Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence (2511.07384v1)
Abstract: Recent advances in depth-recurrent LLMs show that recurrence can decouple train-time compute and parameter count from test-time compute. In this work, we study how to convert existing pretrained non-recurrent LLMs into depth-recurrent models. We find that using a curriculum of recurrences to increase the effective depth of the model over the course of training preserves performance while reducing total computational cost. In our experiments, on mathematics, we observe that converting pretrained models to recurrent ones results in better performance at a given compute budget than simply post-training the original non-recurrent LLM.
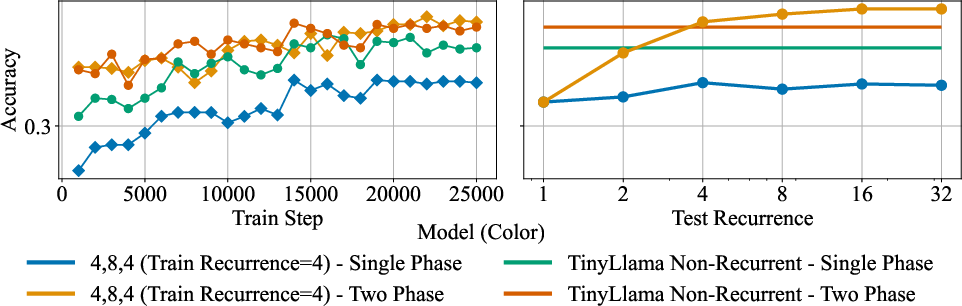
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Teaching Pretrained LLMs to Think Deeper with Retrofitted Recurrence — Explained Simply
Overview: What is this paper about?
This paper shows a way to help existing LLMs “think” more deeply without making them bigger. Instead of adding new layers, the authors teach models to reuse some of their layers multiple times during a single question. This repeated thinking is called recurrence. The idea is like giving the model extra time to reason at test time, so it can solve harder problems—especially math—without needing tons of extra training or more parameters.
The main questions the paper asks
- Can we take a model that’s already trained (like TinyLlama, OLMo, or Llama) and convert it into a “recurrent” model that can think in multiple steps?
- Can this be done efficiently, so training doesn’t get too slow or expensive?
- Does this deeper thinking actually help on reasoning tasks (like math problems) more than just continuing to train the original model?
- If we change the model’s structure, how do we keep it good at general language understanding (not just math)?
How they do it: The approach, with simple analogies
Think of a LLM like a student solving a problem:
- The prelude is the “reading the question” part.
- The recurrent block is the “thinking loop” where the student re-checks and improves their reasoning several times.
- The coda is the “write the final answer” part.
The authors take a pretrained model and perform “model surgery” to organize its layers into these three parts:
- Prelude: early layers that prepare the information.
- Recurrent block: a small group of layers that get reused (looped) several times.
- Coda: final layers that produce the output (like the answer tokens).
Key ideas, explained:
- Recurrence: Instead of making the model deeper (adding more layers), they loop the same “thinking layers” multiple times. It’s like taking extra passes to think more carefully, without changing the model’s size.
- Test-time compute: This is how much “thinking” the model is allowed to do when answering a question. You can increase test-time compute by allowing more recurrences (more loops), without retraining the model or adding parameters.
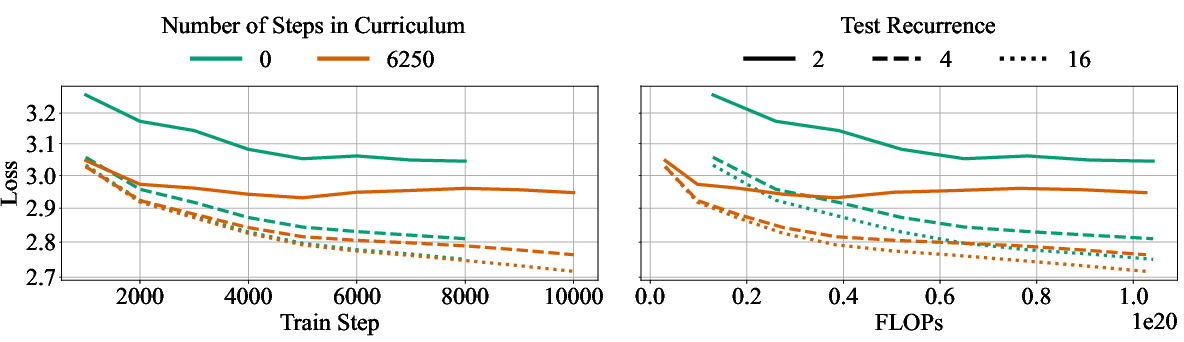
- Scheduling recurrence during training: They don’t start with lots of loops from day one. They follow a curriculum—begin with fewer loops, then gradually increase. This keeps training stable and faster.
- Truncated backpropagation: When training, they only update the model through the last few loops (e.g., the last 8). This saves memory and speeds up training while still teaching the model to benefit from multiple thinking passes.
- Healing period: After changing the model’s structure, they give it a “recovery” phase on general web data before training on math-heavy data. This helps it keep strong basic language skills.
