Long-Horizon Manipulation via Trace-Conditioned VLA Planning
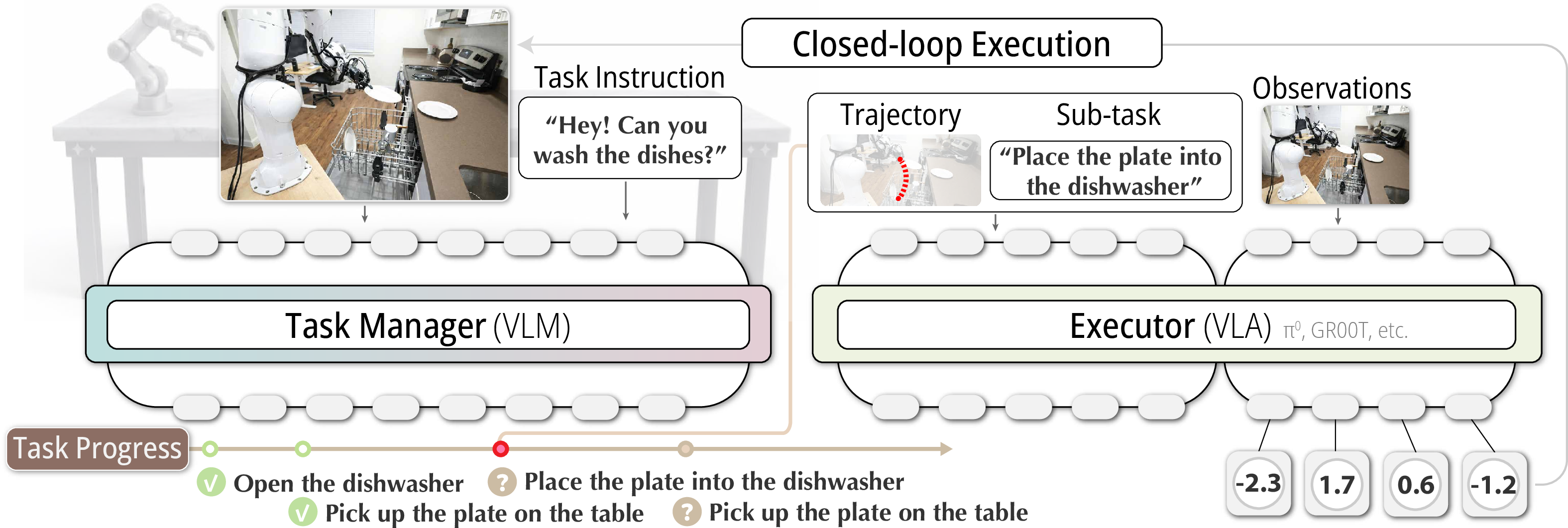
Abstract: Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to handle long, multi-step chores—things like “refill the kettle” or “tidy the desk”—instead of just one quick action like “pick up the cup.” The authors introduce a system called LoHo‑Manip that splits the robot’s “brain” into two parts:
- a high‑level manager that plans and keeps track of what still needs to be done, and
- a low‑level executor that actually moves the robot to do the next small step.
The key idea is to draw a simple path (a “visual trace”) on the robot’s camera view to show exactly where to go next, so the low‑level controller can “follow the line” step by step until the task is complete.
What questions does the paper ask?
The paper tries to solve three main problems:
- How can a robot break a long instruction into clear, smaller steps and keep track of progress?
- How can it keep going—even if it makes a mistake—without a human fixing it?
- How can it do well on new objects or layouts it hasn’t seen before?
How does the system work?
Think of a sports team:
- The manager (coach) decides what plays to run and keeps track of what’s finished and what’s next.
- The players (robot controller) carry out each play on the field.
LoHo‑Manip copies this idea.
The two main parts
- High‑level task manager (a vision‑LLM, like an AI that understands pictures and words):
- Sees the current camera view and the instruction (e.g., “refill the kettle”).
