- The paper introduces a dual-memory approach that integrates perceptual and cognitive streams to tackle non-Markovian challenges in robotic manipulation.
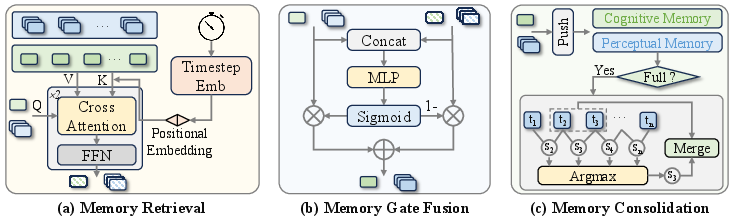
- It employs a Perceptual–Cognitive Memory Bank (PCMB) with retrieval, gate fusion, and token consolidation to merge historical and current observations effectively.
- Experimental results show significant improvements, achieving up to 96.5% success on diverse tasks while maintaining robust performance under out-of-distribution conditions.
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Motivation and Problem Statement
Robotic manipulation tasks are fundamentally non-Markovian, often requiring temporally extended reasoning and memory of past states and actions. Mainstream Vision-Language-Action (VLA) models typically operate on single-frame observations, neglecting temporal dependencies and thus underperforming on long-horizon tasks. The MemoryVLA framework addresses this limitation by introducing a dual-memory system inspired by cognitive science, explicitly modeling both short-term and long-term temporal context for robust robotic control.
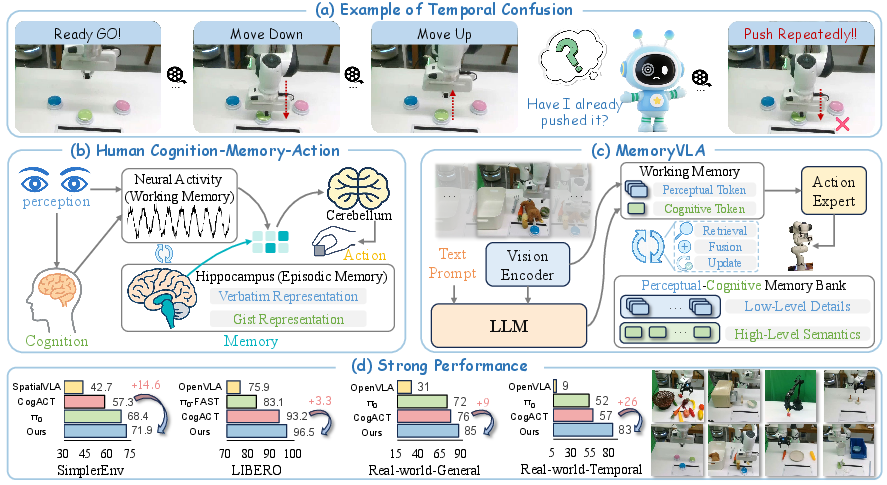
Figure 1: (a) Push Buttons tasks require temporal modeling due to visually indistinguishable pre- and post-action states. (b) Human dual-memory system. (c) MemoryVLA's Perceptual–Cognitive Memory Bank. (d) MemoryVLA outperforms baselines.
Architecture and Methodology
Vision-Language Cognition Module
MemoryVLA leverages a 7B-parameter Prismatic VLM, pretrained on Open-X Embodiment, to encode RGB observations and language instructions into two streams:
- Perceptual tokens: Extracted via DINOv2 and SigLIP backbones, compressed to Np=256 channels using SE-bottleneck.
- Cognitive token: Projected into the LLM embedding space and processed by LLaMA-7B, yielding a compact high-level semantic representation.
These tokens constitute the working memory, analogous to transient neural activity in the cortex.
Perceptual–Cognitive Memory Bank (PCMB)
The PCMB stores temporally indexed entries for both perceptual and cognitive streams, maintaining up to L entries per stream. At each timestep, the working memory queries the PCMB via cross-attention with sinusoidal positional encoding, retrieving decision-relevant historical context.