- FLOPs: This stands for “floating point operations,” basically the number of tiny math steps a computer does. Think of FLOPs as your budget of “how much thinking power” you spend on training or testing.
What they found and why it matters
Here are the main results, summarized:
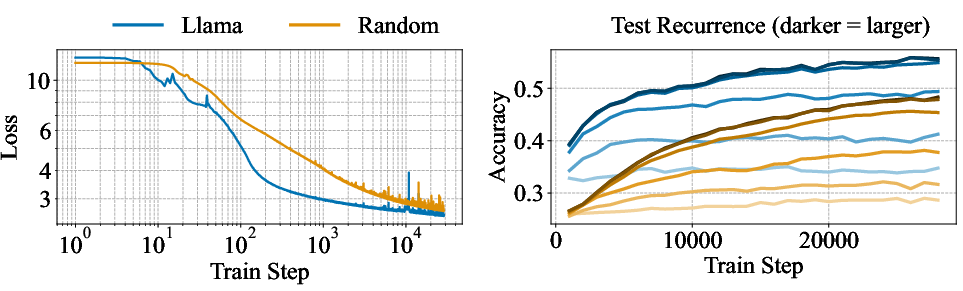
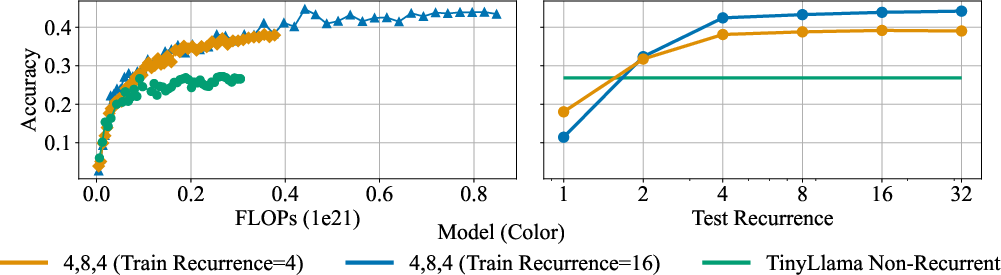
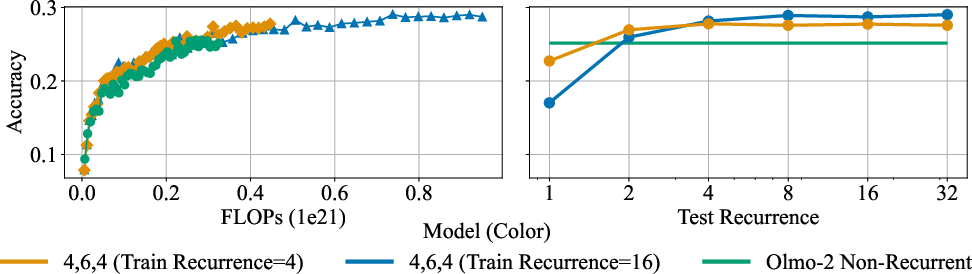
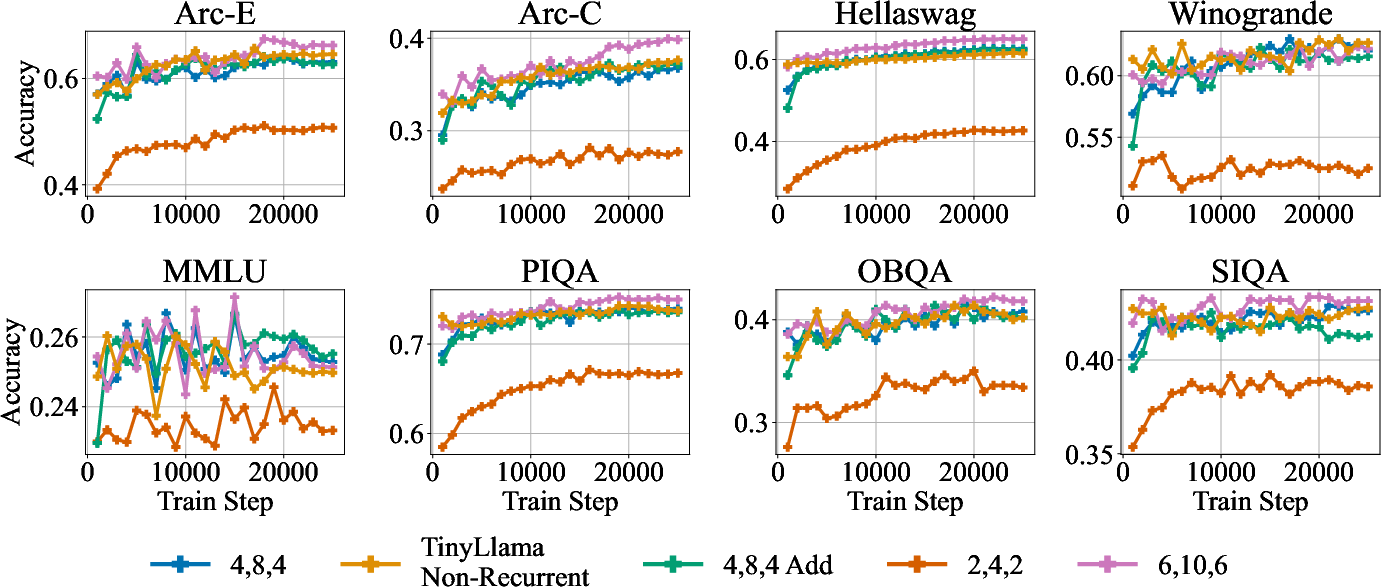
- Starting from a pretrained model is much better than starting from random: When they “retrofit” recurrence into an existing model (instead of training from scratch), the model learns faster and gets better results with less training.
