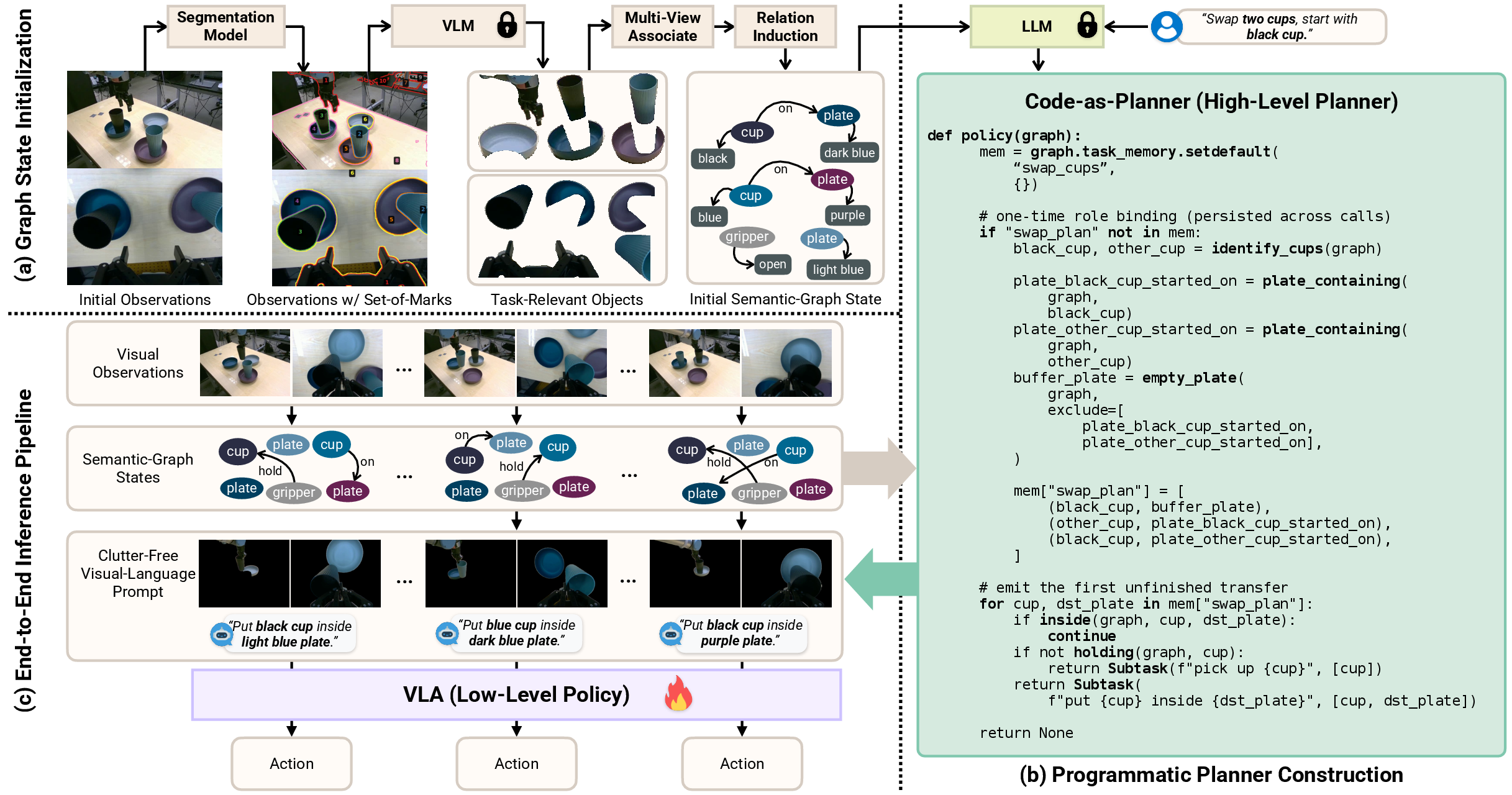
- The paper introduces a hierarchical framework that combines a persistent semantic-graph state with a code-as-planner mechanism to improve non-Markovian vision-language-action control.
- The paper demonstrates that clutter-suppressed visual prompts and structured subtask decomposition lead to higher success rates, achieving 81.7% task performance on real-world manipulations.
- The paper shows through ablation studies that removing clutter-free prompts significantly degrades performance, underscoring the importance of robust visual grounding for fine-grained manipulation.
CodeGraphVLP: Hierarchical Non-Markovian Vision-Language-Action Control via Programmatic Planning and Semantic-Graph State
Motivation and Context
Generalist Vision-Language-Action (VLA) models have advanced robotic manipulation by fusing visual and linguistic modalities to predict actions. However, conventional VLAs assume a Markovian environment, relying solely on the latest observation and instruction. In real-world, long-horizon tasks, observability is partial, evidence can be occluded, and cluttered workspaces exacerbate brittle grounding. Non-Markovian dependencies—where action selection relies on temporally distant information—challenge existing memory-augmented and hierarchical VLM–VLA approaches due to trade-offs between memory capacity, efficiency, and real-time inference latency.
