- The paper introduces a novel vision-language-action framework that explicitly decomposes tasks into structured spatiotemporal chunks, improving planning and execution.
- It employs a dual-generator module combining spatial and temporal flow-matching to ensure smooth trajectories and causal consistency in long-horizon tasks.
- Experiments on benchmarks LIBERO, SIMPLER, and STAR demonstrate significant performance gains over state-of-the-art methods in complex robotic manipulation.
Structured SpatioTemporal VLA for Robotic Manipulation: An Expert Analysis of ST-π
Introduction
The paper "ST-π: Structured SpatioTemporal VLA for Robotic Manipulation" (2604.17880) introduces a vision-language-action (VLA) framework that explicitly structures both chunk-level planning and step-level execution for fine-grained, long-horizon robotic manipulation tasks. The approach contrasts with prior work wherein spatiotemporal dependencies across high-level sub-tasks and within action sequences are modeled implicitly, restricting performance in tasks with explicit spatial and temporal boundaries. ST-π proposes explicit spatiotemporal modeling via a dual-component architecture: a SpatioTemporal Vision-LLM (ST-VLM) for structured task decomposition and a SpatioTemporal Action Expert (ST-AE) for generating coherent action trajectories. The framework is complemented by the development of a new real-world dataset, STAR, with structured spatiotemporal annotations supporting the data requirements of fine-grained manipulation.
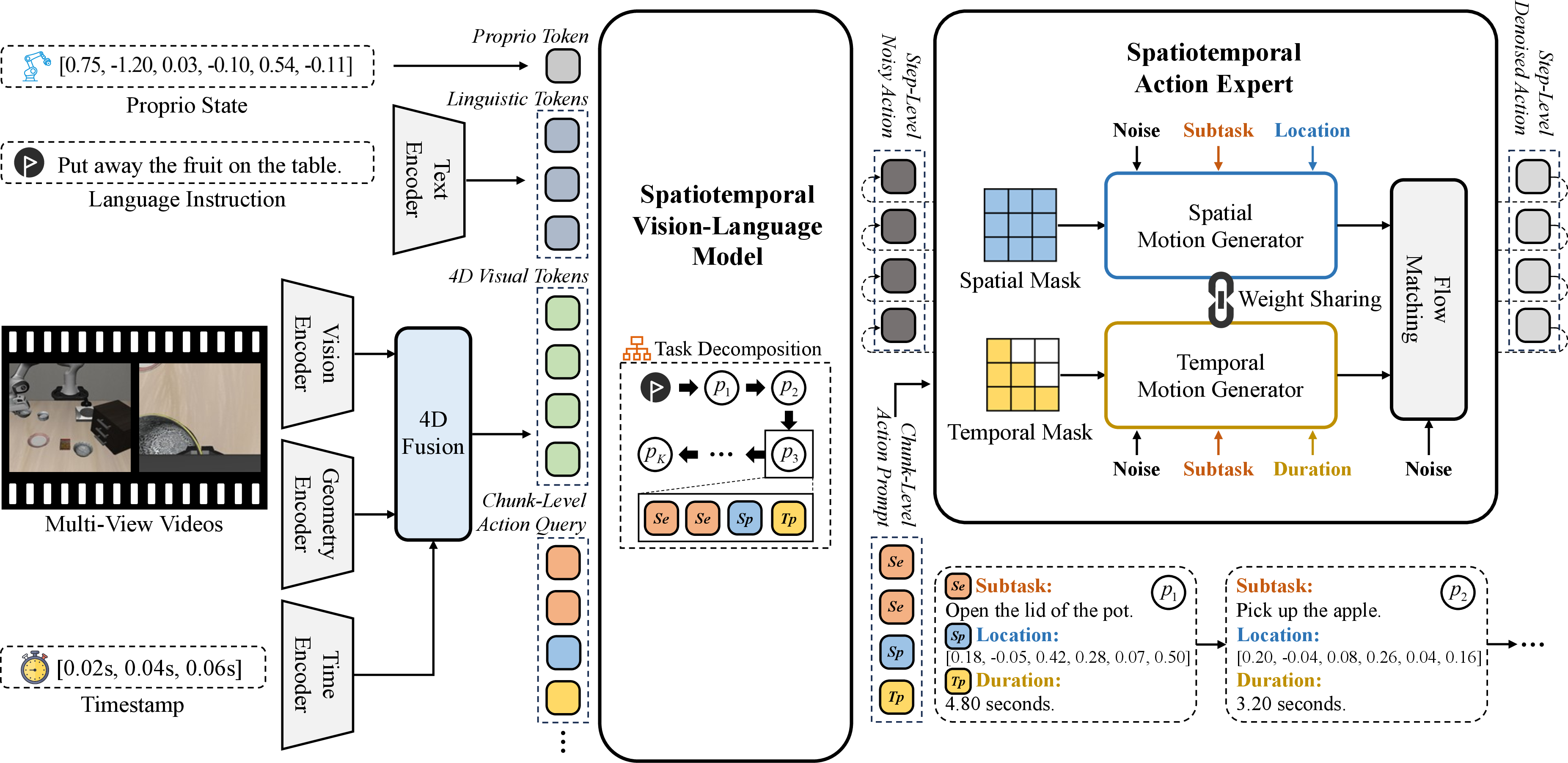