- Scheduling the number of thinking loops helps: Gradually increasing how many loops the model uses during training improves performance while reducing training cost.
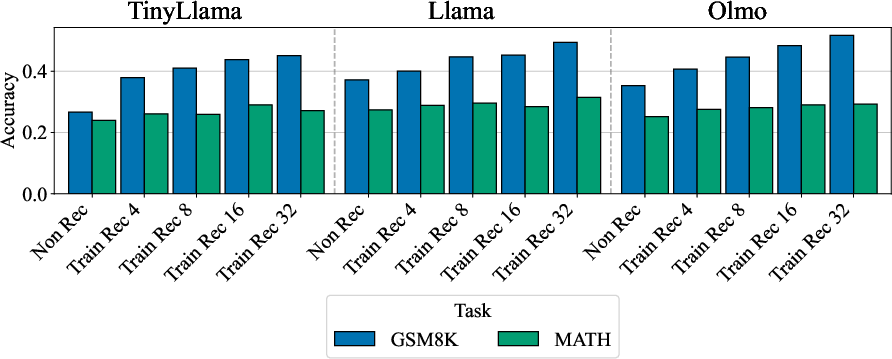
- Better reasoning at the same compute budget: On math tasks like GSM8K and MATH, retrofitted recurrent models beat simply continuing to train the original (non-recurrent) models when using the same training compute (FLOPs). In other words, deeper test-time thinking gives more bang for your buck.
- Fewer parameters, stronger reasoning: The recurrent models often have fewer unique parameters than the original models (because they reuse layers), yet they achieve higher accuracy by thinking more at test time.
- Keep general language skills with a data curriculum: A simple two-phase training plan (first heal on general web text, then add high-quality math and instruction data) helps the recurrent models stay good at general language tasks while getting better at math.
Why this is important
- It decouples model size from thinking ability: You don’t have to build a bigger model to think more deeply. You can reuse what’s already there.
- It saves costs: You can get better reasoning by spending more compute at test time (when you need it), instead of doing massive extra pretraining.
- It’s flexible: You can dial up the number of loops for harder questions and keep them low for easy ones, which could lead to smarter, more efficient systems that adapt to the task.
- It works across different models: The approach was tested on several 1B-parameter models (TinyLlama, OLMo, and Llama) and showed consistent gains, especially in math.
Final thoughts: What could come next
- Automatic “stop when ready”: Future models might learn when to stop looping on their own—thinking longer on hard questions and shorter on easy ones.
- Smarter layer selection: Choosing exactly which layers to reuse and which to keep could further boost performance.
- Bigger scales and new domains: Testing this method on larger models and tasks beyond math (like science or logic) could reveal even more benefits.
- Practical upgrade path: Since many strong models already exist, retrofitting recurrence offers a practical way to upgrade them to deeper thinkers without rebuilding from scratch.
Overall, this paper points to a future where LLMs can think more with the same brain—by looping their thoughts—rather than always needing a bigger brain.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and can guide future research.
- Scale and generalization: The method is only demonstrated at ~1B-parameter scale and ≤50B-token continued pretraining; it is unknown whether the efficiency and gains persist at larger model sizes (e.g., 7B–70B+) and longer training horizons.
- Task breadth: Evaluations focus primarily on math reasoning (GSM8K, MATH) plus a small set of general LM benchmarks; transfer to other reasoning-heavy domains (code, scientific QA, planning, formal proofs, multi-hop retrieval, multimodal reasoning) remains untested.
- Long-context behavior: All training used 1k-token context; the impact of retrofitted recurrence on long-context modeling, memory utilization, and degradation or gains at 8k–128k contexts is unknown.
- Compute tradeoffs vs token-based test-time scaling: The paper does not directly compare recurrent test-time scaling against standard token-based approaches (e.g., self-consistency, CoT sampling, reranking) at matched FLOPs; the relative cost–benefit is unclear.
- Inference efficiency and latency: Real-world inference metrics (throughput, latency, memory, KV-cache behavior) under varying recurrence counts and batch sizes are not reported; deployment practicality is unknown.
- Adaptive halting/exiting: Models use fixed recurrence at inference; whether retrofitted models can be endowed with reliable, learned halting criteria (global or token-level) that allocate compute adaptively is open.
- Extrapolation in recurrence: The ability to generalize to recurrence depths beyond those seen in training (e.g., >32) is not tested; limits and failure modes of “thinking deeper” remain unknown.