- Writes a tiny to‑do list that shows what’s “done” and what’s “remaining.”
- Draws a “visual trace”—a simple 2D path on the image—pointing to where the robot should move or what it should approach next.
- Low‑level executor (a vision‑language‑action policy, the “player”):
- Takes the image with the drawn path and moves the robot to follow it.
- Focuses on short, reliable moves instead of planning the whole task at once.
Why the “visual trace” helps
Imagine someone circling the sink on a photo and drawing a line from the cup to the faucet. That picture is much easier to follow than a paragraph of instructions. The visual trace does that for the robot: “go here, then here.”
Replanning every step (receding horizon)
Instead of planning the entire job once at the start, the manager updates the plan often—like GPS giving fresh directions every few seconds. If the robot drops the cup or gets blocked, the manager notices in the next camera image and updates the “remaining” steps and the drawn path. No special “error rules” are needed; it just keeps going until the to‑do list is empty.
Simple memory for progress
The manager doesn’t store long video histories. It only looks at the current image and a short text summary like:
- “Done: picked up cup.”
- “Remaining: move to faucet, fill cup, go to kettle, pour.”
This avoids getting confused by long, imperfect recordings and keeps decisions fast.
How they trained it (in everyday terms)
- They took robot videos and used off‑the‑shelf AI tools to:
- split the videos into small, meaningful steps (like “grasp cup”),
- track the robot hand’s position in each frame (to get the path to draw).
- They trained the manager to predict:
- the remaining to‑do list, and
- the path to draw next,
- from just the current image and the progress text.
- They fine‑tuned the low‑level controller to “follow the drawn path,” so it can reliably execute each short step.
What did they find?
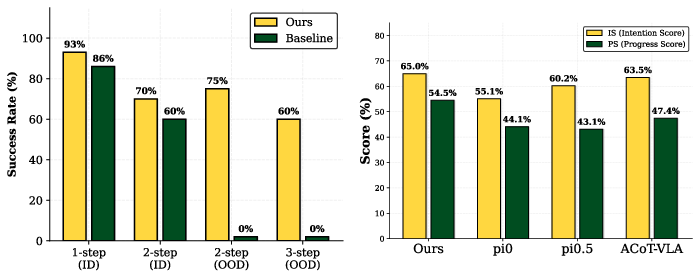
Across many tests—in both computer simulations and a real robot arm (a Franka)—LoHo‑Manip:
- Finished more long, multi‑step tasks successfully than previous methods.
- Recovered better from mistakes (like grabbing the wrong item), because the manager just kept listing the unfinished step and redrawing the path until it was truly done.
- Generalized better to new objects, scenes, and instructions it hadn’t seen before, because the manager could point to the right place with the visual trace, and the executor just followed it.
- Worked as a modular system: the same manager could guide different low‑level controllers, making upgrades easier.
In short, it was more reliable, more flexible, and better at handling long instructions than single “all‑in‑one” robot brains.
Why is this important?
- More dependable household and workplace robots: They can handle real tasks that have many interdependent steps and recover from small failures without giving up.
- Easier to upgrade: Because planning (manager) and movement (executor) are separate, you can improve one without retraining the other.
- Better generalization: The manager’s grounded, drawn guidance helps the robot act correctly even in new environments or with new objects.
- A practical path forward: Turning hard, long-horizon planning into repeated, easy “follow-the-line” moves is a simple trick that pays off in robustness and success.
Takeaway
LoHo‑Manip is like giving a robot a coach who keeps a running to‑do list and a marker to draw the next move right on the robot’s camera view. This turns complicated chores into a chain of small, clear steps the robot can reliably execute. The result: fewer failures, better recovery, and stronger performance on long tasks—both in simulation and in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- 2D visual trace lacks depth and orientation: no encoding of 3D end-effector pose, approach direction, gripper orientation/state, or contact targets needed for many manipulation tasks.
