ManualVLA: A Unified VLA Model for Chain-of-Thought Manual Generation and Robotic Manipulation
Abstract: Vision-Language-Action (VLA) models have recently emerged, demonstrating strong generalization in robotic scene understanding and manipulation. However, when confronted with long-horizon tasks that require defined goal states, such as LEGO assembly or object rearrangement, existing VLA models still face challenges in coordinating high-level planning with precise manipulation. Therefore, we aim to endow a VLA model with the capability to infer the "how" process from the "what" outcomes, transforming goal states into executable procedures. In this paper, we introduce ManualVLA, a unified VLA framework built upon a Mixture-of-Transformers (MoT) architecture, enabling coherent collaboration between multimodal manual generation and action execution. Unlike prior VLA models that directly map sensory inputs to actions, we first equip ManualVLA with a planning expert that generates intermediate manuals consisting of images, position prompts, and textual instructions. Building upon these multimodal manuals, we design a Manual Chain-of-Thought (ManualCoT) reasoning process that feeds them into the action expert, where each manual step provides explicit control conditions, while its latent representation offers implicit guidance for accurate manipulation. To alleviate the burden of data collection, we develop a high-fidelity digital-twin toolkit based on 3D Gaussian Splatting, which automatically generates manual data for planning expert training. ManualVLA demonstrates strong real-world performance, achieving an average success rate 32% higher than the previous hierarchical SOTA baseline on LEGO assembly and object rearrangement tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
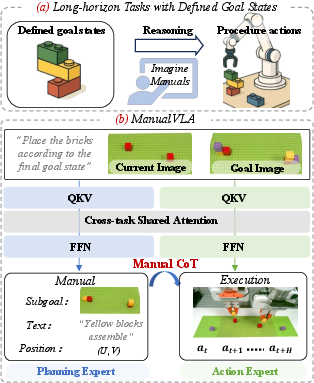
This paper introduces ManualVLA, a robot “brain” that can understand what a final goal should look like (like a finished LEGO model or a neatly arranged box of items), figure out the steps to get there, and then carry out those steps with its arms. Instead of jumping straight from seeing the goal to moving, the robot first creates its own “manual” — a simple, step-by-step plan — and then uses that manual to guide its actions.
The main questions the paper asks
- How can a robot turn a picture of a desired final state (the “what”) into the step-by-step procedure (the “how”) needed to reach it?
- Can the robot plan and act for long, multi-step tasks (called long-horizon tasks), like building 3D LEGO structures or neatly rearranging many objects?
- Can this work well in the real world, not just in simulations, while needing fewer human demonstrations?
How the system works (in everyday terms)
Think of ManualVLA like a team inside one robot:
- A “planning expert” writes a mini manual for the next step.
- An “action expert” uses that manual to move the robot’s arms safely and precisely.
Here’s what the robot’s manual looks like:
- A short text instruction (which object to handle and what to do).
- A picture of the next subgoal (what the scene should look like after the next step).
- Pixel coordinates (U, V) on the image showing exactly where an object should go.
Together, these act like recipe instructions plus a photo plus a map pin.
To connect planning and acting, the robot uses a “Manual Chain-of-Thought”:
- Explicit guidance: It places a visible marker (a mask) at the target (U, V) position on the current image, so the action expert can see where to go — like circling the spot on a photo.
- Implicit guidance: The planning expert also passes along hidden features (think “under-the-hood hints”), which help the action expert understand what to do even when the visible marker isn’t enough.
