is no sensitivity analysis, principled derivation, or comparison to alternatives (RL/ACT/PonderNet variants).
- Ambiguity in gate granularity: per-token versus per-sequence exit decisions and their differing compute/performance trade-offs are not clarified or studied.
- The inference-time threshold q is fixed heuristically; there is no calibration strategy to map q to accuracy/latency budgets across tasks or deployment settings.
- No exploration of token-level heterogeneity in gating (different tokens requiring different loop counts) and its effect on throughput and quality.
- Lack of ablations comparing uniform prior (entropy regularization) to geometric/Poisson-lognormal priors across diverse tasks and scales; the appendix is referenced but not included.
- Absence of analysis on gate failure modes (misclassifying hard examples as easy, and vice versa) and mitigation strategies (uncertainty-aware gates, confidence calibration).
Data and Tokenization
- The tokenizer (Latin/code-focused) excludes Chinese tokens after Stage 1 and may limit advanced math symbol coverage; impact on multilingual and mathematical reasoning is not quantified.
- No controlled study on how tokenizer choice (e.g., math-optimized, multilingual) interacts with looped reasoning and affects gains.
- Pre-training decontamination is not described; only mid-training decontamination is noted—risk of benchmark contamination from massive web datasets remains unassessed.
- Limited transparency on data mixing ratios over time and how different mixtures (web/math/code/SFT) modulate loop benefits and adaptive gating behavior.
Evaluation and Baselines
- Baseline fairness is unclear: differences in tokenizer, data scale, training compute, and context length are not fully normalized; head-to-head controlled comparisons are missing.
- No inference efficiency metrics are reported (latency, FLOPs/token, memory footprint, energy) for LoopLM versus depth-equivalent untied transformers and versus CoT prompting.
- Lack of detailed accuracy–compute Pareto curves showing how loop count and q affect performance across task categories (math, code, long-context).
- Long-context benefits of looping are not empirically dissected (e.g., retrieval, cross-document reasoning, memory retention) despite 64K training.
- No evaluation of loop extrapolation (using more steps than trained) on general capability—only safety is briefly claimed to improve.
Theory and Mechanistic Understanding
- The “~2 bits per parameter” storage claim (from physics-of-LMs framing) is shown on synthetic tasks; no validation on real-world tasks, domains, or larger scales.
- Unclear mechanistic pathways by which recurrence improves “knowledge manipulation” (fact composition, multi-hop reasoning); missing causal/probing analyses on attention/FFN dynamics across steps.
- No analysis of latent fixed points, limit cycles, or stability of hidden-state trajectories when looping beyond training depth.
- Missing formal definition and measurement of “latent reasoning faithfulness” compared to CoT—no causal intervention or counterfactual consistency tests.
Safety and Alignment
- Safety improvements are shown on HEx-PHI only; broader adversarial evaluations (jailbreaks, prompt injection, content moderation) are absent.
- Mechanism by which increased loops improve safety is speculative; there is no analysis of how gating and deeper latent updates reduce harmful generations.
- Potential risks of overthinking (looping too long increasing hallucinations or harmful content) are not measured or mitigated beyond the gate loss.
- Post-training alignment tax is mentioned but not quantified; impact of SFT on base model capabilities and loop behavior is not assessed.
Deployment and Efficiency
- Absence of end-to-end inference throughput measurements when using adaptive exits: real-world latency under varying q, batch sizes, and context lengths.
- No profiling of memory reuse benefits from weight tying at scale (activation checkpointing, KV caching implications, decoder-step costs).
- Missing guidelines for selecting q (and maximum loops) per application to meet SLAs, cost constraints, or energy budgets while preserving accuracy.
- Unclear interaction of looping with decoding strategies (beam search, temperature, top-p) and how it impacts output diversity and robustness.
Generalization and Robustness
- No OOD evaluations to test whether gating and loops generalize to unseen domains, noisy inputs, or distribution shifts.