- Truncated BPTT design: Only the last 8 recurrences receive gradients; how truncation length affects stability, generalization, and test-time extrapolation is not studied.
- Recurrence distribution choice: The Poisson–Lognormal depth distribution is adopted without ablation; optimal distributions, deterministic schedules, or curriculum shapes for different tasks/models remain unexplored.
- Scheduling strategy: Linear and 1/√t schedules are briefly tested; principled methods to learn or adaptively tune depth curricula for best compute–performance tradeoffs are not developed.
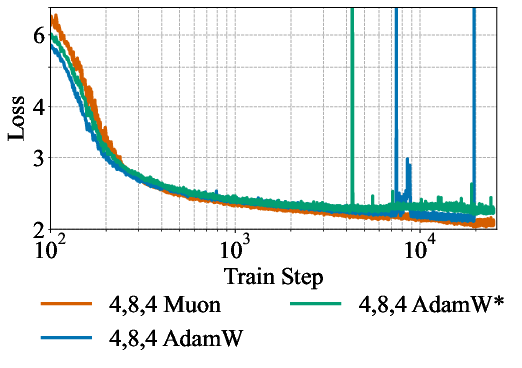
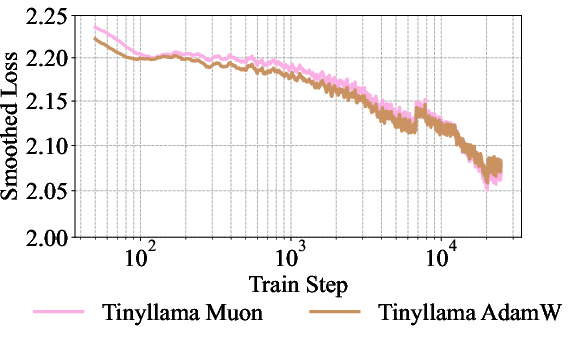
- Optimizer generality: Muon outperforms AdamW in the presented settings, but broader hyperparameter sweeps, stability analyses, and scaling behavior across architectures/sizes are missing.
- Architecture-specific robustness: Results span TinyLlama, OLMo, and Llama-3.2-1B, which differ in norms and vocabularies; a systematic paper of how normalization schemes (pre-/post-norm, QK-norm), attention variants, and weight tying interact with recurrence is absent.
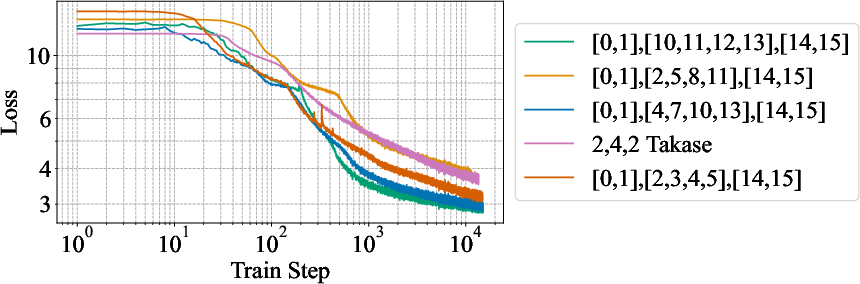
- Layer surgery methodology: The layer-selection heuristic (keep early layers for prelude and later for recurrent/coda) is not principled; a data-driven or theoretically justified method to choose which layers to keep/drop is needed, including across deeper models and diverse architectures.
- Magnitude of pruning: Only 2–6 layers are removed; the tolerance of different models to more aggressive removal, and the tradeoff between unique parameters and recurrent efficiency, remain unquantified.
- Input injection design: The specific concatenation + linear adapter (2h→h) is a single choice; alternatives (gated mixing, attention between e and s, deeper adapters, residual mixers, FiLM) could change stability and performance but were not explored.
- Initial state choice: The recurrent state starts from Gaussian noise; whether learned initial states, zeros, or functions of the prelude improve stability/sample efficiency is unknown.
- Healing curriculum: The “healing” phase (26B tokens of web text) is heuristic; optimal healing duration, data selection, and automatic criteria to detect recovery of base LM capabilities are open questions.
- Data mixture design: The mixed FineWeb–Nemotron SFT recipe improves non-reasoning metrics; systematic exploration of data mixtures (ratios, quality filters, deduplication, multi-domain balance) and their effect on both reasoning and general LM is missing.
- Contamination checks: The paper does not report data contamination audits for GSM8K/MATH; rigorous deduplication and leakage analysis are needed to ensure fair evaluation.
- Decoding and evaluation protocols: Only one in-context example and specific answer extraction criteria are used; sensitivity to decoding strategies (temperature, self-consistency, reranking) and robustness across standard evaluation settings is untested.
- Error analysis: There is no qualitative analysis of failure modes (e.g., arithmetic slips vs. planning errors) or how errors evolve with increased recurrence; this limits targeted improvements.
- Stability across long runs: Training instabilities (e.g., AdamW loss spikes) are noted; comprehensive analysis of stability as recurrence increases, under different clipping/normalization strategies, is missing.
