Motion 3-to-4: 3D Motion Reconstruction for 4D Synthesis
Abstract: We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video and an optional 3D reference mesh. While recent advances have significantly improved 2D, video, and 3D content generation, 4D synthesis remains difficult due to limited training data and the inherent ambiguity of recovering geometry and motion from a monocular viewpoint. Motion 3-to-4 addresses these challenges by decomposing 4D synthesis into static 3D shape generation and motion reconstruction. Using a canonical reference mesh, our model learns a compact motion latent representation and predicts per-frame vertex trajectories to recover complete, temporally coherent geometry. A scalable frame-wise transformer further enables robustness to varying sequence lengths. Evaluations on both standard benchmarks and a new dataset with accurate ground-truth geometry show that Motion 3-to-4 delivers superior fidelity and spatial consistency compared to prior work. Project page is available at https://motion3-to-4.github.io/.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Motion 3‑to‑4, a computer method that turns a short, normal video (from one camera) into a full 4D model of an object. 4D here means a 3D object that also moves over time, like a digital puppet you can watch from any angle as it moves. The method can also use an optional 3D model (mesh) of the object to help it do a better job.
What questions does it try to answer?
- If you only have a regular video showing an object moving, can a computer build a detailed 3D model of that object and its motion over time?
- Can this be done quickly (without slow per-video tuning) and still look good from new viewpoints?
- How can we get reliable motion from limited training data, since high-quality 4D datasets are rare?
How does it work? (In simple terms)
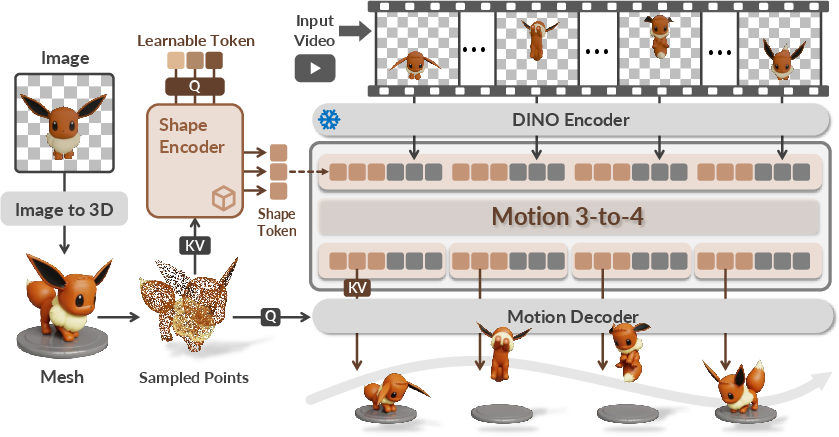
The key idea is to split the hard problem (4D) into two easier parts: shape and motion.
- First, get the shape:
- The system either takes a 3D mesh you provide, or it makes one from the first video frame using a strong 3D generator. Think of this as building a detailed statue of the object at the start.
- Then, figure out the motion:
- Imagine placing tiny stickers all over the surface of the statue. As the video plays, the system predicts where each sticker would move in 3D for every frame. These sticker paths are called “trajectories” or “motion flow.”
- To do this, it uses:
- A geometry encoder: reads the 3D mesh surface points (their position, direction, and color) and summarizes the object’s shape into a small “memory” (a compact code).
- A video encoder: reads each video frame and extracts smart visual features (using a pretrained image model) so it can match surface points to what it sees in the video across time.
- A frame‑wise transformer: a type of neural network that “pays attention” to what matters. It mixes the shared shape memory with each frame’s video features, so it can handle videos of many different lengths smoothly.
- A motion decoder: given the reference surface points and the per‑frame “motion memory,” it predicts where each surface point moves at each time step.
Training is straightforward: the model is shown many examples where the true 3D positions over time are known, and it learns by minimizing the difference between its predicted point positions and the true ones.
Analogy: Build a detailed clay model (shape), then learn how every speck of clay moves by watching the video, so you can replay the motion from any angle.
What did they find?
- Higher quality and consistency: Compared to other methods, Motion 3‑to‑4 produces sharper, more accurate 3D shapes and smoother, more stable motion over time (less jitter and flicker), and it looks good from new viewpoints.