- Lack of multilingual evaluation and transfer experiments (given early inclusion/removal of Chinese data) to understand cross-lingual loop benefits.
- No robustness studies under perturbations (e.g., typos, adversarial paraphrases, long-context distractors) to stress-test gating and loop depth allocation.
These gaps outline concrete directions for follow-up work: controlled baseline parity, principled gate training and calibration, tokenizer and data mixture studies, thorough efficiency profiling, formal faithfulness metrics, deeper mechanistic analysis, broader safety testing, and comprehensive robustness evaluations.
Practical Applications
Practical Applications of LoopLM (Ouro): From Findings to Real-World Impact
The paper introduces Looped LLMs (LoopLM) with shared-parameter recurrence, adaptive early-exit gating, and entropy-regularized training. These innovations enable dynamic latent reasoning without increasing parameter count, deliver strong reasoning performance with small models (1.4B–2.6B), provide long-context capability, and improve safety/faithfulness compared to explicit chain-of-thought. Below are actionable applications grouped by deployment timeline.
Immediate Applications
The following applications are deployable now with the released Ouro models and standard ML tooling. They leverage parameter efficiency, adaptive computation (q-exit), and long-context capabilities to reduce inference cost and latency while maintaining quality.
- Cost- and energy-efficient LLM inference for industry (Software, Cloud, Energy)
- Use case: Reduce GPU memory/compute per request by running Ouro-1.4B/2.6B instead of 4B–8B baselines, and apply q-exit early stopping to dynamically allocate recurrent steps per input difficulty.
- Workflow/Product: Inference server with a “compute budget” knob (q threshold) per tenant/tier; A/B test gates to optimize quality–latency; autoscaler integrates per-request loop count into SLAs.
- Assumptions/Dependencies: Gate threshold q requires task-specific tuning; inference stack must support recurrent loops and step-level metrics; quantization for edge deployment may be needed.
- On-device and edge assistants (Software, Mobile/IoT)
- Use case: Privacy-preserving offline assistants for note-taking, summarization, email replies, IDE copilots, and keyboard suggestions on laptops/phones/AR devices.
- Workflow/Product: SDKs exposing adaptive loops; local models with early exit for simple queries to keep latency low; VS Code plugin using Ouro for code completion/explanations.
- Assumptions/Dependencies: Model fits within device memory (quantized 1.4B preferred); tokenizer is optimized for English/code (limited Chinese/math symbol coverage).
- Real-time customer support and call center automation (Software, CX)
- Use case: Maintain response SLAs by allocating more loops only to complex tickets; reduce cost for simple FAQs with early exit.
- Workflow/Product: Contact-center NLU orchestrator using dynamic loop depth; queue-aware routing that raises q for escalations.
- Assumptions/Dependencies: Calibrated gate behavior under domain SFT; monitoring for over/under-thinking; guardrails for harmful content.
- Enterprise document analysis and search (Software, Productivity)
- Use case: Summarize and extract insights from long internal documents (policies, contracts, research) using the 32–64K context training stages to minimize chunking.
- Workflow/Product: RAG pipelines with long-context summarization and adaptive loops; workplace assistant that prioritizes compute for complex sections.
- Assumptions/Dependencies: Domain adaptation improves reliability; careful prompt design; long-context memory footprint planning.
- Compliance-friendly reasoning without CoT exposure (Healthcare, Finance, Policy)
- Use case: Perform reasoning internally without emitting chain-of-thought, aligning with “no CoT disclosure” policies while preserving performance.
- Workflow/Product: Policy-compliant chat systems that suppress CoT tokens yet retain latent loops; auditable settings for loop depth on sensitive tasks.
- Assumptions/Dependencies: Domain SFT and thorough safety evaluations; legal review and content filters; tokenizer limits for non-English/math-heavy use cases.
- Safety operations and risk reduction (Software Safety, Trust & Safety)
- Use case: Reduce harmfulness by tuning loop counts; set upper bounds on loops for certain categories; observe per-step loss improvements to detect overthinking.
