Vista4D: Video Reshooting with 4D Point Clouds
Abstract: We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and failing to maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition. See our project page for results, code, and models: https://eyeline-labs.github.io/Vista4D






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Vista4D, a tool that lets you “reshoot” a video after it’s been recorded. Imagine you filmed a scene with your phone, but later you want the camera to swoop from the side or circle around the subject. Vista4D rebuilds the scene in 3D over time (that’s the “4D”: 3D space + time) and then generates a new video from any camera path you choose—while keeping the action and look of the original scene.
What questions are the researchers trying to answer?
Vista4D focuses on three simple goals:
- Can we move the camera in post-production and still keep the scene’s motion and appearance believable?
- Can we make the camera follow user-specified paths precisely (like a dolly move, orbit, or zoom)?
- Can we handle real-world messiness (like imperfect depth and 3D estimates) without producing flickers, glitches, or distortions?
How does Vista4D work?
Think of Vista4D as combining a careful 3D “sketch” of the scene with a very skilled “video artist” that fills in details.
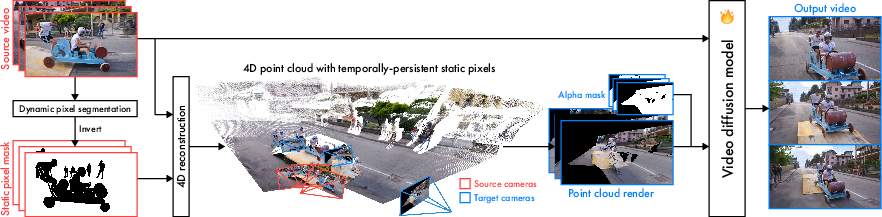
1) Build a 4D point cloud (a dot-based 3D model over time)
- Analogy: Imagine building a scene out of tiny floating dots (a “point cloud”). Each dot knows where it is in 3D space and what color it should be.
- The system analyzes the original video to estimate depth (how far things are) and the camera’s position for each frame, then lifts all frames into a shared 3D world.
- It labels what parts of the scene stay still (like walls or the ground) and makes those “static pixels” persist across all frames. This gives a stable 3D backbone of the environment that’s visible from many angles.
Why this helps: If your new camera path doesn’t see the same pixels as the original video did frame-by-frame, the persistent 3D scaffold still gives strong guidance, so the system can keep the scene consistent and the camera under control.
2) Train on “messy” multi-view data to handle real-world flaws
- Real videos aren’t perfect: depth can be wrong, fast-moving objects cause errors, and non-frontal viewpoints can create “ghosts” or “streaks.”
- Many older methods learned from perfectly clean training data, so they break when things get messy.
- Vista4D trains using multi-camera clips (including synthetic ones) that are intentionally reconstructed with the kinds of imperfections found in real life. This teaches the system to correct geometric mistakes rather than crumble when it sees them.
Analogy: It’s like training a driver not just on sunny, empty roads but also on rain, traffic, and potholes. They become much more reliable in the real world.
3) Combine multiple clues during generation (point cloud + source video + camera instructions)
- The system gives a video diffusion model (think: a very smart video generator) three things: 1) A render of the 3D point cloud from the new camera’s viewpoint 2) The original source video (as a visual reference for colors, textures, and motion) 3) The exact camera path you want (the “instructions”)
- The model looks at these together. The point cloud provides structure and camera control; the original video provides appearance and motion; and the camera instructions tell it where to “film” from.
Analogy: The point cloud is a rough sculpture; the source video is a set of detailed photos; the diffusion model is the artist who uses both to paint the final moving scene from your chosen angle.
What did they find, and why is it important?
The team tested Vista4D against several state-of-the-art methods and found:
- Better camera control: The generated videos match the requested camera moves more accurately (less error in rotation, translation, and lens settings).
- Stronger 3D consistency over time: Fewer flickers or geometry glitches; things stay in the right places from frame to frame.
- Higher visual quality and motion faithfulness: On tests that compare to ground-truth videos, Vista4D scores better or competitive on sharpness and realism, and it better preserves how things move.
- More robust to real-world errors: Even when 3D reconstructions are imperfect (e.g., streaks from moving objects), Vista4D corrects many of these issues by relying on both the point cloud and the original video.