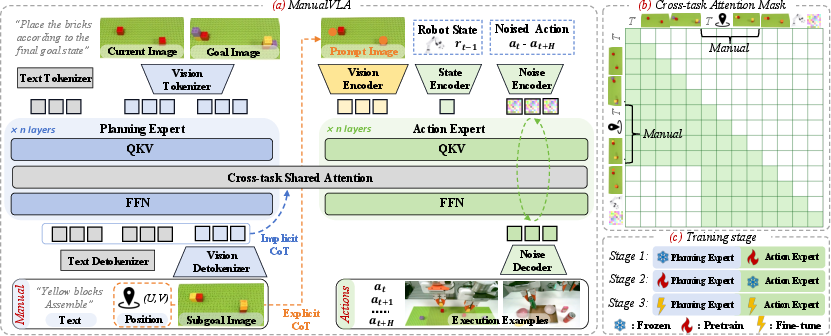
Under the hood, ManualVLA uses a Mixture-of-Transformers (MoT) architecture. Imagine two specialized teams (planning and action) living inside one shared brain. Each team has its own parameters but can “look” at the other’s thoughts through shared attention. That way, planning and acting stay coordinated.
How it’s trained:
- The action expert is pretrained on a huge set of robot movements (over 400,000 examples) so it learns general skills for moving and grasping.
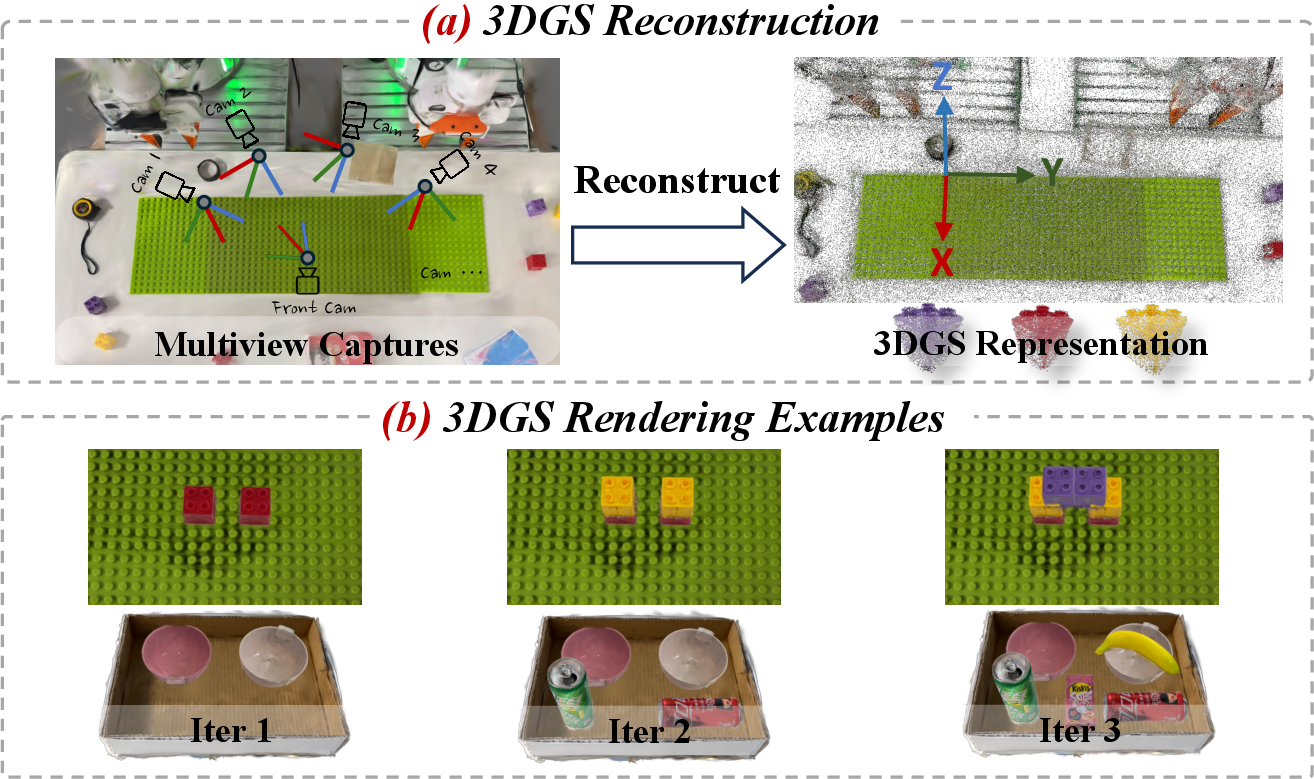
- The planning expert is trained using automatically generated manuals created with a “digital twin” tool. This tool, based on 3D Gaussian Splatting, builds a lifelike 3D copy of the scene from photos and then simulates many intermediate steps, producing realistic images and labels without lots of manual effort.