- Workflow/Product: Safety middleware with per-step gating; dashboards tracking harmfulness versus recurrent steps; fallback to shallow inference for flagged intents.
- Assumptions/Dependencies: Integration with classifiers; dataset-specific calibration; reliance on observed HEx-PHI safety trends generalizing to target domains.
- Academic research on reasoning and scaling (Academia)
- Use case: Study “recursion as a third scaling axis” using open-source Ouro; replicate synthetic tasks showing improved knowledge manipulation (not storage).
- Workflow/Product: Benchmarks that vary loop count; visualizations of per-step improvements It; reproducible pipelines for gate training (Stage II).
- Assumptions/Dependencies: Access to training logs/hidden states for deeper analysis; compute for SFT; standardized evaluation suites.
Long-Term Applications
These applications require further research, scaling, tooling, or domain validation. They build on the paper’s methods (entropy-regularized gating, uniform prior, long-context training) and extend LoopLM into new sectors and products.
- Multilingual and math-heavy expansion (Education, Global Software)
- Use case: High-quality multilingual and advanced math reasoning by re-tokenizing (e.g., Chinese, symbolic math) and continued pretraining/SFT.
- Tools/Workflows: New tokenizer design; multi-trillion-token multilingual/maths corpora; uniform-prior gate training at scale.
- Assumptions/Dependencies: Significant training budgets; careful data curation; evaluation across languages and math benchmarks.
- Token-level adaptive computation and routing (Software, Robotics)
- Use case: Fine-grained per-token exit gating and Mixture-of-Recursions to route compute precisely where needed in long sequences or control loops.
- Tools/Workflows: Token-level gate training; adapter-based relaxed recursive transformers; latency-critical deployments (robot manipulation, autonomous navigation).
- Assumptions/Dependencies: Training stability at finer granularity; framework support for token-level halting; real-time hardware constraints.
- Safety-critical decision auditing with latent traces (Healthcare, Finance, Public Sector)
- Use case: Record and interpret hidden-state trajectories to audit model decisions without exposing CoT text; enable post hoc quality assessment and compliance reviews.
- Tools/Workflows: Step-by-step latent trace logging; interpretability methods for hidden states; dashboards that plot It convergence and exit decisions.
- Assumptions/Dependencies: Methods to make latent updates interpretable; privacy-preserving trace storage; regulatory acceptance.
- Dynamic billing and compute marketplaces (Cloud, FinOps)
- Use case: Price inference by “compute consumed” (loop depth) rather than tokens alone; align SLAs with per-request dynamic computation.
- Tools/Workflows: APIs exposing loop counts; metering and billing tied to q-exit; tenant-level policies (e.g., max loops).
- Assumptions/Dependencies: Standardization of compute metrics; customer education; transparent reporting.
- Co-design with edge silicon for recurrent reuse (Semiconductors, Energy)
- Use case: Hardware blocks optimized for shared weights and latent iteration to minimize memory bandwidth and energy.
- Tools/Workflows: SRAM-centric designs for state reuse; on-chip gate modules; firmware supporting halting criteria.
- Assumptions/Dependencies: Chip design cycles; ecosystem support; alignment of ML frameworks with hardware primitives.
- Clinical and financial decision support after validation (Healthcare, Finance)
- Use case: Deploy LoopLM in structured decision pipelines (triage, underwriting, compliance scanning) where adaptive compute and faithfulness are critical.
- Tools/Workflows: Domain SFT with uniform-prior gating; human-in-the-loop oversight; safety thresholds on loops.
- Assumptions/Dependencies: Extensive domain-specific evaluation; adherence to HIPAA/GDPR/SOX; real-world trials and monitoring.
- Standard-setting and policy guidance on latent reasoning (Policy, Governance)
- Use case: Incorporate adaptive latent reasoning standards in public procurement and AI governance (e.g., “no CoT disclosure” while maintaining capability).