- People preferred it: In a user study, participants chose Vista4D more often for content preservation, camera accuracy, and overall quality.
Why this matters: If you’re a filmmaker, YouTuber, or student making videos, Vista4D lets you “re-shoot” scenes you’ve already filmed—adding cinematic moves and new angles—without reshooting in real life.
What could this be used for?
- More creative camera moves in post: Design new camera paths after filming to improve storytelling or style.
- Dynamic scene expansion: If you have extra casual clips or alternative angles of the same place, Vista4D can merge them into the 4D model, reducing guesswork and improving realism.
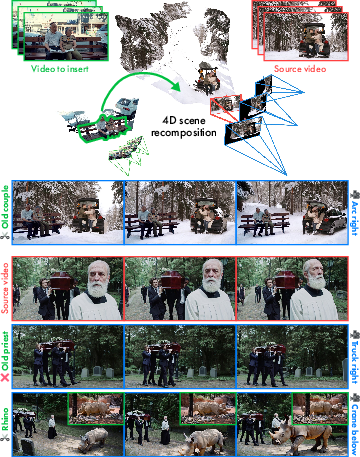
- 4D scene recomposition: You can rearrange or insert objects by editing the 3D point cloud (e.g., add, duplicate, or remove a subject) and Vista4D will blend lighting and motion to keep things believable.
- Long videos with memory: For very long shots, Vista4D keeps a 4D “memory” of what’s already been generated, helping maintain consistency as the camera moves around.
Simple takeaway: Vista4D gives you a reliable way to move the camera and reshape scenes after the fact, with results that look steady, realistic, and faithful to the original video. It opens up new creative possibilities—while also reminding us to think carefully about ethics and ownership as editing tools grow more powerful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain, untested, or unexplored in the paper, aimed to guide future research.
- Lack of a tunable trade-off between explicit and implicit priors: No user- or model-level control to interpolate how strongly generation follows the (possibly flawed) 4D point cloud versus the diffusion prior. Open: design a confidence-aware fusion/gating mechanism with a scalar control knob and per-pixel/region confidence maps from reconstruction.
- Absent uncertainty modeling for geometric inputs: The method conditions on point clouds and alpha masks without explicit uncertainty estimates from depth/pose/segmentation. Open: propagate and learn to exploit uncertainty/confidence maps to modulate reliance on geometry during denoising.
- Static/dynamic segmentation reliability: Static-pixel persistence hinges on a heuristic pipeline (RAM tags → LLM noun filtering → Grounded SAM 2), which can misclassify dynamic/background pixels (e.g., foliage, water, shadows, specularities). Open: end-to-end learning of static/dynamic separation with temporal consistency and uncertainty, plus quantitative robustness benchmarks.
- No persistent representation for dynamic content: Only static pixels are temporally persistent; dynamic objects are not 4D-tracked or temporally bound. Open: integrate scene flow, per-object 4D tracks, or dynamic Gaussians to persist identities/motion and improve long-video consistency for moving subjects.
- Long-video memory limited to static content: Chunked inference registers only static pixels; identity and motion of dynamic actors can drift across chunks. Open: a memory mechanism for dynamic content (e.g., per-object token banks, recurrent state, or 4D motion fields).
- Scarcity and domain gap in training data: Robustness relies partly on synthetic multiview dynamic videos; the domain gap to real-world scenes is not quantified. Open: collect/curate real, time-synchronized dynamic multiview datasets with ground-truth cameras and evaluate domain transfer.
- Evaluation bias from reconstructed cameras: Camera control accuracy is measured using cameras re-estimated from generated videos (via 4D reconstruction), which can bias results. Open: establish benchmarks with ground-truth intrinsics/extrinsics for dynamic scenes and evaluate sensitivity to reconstruction errors.
- Limited camera model realism: Assumes a pinhole camera; ignores rolling shutter, lens distortion, zoom/focus changes, and exposure/shutter effects. Open: incorporate realistic camera models and test on handheld/smartphone footage with RS and variable intrinsics.
- Lighting and photometric consistency not explicitly modeled: “Physically plausible” lighting is emergent from priors; there is no inverse rendering, reflectance, or illumination control. Open: integrate relighting/BRDF estimation or environment lighting to control and evaluate photometric consistency and recomposition realism.