- Finally, the whole system is fine-tuned together on a small number of real demonstrations (about 100 per task), making it data-efficient.
Plain-language explanations of terms:
- Vision–Language–Action (VLA): A model that combines sight (camera images), language (instructions), and actions (robot controls).
- Chain-of-Thought: A step-by-step way of reasoning; here, the robot first creates steps (the manual) and then follows them.
- Mixture-of-Transformers (MoT): One model that contains two specialized sub-models (experts), which share information to work better together.
- 3D Gaussian Splatting: A way to make a quick, realistic 3D version of a scene from many photos, useful for generating training images.
- Diffusion-based action generation: A technique for producing smooth, precise movement commands by “denoising” actions over several steps.
What the researchers found and why it matters
- ManualVLA completes long, multi-step tasks much better than strong existing methods. In real-world tests (LEGO assembly and object rearrangement), it had about 32% higher success rates than the previous best hierarchical baseline.
- It plans clear intermediate steps (manuals) and turns them into accurate movements. Even if the manual has small errors, the combined explicit and implicit guidance helps the robot still do the right thing.
- It generalizes well: it works when backgrounds, lighting, or object shapes change, and it also performs strongly on a standard simulation benchmark (RLBench), achieving the best average success rate among compared methods.
- It’s data-efficient: after big pretraining, it only needs around 100 demonstrations per task to adapt to new tasks.
In short, making the robot write and use its own manual helps it stay on track across many steps, keeping precision high from start to finish.
What this could mean for the future
- More reliable household and factory robots: Robots could assemble products, sort and organize items, or set up rooms by reading a final goal and planning their own steps.
- Lower human effort: Instead of recording human hand videos or writing detailed instructions, the robot can generate the manuals it needs.
- Safer, more precise manipulation: The explicit maps (target markers) and implicit reasoning reduce mistakes like misplacing a brick or colliding objects.
- A general framework: The idea of “plan with a manual, then act” could be applied to many complex tasks, from warehouses to home assistance, making robots more independent and trustworthy.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps and open questions that remain after this paper, framed to enable actionable follow-ups by future researchers.
- Subgoal granularity and detection: The paper relies on a heuristic (change in text output) to decide when to generate a new manual; there is no principled method to detect subgoal completion or choose step granularity. How can we formalize criteria for subgoal boundaries, completion checks, and adaptive step sizing?
- 6-DoF and orientation-aware manuals: Position prompts are 2D pixel coordinates; orientation, height, and contact geometry are not modeled, especially problematic for 3D LEGO assembly and insertion-like tasks. What is the impact of adding 6-DoF poses and contact state constraints to manuals, and how should these be encoded?
- Prompt design space: The explicit CoT uses overlay masks from ; alternatives (heatmaps, keypoint sets, bounding boxes, segmentation, affordance maps, 3D point-cloud prompts) are not explored. Which prompt types maximize action accuracy and robustness across tasks and viewpoints?
- Implicit CoT interpretability and auditing: The cross-task attention mask provides latent conditioning, but its internal mechanisms remain opaque. Can we quantify and visualize how manual tokens influence action tokens (e.g., attention maps, causal attributions) and isolate which manual components drive action improvements?
- MoT routing strategy: Tokens are assigned to the planning vs action expert by fixed sequence design; dynamic routing or learned gating is not studied. Would token-level or segment-level adaptive routing (e.g., top-k experts, conditional compute) improve performance or efficiency?
- Compute, memory, and latency: The paper does not report inference time, compute footprint, or timing under dual-arm control. What are the real-time constraints and trade-offs (MoT vs MoE, diffusion vs autoregressive) on embedded or edge hardware?