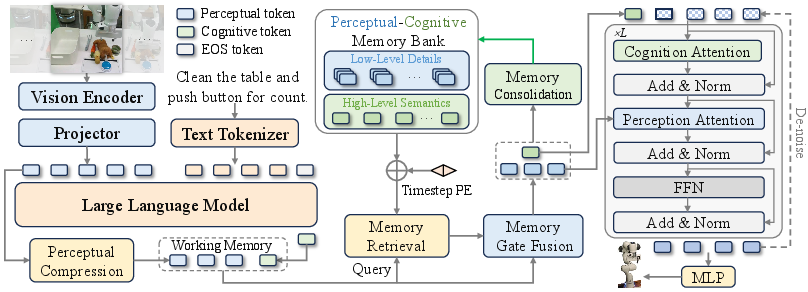
Figure 2: MemoryVLA architecture: VLM encodes inputs, working memory queries PCMB, fuses retrieved context, and conditions a diffusion transformer for action prediction.
Memory Retrieval, Fusion, and Consolidation
Memory-Conditioned Diffusion Action Expert
The memory-augmented tokens condition a diffusion-based Transformer (DiT) policy, implemented with DDIM and 10 denoising steps, to predict a sequence of T=16 future 7-DoF actions. The architecture supports foresight and multi-step planning, with cognition-attention and perception-attention layers guiding semantic and fine-grained control, respectively.
Experimental Evaluation
Benchmarks and Setup
MemoryVLA is evaluated on three robots (Franka, WidowX, Google Robot) across 10 suites, 150+ tasks, and 500+ variations in both simulation and real-world settings.

Figure 4: Experimental setup: three simulation benchmarks and two real-world suites, spanning 150+ tasks and 500+ variations.
SimplerEnv Results
On SimplerEnv-Bridge (WidowX), MemoryVLA achieves 71.9% average success, a +14.6 point gain over CogACT-Large and surpassing π0. On SimplerEnv-Fractal (Google Robot), it attains 72.7% overall, outperforming CogACT by +4.6 points, with notable improvements on Open/Close Drawer and Put in Drawer tasks.
LIBERO Results
On LIBERO (Franka), MemoryVLA reaches 96.5% average success across five suites, exceeding CogACT by +3.3 points and outperforming π0, despite using only third-person RGB (no wrist or proprioceptive inputs).
Real-World Results
On 12 real-world tasks (six general, six long-horizon temporal), MemoryVLA achieves 85% and 83% success, respectively, outperforming CogACT by +9 and +26 points. Gains are especially pronounced on long-horizon tasks requiring temporal reasoning, such as Seq. Push Buttons (+43) and Change Food (+38).
Robustness and Generalization
MemoryVLA demonstrates strong robustness under out-of-distribution (OOD) conditions, maintaining high success rates across unseen backgrounds, distractors, lighting, objects, containers, and occlusions in both real-world and simulation. The largest performance degradation is observed under severe camera view changes.
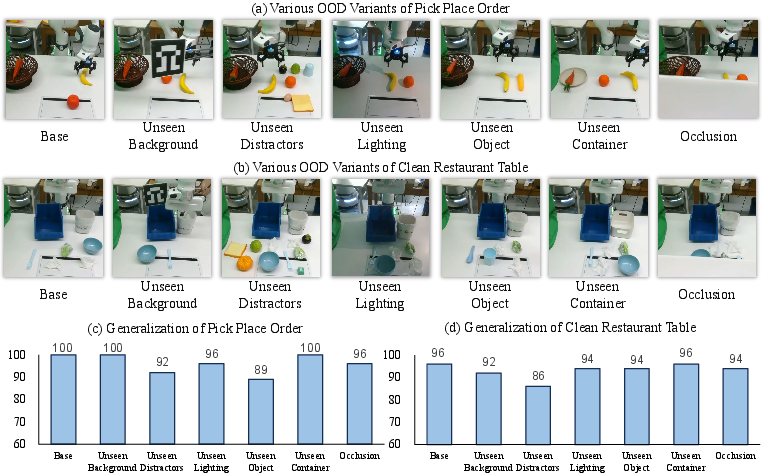
Figure 5: Real-world OOD robustness: MemoryVLA maintains high success rates across diverse variants.