- Disocclusion and hallucination control: The method lacks explicit mechanisms to constrain or edit hallucinated unseen content. Open: add priors (normals, semantics, depth uncertainty) and user-guided constraints to bound and steer disoccluded region synthesis.
- Failure modes under severe geometry errors: Robustness to transparent/specular surfaces, thin structures, fast motion, or large non-frontal deviations is qualitatively suggested but not systematically measured. Open: adversarial stress-testing and stratified benchmarks by geometry error regimes.
- Limited ablations on segmentation and reconstruction noise: The paper simulates a single segmentation failure; no systematic study across segmentation quality or depth noise levels. Open: controlled ablations varying segmentation precision/recall and depth/pose noise to map failure thresholds.
- Computational cost and latency: Uses a 14B-parameter video model; training and inference efficiency, memory footprint, and real-time feasibility (e.g., on-set use) are not addressed. Open: model distillation, caching, streaming inference, and latency-accuracy trade-off studies.
- Interactive/online 6DoF control untested: The framework assumes predefined trajectories; interactive, real-time camera control with immediate visual feedback remains unexplored. Open: incremental rendering and low-latency conditioning pipelines for on-the-fly camera edits.
- Fairness of baseline comparisons: It is unclear whether baselines were retrained on the same data mixture or tuned to similar capacity/resolution. Open: standardized training and evaluation protocols for video reshooting, including shared data and compute budgets.
- Metric limitations and contradictions: FID/FVD sometimes favor weaker camera control; camera accuracy relies on reconstructed cameras; SSIM mis-ranks quality in dynamic NVS examples. Open: develop metrics disentangling camera adherence, 3D/temporal consistency, and perceptual fidelity, and report all in a balanced way.
- Scene recomposition and expansion lack quantitative evaluation: Demonstrations are qualitative; there is no task-specific metric or user study for recomposition realism or expansion fidelity. Open: define benchmarks and perceptual tests for 4D recomposition and dynamic scene expansion.
- Alignment of asynchronous multiview captures: Dynamic scene expansion assumes joint 4D reconstruction; handling unsynchronized auxiliary captures and temporal alignment is not detailed. Open: methods for time alignment and fusion of asynchronous views in dynamic scenes.
- Handling extreme low-overlap trajectories: Although static persistence helps, the failure threshold (how little overlap is tolerable) is not quantified. Open: evaluate performance as a function of source–target overlap and baseline, and design strategies for extreme baselines.
- Robustness to non-Lambertian effects and illumination changes over time: Static persistence may not hold under changing illumination or view-dependent appearance. Open: view- and lighting-aware persistence or explicit reflectance models.
- Fusion architecture choices are underexplored: The paper adopts frame-wise token concatenation for joint conditioning; alternative fusions (cross-attention with confidence gating, FiLM, adapters) are not compared. Open: systematic study of fusion strategies under conflicting geometry/appearance cues.
- No explicit controls for imaging parameters: Beyond intrinsics, exposure, motion blur, and noise are uncontrolled. Open: condition on or predict imaging pipeline parameters for photorealistic, physically consistent output matching target cameras.
- Reproducibility and benchmark release: The constructed 110-pair evaluation set and camera-design UI are referenced but not clearly released. Open: release datasets, code, and evaluation scripts to enable standardized benchmarking.
- Safety and provenance: While broader impacts are noted, there is no technical mechanism for watermarking, provenance tracking, or misuse prevention in reshot videos. Open: integrate invisible watermarks and provenance metadata into the generation pipeline.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that build directly on Vista4D’s 4D-grounded video reshooting, joint point-cloud/video conditioning, and robustness to noisy 4D reconstructions.
- Virtual cinematography in post-production (film/TV, streaming, advertising)
- Use: Reshoot existing takes with new camera trajectories (dollies, arcs, crane shots), tighten coverage without re-shoots, stabilize or reframe to different aspect ratios (e.g., 16:9 to 9:16).
- Tools/products/workflows: NLE/VFX integrations (Premiere/After Effects, DaVinci Resolve, Nuke); a “Vista4D Reshoot” node that accepts a source clip and a designed camera path; on-set capture pipelines that export 4D recon.
- Assumptions/dependencies: Rights to source footage; GPU compute; 4D reconstruction quality (e.g., π³, STream3R); basic static/dynamic segmentation (SAM 2 / Grounded SAM 2); offline (non-real-time) turnaround acceptable.
