- The paper presents ManiAgent, a training-free framework that decomposes robotic manipulation into dedicated perception, reasoning, and control agents.
- It achieves high success rates in simulation (86.8%) and real-world experiments (95.8%), demonstrating robust performance in complex tasks.
- ManiAgent leverages caching and inter-agent communication for automated data collection, reducing reliance on costly human annotations.
ManiAgent: An Agentic Framework for General Robotic Manipulation
Motivation and Context
The ManiAgent framework addresses two persistent limitations in Vision-Language-Action (VLA) models for robotic manipulation: (1) dependence on large-scale, high-quality demonstration data, and (2) insufficient task intelligence for complex reasoning and long-horizon planning. Existing VLA approaches, while effective for direct mapping from multimodal inputs to actions, degrade under data scarcity and struggle with advanced planning, indirect instructions, and compositional reasoning. ManiAgent proposes a training-free, agentic architecture that leverages the capabilities of LLMs and Vision-LLMs (VLMs) through modular specialization and inter-agent communication, enabling robust, generalizable manipulation without additional demonstration data.
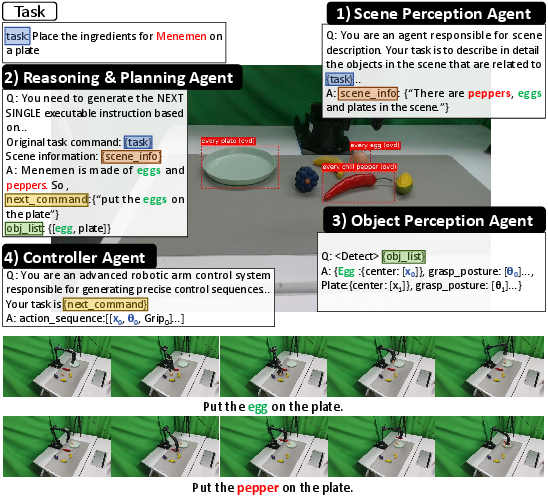
Figure 1: ManiAgent decomposes the Menemen ingredient-finding task into perception, reasoning, and execution handled by dedicated agents.
Framework Architecture
ManiAgent is structured as a multi-agent system, with each agent specializing in a distinct stage of the manipulation pipeline: perception, reasoning, and control. The framework operates in a closed-loop, end-to-end fashion, from task description and environmental input to executable robotic actions.
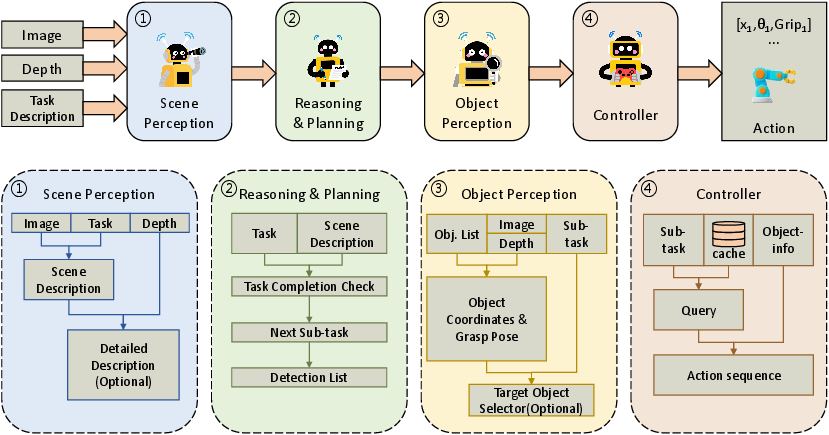
Figure 2: Overview of the ManiAgent framework, detailing the flow from perception to reasoning, object detection, and controller execution with caching.
Perception Agent
The perception agent utilizes a VLM to generate task-relevant scene descriptions from RGB images, depth maps, and user instructions. Prompt optimization is formalized as a multi-objective problem balancing recall (completeness of scene information) and relevance (task-specificity). When textual descriptions are insufficient, object detection networks (e.g., Florence-v2) are invoked to extract pixel coordinates, which are transformed into 3D spatial coordinates using camera calibration parameters. This enables precise localization and manipulation of objects, overcoming the limitations of LLMs in spatial reasoning.
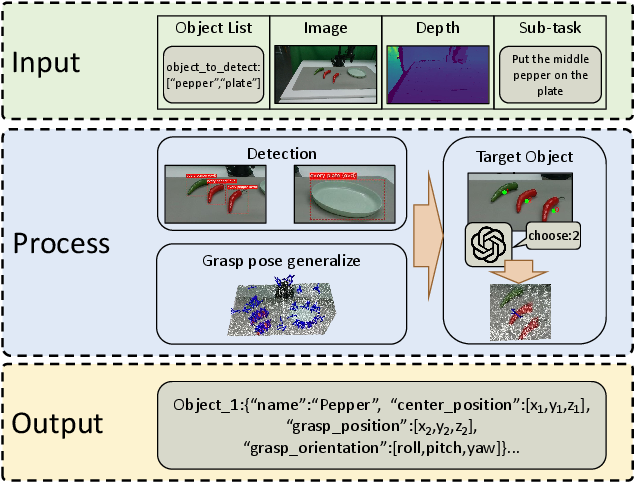
Figure 3: The perception module processes object lists, images, depth, and camera parameters to output object coordinates and grasping poses.