- Theoretical grounding: There is no formal analysis of why pretrained layers are “loopable,” how residual stream alignment supports recurrence, or under what conditions recurrence preserves/extends functionality.
- Token-level adaptivity: Per-token or per-head adaptive recurrence (mixture-of-depths/recursions) is not integrated; whether retrofitted models can learn token-wise compute allocation remains open.
- MoE and sparse architectures: The approach is only evaluated on dense decoders; retrofitting recurrence for MoE or hybrid sparse models (routing across iterations) is unexplored.
- Combined scaling methods: The interplay between latent recurrence and external methods (retrieval augmentation, tool use, program-of-thought, verifier-guided decoding) is not examined.
- Perplexity and LM quality: While validation loss and some benchmarks are reported, standardized perplexity on held-out corpora and detailed LM capability tracking post-surgery are limited.
- Safety, bias, and calibration: Effects of recurrence and layer surgery on factuality, calibration, bias, and safety behaviors are not assessed.
- Hardware–software co-design: Kernel-level or framework-level optimizations for recurrent passes (e.g., KV reuse across iterations, memory locality) and their impact on speed/energy are not investigated.
- Fairness vs deeper non-recurrent baselines: Comparisons are made to same-parameter baselines; comparisons to simply training a deeper non-recurrent model at matched FLOPs, or to parameter-efficient methods (LoRA, distillation) under equal cost, are missing.
- Negative or mixed findings: Some trends (e.g., TinyLlama’s weaker gains at larger training recurrences) are noted but not explained; understanding when recurrence underperforms and why is an open problem.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that leverage the paper’s findings on retrofitting pretrained LMs with depth recurrence, recurrence curricula, and data healing strategies.
- Sector: Software/AI Engineering — “Think-deeper” inference knob for existing LLM products
- Use case: Add a runtime parameter r that increases internal recurrences (compute) without changing memory footprint or context length; expose this as a “deep reasoning mode” for tough queries.
- Tools/workflows: Integrate the paper’s GitHub code and HuggingFace checkpoints; extend inference servers (e.g., vLLM, TGI) to support recurrent loops and adjustable r per request.
- Assumptions/dependencies: Access to model weights and inference stack; acceptable latency for higher r; serving stack supports custom forward passes with the prelude/recurrent/coda loop.
- Sector: Education — Lightweight math tutors and paper aids on edge devices
- Use case: Deploy 1B-class retrofitted models on laptops/tablets with a “slow-but-smart” mode for harder math problems (GSM8K/MATH-like tasks).
- Tools/workflows: Use TinyLlama/OLMo/Llama-3.2-1B recurrent variants; couple with problem-difficulty heuristics (e.g., wrong-first-try → increase r).
- Assumptions/dependencies: Performance reported at ~1B scale; domain transfer beyond math requires additional fine-tuning.
- Sector: Finance/Enterprise Analytics — Small, on-prem reasoning assistants
- Use case: Reasoning on spreadsheets, risk summaries, and KPI diagnostics with variable test-time compute while keeping parameter counts small for governance and cost.
- Tools/workflows: Serve a recurrent 1B-class LM behind a corporate gateway; expose per-query compute budgets (r) via policy; default to low r, escalate for critical analyses.
- Assumptions/dependencies: Higher r increases latency; domain-specific data may require a two‑phase fine-tune (healing on domain text, then high-quality task data).
- Sector: Robotics/Embedded/Edge — Compute-flexible local planners
- Use case: Run low-parameter, memory-light models on hardware-constrained systems; increase recurrence only when tasks require deeper planning/reasoning.
- Tools/workflows: Retrofit small LMs used in planning/prompting pipelines; tie r to available time/energy budget or uncertainty estimates.
- Assumptions/dependencies: Integration with control stack; task distribution may differ from math; safety validation required.
- Sector: MLOps — Training pipeline upgrade: retrofitting + healing + recurrence scheduling
- Use case: Convert fixed-depth checkpoints into recurrent models; minimize compute with linear or 1/sqrt scheduling of recurrences; apply a “healing” phase to restore LM ability after model surgery.
- Tools/workflows:
- Model surgery: select early layers for prelude and later layers for recurrent block/coda; insert linear adapter that consumes [e, s_i] → h.
- Training: truncated backprop through last 8 iterations; schedule mean of a Poisson–Lognormal for recurrences; adopt Muon optimizer for stability.
- Compute tracking: use FLOPs formula FLOPs = (6N1 + 2N2)D with N1 (grad) and N2 (no-grad) effective parameters.
- Assumptions/dependencies: Hyperparameter tuning for layer selection and schedules; data availability for healing phase (e.g., FineWeb‑Edu) and high-quality task data (e.g., Nemotron SFT).
- Sector: Open Source/Research — Reproducible baselines for latent-reasoning models
- Use case: Academic labs benchmark test-time compute scaling without bespoke chain-of-thought traces; evaluate curricula and optimizers (Muon vs AdamW) on public datasets.
- Tools/workflows: Use provided code/models; run ablations on scheduling, layer selection, and data mixtures; report compute with the paper’s FLOPs accounting.