CodeGraphVLP Architecture
CodeGraphVLP introduces a hierarchical framework integrating a persistent semantic-graph state with a code-as-planner mechanism and progress-guided visual-linguistic prompting. The approach decomposes task execution into three architectural pillars:
Semantic-Graph State Construction and Maintenance
The semantic-graph state is characterized as Gt=(Vt,Et), where nodes are task-relevant objects (with semantic, spatial, and attribute information) and edges denote spatial or functional relations (e.g., in, on, near). Initialization uses YOLOE for segmentation and Set-of-Mark prompting with VLMs for object relevance filtering. Multi-view association aligns objects across disparate camera feeds, combining CLIP-based semantic similarity and geometric distance signatures. Relation induction applies proximity and containment heuristics on segmentation masks. Online updates leverage Cutie for tracking, periodic re-segmentation, and dynamic association—all maintaining compactness and robustness under partial observability and clutter.
Programmatic Planning via Executable Code
A novel aspect is instantiating the planner as an LLM-synthesized executable that interacts with the semantic-graph API. It amortizes inference cost by performing a one-time synthesis, thereafter operating via lightweight graph queries and predicate checks. The planner encapsulates:
- Helper routines for object and relation queries
- Boolean predicates encoding task constraints and completion conditions
- Policy(graph) logic that tracks subtask progress via persistent memory and outputs subtask instruction (ltsub) and subtask-relevant objects (Otrel)
The planner’s persistent task memory allows fine-grained progress tracking and avoidance of redundant actions, supporting robust execution in non-Markovian settings.
Clutter-Free Visual-Language Prompting
To address clutter-induced grounding failures, CodeGraphVLP constructs masked observations focusing only on the objects identified by the planner as relevant for the immediate subtask. The VLA executor is conditioned on:
- Subtask Language Cue: Planner-produced imperative instruction aligning linguistic context with the current grounded subtask.
- Clutter-free Visual Cue: Masked RGB frames retaining only regions corresponding to relevant objects.
This input alignment, performed consistently during training and deployment, enhances robustness in dense and distractor-heavy environments.
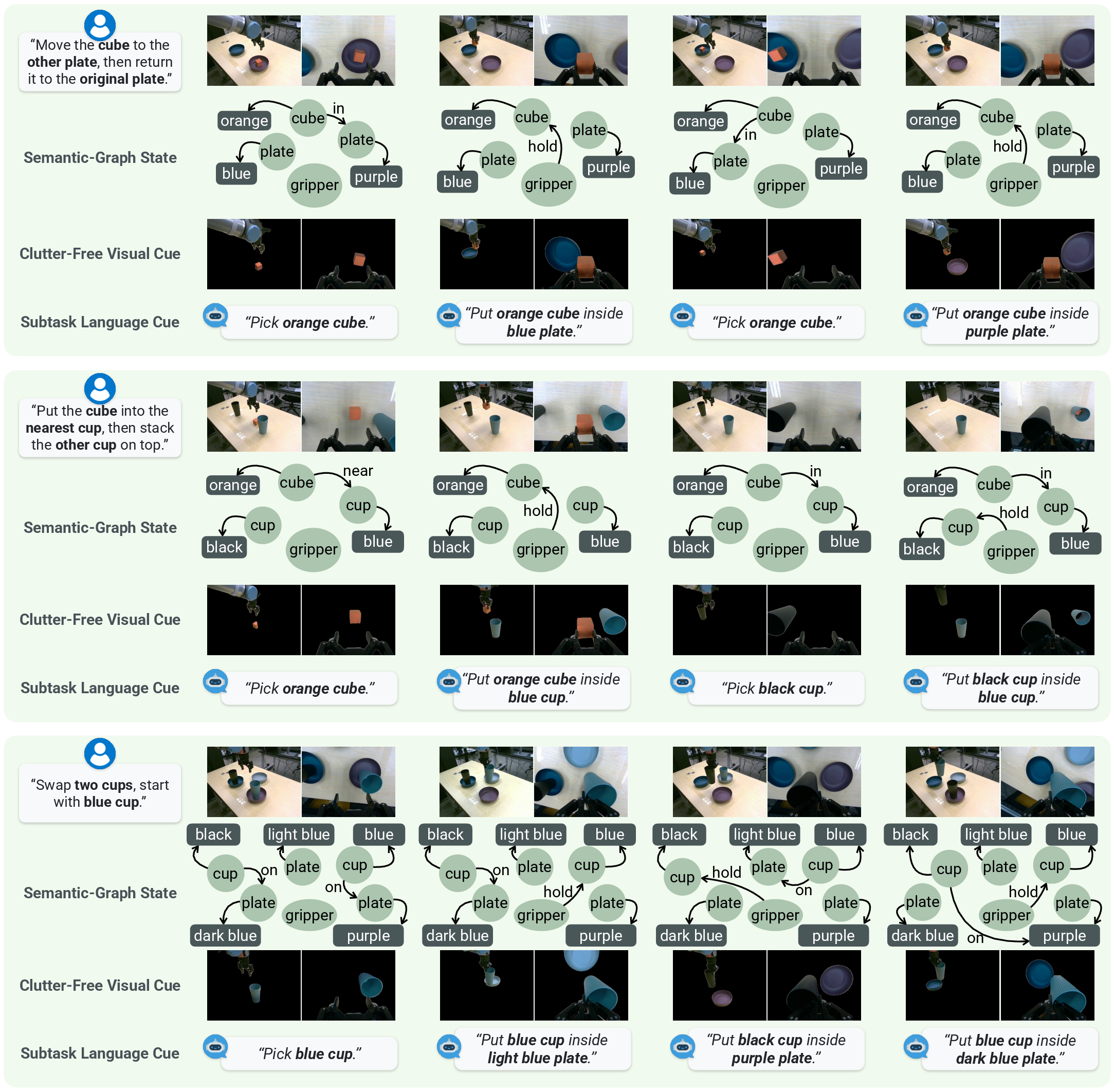
Figure 2: Qualitative rollouts on long-horizon tabletop tasks, illustrating semantic-graph evolution and clutter-free prompting for the VLA executor.
Empirical Evaluation