- Bimanual coordination learning: The system alternates arms to reduce collisions but does not learn a coordination policy. How can we learn arm assignment, synchronization, and collision-aware scheduling end-to-end, including grasp handoffs and cooperative manipulation?
- Safety and constraint handling: There is no explicit collision checking, force/torque constraint modeling, or safety guarantees. How can we incorporate physics constraints, safe set control, or certified policies for long-horizon manipulation under uncertainty?
- Sensor modality limits: Inputs are single front-view RGB and robot state; depth, multi-view, tactile, and force sensing are not used. What is the effect of adding these modalities on robustness to occlusions, lighting, clutter, and viewpoint changes?
- Generalization breadth: Real-world evaluation is limited to LEGO assembly and object rearrangement on a dual-arm Franka; cross-robot, cross-gripper, and diverse household/industrial tasks are not tested. How well does ManualVLA transfer across embodiments, gripper types, and more complex assemblies (tools, fasteners, deformables)?
- Domain gap quantification (digital twin → real): The 3DGS digital twin generates manuals, but the sim2real gap is unquantified. How close are synthetic manuals to real-world conditions, and how can we calibrate or adapt manuals to mitigate distribution shift (transparent, reflective, deformable, cluttered objects)?
- Data efficiency and scaling laws: The claim of 100 demos per task is not accompanied by data-scaling ablations. What are the performance curves vs. number of demos, pretraining sizes, and manual dataset scale, and how does data composition affect downstream generalization?
- Error detection and recovery: ManualVLA is said to be robust to “moderate manual errors,” but mechanisms for detecting erroneous manuals and triggering replanning or correction are unspecified. Can we add explicit error monitors and recovery policies?
- Subgoal feasibility checks: Generated manuals are evaluated with PSNR/FID/MAE but not with physical feasibility metrics (reachability, collision risk, stability). How can we introduce feasibility prediction or verification into manual generation?
- Position tokenization and precision: Coordinates are supervised via tokenized cross-entropy; discretization resolution, calibration, and quantization effects on fine-grained placement accuracy are not analyzed. What encoding (continuous vs token, mixed precision) yields best control fidelity?
- Action chunk length and adaptivity: The action expert outputs chunks of length h, but h and its effects on stability, feedback frequency, and error accumulation are not studied. How should chunking be adapted online based on task complexity or uncertainty?
- Long-context limits: The claimed “long-context interactions” across manuals and actions lack an analysis of context window limits, degradation over very long horizons, and memory mechanisms. How does performance scale with sequence length, and can retrieval or external memory help?
- Goal specification forms: Final goals are images; textual goals, partial constraints, or symbolic specifications (e.g., “stack red on blue maintaining clearance”) are not explored. How can ManualVLA plan and act from non-image goals or mixed goal modalities?
- Robustness to dynamics: All tasks are quasi-static; moving objects, humans-in-the-loop, or time-varying constraints are not addressed. What extensions enable real-time adaptation to dynamic scenes?
- Failure mode taxonomy: Failure cases are mentioned in the appendix, but a systematic taxonomy (perception errors, manual hallucinations, control inaccuracies, collision) and quantitative breakdown are absent. Can we standardize failure analysis to target the most impactful fixes?
- Benchmarking fairness and reproducibility: Baseline conditioning was modified (goal images added), but standardized protocols, code, and datasets are not provided. Will releasing code, calibration tools, and the digital-twin pipeline enable consistent reproduction and broader comparison?
- RL or reward coupling: Manuals and actions are trained via supervised losses; joint optimization with task rewards (e.g., RL fine-tuning, differentiable planning) is absent. Can reward-driven training improve manual quality and action execution coherence?
- Task diversity: Beyond LEGO and rearrangement, tasks like tool use, fastening, wire routing, and deformable manipulation are not tested. How does the approach scale to these domains, and what manual components are needed (e.g., force targets, material models)?
- Object identity and instance tracking: The system assumes successful identification of target objects via manuals; robust instance tracking under occlusion, identical colors/shapes, and clutter is not evaluated. What integrations (tracking modules, segmentation, 3D instance models) improve reliability?