- Multi-view consistency and calibration: how traces are aligned across top-view and wrist-view cameras and mapped to robot coordinates is not specified nor evaluated.
- Feasibility and safety of trace-following: no mechanism to guarantee collision-free, kinematically feasible trajectories or to account for obstacles, self-collisions, or workspace constraints.
- Dynamic/interactive environments: robustness to moving targets, human interference, or objects that shift during execution is not assessed.
- Partial observability and occlusions: conditioning on the current frame only may fail under occlusions; no analysis of failure modes or methods to recover missing context.
- Memory correctness and drift: the textual “completed/remaining” memory is self-reported by the manager without external verification; misclassification can cause loops or skipped steps.
- Termination criteria and loop avoidance: no strategy to detect task completion or prevent endless re-planning cycles when the manager repeatedly mispredicts progress.
- Trace rendering side-effects: overlaying traces on pixels may obscure important visual cues; alternatives (e.g., separate channels or 3D overlays) are not studied.
- End-effector localization accuracy: the impact of noisy pixel-level end-effector labels (especially on real robots) on manager training and inference is not quantified.
- Failure recovery generality: synthesized failures focus on grasp substitution; broader error types (slippage, misplacement, blocked paths, orientation errors, partial pours) are not modeled or evaluated.
- Scaling to very long horizons: performance and memory behavior for tasks with dozens of dependent steps (e.g., 20–50+) is not characterized.
- Invocation frequency and latency: the computational cost, step rate, and real-time responsiveness of repeatedly invoking the manager are not reported.
- Executor-agnostic claims vs. evaluation: despite a modular interface, empirical validation with multiple, diverse VLAs beyond π0.5 is limited; plug-and-play compatibility remains unproven.
- Subtask abstraction quality: how atomic primitives are defined, standardized across tasks, and kept consistent across different embodiments and datasets is not detailed.
- Mapping subtask text to skills: it is unclear how the executor interprets subtask semantics beyond “follow the trace,” especially for actions requiring discrete mode switches (open/close, rotate, press).
- Contact-rich manipulation: tasks needing force/torque control, compliance, insertion, or sliding with tight tolerances are not addressed by the trace representation.
- Clutter, narrow spaces, and complex geometry: robustness in heavily cluttered tabletop scenes or confined manipulation settings is not evaluated.
- Integration with structured planners: no mechanism to check preconditions/effects or incorporate task-and-motion planning (TAMP), PDDL, scene graphs, or constraint solvers.
- State variables beyond language memory: numeric task states (e.g., fill level, temperature, screw tightness) are not measured or tracked; reliance on vision-only progress text may be insufficient.
- Camera motion and ego-visual dynamics: wrist-view movement complicates pixel-trace stability; the approach to keeping traces valid under camera motion is not discussed.
- Trace parameterization choices: waypoint density, resampling strategy, smoothing, thickness/color, and their effect on executor performance are not ablated.
- Domain shift analysis: robustness to lighting changes, reflections, motion blur, varying backgrounds, and sensor noise is not systematically tested.
- Real-world safety protocols: collision checks, emergency stops, workspace limits, and recovery procedures during failures are not specified.
- Generalization across embodiments in closed loop: while trajectory prediction is shown cross-embodiment, end-to-end closed-loop manipulation on different arms/grippers is not demonstrated.
- Sample efficiency and data scaling: sensitivity to the number/quality of demonstrations (e.g., beyond 100 demos) and the trade-off between real vs. synthetic data is not studied.
- Labeling pipeline reliability: event segmentation via off-the-shelf VLMs may introduce errors; label quality, error rates, and their downstream effects are not analyzed.
- Benchmark comparability: fairness of comparisons across models with different training data, modalities, and scales is unclear; reproducibility details are missing.
- Progress-tracking metrics: accuracy of the manager’s “done vs. remaining” predictions against ground-truth task states is not quantitatively evaluated.