- Previs/techvis camera exploration from single-camera plates (film, virtual production)
- Use: Quickly preview alternate camera moves on dailies; iterate on shot design; align post camera paths with editorial intent.
- Tools/products/workflows: Previs tool inside DCC (Maya/Blender/Unreal) that ingests plates and exports previewed takes; camera path authoring UI.
- Assumptions/dependencies: Sufficient source coverage; modest compute; no hard real-time requirement.
- Social/mobile creator tools for dynamic reframing (consumer apps, advertising)
- Use: Add cinematic moves to smartphone videos; create multiple angles for short-form content; “auto-reshoot” for vertical/horizontal platforms.
- Tools/products/workflows: Mobile/desktop apps with preset camera templates; batch processing for content studios.
- Assumptions/dependencies: Run-time acceleration or cloud inference; acceptable hallucination for unseen regions; clear labeling to avoid misleading edits.
- Sports replay enhancement from limited views (broadcast, media)
- Use: Generate virtual replays with alternate angles from broadcast footage; enhance highlight packages.
- Tools/products/workflows: Post-replay workstation; integration with broadcast asset manager; optional ingestion of audience smartphone clips for dynamic scene expansion.
- Assumptions/dependencies: Not real-time; camera geometry approximations acceptable; robust segmentation of players; compute availability.
- E-commerce and product video augmentation (retail, marketing)
- Use: Reshoot product demos for various angles without re-capturing; maintain consistent motion and lighting cues; scale content for multiple marketplaces.
- Tools/products/workflows: Merchant-side web tools or agency post pipelines; template libraries of camera moves.
- Assumptions/dependencies: Accurate object masks; consistent background control; IP permissions.
- Training data augmentation for vision models (academia, robotics, software)
- Use: Create multi-view sequences from single videos to pretrain or evaluate geometry/consistency-aware perception models.
- Tools/products/workflows: Data pipelines that emit reshot variants and camera metadata; benchmarking harness using RE@SG-style metrics.
- Assumptions/dependencies: Acknowledgment of metric-scale ambiguity; domain gap considerations; dataset licenses.
- 4D scene recomposition for editorial clean-up (post/VFX)
- Use: Remove/duplicate background elements, clone extras, or swap props by point-cloud editing; maintain motion coherence.
- Tools/products/workflows: 4D point cloud editor plug-in; mask-based manipulation UI; export back to editorial timelines.
- Assumptions/dependencies: Editor proficiency with point-cloud semantics; segmentation quality; review for lighting consistency.
- Aspect-ratio repurposing with camera control (media localization, news/documentary)
- Use: Produce platform-specific crops with intentional camera paths to preserve subjects and narrative focus.
- Tools/products/workflows: Batch “smart reframing” with designed or auto-derived camera moves; QC review in localization workflows.
- Assumptions/dependencies: Editorial policy and provenance tagging; compliance with journalistic guidelines.
- Long-form post with persistent scene memory (film/TV, games)
- Use: Process long sequences in chunks while preserving spatial continuity of static content (e.g., location features across an arc shot).
- Tools/products/workflows: Chunked inference scheduler; 4D memory registry; first-frame conditioned variants for inter-chunk continuity.
- Assumptions/dependencies: Offline compute; storage for persistent point clouds; consistent color pipeline across chunks.
- Architectural/real-estate walkthroughs from single tours (AEC, real estate)
- Use: Generate guided tours with better camera motion from a single walkthrough; highlight different viewpoints without revisits.
- Tools/products/workflows: Broker-facing web tool; template library for tour styles (flythrough, dolly-in).
- Assumptions/dependencies: Interiors with limited dynamics; reflective/transparent surfaces may reduce fidelity; offline rendering.
- Classroom demonstrations and outreach content (education)
- Use: Create multi-angle views of lab experiments or field demonstrations from one capture, improving student engagement.
- Tools/products/workflows: Instructor-facing simple UI; presets for common camera paths.
- Assumptions/dependencies: Non-critical measurement use (visualization only); disclaimers on scientific accuracy of geometric reconstructions.
- Ethical/provenance add-ons for generative reshooting (policy, industry)
- Use: Attach watermarks and C2PA provenance claims to reshot videos; log camera paths and edits for auditability.