- Fast, feed‑forward results: It runs in seconds to minutes and doesn’t need slow, per-video optimization. They report several frames per second on long sequences.
- Works well even with limited 4D training data: Because it reuses a strong 3D shape generator and focuses on learning motion as “surface‑to‑pixel” matching, it generalizes better than methods that try to learn everything end‑to‑end from scarce 4D data.
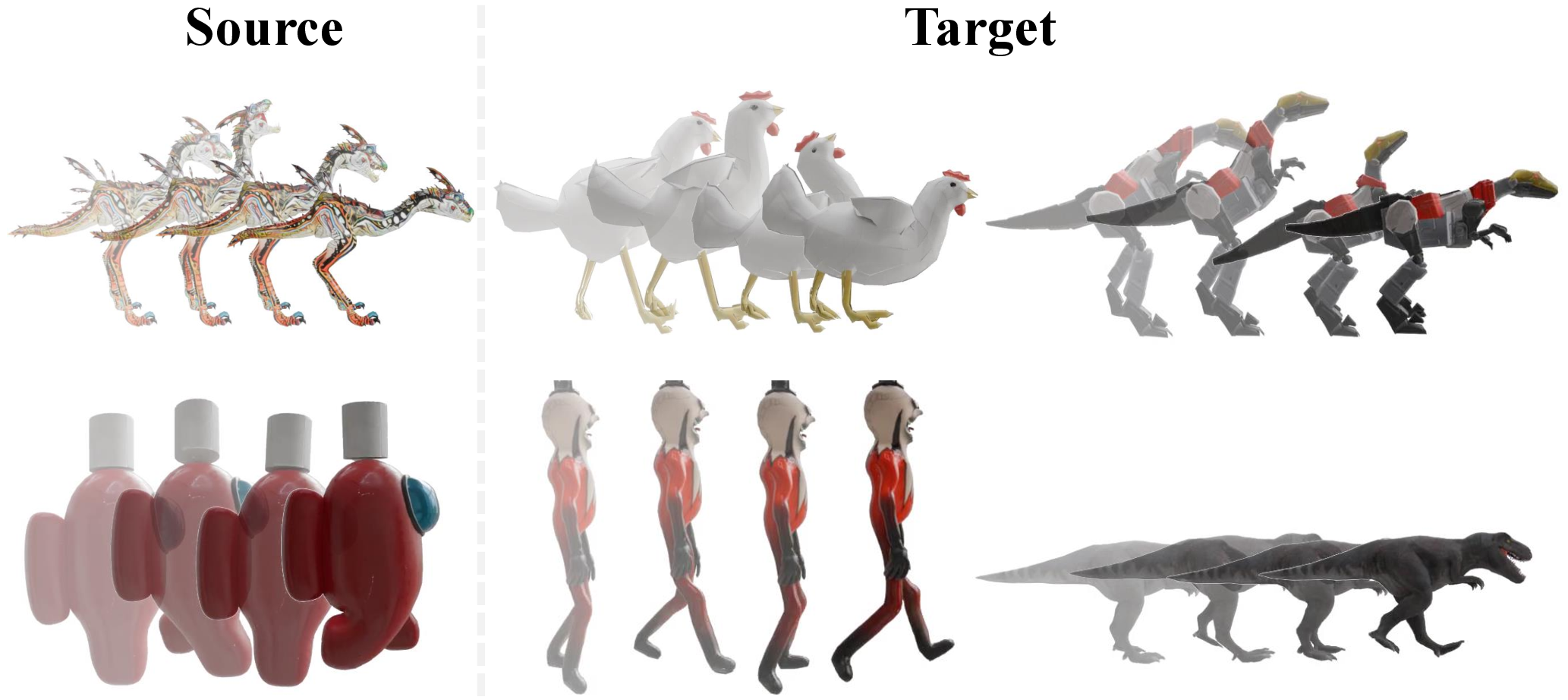
- Motion transfer: The system can take motion from one video and apply it to a different 3D model (for example, making a chicken mesh move like a dragon in a video).
- New benchmark: They built a test set called Motion‑80 with accurate 3D ground truth and realistic renderings, making it easier to fairly compare methods.