- Mobile manipulation and navigation: the approach is not validated for base motion, long path planning, or multi-room tasks where 3D mapping is essential.
- Multi-agent/bimanual manipulation: extension to coordinating two arms or multiple agents is not discussed.
- Energy/computational footprint on-robot: inference time, model size, and resource demands for running VLM+VLA in real-time on embedded hardware are not reported.
- Handling distractors and semantic ambiguity: systematic evaluation under heavy distractor objects and ambiguous language instructions is limited.
- Failure analysis and ablations: contributions of “remaining plan” vs. single-step directives, and trace vs. text conditioning, lack thorough ablation on closed-loop success.
- Orientation- and grasp-type specification: how the manager/executor specify and achieve precise grasp types, approach angles, and tool use is left open.
- Depth and 3D scene understanding: the potential of leveraging depth or reconstructed 3D scene representations to improve trace feasibility and grounding is unexplored.
Practical Applications
Immediate Applications
The following use cases can be deployed with today’s robot hardware, vision-language(-action) models, and available datasets, leveraging LoHo-Manip’s decoupled task manager, progress-aware planning, and visual trace prompting.
- Robust long-horizon execution in existing robot cells (Manufacturing, Warehousing, Logistics; Robotics)
- What: Retrofit current pick-and-place, assembly, kitting, packaging, or inspection cells with a task manager that decomposes instructions into subtasks and renders a 2D visual trace to guide the existing VLA/VA executor.
- Tools/Workflows: ROS/Isaac integration of a “Task Manager” node; executor fine-tuning for trace-following; on-camera overlay of traces; receding-horizon loop for implicit recovery.
- Assumptions/Dependencies: Calibrated RGB camera(s); end-effector localization to create/check traces; small finetuning budget for the executor; sufficient on-prem compute to run a lightweight VLM manager and VLA at control rates.
- Automated demonstration curation and dataset creation (Academia, Robotics R&D; Software)
- What: Use the paper’s data pipeline to segment existing manipulation videos into atomic subtasks and extract end-effector traces for supervision, dataset cleaning, and new training sets.
- Tools/Workflows: Off-the-shelf VLMs for event grounding + object detection; automatic extraction of 2D keypoint trajectories; export to Open X-Embodiment format.
- Assumptions/Dependencies: Access to recorded RGB streams and pose or reliable end-effector visual localization; a VLM with adequate grounding accuracy.
- Progress-aware monitoring and observability for robot operations (Manufacturing, Logistics; Software/DevOps for Robotics)
- What: Stream “done/remaining” plans and visual traces to an ops dashboard for introspection, failure triage, and human-in-the-loop interventions.
- Tools/Workflows: Telemetry pipeline that logs the textual memory and traces; stop/resume/replan buttons tied to manager outputs; alerting on stalled subtasks.
- Assumptions/Dependencies: Stable networked logging; alignment of subtask vocabulary with cell-specific SOPs; human oversight protocols.
- Zero-shot targeting of novel items via trace prompts (E-commerce Fulfillment, Lab Automation; Robotics)
- What: Exploit the manager’s grounding to point to unseen objects and have the executor follow traces even when the object category wasn’t in executor training.
- Tools/Workflows: “Trace-as-prompt” adaptation of the executor; manager trained/fine-tuned on diverse visual grounding data.
- Assumptions/Dependencies: Manager must reliably detect and point to targets in current views; mild domain shift tolerated by the VLM; camera coverage of workspace.
- Faster recovery from execution errors without custom heuristics (Manufacturing, Service Robotics; Robotics)
- What: Replace hand-crafted failure detectors with implicit remaining-plan recomputation; failed subtasks persist and trigger new traces until completion.
- Tools/Workflows: Receding-horizon manager calls; short control bursts between updates; optional failure synthesis augmentation during training (as in paper).