Figure 1: Overview of ST-π, illustrating explicit structured task decomposition and dual-generator action chunk creation for stable long-horizon trajectories.
Fine-grained robotic manipulation encompasses tasks with multiple sequential sub-tasks, each with distinct spatial and temporal boundaries. Existing VLA approaches, even those utilizing 4D representations, often encode such structure only implicitly in latent spaces. Consequently, these models are limited in their ability to reason about inter-sub-task dependencies and maintain stable execution across long temporal horizons. The authors argue that explicit spatiotemporal chunk-level decomposition, alongside step-level action generation with interleaved spatial and temporal inductive biases, is necessary for robust long-horizon manipulation. This design principle underpins the architecture of ST-π.
ST-π Framework
SpatioTemporal Vision-LLM (ST-VLM)
ST-VLM processes 4D observations (sequences of RGB images, geometric features, and time embeddings) and high-level language instructions, producing a structured plan—a sequence of chunk-level action prompts. Each action prompt contains semantic tokens representing intent, spatial tokens for target regions, and temporal tokens specifying durations. Planning is executed in a rolling-horizon style, where a fixed future window of sub-tasks K is autoregressively predicted, enforcing causal dependencies via block-wise causal attention mechanisms. The chunking structure (semantic/spatial/temporal decomposition) is tightly supervised during training to enforce explicit and interpretable boundaries between sub-tasks.