Reasoning Agent
The reasoning agent fuses scene descriptions with task instructions and LLM-embedded physical knowledge to perform incremental sub-task decomposition. This agent maintains historical memory to avoid local loops and adapts sub-task planning to the evolving scene, ensuring feasibility and robustness. Object lists for each sub-task are generated to guide the perception agent in subsequent detection and pose estimation.
Object Perception and Grasp Pose Generation
Open-vocabulary detection is performed using VLMs, with prompts designed to maximize recall (e.g., prefixing "every" to object names). Detected objects are disambiguated via sequential annotation and targeted prompts. Grasp poses are generated using AnyGrasp, selecting the highest-scoring pose within the object's neighborhood. Both center and grasp positions are output for downstream use.
Controller Agent and Caching
The controller agent translates sub-task descriptions and object details into executable action sequences using the LLM. Action generation is formalized as a sequencing problem over valid object center and grasp pose pairs. To mitigate LLM-induced latency, a caching mechanism stores parameterized action sequences for previously executed sub-tasks, enabling rapid retrieval and integration with current scene details. This design ensures consistency and efficiency in repeated or similar tasks.
Experimental Evaluation
Simulation Results
ManiAgent was evaluated on the SimplerEnv platform, using BridgeTable-v1 and BridgeTable-v2 environments. Across four representative tasks, ManiAgent (with GPT-5) achieved an average success rate of 86.8%, outperforming CogACT (51.3%) and Pi-0 (55.7%). Performance scaled with VLM capability, demonstrating effective conversion of perception-language-reasoning capacity into action success. Failure modes were primarily due to occlusion and depth-RGB misalignment, suggesting further improvements via detector-specific adjustments.

Figure 4: Task execution process in the SimplerEnv simulation environment.
Real-World Experiments
Physical experiments were conducted using a WidowX-250s robotic arm and Realsense D435 cameras. Eight tasks were designed to evaluate non-pick-and-place capability, generalization, relative position perception, intention reasoning, knowledge retrieval, and multi-step planning. ManiAgent achieved an average success rate of 95.8% with commercial VLMs (Claude-4-sonnet, Grok-4), while open-source models lagged due to format adherence issues. Notable observations included robust handling of indirect instructions, multi-step reasoning, and knowledge-based conventions (e.g., utensil placement etiquette).
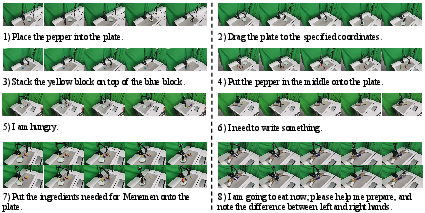
Figure 5: Definition and scenario examples of real-world manipulation tasks.
Comparative Analysis
ManiAgent was compared to ReKep on four physical tasks. Across all VLMs, ManiAgent exhibited substantial improvements in success rates (up to 75% higher), particularly in tasks requiring accurate pose estimation and long-horizon planning. ReKep's limitations in trajectory optimization and multi-step reasoning were evident, whereas ManiAgent's modular reasoning and pose generation enabled superior performance in complex, cluttered scenes.
Automated Data Collection
ManiAgent's reliability enables its use as an automated data collection tool for VLA training. The framework supports rule-based scene resets and coordinate-based task definitions, facilitating uniform data acquisition across scene positions. In practical deployment, ManiAgent collected 551 trajectories for a pick-and-place task, with an 81.51% success rate and minimal manual intervention (one every 46 minutes). Models trained on ManiAgent-collected data (e.g., CogACT) demonstrated comparable performance to those trained on human-annotated datasets, validating the framework's utility for scalable, high-quality dataset generation.

Figure 6: ManiAgent automates data collection, enabling efficient dataset generation and downstream VLA training.
Implementation Considerations
- Computational Requirements: ManiAgent relies on high-capacity VLMs and LLMs, with latency mitigated via caching. Real-time deployment requires GPU acceleration for perception and inference.
- Scalability: The modular agentic design supports extension to diverse platforms (e.g., mobile robots, multi-arm systems) and integration with additional sensors.
- Limitations: Performance is bounded by the underlying VLM/LLM capabilities and object detection accuracy. Scene occlusion and ambiguous instructions remain challenging.
- Deployment: The framework is training-free, enabling rapid deployment in new environments. Caching and prompt optimization further enhance efficiency.
Implications and Future Directions
ManiAgent demonstrates that agentic decomposition, leveraging specialized LLM/VLM agents, can overcome data and reasoning bottlenecks in general robotic manipulation. The framework's high success rates and automated data collection capabilities have direct implications for scalable VLA training, reducing reliance on costly human annotation. Theoretically, ManiAgent suggests that modular, closed-loop agentic architectures can generalize across diverse manipulation scenarios, provided sufficient perceptual and reasoning capacity.
Future work should focus on:
- Enhancing real-time feedback and closed-loop error recovery.
- Extending the framework to heterogeneous robotic platforms and multi-agent collaboration.
- Integrating human-robot interaction for adaptive task specification and correction.
- Improving robustness to occlusion, ambiguous instructions, and dynamic environments via advanced perception and reasoning modules.
Conclusion
ManiAgent introduces a modular, agentic framework for general robotic manipulation, achieving superior performance in both simulation and real-world tasks without reliance on demonstration data. Its architecture enables robust perception, reasoning, and control, with demonstrated advantages in complex task execution and automated data collection. ManiAgent provides a scalable foundation for future research in agentic robotics, VLA model training, and embodied intelligence.