- Tools/Workflows: Benchmarks for faithfulness of latent traces; guidelines for compute budgets and halting; transparency on gating policies.
- Assumptions/Dependencies: Collaboration with standards bodies; reproducibility of safety benefits; stakeholder education.
- Developer observability and calibration tools (Software Tooling)
- Use case: Visualize and tune early-exit gates, track under/over-thinking, and optimize q for tasks and user tiers.
- Tools/Workflows: IDE/debugging plugins for loop introspection; APM dashboards for It and gate distributions; auto-calibration pipelines.
- Assumptions/Dependencies: Exposing and stabilizing step-level signals; integration with popular inference runtimes.
- Green AI benchmarking (Energy, Sustainability)
- Use case: Quantify energy savings from parameter efficiency and adaptive computation; certify “green” deployments.
- Tools/Workflows: Standardized energy metrics per loop; reporting integrated into inference servers; optimization against carbon budgets.
- Assumptions/Dependencies: Reliable energy measurements; adoption by cloud providers; external auditing.
In summary, LoopLM enables immediate cost-effective, policy-friendly reasoning across software and enterprise workflows, with a clear path to long-term innovations in multilingual reasoning, token-level adaptive computation, safety auditing, and hardware co-design. Deployment feasibility hinges on careful gate calibration, domain adaptation, tokenizer coverage, and observability of loop dynamics.
Glossary
- Adaptive computation: Dynamically allocating compute based on input difficulty to use more steps for hard inputs and fewer for easy ones. "LoopLM allows adaptive computation via a learned early exit mechanism"
- ALBERT: A transformer variant that reduces parameters via cross-layer weight sharing and embedding factorization. "The most prominent example in the modern transformer era is ALBERT~\cite{lan2019albert}, which combines parameter re-use with embedding factorization to drastically reduce the total parameter count."
- Chain-of-Thought (CoT): An inference-time technique where models generate intermediate textual reasoning steps to improve problem solving. "The second leverages inference-time compute through Chain-of-Thought (CoT) reasoning"
- ChatML: A structured message format for conversational training data used to standardize prompts and responses. "All samples are converted into ChatML format to reduce alignment tax in the subsequent post-training stage."
- Continual Training (CT) Annealing: A training phase with annealed learning rates and higher-quality data to refine capabilities. "Stage 2: Continual Training (CT) Annealing"
- Cumulative Distribution Function (CDF): The cumulative probability of exiting by a given recurrent step, used to trigger early termination. "we adopt a deterministic Q-exit criterion based on the cumulative distribution function (CDF), described in \Cref{alg:qexit}."
- Decontamination: Removing samples overlapping with evaluation benchmarks to avoid leakage and inflated scores. "while conducting thorough decontamination to minimize potential overlaps with mainstream evaluation benchmarks."
- Early exit gate: A learned gating function that decides whether to halt or continue the next recurrent step. "The early exit gate at loop step is defined by"
- Evidence Lower Bound (ELBO): A variational objective that trades off data fit and divergence from a prior for latent variable models. "we can derive an Evidence Lower Bound (ELBO) objective:"
- Entropy regularization: An objective term encouraging a broader (higher-entropy) distribution over exit steps to promote exploration. "our training objective combines the next-token prediction loss with an entropy regularization term over :"
- Gating mechanism: A learned controller that modulates whether to continue recurrent computation or stop. "This is achieved by the gating mechanism we shall describe below."
- Geometric prior: A prior distribution favoring earlier halts in adaptive computation, often used to bias shallow computation. "PonderNet and other adaptive computation methods typically employ geometric priors:"
- KL divergence: A measure of divergence between the learned exit distribution and a prior, used in the ELBO. "the KL divergence simplifies to:"
- Latent chain of thought: The sequence of hidden state refinements across recurrent steps that implicitly performs reasoning. "the hidden states form a latent chain of thought that progressively refines the representation to solve a task."