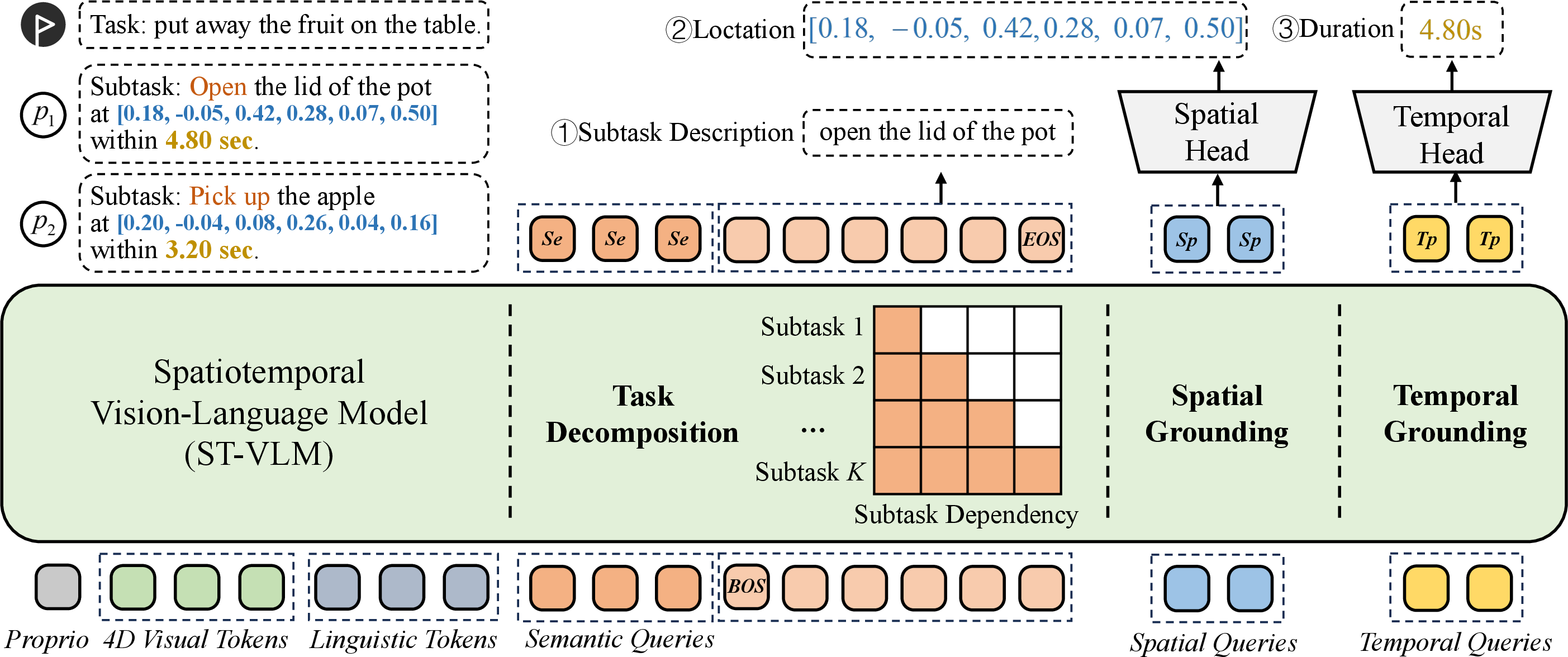
Figure 2: The ST-VLM architecture constructs unified 4D representations and generates causally ordered chunk-level action prompts through structured task decomposition.
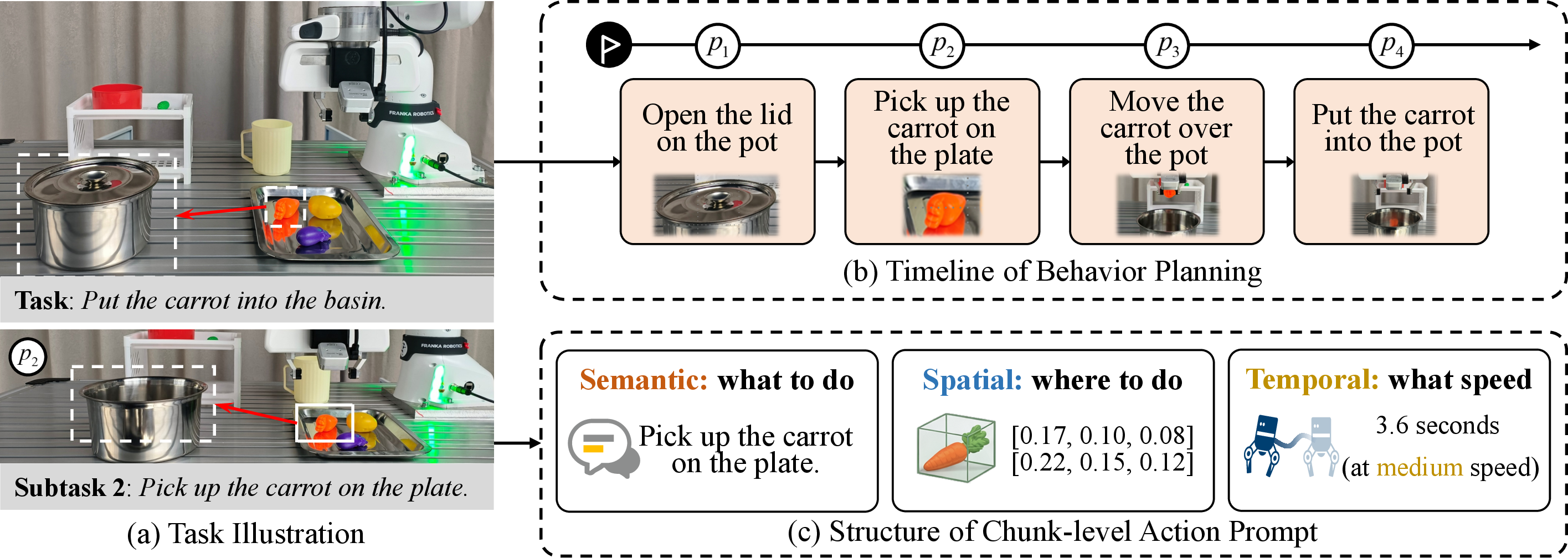
Figure 3: Task decomposition: a complex task (a) is segmented into sub-tasks (b), each represented by structured chunk-level action prompts (c) capturing semantic, spatial, and temporal characteristics.
SpatioTemporal Action Expert (ST-AE)
The ST-AE is a dual-generator module that, conditioned on chunk-level action prompts and 4D observations, generates low-level action chunks via a flow-matching mechanism. The