- Tools/products/workflows: Post-export watermarking module; provenance manifests tied to editorial assets.
- Assumptions/dependencies: Adoption of C2PA or equivalent standards; organizational policy alignment.
Long-Term Applications
These use cases require further research, scaling, latency reduction, or domain validation beyond the current offline, compute-intensive setup.
- Real-time virtual camera for live sports and events (broadcast, media)
- Use: Generate alternate angles during live play or near-instant replays from a few camera feeds.
- Tools/products/workflows: Low-latency inference on dedicated accelerators; on-prem broadcast integration; on-the-fly dynamic scene expansion from crowd captures.
- Assumptions/dependencies: Significant model optimization (distillation, quantization), streaming 4D recon, robust dynamic segmentation, editorial safeguards.
- On-set virtual production with post-reshoot capability (film/TV, VP)
- Use: Real-time preview of camera changes on plates; post-adjust LED wall coverage and parallax after principal photography.
- Tools/products/workflows: Tight integration with Unreal/LED stages; low-latency camera encoders; artist “explicit–implicit prior” blending control (addressing the paper’s noted limitation).
- Assumptions/dependencies: Sub-100 ms latencies; reliable calibration; content-security and rights management.
- 6DoF consumer telepresence and VR from monocular video (AR/VR, consumer apps)
- Use: Allow viewers to move freely in short dynamic scenes reconstructed from a single camera.
- Tools/products/workflows: Lightweight 4D point-cloud streaming; head-coupled rendering with temporal coherence.
- Assumptions/dependencies: Robust novel occlusions handling; high-fidelity view synthesis; mobile-class runtime.
- Safety-critical visualization and training (healthcare, industrial training)
- Use: Reshoot surgical/endoscopic or industrial procedure videos to enhance viewpoint understanding in training simulators.
- Tools/products/workflows: Domain-adapted 4D recon and segmentation; integration with surgical/industrial simulators.
- Assumptions/dependencies: Rigorous validation of geometric/temporal accuracy; regulatory approval; strict provenance.
- Autonomous systems simulation and data generation (robotics, automotive)
- Use: Reshoot dashcam/robot videos to synthesize new training viewpoints; augment rare corner cases by 4D recomposition.
- Tools/products/workflows: Closed-loop sim pipelines; uncertainty-aware labeling of generated frames.
- Assumptions/dependencies: Address metric-scale/pose ambiguities; quantify sim-to-real transfer; bias and artifact monitoring.
- City-scale dynamic scene authoring from casual captures (smart cities, digital twins)
- Use: Fuse public and municipal videos to produce dynamic 4D scenes for planning or traffic analysis; reshoot for hypothetical viewpoints.
- Tools/products/workflows: Privacy-preserving ingestion; identity-safe segmentation; governance dashboards.
- Assumptions/dependencies: Strong privacy and consent frameworks; scalable, robust 4D recon at city scale; policy compliance.
- Automatic content localization with semantic intent (media, advertising)
- Use: Auto-generate platform- and culture-aware reframings that preserve narrative emphasis using semantic cues.
- Tools/products/workflows: Intent detection + camera path planner; integrated QC and compliance.
- Assumptions/dependencies: Reliable semantic understanding; editorial review; reduced hallucinations for unseen regions.
- Forensic tools and policy frameworks (policy, legal, platforms)
- Use: Detection of reshot/manipulated videos; mandated disclosure rules for camera-altered footage; standardized edit logs.
- Tools/products/workflows: Platform-level detectors; C2PA-based policies; audit pipelines for publishers.
- Assumptions/dependencies: Industry-wide standards; stakeholder alignment; adversarial robustness.
- General-purpose 4D point cloud editing suites (software, VFX)
- Use: Full-featured UIs to manipulate dynamic 4D scenes (insert/replace actors, relight, duplicate) with physically plausible blending.
- Tools/products/workflows: Layered 4D editing, lighting-aware generative modules, asset libraries; interoperability with DCCs.
- Assumptions/dependencies: Better control of lighting/relighting; consistent material/BRDF priors; artist-in-the-loop controls for explicit–implicit prior blending.
- Scientific visualization and education at scale (academia, museums)
- Use: Create multi-angle explorable archives of rare dynamic phenomena for classrooms and exhibits from single captures.