- Latent reasoning: Performing iterative reasoning in hidden-state space rather than via explicit text generation. "Here, the LoopLM's iteration is viewed as latent reasoning where each step is a non-verbal 'thought' that refines the model's internal representation."
- LoRA adapters: Low-rank adaptation modules injected to modify behavior across recursive steps without full retraining. "Relaxed Recursive Transformers with a common base block while injecting unique LoRA adapters across recursive steps"
- Long Context Training (LongCT): A stage designed to extend the model’s effective context window using long-sequence data. "The LongCT stage extends the long-context capabilities of the model."
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert modules to increase capacity efficiently. "Megrez2~\cite{li2025megrez2} reuses experts across layers in a standard Mixture-of-Experts (MoE) model"
- Mixture-of-Recursions: An approach combining recursive parameter efficiency with adaptive routing across multiple recursive paths. "More advanced variants, such as Mixture-of-Recursions~\cite{bae2025mixture} combine recursive parameter efficiency with adaptive, token-level routing."
- Multi-Head Attention (MHA): An attention mechanism that uses multiple parallel heads to capture diverse relationships. "Each block uses Multi-Head Attention (MHA) with Rotary Position Embeddings (RoPE) to handle sequence order."
- PonderNet: A method for adaptive halting that optimizes an ELBO with a halting prior to learn when to stop computation. "our approach aligns with adaptive computation methods like PonderNet~\cite{banino2021pondernet}, which also optimize an ELBO objective for dynamic halting."
- Poisson-lognormal prior: A halting prior that biases toward shallow computation by placing more mass on early steps. "Similarly, methods like Recurrent Depth~\cite{geiping2025scaling} use Poisson-lognormal priors that also favor shallow computation."
- Q-exit criterion: A deterministic halting rule that exits when the CDF over exit probabilities exceeds a threshold q. "we adopt a deterministic Q-exit criterion based on the cumulative distribution function (CDF)"
- Recurrent depth: The number of iterative applications of shared layers that deepens computation without increasing parameters. "recurrent-depth structures used to improve the efficiency and reasoning capabilities of modern LLMs."
- RMSNorm: A normalization layer using root-mean-square statistics for stability, placed before sublayers. "we employ a sandwich normalization structure. This places an RMSNorm layer before both the attention and FFN sub-layers"
- Rotary Position Embeddings (RoPE): A positional encoding technique that rotates query/key vectors to encode relative positions. "Each block uses Multi-Head Attention (MHA) with Rotary Position Embeddings (RoPE) to handle sequence order."
- Sandwich normalization: A pattern of placing normalization layers before multiple submodules to stabilize training. "we employ a sandwich normalization structure."
- Supervised Fine-Tuning (SFT): Post-pretraining optimization on labeled tasks to sharpen capabilities and align behavior. "Finally, these base models are further refined through a specialized Reasoning SFT (Supervised Fine-Tuning) stage"
- SwiGLU: A gated linear unit variant used in FFNs that improves efficiency and performance. "The feed-forward network (FFN) in each block utilizes a SwiGLU activation"
- Universal Transformer: A transformer that reuses a single block recurrently across depth instead of distinct layers. "originating with the seminal Universal Transformer~\cite{dehghani2018universal}"
- Upcycling: Expanding model capacity mid-training by structurally increasing layers or parameters while reusing learned weights. "we adopt an upcycling strategy that enables efficient scaling of model capacity during training."
- Variational inference: A framework for approximating latent-variable posteriors by optimizing a tractable objective like the ELBO. "The entropy-regularized objective can be equivalently viewed through the lens of variational inference."
- Warmup-Stable-Decay (WSD): A learning-rate schedule that warms up, stays constant, then decays during pretraining. "align with the Warmup-Stable-Decay (WSD)~\cite{wen2024understanding} learning rate scheduler"
- Weight tying: Reusing the same parameters across multiple layers/steps to reduce model size and enforce consistency. "behaves like a deep Transformer where the weights of all layers are tied."
Collections
Sign up for free to add this paper to one or more collections.