- Cross-embodiment adaptation: The action expert is pretrained on mixed datasets but fine-tuned per task/robot; the paper does not quantify adaptation effort to new robots. Can we add calibration layers or adapters to minimize per-robot fine-tuning?
- Attention mask design: The cross-task shared attention mask is crucial but underspecified. What mask designs (windowed, causal, hierarchical) optimize information flow without leakage or interference?
- Real-time calibration and camera changes: Robustness to camera re-positioning or lens changes is not evaluated. How can online calibration or self-supervised re-alignment maintain prompt accuracy under viewpoint drift?
- Manual text evaluation: Noun accuracy is reported, but verbs, prepositions, and compositional correctness of instructions are not measured. Can human evaluation or automated metrics for procedural text quality be added?
- Ethical and safety considerations: The paper does not discuss safe deployment (e.g., near humans), failure handling thresholds, or emergency stops under learned policies. What frameworks ensure safe operation with long-horizon autonomy?
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s demonstrated real-world performance (dual-arm Franka platform, 32% average success-rate improvement over SOTA on long-horizon assembly/rearrangement tasks) and the provided digital-twin data generation workflow.
- Flexible small-part assembly from goal images or layouts (Manufacturing, Robotics)
- Use case: Assemble kits, toys, fixtures, or small consumer products when provided with a final configuration image or diagram.
- Tools/products/workflows:
- Goal-to-Manual Planner that turns a final state into multimodal manuals (next-step image, UV positions, text).
- ManualCoT Visual Prompting Engine integrating explicit masks over current images.
- ROS 2/MoveIt integration with dual-arm controllers for bimanual placement and alignment.
- Assumptions/dependencies: Reliable RGB sensing and camera calibration; UV-to-robot mapping; objects similar to training distribution; basic safety interlocks; ~100 teleoperation demos to fine-tune per new task.
- Planogram compliance and shelf restocking (Retail, Logistics)
- Use case: Restock shelves or displays to match planograms (goal-state images) while minimizing collisions and maintaining placement accuracy.
- Tools/products/workflows: Planogram-to-Procedure Parser feeding stepwise manuals into existing robot stockers; visual prompts to guide pick/place.
- Assumptions/dependencies: SKU recognition; occlusion handling; standardized shelving; integration with inventory systems; lighting variability management.
- Bin packing and kitting to target pack layouts (E-commerce, Warehousing)
- Use case: Arrange items inside boxes to match target spatial layouts for protection and presentation (goal-state images).
- Tools/products/workflows: “Repack Bot” pipeline that reads packing diagrams and auto-generates procedural subgoals; WMS integration for order context.
- Assumptions/dependencies: Fragile item handling (force/torque sensing); accurate 3D mapping from UV cues; collision-free bimanual motion planning.
- Instrument tray setup in hospitals and labs (Healthcare operations, Biotech)
- Use case: Arrange instruments or consumables on trays to match predefined layouts, improving consistency and freeing staff time.
- Tools/products/workflows: “TrayPrep Assistant” that converts standard pack layouts into manuals; procedural verification via subgoal image matching.
- Assumptions/dependencies: Sterility protocols; reliable item identification; safety and regulatory compliance; controlled environments.
- Lab automation for sample racks and pipette arrangements (Biotech, Pharma R&D)
- Use case: Configure racks, plates, and tools from goal-state images without hand-crafted step-by-step programming.
- Tools/products/workflows: Goal-conditioned arranger for small labware; integration with LIMS/automation orchestration.
- Assumptions/dependencies: High positional accuracy; specialized grippers; camera calibration; limited variance in object geometry.
- Photo-to-tidy home organization (Daily Life, Service Robotics)
- Use case: User provides a “desired after” photo; robot rearranges household items accordingly.
- Tools/products/workflows: Mobile app to capture goals, preview generated manuals, and approve step sequences; closed-loop rearrangement.
- Assumptions/dependencies: Household-safe manipulation; diverse object recognition; robust to clutter and lighting; affordable consumer hardware.