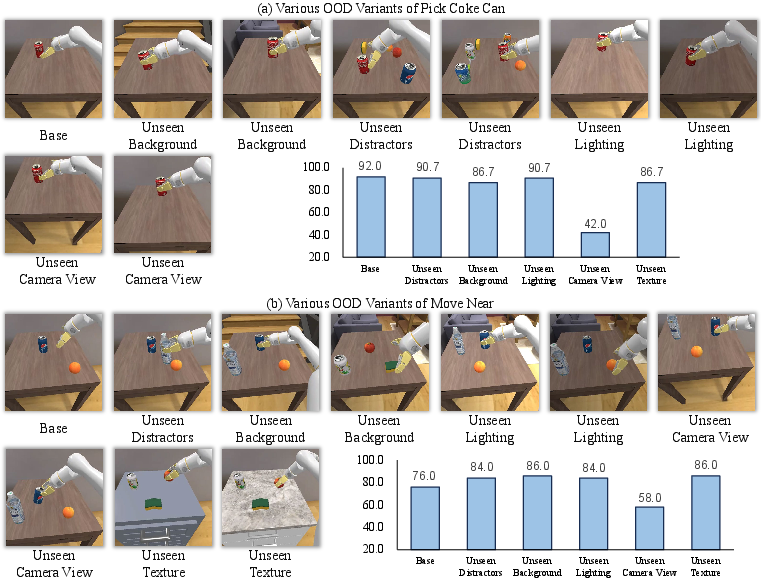
Figure 6: Simulation OOD robustness: strong generalization except for unseen camera views.
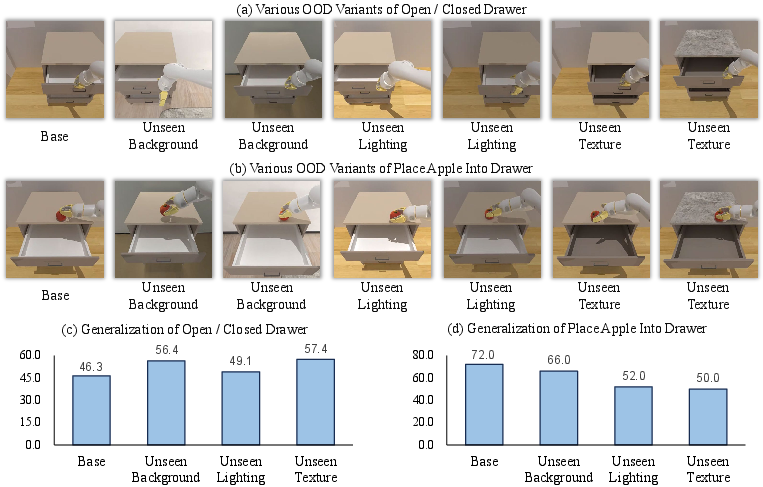
Figure 7: Simulation OOD robustness for hinge-like manipulation: moderate shifts are handled well, camera view changes cause notable drops.
Ablation Studies
Ablations on SimplerEnv-Bridge reveal:
- Combining perceptual and cognitive memory yields the highest success (71.9%).
- Optimal memory length is 16; shorter or longer lengths degrade performance.
- Timestep positional encoding, gate fusion, and token-merge consolidation each contribute positively to performance.
Qualitative Results
MemoryVLA produces coherent, temporally aware action sequences in both general and long-horizon tasks, as visualized in qualitative rollouts.
