- The paper presents a modular framework that integrates pre-trained LLMs and VLMs via dynamic scene graphs to translate natural language commands into robotic actions.
- Its layered architecture separates perception, reasoning, interaction, and execution, achieving near-ceiling planning and robust spatial grounding.
- Experimental results show high task completion rates across various scenarios, though challenges remain with ambiguous instructions and complex, occluded scenes.
Foundation Model-Driven Long-Horizon Robotic Manipulation via Scene Graphs
Introduction and Motivation
This paper presents a modular framework for robotic manipulation that leverages multiple pre-trained foundation models—specifically, LLMs and VLMs—integrated via dynamically updated scene graphs. The system is designed to translate high-level natural language commands into executable robot actions without requiring task-specific training or fine-tuning. The architecture is layered, with each layer responsible for a distinct aspect of the perception-planning-execution pipeline, and scene graphs serving as the central world model for spatial and semantic reasoning.
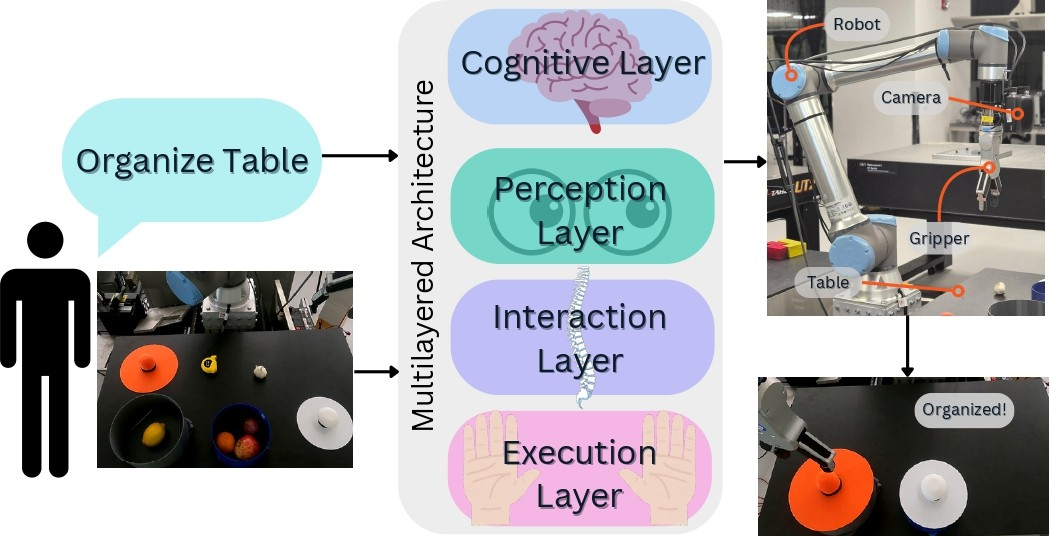
Figure 1: Overview of the framework, illustrating the translation of user commands into robot actions through layered model integration.
Layered Framework Architecture
The framework is implemented in ROS2 and comprises four principal layers:
- Perception Layer: Utilizes a VLM (Qwen2.5-VL) with RGB-D input for object localization, spatial reasoning, and semantic scene description. The VLM is queried for bounding boxes and specific points, which are projected into 3D coordinates for manipulation.
- Cognitive Layer: Employs a reasoning-oriented LLM (Gemini 2.5 Pro) for long-horizon, constraint-aware task sequencing, integrating scene graph information and tool definitions.
- Interaction Layer: Uses a fast, non-reasoning LLM (GPT-4.1) for natural language interpretation, function calling, and coordination of execution steps, including dynamic re-planning and user interaction.
- Execution Layer: Relies on a GPU-accelerated motion planner (Nvidia cuRobo) and controller for robust, collision-free trajectory generation and precise object manipulation.