- Assumptions/Dependencies: Manager must handle partial observability with current-frame conditioning and textual memory; adequate cadence for updates.
- AR/UX overlays for human-robot collaboration and training (Manufacturing, Education; HRI/UX)
- What: Visualize predicted traces and remaining subtasks on an AR display or workstation to coordinate with humans (e.g., confirm next step, handover).
- Tools/Workflows: AR app that renders 2D traces in image space; confirmation gates before critical steps; “teach-by-explaining” demos using trace playback.
- Assumptions/Dependencies: Synchronized camera feeds; UI integration; ergonomic alignment between camera view and human perspective.
- Benchmarking and controlled ablations for long-horizon manipulation (Academia; Evaluation)
- What: Use the manager’s explicit plan and trace to probe failure modes, measure progress scores, and run fair comparisons across VLAs with the same manager.
- Tools/Workflows: VLABench/LIBERO test harness; manager checkpoints fixed across executors; per-step plan+trace logs for reproducibility.
- Assumptions/Dependencies: Access to target benchmarks; compatible action spaces or wrappers for multiple VLAs.
- Modular policy upgrades with reduced re-engineering (Robotics Platforms; Software)
- What: Swap in new low-level policies (e.g., different arms or grippers) without retraining the high-level manager; retain the “trace interface.”
- Tools/Workflows: Standardized trace rendering across embodiments; executor adapters that accept the same spatial prompt.
- Assumptions/Dependencies: Executors must be fine-tuned to follow the trace; consistent camera-action alignment across embodiments.
- Pre-deployment “dry runs” in simulation with trace-conditioned control (Digital Twins; Software/Simulation)
- What: Validate long-horizon plans in simulation using the same manager/executor loop before deploying to real cells.
- Tools/Workflows: Isaac Sim or similar digital twin; manager-in-the-loop rollout; trajectory discrepancy metrics (DFD/HD/RMSE) to gate deployment.
- Assumptions/Dependencies: Sim-to-real calibrated camera and kinematics; domain gap manageable for visual grounding.
- Explainability and compliance logging for safety-critical workflows (Manufacturing QA; Policy/Compliance)
- What: Store remaining-plan texts and rendered traces as interpretable evidence of intended behavior for audits and incident reviews.
- Tools/Workflows: Immutable logs with per-step trace images and timestamps; reviewer tools to scrub through plan evolution.
- Assumptions/Dependencies: Organizational policies that accept plan/trace logs as explainability artifacts; secure storage.
Long-Term Applications
These opportunities require further research, scaling, or engineering beyond the current paper (e.g., 3D traces, mobile manipulation, broader safety and standards).
- Household and service robots executing complex chores (Consumer Robotics, Hospitality; Daily Life)
- What: Multi-room, multi-object tasks (e.g., “prepare coffee and tidy the counter”) with robust recovery and generalization to new homes and items.
- Potential Products: Home task manager app with receding-horizon plans; plug-and-play executors for different robot platforms.
- Assumptions/Dependencies: Reliable mobile manipulation (navigation + manipulation); 3D scene understanding; safety certification.
- Assistive care and clinical support (Healthcare; Policy/Safety)
- What: Progress-aware assistance (e.g., meal prep, medication staging) with explicit plan logs and human approval checkpoints.
- Potential Products: “Care-task manager” with oversight UI; trace-conditioned assistive manipulators.
- Assumptions/Dependencies: Stringent safety, privacy, and regulatory approvals; high-precision perception; robust failure handling under strict constraints.
- Construction, maintenance, and inspection workflows (AEC, Utilities; Robotics)
- What: Long, interdependent procedures (e.g., valve inspections, filter replacements) with dynamic replanning from evolving observations.
- Potential Products: Field-robot task manager with outdoor-capable tracing and low-connectivity operation.
- Assumptions/Dependencies: Harsh environment robustness; 3D traces on complex surfaces; weather and lighting variability.