- Educational modules and research prototyping (Academia, Robotics Education)
- Use case: Teach long-horizon, goal-conditioned manipulation using interpretable manuals and reduced data requirements (~100 demos).
- Tools/products/workflows: Digital-twin 3D Gaussian Splatting (3DGS) manual generator; RLBench integration; ManualCoT visualization for instruction.
- Assumptions/dependencies: GPU resources; multi-view capture for digital twins; access to dual-arm or single-arm platforms; open-source model licenses.
- Policy-compliant auditability for robot actions (Compliance, Operations)
- Use case: Log interpretable “manual steps” for audit trails in regulated environments (e.g., medical, food handling).
- Tools/products/workflows: ManualCoT Viewer with PSNR/FID/MAE metrics for subgoal quality; time-stamped manual/action step logs.
- Assumptions/dependencies: Standardized logging; privacy and data retention policies; acceptance by auditors/regulators.
- Teleoperation-efficient data collection (Robotics R&D)
- Use case: Reduce data burden by combining large open robot datasets with ~100 task-specific demos and auto-generated manuals.
- Tools/products/workflows: Master–puppet teleoperation pipeline; demonstration compression; joint fine-tuning scripts.
- Assumptions/dependencies: Teleop hardware; trained operators; compatibility with existing datasets; compute availability for diffusion-based action training.
Long-Term Applications
The following applications will require further research, scaling, or development (e.g., broader generalization, deformable object handling, safety certification, CAD integration).
- CAD-to-assembly “Design-to-Motion” compiler (Manufacturing, Robotics)
- Use case: Convert final CAD product states into executable subgoal manuals and precise actions for flexible assembly lines.
- Tools/products/workflows: CAD parser; CAD-to-3DGS alignment; 6D pose estimation; robust MoT-based planner/executor combo.
- Assumptions/dependencies: Accurate model alignment; tactile/compliance control; domain adaptation beyond UV prompts; extensive validation.
- General household assistant for multi-room chores (Home Robotics)
- Use case: Perform complex, long-horizon tasks (tidying, setting tables, laundry sorting) from user-defined goal states.
- Tools/products/workflows: Goal-conditioned chore planner; navigation and scene understanding; multi-arm coordination; AR-based plan preview/correction.
- Assumptions/dependencies: Robust generalization to diverse homes, deformables handling, safety and social acceptability; cost-effective hardware.
- Multi-robot collaborative assembly and scheduling (Industrial Robotics)
- Use case: Distribute manuals and actions across several robots with shared context for faster, robust assembly.
- Tools/products/workflows: ManualCoT multi-agent orchestrator; shared attention across agents; dynamic subgoal allocation.
- Assumptions/dependencies: Reliable inter-robot communication; global coordination; standardized safety protocols.
- Assistive care tasks (Healthcare, Elderly Care)
- Use case: Dressing assistance, meal prep, object handover guided by desired end-states and interpretable manual steps.
- Tools/products/workflows: Care-oriented ManualVLA variants with force/tactile sensing; human-in-the-loop correction UI.
- Assumptions/dependencies: Deformable/soft material manipulation; stringent safety/regulatory approval; user-specific adaptation.
- Hazardous environment handling and cleanup (Energy, Nuclear, Offshore)
- Use case: Rearrangement and assembly tasks in radioactive or high-risk areas from remote goal states and digital twins.
- Tools/products/workflows: Telepresence with goal-conditioned planning; radiation-hardened hardware; robust sim-to-real via 3DGS.
- Assumptions/dependencies: Remote sensing fidelity; extreme robustness; specialized hardware and safety procedures.
- Autonomous retail inventory management (Retail Operations)
- Use case: Continuous scanning of shelf states; generate manuals to restore planogram under real-time constraints.
- Tools/products/workflows: CV-based planogram compliance checker; plan correction via ManualCoT; human override interface.
- Assumptions/dependencies: Scalable shelf scanning; SKU variability; customer safety; store layout heterogeneity.
- Standards and policy for interpretable robot planning (Policy, Regulation)
- Use case: Establish requirements that robots log “manual-style” steps for accountability and failure analysis.