- Assumptions/dependencies: Compute budget for continued pretraining; community standards for reporting both parameter count and test-time compute.
- Sector: Cloud Platforms/SaaS — Cost-tiered “compute-on-demand” LLM plans
- Use case: Offer user-selectable depth settings (r) mapped to latency/price tiers; upsell “deep reasoning” for complex tickets, coding tasks, or analytics requests.
- Tools/workflows: Add a per-request r parameter and observability for per-call FLOPs; implement simple heuristics to cap r for easy tasks.
- Assumptions/dependencies: Billing linked to compute; clear SLAs for added latency; guardrails when r is too small/large for task difficulty.
- Sector: Policy/Measurement — Transparent compute accounting in model cards
- Use case: Report test-time compute ranges and training FLOPs using the paper’s formulas to complement parameter counts in transparency documentation.
- Tools/workflows: Extend model cards with: parameter count (unique), typical r, min/max r, FLOPs per query as r varies, and training schedule details.
- Assumptions/dependencies: Organizational mandate to standardize reporting; stakeholder understanding of compute vs parameter decoupling.
- Sector: Energy/IT Ops — Elastic inference aligned with grid conditions
- Use case: Dynamically reduce r during peak energy cost periods and increase r when cheap/renewable energy is available, without redeploying the model.
- Tools/workflows: Tie recurrence controller to demand-response signals; expose r as a tunable per-batch parameter in inference orchestration.
- Assumptions/dependencies: Monitoring of grid/energy signals; acceptable quality/latency variance for end users.
- Sector: Data Engineering — Safer fine-tuning on “high-quality” datasets
- Use case: Apply the two-phase curriculum (healing → high-quality SFT/math mix) to avoid catastrophic degradation in non-reasoning tasks after architecture changes.
- Tools/workflows: Data curation pipeline that strips RL-generated “reasoning” traces and assistant tags (as done for Nemotron-Pretraining-SFT-v1) to limit distribution shifts.
- Assumptions/dependencies: Availability of domain-appropriate healing corpus; consistent preprocessing.
Long-Term Applications
These applications are plausible extensions that likely require further research, scaling, or productization.
- Sector: Software/AI Engineering — Automatic, adaptive recurrence with learned exit criteria
- Use case: Per-query or per-token controllers that allocate just enough depth (r) based on uncertainty or self-verification signals, achieving “anytime inference.”
- Tools/products: Learned halting policies integrated into the recurrent block; calibration to trade off accuracy, latency, and cost automatically.
- Assumptions/dependencies: Reliable confidence/verification signals; robust training to avoid over- or under-computation; further validation across domains.
- Sector: Healthcare/Legal/Scientific R&D — Latent reasoning for regulated, on-prem assistants
- Use case: Replace large, CoT-heavy models with smaller recurrent models that “think in latent space” for structured reasoning, preserving privacy and lowering infrastructure cost.
- Tools/products: Domain-specialized retrofits (e.g., biomedical corpora → healing → high-quality clinical/scientific SFT); compliance-aligned model cards with compute ranges.
- Assumptions/dependencies: Extensive domain tuning, auditing, and safety testing; larger-scale validation beyond math; clear governance for adjustable compute.
- Sector: Programming/DevTools — Recurrent reasoning for code synthesis and verification
- Use case: IDE copilots that allocate deeper internal reasoning for tricky synthesis or debugging while staying lightweight on-device or on small servers.
- Tools/products: Retrofitted code LMs with adaptive r; integration with test/verify loops and static analyzers; “deep reasoning on failure” workflows.
- Assumptions/dependencies: Evidence of transfer from math to code reasoning; careful prompting/evaluation; compute-latency tradeoff acceptable to developers.
- Sector: Robotics/Autonomy — Anytime planners with recurrence-aware scheduling
- Use case: Robots and autonomous systems that adjust their compute per situation (e.g., high r in complex environments, low r during routine operation).
- Tools/products: Joint planners with uncertainty-aware controllers that modulate depth; co-design with real-time constraints and safety certification.
- Assumptions/dependencies: Real-time guarantees; predictable latency under high r; safety verification and fallback strategies.
- Sector: Cloud/Hardware Co-design — Accelerators optimized for recurrent depth reuse
- Use case: ASICs/compilers tuned for weight reuse across iterations with minimal memory overhead, maximizing throughput for depth-recurrent LMs.
- Tools/products: Kernel/graph optimizations for looping blocks; memory scheduling to exploit fixed-parameter reuse; batching strategies for heterogeneous r.
- Assumptions/dependencies: Sufficient market demand; standardized recurrent abstractions in ML frameworks.
- Sector: Policy/Standards — Compute budgeting and disclosure norms
- Use case: Regulatory frameworks that require reporting both parameter counts and test-time compute envelopes; procurement standards for “compute elasticity.”
- Tools/products: Benchmarks and scorecards that normalize performance by compute and allow variable-depth settings; environmental impact disclosure per r-profile.
- Assumptions/dependencies: Multi-stakeholder agreement on metrics; tooling for reliable compute measurement in production.