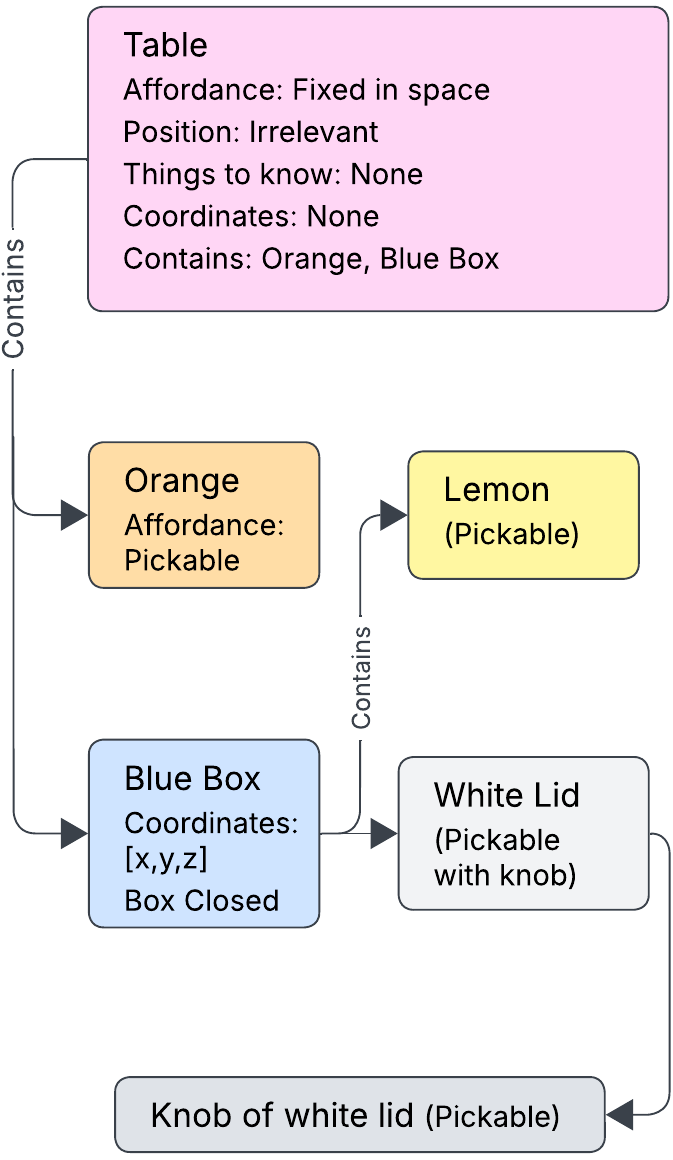
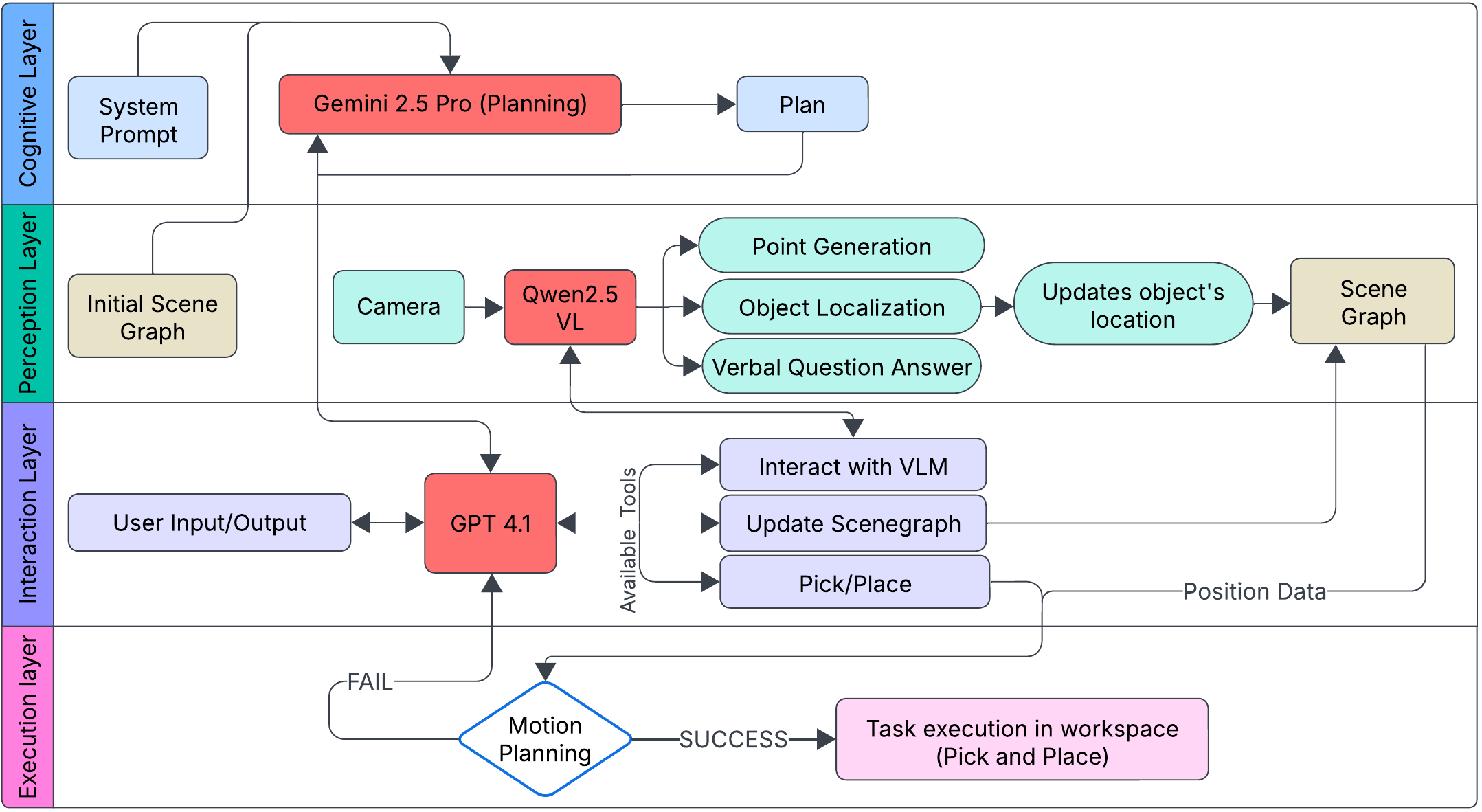
Figure 2: (a) Scene graph structure encoding spatial and semantic relations. (b) System architecture with bottom-up hierarchy from execution to cognitive layers.
Scene graphs, implemented via NetworkX and represented in hierarchical JSON, encode object properties, affordances, positions, and containment relations. They are updated online as perception outputs and manipulation actions occur, ensuring persistent and accurate world modeling.
Perception and Spatial Reasoning
The perception layer's VLM is queried in two modes:
- Bounding Box Localization: The LLM first verifies object presence to avoid hallucinations, then requests bounding boxes from the VLM. These are mapped to 3D coordinates using depth data and multi-view point cloud reconstruction, enabling precise grasping and placement.
- Specific Point Queries: For tasks such as "place the lid at a free spot," the VLM outputs pixel coordinates, which are projected into 3D space for direct placement.
Qwen2.5-VL demonstrates strong generalization to novel objects and affordances, supporting robust spatial reasoning in cluttered and ambiguous scenes without retraining.


Figure 3: (a) VLM localizes fine-grained affordances (lid knobs). (b) VLM identifies a temporary placement location for the lid.
