- The paper introduces a dual-system framework that separates high-level reasoning from low-level action, leveraging reinforced visual latent planning for multi-step task execution.
- It utilizes a Q-Former-based latent projector and reinforcement learning to fine-tune actions, achieving performance gains of up to 16.9% over state-of-the-art baselines.
- Experimental results demonstrate enhanced few-shot adaptation, long-horizon planning, and self-correction capabilities, confirming its robustness in embodied tasks.
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Introduction and Motivation
ThinkAct addresses the limitations of current Vision-Language-Action (VLA) models in embodied reasoning, particularly their inability to perform explicit, structured planning and adapt to complex, long-horizon tasks. Existing VLA approaches typically map multimodal inputs directly to actions in an end-to-end fashion, which restricts their capacity for multi-step reasoning, generalization, and self-correction. ThinkAct introduces a dual-system framework that explicitly separates high-level reasoning from low-level action execution, leveraging reinforced visual latent planning to bridge the gap between abstract reasoning and physical action.

Figure 1: ThinkAct enables few-shot adaptation, long-horizon planning, and self-correction in embodied tasks by reinforcing reasoning with action-aligned visual feedback.
Methodology
Dual-System Architecture
ThinkAct consists of two primary modules:
- Reasoning MLLM (Fθ): A multimodal LLM that generates high-level reasoning plans, producing both intermediate reasoning steps and a visual plan latent (ct) that encodes spatial-temporal intent.
- Action Model (πϕ): A Transformer-based policy (e.g., DiT-based diffusion policy) that conditions on the visual plan latent to generate executable actions in the target environment.
This architecture allows asynchronous operation, where the reasoning module can "think slowly" while the action module executes "fast control," supporting both deliberative planning and real-time action.
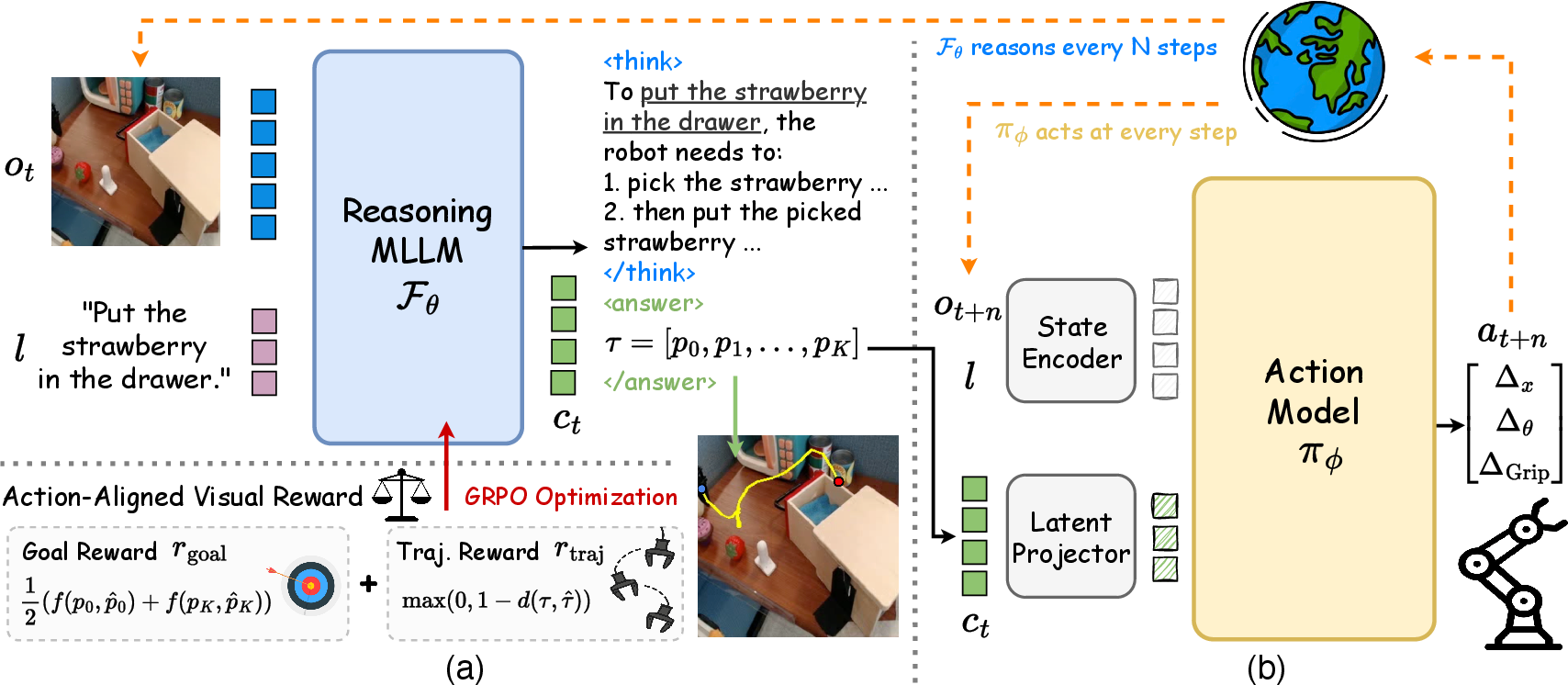
Figure 2: Overview of ThinkAct’s dual-system: (a) Reasoning MLLM generates visual plan latents with action-aligned rewards; (b) Action model executes actions conditioned on the latent plan.
Reinforced Visual Latent Planning
ThinkAct advances the use of reinforcement learning (RL) to incentivize embodied reasoning in the MLLM. The RL objective is shaped by action-aligned visual feedback, which consists of:
- Goal Reward (rgoal): Measures the alignment between predicted and ground-truth start/end positions of the gripper trajectory.
- Trajectory Reward (rtraj): Enforces distributional similarity between predicted and demonstrated trajectories using dynamic time warping (DTW).
- Format Reward (rformat): Ensures output format correctness.
The total reward is a weighted sum of these components, with action-aligned visual feedback being the dominant term. Group Relative Policy Optimization (GRPO) is used for RL fine-tuning, sampling multiple candidate reasoning traces and optimizing for those with higher visual rewards.
Reasoning-Enhanced Action Adaptation
The action model is conditioned on the visual plan latent via a Q-Former-based latent projector. During adaptation, only the action model and projector are updated via imitation learning, while the reasoning MLLM remains frozen. This design enables efficient few-shot adaptation to new environments and tasks, as the high-level intent encoded in the latent plan provides strong guidance for low-level control.
Experimental Results
Robot Manipulation and Embodied Reasoning
ThinkAct is evaluated on SimplerEnv and LIBERO for manipulation, and on EgoPlan-Bench2, RoboVQA, and OpenEQA for embodied reasoning. The framework consistently outperforms strong baselines and recent state-of-the-art models across all benchmarks.
Qualitative Analysis
Qualitative results highlight ThinkAct’s capacity for structured reasoning, long-horizon decomposition, and trajectory planning. RL fine-tuning is shown to significantly improve the quality and correctness of reasoning traces, as evidenced by comparisons before and after RL.