Experiments are conducted on a UR10e manipulator with dual camera feeds. Three real-world, non-Markovian manipulation tasks are used: Pick-and-Place Twice (history-dependent), Place-and-Stack (occlusion-driven dependency), and Swap Cups (multi-step, buffer-dependent swapping with initial-state memory requirements). Baselines include state-of-the-art VLAs (autoregressive and flow-based), memory-augmented variants, and hierarchical VLM–VLA systems.
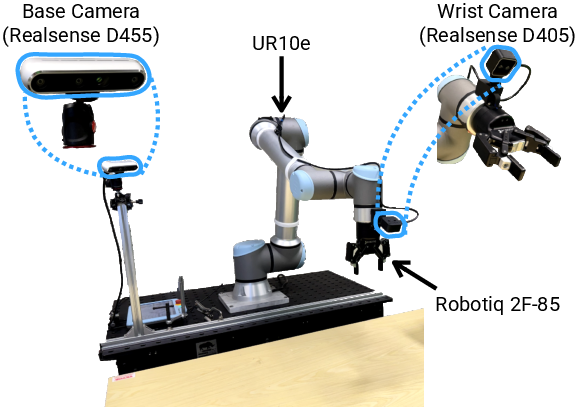
Figure 3: Robot setup with global and wrist-mounted views, integral for multi-view semantic-graph construction.
Summary of Results:
- Success Rate: CodeGraphVLP delivers average task success rates of 81.7%, exceeding all baselines, including history-enabled and hierarchical alternatives.
- Partial Completion Metrics: Superior intermediate milestone achievement highlights improved subtask reliability.
- Ablation Studies: Removing clutter-free visual prompts reduces Swap Cups success from 85% to 40%. Switching to VLM-in-the-loop planning increases latency (up to 3.142 s/step) while impairing reliability, compared to Code-as-Planner’s 0.328 s/step and 85% success.
Implications and Future Directions
CodeGraphVLP demonstrates that explicit, persistent semantic memory and programmatic planning significantly enhance non-Markovian manipulation performance. The structured approach provides interpretable progress tracking, amortizes LLM inference cost, and supports real-time deployment. Grounded clutter-free prompting ensures robustness in complex scenes, circumventing the limitations of unstructured memory or repeated VLM queries.
Technical implications include:
- Disentangling progression estimation from low-level action execution enables efficient scaling to longer-horizon tasks.
- Automation of planner synthesis via LLMs facilitates domain adaptation, contingent on reliable prompt design and foundation model fidelity.
- The semantic-graph paradigm opens avenues for compositional reasoning, multi-agent collaboration, and open-vocabulary manipulation.
Challenges remain in semantic-graph construction—particularly open-world robustness, attribute reliability, and scalable relation induction under dynamic observations. Future research may focus on joint optimization of semantic-graph maintenance and VLA execution, automated code planner verification, and extension to diverse embodied task domains beyond tabletop manipulation.
Conclusion
CodeGraphVLP provides a holistic, hierarchical control framework for non-Markovian vision-language-action systems, integrating structured semantic state, efficient programmatic planning, and robust clutter-suppressed prompting. Empirical results underscore substantial gains in both reliability and latency over standard and memory-augmented baselines. These advances position CodeGraphVLP as a viable paradigm for deploying generalist manipulation agents in real-world, long-horizon, partially observable environments (2604.22238).