Planning and Task Sequencing
The cognitive layer (Gemini 2.5 Pro) generates exhaustive, multi-step plans by integrating user goals, scene graph state, and available tool definitions. The separation of planning (reasoning LLM) from execution (non-reasoning LLM) enables advanced reasoning for long-horizon tasks while maintaining fast, reliable control.
The interaction layer (GPT-4.1) orchestrates execution by calling motion primitives, perception queries, and scene graph updates as specified in the plan, handling feedback and failure cases with dynamic re-planning.
Experimental Evaluation
Experiments span three classes:
- Fundamental Capabilities (Exp. I): Tasks include relative positioning ("move the orange between the apple and yarn"), semantic clustering ("move the lone isolated fruit near the other fruits"), outlier detection, and recipe-based selection. The framework demonstrates stable LLM-VLM dialogue and accurate spatial localization, with performance sensitive to the specificity of user instructions.





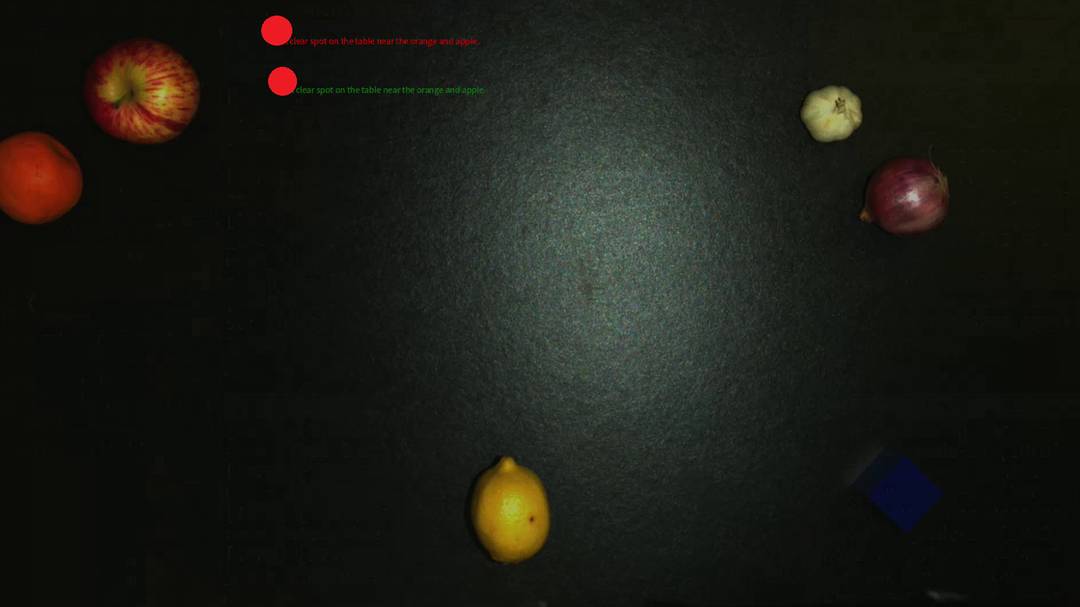
Figure 4: I-A: Orange moved between apple and yarn; VLM identifies "in-between" point. I-B: Lemon shifted to correct cluster; VLM provides feasible points.