Figure 4: Comparison of reasoning and answers with and without RL; RL-tuned ThinkAct produces more accurate and context-aware responses.
Few-Shot Adaptation
ThinkAct demonstrates strong few-shot adaptation on LIBERO, outperforming Magma by 7.3% on goal variation and 9.5% on spatial variation with only 10 demonstrations per task.
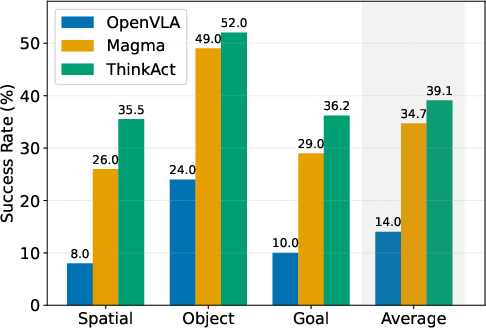
Figure 5: Few-shot adaptation results on LIBERO, showing ThinkAct’s superior generalization with limited data.
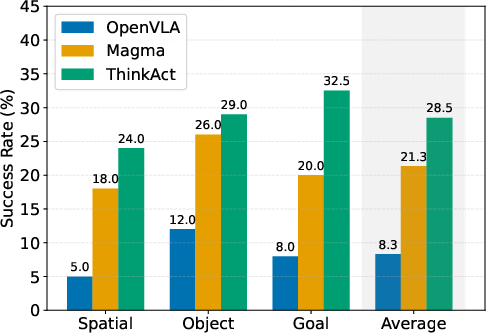
Figure 6: 5-shot adaptation results on LIBERO, further confirming ThinkAct’s data efficiency.
Self-Reflection and Correction
The reasoning MLLM in ThinkAct can detect execution failures and replan accordingly by leveraging temporal context. This enables the agent to recover from errors, such as regrasping a dropped object and completing the task successfully.

Figure 7: Self-reflection and correction: the robot detects a failure and generates a revised plan to recover.

Figure 8: Additional demonstrations of ThinkAct’s self-correction capability in diverse manipulation scenarios.
Ablation Studies
Ablation experiments confirm that both the goal and trajectory rewards are critical for effective planning and reasoning. Removing either component leads to a measurable drop in performance, and excluding both reduces the model to near-supervised baseline levels.
Implications and Future Directions
ThinkAct demonstrates that explicit, RL-incentivized reasoning—grounded in action-aligned visual feedback—substantially improves the generalization, adaptability, and robustness of embodied agents. The dual-system architecture, with its separation of reasoning and action, provides a scalable paradigm for integrating deliberative planning with efficient control. The strong few-shot adaptation and self-correction capabilities suggest practical utility in real-world robotics, assistive systems, and dynamic environments.
The reliance on pretrained MLLMs introduces limitations, particularly susceptibility to hallucinations in visual or spatial reasoning. Future research should explore grounding-aware training, hallucination suppression, and tighter integration between reasoning and perception to further enhance reliability. Additionally, the framework’s modularity invites extensions to hierarchical planning, multi-agent coordination, and real-world deployment with safety constraints.
Conclusion
ThinkAct establishes a new standard for vision-language-action reasoning by combining reinforced visual latent planning with reasoning-enhanced action adaptation. The framework achieves state-of-the-art results on a range of embodied reasoning and manipulation benchmarks, with strong evidence for improved long-horizon planning, few-shot generalization, and emergent self-correction. The approach provides a robust foundation for the development of more deliberative, adaptable, and reliable embodied AI systems.