- Multi-robot coordination via multi-trace scheduling (Manufacturing, Warehousing; Robotics/Operations)
- What: A single manager orchestrates multiple executors, issuing distinct traces per robot and resolving resource/contention constraints.
- Potential Products: “Coordinator” layer for fleet scheduling with trace-aware task allocation.
- Assumptions/Dependencies: Communication middleware; shared workspace safety; task-level synchronization primitives.
- From 2D visual traces to 3D semantic trajectories (General Robotics; Research)
- What: Lift traces to 3D waypoints with object-centric semantics and uncertainty, enabling whole-body control and out-of-plane tasks.
- Potential Products: 3D “Trace Prompt Protocol” and libraries for SE(3) tracing; calibration-light 3D grounding.
- Assumptions/Dependencies: Robust depth/pose estimation; alignment across sensors; sample-efficient training for 3D trace-following.
- Mobile manipulation with integrated navigation planning (Logistics, Service Robotics; Robotics)
- What: Unify room-level routing with local manipulation via hierarchical traces (e.g., waypoint chains from doors to workstations to tools).
- Potential Products: Hierarchical receding-horizon planner that alternates nav-traces and manip-traces.
- Assumptions/Dependencies: Navigation stack integration; persistent memory across spaces; map and localization reliability.
- Vendor-agnostic “Task Manager as-a-Service” and standardization (Robotics Ecosystem; Policy/Standards)
- What: A cloud or on-prem service exposing a standard API for remaining-plan texts and trace prompts across robot vendors.
- Potential Products: Open standard for trace-serialization and rendering; conformance test suites.
- Assumptions/Dependencies: Industry buy-in; data governance for video streams; latency constraints for control loops.
- Human-in-the-loop teaching and assessment with trace feedback (Education/Training; HRI)
- What: Use the manager to generate stepwise plans and traces for teaching novices and grading robot coursework or certifications.
- Potential Products: “Trace Studio” for authoring, reviewing, and grading; interactive correction of manager outputs.
- Assumptions/Dependencies: Pedagogical interfaces; standardized task libraries; reliable plan interpretability.
- Safety and regulatory frameworks centered on interpretable plans (Policy, Insurance; Standards)
- What: Use remaining-plan logs and trace evidence to define minimum explainability and recovery requirements for deployed robots.
- Potential Products: Compliance checkers that replay logs and verify gated approvals at key steps.
- Assumptions/Dependencies: Consensus on metrics and evidence formats; formal risk models that accept plan/trace artifacts.
- Foundation models that generalize across embodiments and tasks (Research; Platform Strategy)
- What: A single high-level manager that ports across arms, grippers, and sensors with minimal adaptation, relying on the stable trace interface.
- Potential Products: Cross-embodiment checkpoints for managers; adapters for diverse action spaces.
- Assumptions/Dependencies: Broader, more diverse training data; improved grounding under extreme shifts; executor-agnostic trace semantics.
- Self-improving robots via failure synthesis and closed-loop data collection (Research/Operations)
- What: Scale the paper’s failure augmentation to continual learning pipelines that mine recovery cases and retrain the manager/executor.
- Potential Products: Automated “recovery miner” and retraining scheduler; on-robot data flywheels.
- Assumptions/Dependencies: Safe data collection during failures; robust labeling and privacy controls; compute for periodic retraining.
Glossary
- 2D keypoint trajectory: A sequence of pixel coordinates indicating a path or motion plan in the image plane. "a visual trace---a compact 2D keypoint trajectory prompt specifying where to go and what to approach next."