- Tools/products/workflows: Manual-based audit logs; standardized metrics (PSNR, FID, MAE) for subgoal fidelity; certification frameworks.
- Assumptions/dependencies: Multi-stakeholder consensus; industry adoption; clear mapping from manual tokens to regulatory criteria.
- “ManualVLA SDK” and “Digital-Twin Manual Factory” (Software, Cloud Robotics)
- Use case: Offer end-to-end APIs to generate manuals from goal states, train action experts, and deploy to robot fleets.
- Tools/products/workflows: Cloud training and simulation; ROS packages; managed datasets; visualization dashboards.
- Assumptions/dependencies: Compute costs; licensing of base models (Janus-Pro, DeepSeek-LLM, SigLIP); enterprise security; MLOps maturity.
- Maintenance and assembly on large assets (Energy, Infrastructure)
- Use case: Goal-conditioned placement for turbine components, switchgear arrangement, or utility panel assembly.
- Tools/products/workflows: 3D goal interpretation; high-DOF manipulation; manual generation from engineering specs; QA integration.
- Assumptions/dependencies: Outdoor variability; weather; complex safety standards; force and torque control; operator oversight.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper.
- 3D Gaussian Splatting: A neural rendering technique that represents scenes as collections of 3D Gaussians for fast, photorealistic view synthesis and editing. "we develop a high-fidelity digital-twin toolkit based on 3D Gaussian Splatting, which automatically generates manual data for planning expert training."
- Action expert: The specialized component of the model that generates low-level control actions conditioned on planning outputs and observations. "The framework consists of two experts: a planning expert responsible for generating multimodal manuals, and an action expert responsible for predicting precise actions."
- Affordance: Visual or spatial cues indicating where and how an object can be manipulated. "highlighting the affordance region that serves as input to the action expert."
- Attention mask: A constraint in the attention mechanism that controls which tokens can attend to which others, enabling structured information flow. "the subgoal manual serves as a conditioning signal for action modeling through our constructed cross-task attention mask."
- Autoregressive: A generation paradigm where each output token or action is predicted sequentially, conditioned on previously generated outputs. "Specifically, FAST~\cite{pertsch2025fast} utilizes autoregressive action outputs,"
- Bimanual control: Coordinated manipulation using two robotic arms to perform tasks requiring dual-arm synchronization. "execute them through coordinated bimanual control."
- Chain-of-Thought (CoT): An explicit reasoning strategy where intermediate steps are generated to guide complex decision-making or action execution. "we introduce a comprehensive Chain-of-Thought (CoT) reasoning process that combines both explicit and implicit cues to transform the generated manuals into precise actions."
- Cross-task shared attention mechanism: An attention design that allows features from the planning (manual-generation) expert to inform the action expert, enabling long-context interactions. "a cross-task shared attention mechanism between the two experts enables long-context interactions between manual-generation features and action generation, providing implicit guidance for coherent manipulation."
- Digital twin: A high-fidelity virtual replica of a physical system used to synthesize data and simulate task execution. "we develop a high-fidelity digital-twin toolkit based on 3D Gaussian Splatting, which automatically generates manual data for planning expert training."
- Diffusion-based action generation: An action modeling approach that uses diffusion processes to iteratively refine actions from noise, improving precision in control. "we find that for precise manipulation tasks, diffusion-based action generation yields superior performance."