spatial generator enforces trajectory smoothness through bidirectional attention across steps, conditioned on spatial and semantic tokens. The temporal generator enforces temporal causal consistency, with each action step only dependent on its past, conditioned on temporal and semantic tokens. Updated flows from both generators are fused in a time-dependent fashion, interpolating from spatial to temporal predominance as the action chunk is iteratively refined via denoising.
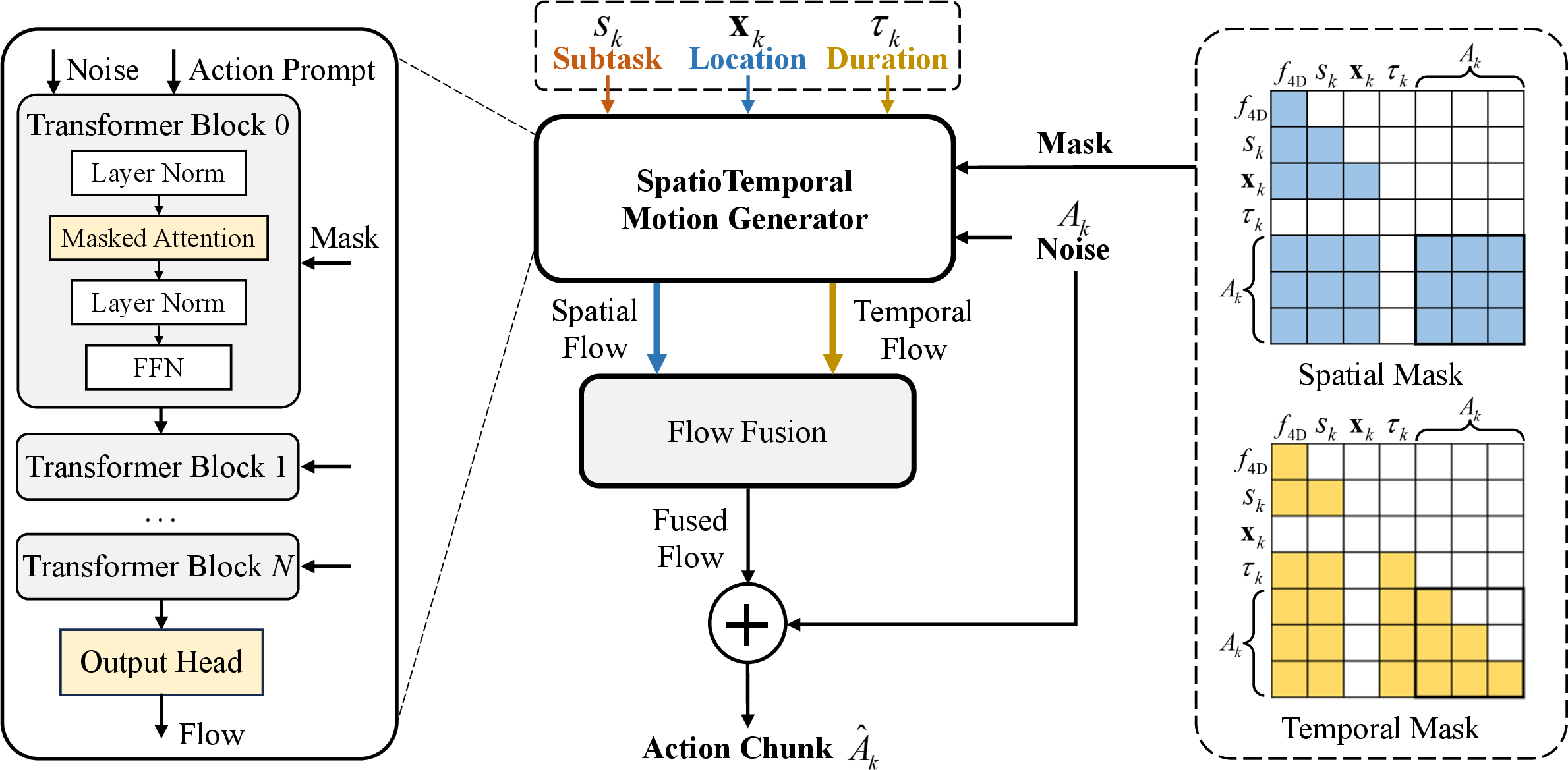
Figure 4: ST-AE architecture with dual spatial and temporal motion generators, whose fused flows guide the generation of spatially smooth and temporally coherent action sequences.
Training and Optimization
Training proceeds in three stages:
- Spatial alignment: Geometry adapters and 4D fusion modules are trained on 3D scene datasets.
- Structured chunk-level decomposition: The model learns to autoregressively generate semantically and temporally segmented prompts from demonstration data.
- Action policy learning: End-to-end fine-tuning on the STAR dataset using flow-matching penalties engages both spatial and temporal generators in the ST-AE.
Supervision involves language modeling for semantic tokens, regression losses on spatial and temporal targets, and flow-matching objectives for action denoising.