- atomic interaction primitives: Minimal, indivisible robot actions used to compose longer tasks. "we represent the task as a sequence of atomic interaction primitives"
- BLEU score: An n-gram overlap metric commonly used to evaluate generated text against references. "We report the BLEU score for RoboVQA"
- closed loop: A control setup where outputs are fed back into planning or control to continually adjust behavior. "yields an implicit closed loop"
- credit assignment: The challenge of determining which past actions contributed to current outcomes in long sequences. "unstable credit assignment"
- Discrete Fréchet Distance (DFD): A trajectory similarity metric that measures the similarity between curves considering the order of points. "Discrete Fréchet Distance (DFD)"
- distribution shift: A mismatch between training and deployment data distributions that can degrade performance. "distribution shift between training trajectories and real executions."
- egocentric: Referring to first-person or agent-centric observations. "an egocentric observation image"
- end-effector: The robot’s tool or gripper at the end of its arm that interacts with the environment. "the 2D pixel coordinate of the robot end-effector"
- end-to-end manipulation: A setup where perception, planning, and control are integrated into a single learned pipeline for manipulation tasks. "end-to-end manipulation in simulation and on a real Franka robot"
- Hausdorff Distance (HD): A measure of the maximum deviation between two sets of points, used to compare trajectories or shapes. "Hausdorff Distance (HD)"
- imitation learning: Learning policies by mimicking expert demonstrations rather than explicit reward optimization. "driven by large-scale imitation learning"
- Intention Score (IS): A metric assessing how well an agent’s actions align with the intended task goals. "Intention Score (IS) and Progress Score (PS)"
- long-horizon manipulation: Robotic tasks requiring many interdependent steps with persistent reasoning and control over extended durations. "Long-horizon manipulation remains challenging"
- monolithic policy: A single model that jointly handles planning and control without modular separation. "a single monolithic policy"
- occlusions: Visual obstructions where objects are partially or fully hidden from view. "partial failures, occlusions, or object motion."
- out-of-distribution generalization: The ability to perform well on inputs that differ from those seen during training. "out-of-distribution generalization."
- partial observability: A condition where the agent cannot fully observe the true state of the environment. "limited by drift and partial observability."
- progress-aware remaining plan: A plan representation that explicitly encodes what has been completed and what is left to do. "it predicts a progress-aware remaining plan"
- progress tracking: Maintaining an estimate of which sub-tasks have been completed during execution. "implicit progress tracking"
- receding-horizon: A planning approach that repeatedly optimizes over a short future window and updates as new observations arrive. "invoked in a receding-horizon manner"
- replanning: Updating the plan during execution to account for failures or changes. "implicit replanning"
- Root Mean Square Error (RMSE): A standard metric measuring the average magnitude of errors between predicted and ground-truth values. "Root Mean Square Error (RMSE)"
- scene-graph: A structured representation of a scene’s objects and their relations used for grounded planning. "3D scene-graph grounded planning"
- semantic navigation: Navigation guided by high-level semantic goals (e.g., objects/categories) rather than just geometric targets. "for semantic navigation and interaction in 3D indoor scenes."
- task-and-motion planning (TAMP): A framework that integrates symbolic task planning with continuous motion planning for feasibility. "task-and-motion planning (TAMP)"
- teleoperation: Controlling a robot remotely by a human operator to collect demonstrations or perform tasks. "via teleoperation"
- value maps: Spatial representations encoding expected utility or value across locations to guide actions. "code, value maps, or waypoints"
- video grounding: Linking textual descriptions to specific spatial-temporal regions or events in video. "with video grounding capabilities"
- visual localization: Estimating the position of objects or the robot within visual input. "via visual localization."
- visual trace: A rendered trajectory overlay used as a spatial prompt guiding low-level control. "a visual trace---a compact 2D keypoint trajectory prompt"
- vision-language-action (VLA): Models that map visual and textual inputs directly to action outputs. "The executor VLA is adapted to condition on the rendered trace"
- vision-LLM (VLM): Models that integrate visual and textual understanding for perception and reasoning. "a dedicated task-management VLM"
- waypoint sequence: A list of intermediate target points that define a path or plan for execution. "(e.g., waypoint sequence)"
Collections
Sign up for free to add this paper to one or more collections.