- Tools/products/workflows: Curatorial ingestion pipelines; viewer interactivity controls.
- Assumptions/dependencies: Provenance and context to avoid misinterpretation; resource support for long-term hosting.
Notes on Feasibility, Cross-Cutting Assumptions, and Dependencies
- Compute and latency: Current training/inference is offline and GPU-intensive; real-time or mobile deployment requires optimization (model compression, distillation, reduced context windows).
- 4D reconstruction quality: Performance depends on depth/camera estimation (e.g., π³, STream3R) and segmentation (SAM 2/Grounded SAM 2). Highly reflective/transparent or extremely fast-motion scenes remain challenging.
- Geometric accuracy and scale: Despite improved RE@SG and camera control, monocular scale ambiguity persists; applications requiring metric accuracy must calibrate or fuse with additional sensors.
- Control over priors: The paper notes a limitation—no user-controllable trade-off between adherence to point clouds (explicit prior) and correction via video priors (implicit). A “blend” knob is desirable for professional workflows.
- Legal/ethical: Ownership of source footage, talent and location releases, and required disclosure/watermarking (C2PA) are critical. News/documentary and safety-critical use require stricter provenance and review.
- Domain adaptation: Specialized sectors (healthcare, industrial, sports) may need fine-tuning on domain data and validated segmentation models for reliable outcomes.
- Tooling maturity: Broad adoption hinges on robust editor integrations, intuitive camera-path design UIs, and 4D point-cloud editing tools with QC aids (e.g., artifact visualization, confidence maps).
Glossary
- 4D consistency: Consistency of geometry and appearance across space and time when synthesizing dynamic scenes. "Our results demonstrate improved 4D consistency, camera control, and visual quality"
- 4D Gaussians: Gaussian primitives parameterized over space and time used to represent dynamic scenes for rendering. "Some recent methods also predict 4D Gaussians from monocular videos"
- 4D point cloud: A set of 3D points evolving over time, providing spatiotemporal scene structure. "grounds the input video and target cameras in a 4D point cloud"
- 4D reconstruction: Recovering time-varying 3D structure and camera motion from video to produce a 4D scene representation. "We will further combine the diffusion models with 4D reconstruction which lifts the monocular source video into a 4D point cloud"
- 4D scene recomposition: Editing and rearranging elements within a reconstructed dynamic 3D scene over time. "our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition"
- alpha mask: Per-pixel transparency map indicating valid or visible regions in a rendered image/video. "its alpha mask "
- autoregressive generation: Generating sequences by conditioning each output on previously generated outputs. "we autoregressively generate chunks of the video"
- camera embeddings: Learnable vector representations encoding camera parameters or poses for conditioning generative models. "camera embeddings \cite{bai2025recammaster, vanhoorick2024gcd}"
- camera extrinsics: Parameters describing the camera’s pose (rotation and translation) in world coordinates. "camera extrinsics "
- camera intrinsics: Parameters of the camera’s internal geometry (e.g., focal length, principal point). "camera intrinsics "
- camera trajectory: The path and orientations of a camera over time. "from novel camera trajectories and viewpoints"
- CLIP-T: A text-similarity metric from CLIP used to assess prompt alignment of generated content. "and CLIP-T \cite{radford2021clip} for prompt alignment"
- cross-attention: Attention mechanism that conditions one sequence on another, often used to inject guidance signals. "Unlike TrajectoryCrafter's cross-attention injection of source videos"
- Depth Watertight Mesh: A mesh constructed from depth that is closed (no holes), used to avoid inpainting ambiguities. "proposes the Depth Watertight Mesh during inference"
- double-reprojection: Training trick that reprojects renders between source and target views twice to create occlusions and pairs. "TrajectoryCrafter \cite{yu2025trajcraft} applies double-reprojection to monocular videos"
- dynamic pixels: Pixels corresponding to scene elements that move independently, complicating depth/geometry estimation. "This is especially true for dynamic pixels where depth estimators cannot leverage multiview geometry constraints"
- EPE (endpoint error): Optical flow error metric measuring the average distance between predicted and ground-truth flow vectors. "EPE (endpoint error) measures optical flow error between the generated and ground truth videos"