- Diffusion policy: A learning framework that trains policies by denoising actions sampled from a diffusion process, typically with an MSE objective on predicted noise. "Following diffusion policy~\cite{chi2023diffusion}, the training objective is the mean squared error (MSE) between the predicted noises at the -th denoising steps and the ground-truth noises ,"
- Flow matching: A generative modeling method that learns continuous flows transforming simple distributions into target ones, used here for action generation. "~\cite{black2024pi_0} and ~\cite{intelligence2025pi05visionlanguageactionmodelopenworld} employ flow matching,"
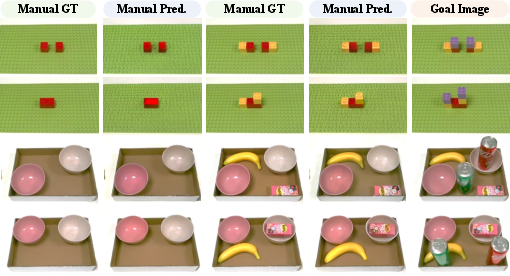
- Fréchet Inception Distance (FID): A metric that measures the distributional similarity between generated and real images using features from a pretrained network. "Furthermore, the low FID scores, particularly in the Object Rearrangement task, demonstrate that the generated image distribution closely matches that of real images, confirming their realism and fidelity."
- Global attention operator: An attention mechanism computed over all tokens in a sequence, potentially with task-specific projections, enabling unified cross-token interactions. "Finally, to define the global attention operator~\cite{deng2025emerging}, let denote the matrix form of the input sequence , where each row corresponds to a token embedding."
- Janus-Pro: A powerful vision-language foundation model used as the base for multimodal understanding and generation. "ManualVLA adopts Janus-Pro \cite{chen2025janus} as its foundation model due to its strong capability in general multimodal understanding and generation."
- Manual Chain-of-Thought (ManualCoT): A planning-to-action reasoning scheme where multimodal manuals (text, images, positions) are explicitly and implicitly transformed into executable actions. "We design a Manual Chain-of-Thought (ManualCoT) reasoning process that translates generated manuals into precise actions,"
- Master-puppet teleoperation: A data collection method where a human operator (master) controls a robot (puppet) to provide demonstrations. "we collect 100 demonstrations for each downstream task using master-puppet teleoperation."
- Mixture-of-Experts (MoE): An architecture that uses expert subnetworks (often FFNs) with routing, here contrasted with MoT for quality in both manuals and actions. "we compare our MoT architecture with a standard Mixture-of-Experts (MoE) architecture (duplicate only FFNs in LLM)"
- Mixture-of-Transformers (MoT): A multi-expert Transformer architecture with task-specific parameters for attention, FFN, and normalization, enabling specialized planning and action experts within a unified model. "we propose ManualVLA, a unified VLA model built upon a MoT architecture."
- Peak Signal-to-Noise Ratio (PSNR): A quantitative measure of image reconstruction quality that compares the maximum possible signal to the noise affecting fidelity. "our model produces satisfactory intermediate images across all three tasks, achieving high PSNR scores,"
- Proprioceptive inputs: Internal robot state signals (e.g., joint angles, gripper pose) used to condition action generation. "VLA models integrate visual, linguistic, and proprioceptive inputs to generate robot control signals,"
- SigLIP-Large: A high-capacity visual encoder trained with a sigmoid loss, used to extract semantic features from images. "ManualVLA uses SigLIP-Large~\cite{zhai2023sigmoid} with an input resolution of 384 to extract high-dimensional semantic features from input images."
- Vector-quantized Generative Adversarial Network (VQGAN): A model that compresses images into discrete codebook tokens for high-quality image synthesis and reconstruction. "For the vision tokenizer, ManualVLA adopts an encoder-quantizer-decoder architecture following VQGAN~\cite{esser2021taming}."
- Vision–Language–Action (VLA) model: A model that maps multimodal observations (vision, language, and robot state) to actions for manipulation tasks. "VisionâLanguageâAction (VLA) models have recently emerged, demonstrating strong generalization in robotic scene understanding and manipulation."
- Vision-LLM (VLM): A model trained on paired image-text data to perform multimodal understanding and generation. "Vision-LLMs (VLMs)~\cite{alayrac2022flamingo,radford2021learning,karamcheti2024prismatic} have achieved strong multimodal reasoning by learning from internet-scale image-text data."
- Visual prompt: A visual conditioning signal (e.g., a mask overlaid on an image) guiding the action expert toward specific regions or goals. "each positional indicator serves as a visual prompt embedded into the observation of the action expert."
Collections
Sign up for free to add this paper to one or more collections.