- Sector: Green AI/Operations — Carbon-aware depth scheduling
- Use case: Match inference depth to carbon intensity forecasts (e.g., deeper reasoning when renewables are abundant) to minimize emissions without retraining.
- Tools/products: Orchestrators that co-optimize accuracy, latency, and carbon cost via r; dashboards with compute and emissions telemetry.
- Assumptions/dependencies: Accurate carbon-intensity data; user tolerance for variable latency/quality; governance to prevent quality regressions.
- Sector: Safety/Transparency — Latent reasoning with selective externalization
- Use case: Systems that default to latent reasoning (privacy, bandwidth) and only externalize reasoning traces when needed for audit or user trust.
- Tools/products: “Explain on demand” modules that translate latent states to human-readable rationales post hoc; paired with proof/verification (e.g., Math-Verify-like tools).
- Assumptions/dependencies: Research on faithful rationale extraction from latent computation; user studies and policy alignment.
- Sector: Data-centric AI — Generalized “healing” after model surgery
- Use case: Standardize healing curricula for other architectural changes (pruning, MoE conversion, distillation) to preserve general LM ability before task specialization.
- Tools/products: Playbooks that prescribe data mixes and schedules to minimize distribution shift after surgery; automated validators that monitor non-reasoning regressions.
- Assumptions/dependencies: Transferability across architectures and scales; accessible, high-quality healing corpora.
- Sector: Benchmarking — Test-time-compute–aware leaderboards
- Use case: Leaderboards that report performance as a function of r (or accumulated FLOPs), enabling fair comparisons across models with different parameter counts and compute policies.
- Tools/products: Evaluation harnesses that sweep r and normalize by FLOPs; official “anytime” metrics for reasoning tasks (e.g., GSM8K, MATH, code, science QA).
- Assumptions/dependencies: Community adoption; standardized FLOPs accounting (including (6N1 + 2N2)D for training and per‑r inference FLOPs).
Cross-cutting assumptions and dependencies
- Scaling: Results are demonstrated at ~1B parameter scale and on math-centric datasets; generalization to larger models and broader domains requires validation.
- Serving compatibility: Production stacks must support recurrent loops, the prelude/recurrent/coda adapter, and per-request r selection.
- Latency budgets: Larger r increases inference time; user experience and SLAs must account for this.
- Data quality: Healing and high-quality SFT mixes are important to avoid non-reasoning regressions; data governance (e.g., stripping RL-generated reasoning traces) matters.
- Optimizer/stability: Muon provided better stability for recurrent training in the paper; if unavailable, stable AdamW variants and update clipping may be needed.
- Licensing: Retrofitting depends on access to suitable pretrained checkpoints under compatible licenses.
Glossary
- Adaptive-depth mechanisms: Techniques that allow a model to dynamically adjust the number of processing steps per input to improve computational efficiency. "Adaptive-depth mechanisms have been studied with the specific goal of increasing computation efficiency~\citep{graves2016adaptive,elbayad2019depth, schwarzschild2021can, bansal2022end}."
- Chain-of-thought traces: Explicit sequences of intermediate reasoning tokens generated to improve problem-solving during inference. "The mainstream paradigm for test-time scaling involves generating many tokens, either in chain-of-thought traces or by generating many candidate solutions and choosing the best \citep{snell2024scaling,guo2025deepseek}."
- Coda: The final block(s) of a model that map hidden states to output probabilities or logits. "We define as the prelude, as the recurrent block and as the coda; each of which is a set of unique transformer blocks with the embeddings included in and unembeddings in ."
- Context length: The maximum number of tokens a model processes in one sequence window. "We also use grouped-query attention \citep{ainslie2023gqa}, train all models with a context length of 1024, and do not weight-tie the embedding and unembedding layers."
- Depth-recurrence: Reusing the same block of layers multiple times to increase effective depth and compute without increasing parameters. "An emerging alternative paradigm for test-time scaling leverages depth-recurrence, by which a LLM can simply recur layers for more iterations to expend more compute."
- Distillation (logit-level): Training a model to match the output logits of one or more larger teacher models. "using logit level distillation from Llama-3.1-8B and Llama-3.1-70B for $9$ trillion tokens \citep{meta_llama_3_2_announcement}."
- Effective parameters: The conceptual parameter count that accounts for repeated use of shared weights across recurrences. "One can also consider the {\em effective parameters} of a recurrent model by including repetitions across recurrences."
- Embeddings/Unembeddings: Layers that convert tokens to vectors (embeddings) and vectors back to token logits (unembeddings). "We define as the prelude, as the recurrent block and as the coda; each of which is a set of unique transformer blocks with the embeddings included in and unembeddings in ."
- FLOPs (Floating Point Operations): A measure of computation used to quantify training or inference cost. "When calculating training FLOPs for standard fixed depth transformers, we use the approximation \citep{kaplan2020scaling}, where is non-embedding parameters and is number of training tokens."
- Grouped-query attention (GQA): An attention variant that groups queries to reduce compute while maintaining performance. "We also use grouped-query attention \citep{ainslie2023gqa}, train all models with a context length of 1024, and do not weight-tie the embedding and unembedding layers."