- FID (Fréchet Inception Distance): A perceptual distance metric comparing feature distributions of real and generated images/videos. "We use FID \cite{heusel2017fid}"
- flow matching objective: A continuous-time training objective aligning data with noise via learned velocity fields for generative modeling. "with the flow matching objective"
- FVD (Fréchet Video Distance): A perceptual quality metric extending FID to video by comparing spatiotemporal features. "FVD \cite{uterthiner2019fvd}"
- identity-initialized projection: A linear layer initialized as identity to stabilize conditioning or residual pathways. "with an identity-initialized projection after self-attention"
- implicit priors: Model-learned, non-explicit geometric cues (e.g., via embeddings or references) used for camera control. "Video reshooting with implicit priors"
- in-context conditioning: Supplying the source video and related signals as additional input frames/tokens to guide generation. "We find that in-context conditioning best preserves source video content"
- inverse perspective projection: Mapping image pixels with depth back into 3D camera coordinates. "the inverse perspective projection"
- LPIPS: Learned Perceptual Image Patch Similarity, a perceptual similarity metric between images/videos. "LPIPS"
- mPSNR: Masked PSNR; PSNR computed only within a specified mask (e.g., foreground/visible regions). "mPSNR"
- mSSIM: Masked SSIM; SSIM computed within masked regions to assess localized structural similarity. "mSSIM"
- novel view synthesis (NVS): Rendering a scene from viewpoints not seen in the input data. "novel view synthesis (NVS)"
- occluded regions: Areas not visible from a given viewpoint, often requiring inference or inpainting. "to create occluded regions for paired training"
- patchified latent tokens: Tokenized latent patches fed into a transformer for video/image diffusion models. "we concatenate the patchified latent tokens of the source video and point cloud render"
- per-frame reprojection error: Error measuring how well 3D points projected into 2D align frame-by-frame, used for consistency. "we adopt the per-frame reprojection error of SuperPoint \cite{detone2018superpoint} landmarks"
- Plücker embeddings: Line representations in 3D space used to encode camera rays for neural networks. "We inject the target cameras as Plücker embeddings"
- point cloud render: An image produced by projecting a (3D/4D) point cloud into a camera view. "the point cloud render "
- PSNR: Peak Signal-to-Noise Ratio, a pixel-wise fidelity metric (higher is better). "PSNR"
- RE@SG: Reprojection Error under SuperGlue; reprojection error measured using SuperGlue-corresponded keypoints. "with the lowest reprojection error under SuperGlue (RE@SG)"
- SLAM: Simultaneous Localization and Mapping; incremental estimation of camera pose and map from video. "combine these depth priors and camera optimization with SLAM~\cite{teed2021droid}"
- spatiotemporal grounding: Tying generation to explicit space-time structure (e.g., 4D point clouds) for consistency and control. "providing spatiotemporal grounding for reconstruction"
- static pixel mask: Segmentation indicating image regions that remain static over time for persistent 4D context. "a static pixel mask "
- structure from motion: Recovering 3D structure and camera motion from multiple images. "Traditional structure from motion~\cite{schonberger2016colmap}"
- SuperGlue: A graph neural-network matcher for feature correspondences between images. "under SuperGlue (RE@SG) \cite{sarlin2020superglue}"
- SuperPoint: A learned interest point detector/descriptor used for image matching. "SuperPoint \cite{detone2018superpoint}"
- temporally-persistent point cloud: A point cloud where static pixels persist across frames, providing long-horizon context. "the temporally-persistent point cloud"
- VBench: A benchmark suite evaluating various aspects of video generation quality (e.g., aesthetics, consistency). "VBench \cite{huang2024vbench}"
- VBench-2.0: An extended benchmark for video generation including more categories (e.g., human anatomy). "VBench-2.0 \cite{zheng2025vbench2}"
- video diffusion model: A generative model that synthesizes videos by denoising latent variables over time. "We will employ video diffusion models"
- video reshooting: Re-rendering a video’s scene from new camera paths while preserving dynamics and content. "which we call video reshooting"
- world-space transformation: Mapping from camera coordinates into a common world coordinate frame. "world-space transformation"
- zero-initialized linear projections: Linear layers initialized to zero so the model initially ignores a conditioning signal. "via zero-initialized linear projections"
Collections
Sign up for free to add this paper to one or more collections.