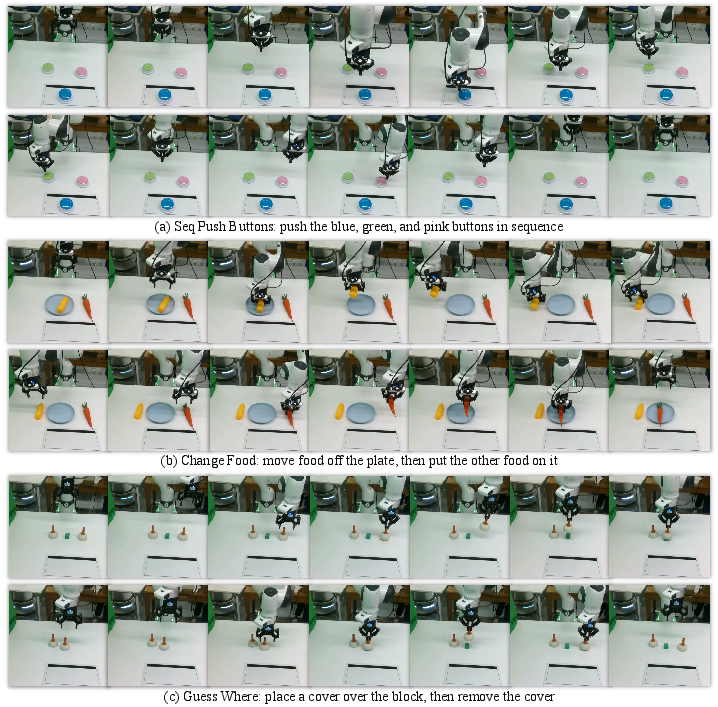
Figure 8: Real-world long-horizon temporal tasks: Seq Push Buttons, Change Food, Guess Where.

Figure 9: Real-world long-horizon temporal tasks: Clean Table Count, Pick Place Order, Clean Restaurant Table.

Figure 10: Real-world general tasks: Insert Circle, Egg in Pan, Egg in Oven, Stack Cups, Stack Blocks, Pick Diverse Fruits.

Figure 11: SimplerEnv-Bridge tasks: Spoon on Tower, Carrot on Plate, Stack Cube, Eggplant in Basket.

Figure 12: SimplerEnv-Fractal tasks: Pick Coke Can, Move Near, Open/Close Drawer, Put in Drawer.

Figure 13: LIBERO tasks: representative trajectories from all five suites.
Implementation Considerations
- Computational Requirements: Training requires 8 NVIDIA A100 GPUs, batch size 256, and a 7B VLM backbone. Inference uses DDIM with 10 steps for efficient trajectory generation.
- Data Modalities: Only third-person RGB and language instructions are used, simplifying deployment and reducing hardware dependencies.
- Memory Management: PCMB consolidation is critical for scalability, preventing memory bloat and maintaining salient information.
- Deployment: The architecture is compatible with ROS and standard RGB camera setups, facilitating real-world integration.
Implications and Future Directions
MemoryVLA establishes the importance of explicit temporal memory modeling in VLA frameworks, yielding substantial gains on long-horizon and OOD tasks. The dual-memory design, inspired by cognitive science, enables robust, generalizable manipulation policies without reliance on proprioceptive or wrist-camera inputs.
Future research directions include:
- Memory Reflection: Aligning long-term memory with LLM input space for embedding-space chain-of-thought reasoning.
- Lifelong Memory: Biologically inspired consolidation to distill frequently reused experiences into permanent representations, supporting scalable generalization across scenes, tasks, and embodiments.
Conclusion
MemoryVLA introduces a principled Cognition-Memory-Action framework for robotic manipulation, integrating perceptual and cognitive memory with diffusion-based action prediction. The approach achieves state-of-the-art performance across diverse benchmarks, demonstrating strong robustness, generalization, and real-world applicability. The explicit modeling of temporal dependencies is shown to be essential for long-horizon robotic control, and the architecture provides a foundation for future advances in memory-augmented embodied AI.