STAR Dataset
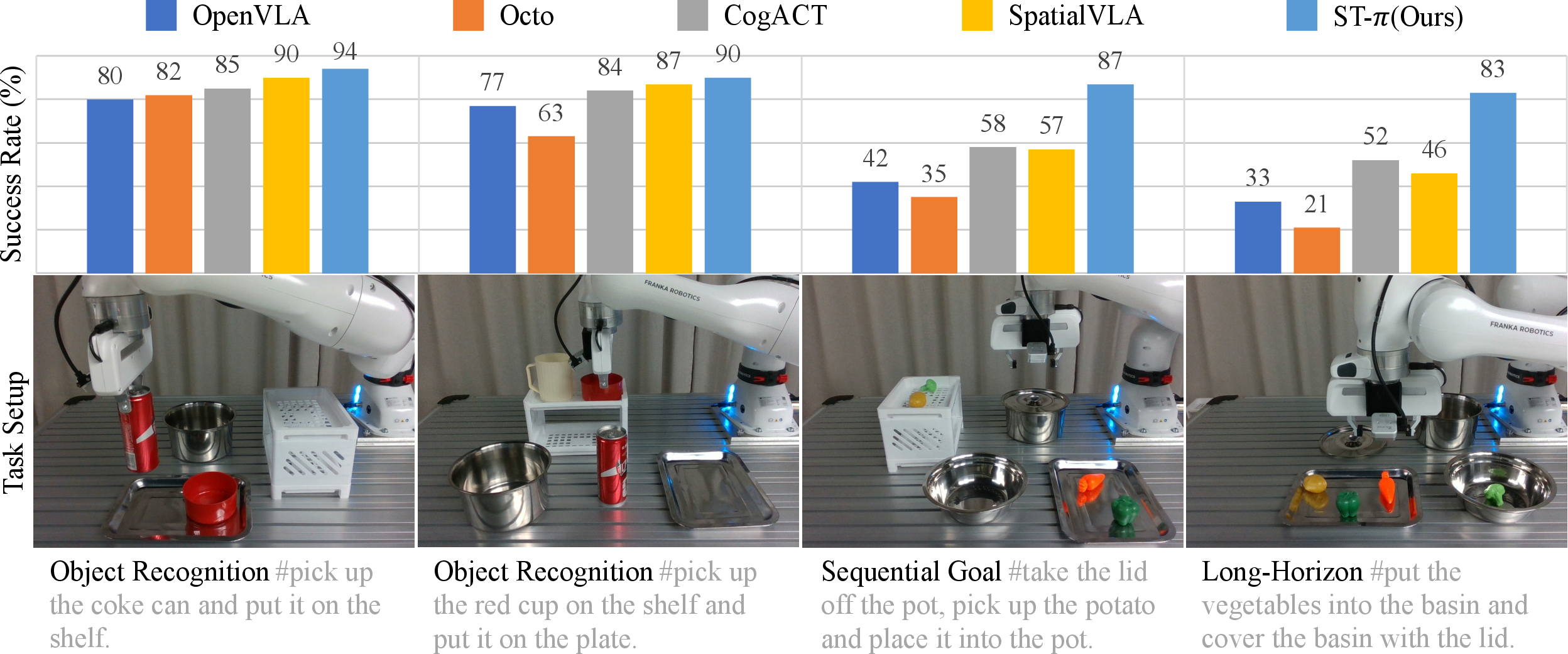
To address the lack of structured, real-world long-horizon manipulation datasets, the authors introduce STAR (Spatiotemporal Task Annotation for Robotics), collected with a Franka Research 3 platform. STAR provides 30 tasks of increasing complexity (Object Recognition, Sequential Goal, Long-Horizon), each annotated with natural language instructions, spatial targets, and execution durations, enabling rigorous evaluation of spatiotemporal decomposition and policy generalization.

Figure 5: The STAR dataset and experimental platform, with each task decomposed into granular sub-tasks annotated with language, location, and timing.
Experimental Evaluation
The authors conduct comprehensive evaluations on three benchmarks: LIBERO, SIMPLER, and the introduced STAR dataset. ST-π is compared against state-of-the-art VLA baselines including OpenVLA, Octo, CogACT, π0.5, 4D-VLA, and SpatialVLA.
Key findings:
Ablation Studies and Analysis
Ablations show distinct performance drops when either ST-VLM (structured task decomposition) or ST-AE (dual spatiotemporal generators) are removed. Full 4D observation input is necessary for optimal performance, with reduction to 3D or 2D input resulting in degraded stability and success rates.
Task decomposition granularity is also analyzed: moderately increased sub-task numbers (π8) yield optimal trade-offs between policy flexibility and prediction noise.
Ablation on spatiotemporal attention structures reveals that strictly causal inter-chunk attention is crucial for stable long-horizon planning—bidirectional or no attention degrades both simulation and real-world metrics.