Figure 5: I-C: Non-edible object selected as outlier. I-D: Robot picks only ingredients required for fried noodles.
- Structured Benchmark-Inspired Scenarios (Exp. II): Block stacking and Tower of Hanoi tasks test iterative spatial reasoning and constraint-aware sequencing. The framework successfully interprets both concrete and abstract user directives, updating the scene graph and adhering to logical constraints.






Figure 6: II-A: Blocks stacked into a tall structure. II-B: Tower of Hanoi solved stepwise, respecting puzzle rules.
- Advanced Reasoning and Occlusion Handling (Exp. III): Autonomous sorting, table organization, and occlusion scenarios require multi-step reasoning, semantic categorization, and affordance localization. The system infers implicit goals from underspecified commands ("organize the table"), detects inconsistencies, and handles occlusions by leveraging VLM affordance localization.


Figure 7: III-A: Items sorted into boxes by inferred categories (fruits vs. vegetables).






Figure 8: III-B: Misplaced lemon transferred; table organized; boxes closed. III-C: Occlusion handled by opening toolbox, placing lid at VLM-identified point, and proceeding with organization.
Quantitative Results and Analysis
Across 10–20 trials per experiment, the framework achieves:
- Planning Feasibility (PF): ≥95% in all but the most complex occlusion scenario (III-C: 80%).
- Task Completion Rate (TCR): 100% for fundamental and structured tasks; reduced in ambiguous (I-B1: 20%) and cluttered/occluded scenes (III-B: 75%, III-C: 60%).
- Scene Graph Handling (SGH): 100% in all cases.
Failures are concentrated in cases of ambiguous language (insufficient context for VLM queries) and increased physical complexity (collisions with manipulatable objects not modeled as dynamic obstacles). The layered design mitigates error propagation and supports robust world-model maintenance.
Implementation Considerations
- Computational Requirements: The framework requires access to high-capacity LLMs and VLMs via API, a GPU for motion planning, and a 3D camera for perception. Real-time performance is achieved by decoupling slow reasoning from fast execution.
- Scalability: The modular ROS2 implementation supports extension to more dexterous manipulation and additional perception modalities.
- Limitations: Sensitivity to linguistic ambiguity and lack of dynamic obstacle modeling at the execution layer are primary bottlenecks. VLM performance degrades in highly cluttered scenes or with underspecified queries.
Implications and Future Directions
The integration of foundation models with structured scene graphs enables generalizable, adaptable robotic manipulation without task-specific training. This approach occupies a middle ground between data-intensive VLA models and brittle LLM/VLM-only planners, supporting long-horizon, semantically constrained tasks with robust spatial grounding.
Future work should address dexterous manipulation, dynamic obstacle modeling, and further exploitation of VLMs for deformable and complex objects. The framework's modularity facilitates rapid adaptation to new tasks and environments, suggesting a scalable path toward general-purpose robotic agents.
Conclusion
This study demonstrates that a layered framework combining foundation models and scene graphs can reliably translate natural language instructions into long-horizon robotic manipulation actions. The system achieves near-ceiling planning and scene graph handling, strong perceptual generalization, and robust execution across diverse tasks. Remaining challenges include handling linguistic ambiguity and dynamic physical interactions. The proposed architecture provides a practical foundation for scalable, semantically informed robotic manipulation systems.