- Healing period: An initial training phase after architectural changes to recover general language modeling performance. "Since we remove layers when converting fixed depth models to recurrent ones, we find that introducing a ``healing'' period with minimal distribution shift helps recover basic language modeling performance before switching to task-specific data to further refine the depth-recurrent model's reasoning performance (\Cref{fig:tinyllama-data-mix} and \Cref{tab:data-mix})."
- Latent reasoning: Performing internal reasoning within hidden representations rather than through explicit token generation. "the first work to establish that latent reasoning as a scalable, alternate approach for pretraining transformer LLMs."
- Linear adapter: A learned linear layer that transforms concatenated features (e.g., prelude and recurrent states) into the model’s hidden width. "After each recurrence, we concatenate the output of the prelude with the output of the recurrent block (or random noise at time zero) and apply a linear adapter."
- Mixture of depths: Architectures that route tokens through varying numbers of transformer blocks to adapt computation per token. "\citet{raposo2024mixture} propose mixture of depths models which adaptively route tokens through or around each transformer block."
- Model surgery: Post-hoc architectural modifications to pretrained models (e.g., pruning, rearranging layers). "Model surgery.\ There is a rich literature on methods for making post-hoc changes to model architecture and size~\citep{chen2015net2net,wei2016network}."
- Muon optimizer: An optimization algorithm used in place of AdamW to stabilize and improve training of recurrent models. "In subsequent experiments, we optimize all models with Muon."
- Poisson-Lognormal distribution: A distribution used to sample the number of recurrences per step to enable adaptive-depth training. "To allow for adaptive recurrence at test time, \citet{geiping2025scaling} sample from a Poisson-Lognormal distribution with a mean of $32$ at each training step."
- Post-normalization: Applying normalization after transformer sublayers; contrasts with pre-normalization. "the OLMo models use QK-norm and a post-normalization scheme unlike the llama models which use a pre-normalization scheme and do not use a QK-norm."
- Pre-normalization: Applying normalization before transformer sublayers; contrasts with post-normalization. "the OLMo models use QK-norm and a post-normalization scheme unlike the llama models which use a pre-normalization scheme and do not use a QK-norm."
- Prelude: The initial block(s) that compute embeddings and initial states before recurrence. "We define as the prelude, as the recurrent block and as the coda; each of which is a set of unique transformer blocks with the embeddings included in and unembeddings in ."
- QK-norm: A normalization applied to query-key vectors in attention for stability and performance. "the OLMo models use QK-norm and a post-normalization scheme unlike the llama models which use a pre-normalization scheme and do not use a QK-norm."
- Recurrent block: The core block whose weights are reused across multiple iterations to deepen computation. "We define as the prelude, as the recurrent block and as the coda; each of which is a set of unique transformer blocks with the embeddings included in and unembeddings in ."
- Residual connections: Additive skip pathways that feed a block’s output back into the same stream for stable deep training. "Because transformer models include residual connections \citep{he2015deep} that write updates back into the same residual stream, transformer layers operate in a shared representation space \citep{elhage2021mathematical}."
- Residual stream: The shared hidden representation updated by residual connections across layers. "Because transformer models include residual connections \citep{he2015deep} that write updates back into the same residual stream, transformer layers operate in a shared representation space \citep{elhage2021mathematical}."
- Scalable initialization: An initialization scheme designed to remain stable under changes to model shape or recurrence. "\citet{geiping2025scaling} use a ``scalable initialization'' \citep{takase2023spike} for their Huginn-0125 model."
- Skip connection: A direct pathway that bypasses a block, enabling gradient flow and stable training of deep/recurrent structures. "We note that the prelude parameters are still updated as the skip connection to the recurrent block allows for gradient propagation from the output."
- Test-time compute scaling: Increasing inference compute (without changing parameters) to improve output quality. "{\em Test-time compute scaling} refers to the use of additional computation during inference to improve model outputs."
- Truncated backpropagation: Limiting gradient propagation to a fixed number of recurrent steps to control memory and compute. "They also employ a truncated backpropagation procedure, only propagating gradients through at most the last $8$ passes through ."
- Universal transformers: Transformer variants with recurrence that, in theory, can simulate any computation (Turing-complete). "It has been shown that ``universal transformers'' based on recurrence are Turing-complete \citep{dehghani2018universal}."
- Weight shared layers: Reusing the same layer weights across repeated applications to reduce parameters and enable recurrence. "Recurrent transformers with weight shared layers but a fixed layer repetition count have been studied in detail~\citep{lan2019albert,takase2021lessons,fan2024looped,bae2024relaxed,gao2024algoformer,ng2024loop,csordas2024moeut,mcleish2024transformers,saunshi2025reasoning,zeng2025pretraining}."
- Weight tying: Using the same parameters for both embedding and unembedding layers to reduce parameter count. "We also use grouped-query attention \citep{ainslie2023gqa}, train all models with a context length of 1024, and do not weight-tie the embedding and unembedding layers."
Collections
Sign up for free to add this paper to one or more collections.