Analysis of the action expert indicates that while the spatial generator alone ensures trajectory smoothness and the temporal generator ensures velocity regularity, only their combination delivers spatial and temporal coherence.
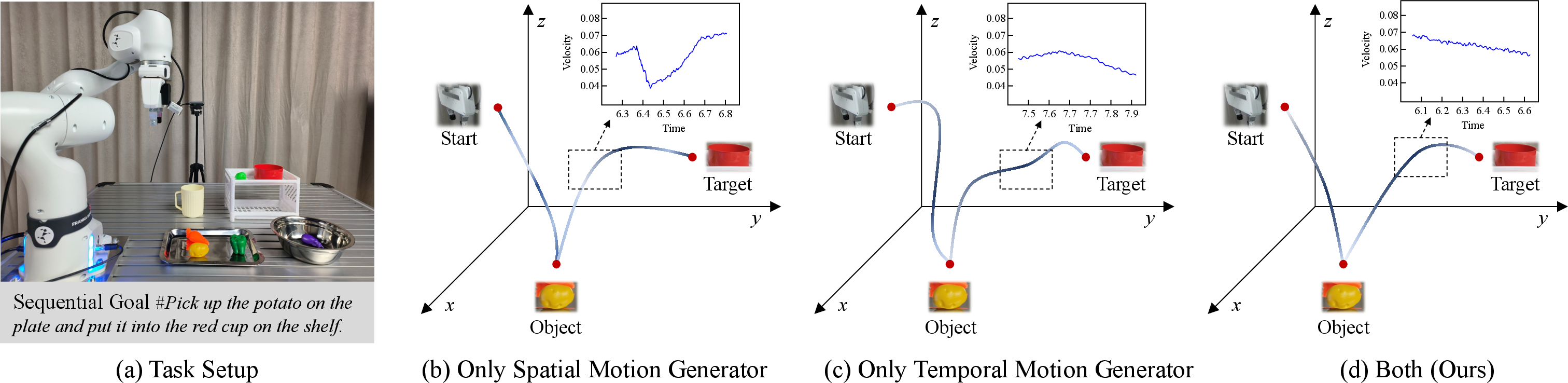
Figure 7: Trajectory analysis reveals that only the combined spatial and temporal generators of ST-AE produce both smooth and temporally consistent execution paths.
Discussion and Implications
ST-π9 demonstrates that explicit structuring of both high-level spatiotemporal decomposition and low-level action generation substantially improves planning and execution across both simulated and real-world manipulation domains. The explicit architectural biases—chunk-level planning, causal inter-chunk dependencies, dual-generator action composition—yield measurable gains in robustness and task completion rates for long-horizon tasks. This framework suggests that moving beyond implicit spatiotemporal modeling is necessary for the next generation of generalist robotic policies, particularly as embodied tasks scale in complexity.
Pragmatically, the modularity of ST-π0 allows adaptation to diverse robotic platforms and application areas demanding long-horizon, multi-stage behaviors. The reliance on explicit decomposition also enhances interpretability and debugging capabilities, which are desirable for safety-critical and human-robot collaborative contexts.
Theoretically, the work provides strong empirical evidence for hybrid approaches combining structured planning with deep policy learning, as well as the effectiveness of flow-matching denoising strategies for action synthesis.
Future extensions should address non-sequential task structures (e.g., parallel or branching sub-task execution), richer hierarchical decompositions, and broader multi-modal grounding (such as tactile or force sensing).
Conclusion
ST-π1 (2604.17880) establishes a new state of the art for vision-language-action robotic manipulation by explicitly modeling both chunk-level spatiotemporal decomposition and step-level action generation. The structured dual-component framework, validated through rigorous simulation and real-world experiments, demonstrates the necessity of interpretable, causally-aware planning and coherent action synthesis for fine-grained, long-horizon manipulation tasks. The methodology and dataset contributions will likely catalyze further research on explicit hierarchical and spatiotemporal reasoning for embodied AI.