Limitations:
- If parts of the mesh are too close or touching at the start, points can “stick” together in later motion.
- Big changes in object structure that appear later (like opening/closing holes the initial mesh didn’t have) are hard to handle, because the reference mesh comes from the first frame.
Why does this matter?
- Better tools for VR, movies, games, and robotics: You can turn a simple video into a high‑quality 4D asset that can be viewed and edited from any angle.
- Faster content creation: Artists and developers can animate existing 3D models using motion from regular videos, saving time and effort.
- Stronger generalization with less data: By splitting the problem into shape then motion, the method avoids needing massive specialized 4D datasets.
- A step toward reliable 4D understanding from everyday videos: This could help machines better understand how objects move and deform in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions for future work, focusing on what is missing, uncertain, or left unexplored in the paper.
- Topology awareness: The geometry encoder operates on dense point sets without explicit mesh topology modeling, leading to vertex sticking and failures when topology changes. How can topology-aware encoders, dynamic remeshing, or mesh graph transformers be integrated to handle topological events (e.g., opening/closing mouth, separations, contacts)?
- Handling topology changes over time: The pipeline uses a single reference mesh from the first frame and cannot adapt to later topology changes. What strategies (e.g., time-varying meshes, mesh surgery, implicit fields converted to meshes per frame) can robustly accommodate topology evolution?
- Scale and orientation ambiguity: Evaluation relies on ICP rigid registration to resolve monocular ambiguities. Can the model learn metric scale and pose directly (e.g., via camera-aware training, scale priors, or self-calibration) to avoid post-hoc alignment?
- Camera motion estimation: Training data uses fixed viewpoints, and the method does not explicitly estimate camera motion for in-the-wild videos. How can simultaneous reconstruction of object and camera motion be incorporated to handle handheld or moving cameras?
- Occlusions and unseen regions: Motion is reconstructed via surface-to-pixel alignment, but occluded surfaces rely on priors from the initial mesh. How can uncertainty-aware motion fields, multi-view aggregation, or learned priors improve motion predictions for occluded/unseen parts?
- Sensitivity to initial mesh quality: The method optionally initializes from a generated mesh (e.g., Hunyuan3D 2.0) but does not quantify robustness to mesh errors (geometry noise, texture artifacts, wrong topology). What is the performance degradation under controlled perturbations, and can mesh refinement be integrated before motion decoding?
- Long-sequence scalability: The model is trained on 12-frame sequences but evaluated on sequences >128 frames with some metric degradation. What architectural or training changes (e.g., memory-efficient attention, recurrence, hierarchical temporal modeling, curriculum training) improve very long-term temporal coherence?
- Physical plausibility and constraints: There is no enforcement of kinematic constraints, rigidity preservation, volume conservation, or collision/contact handling. How can physics-informed losses or differentiable simulation priors improve realism and prevent implausible motion?
- Appearance modeling over time: Textures are taken from the reference mesh; time-varying appearance (e.g., lighting changes, non-Lambertian effects, texture stretch under deformation) is not explicitly modeled. Can a dynamic appearance branch or relighting module improve rendering fidelity under varying illumination and deformation?
- Background/foreground segmentation robustness: In-the-wild results depend on BiRefNet segmentation, but the pipeline’s tolerance to segmentation errors (leakage, holes, temporal inconsistency) is not analyzed. How can joint segmentation-reconstruction or robust attention mechanisms mitigate segmentation noise?
- Multi-object and interactions: The approach targets single-object 4D synthesis; interactions (contacts, grasping, collisions) and multi-object scenes are not addressed. How can the framework be extended to multiple deforming objects and object-object constraints?
- Retargeting evaluation: Motion transfer is shown qualitatively, without quantitative metrics or user studies. What standardized metrics (e.g., correspondence accuracy, motion style preservation, perceptual ratings) and datasets can evaluate motion retargeting across category and topology gaps?
- Domain gap to real-world videos: Training supervision uses synthetic assets with paired geometry; generalization to real footage is demonstrated qualitatively but not quantitatively. Can semi/self-supervised training with real videos, synthetic-to-real domain adaptation, or synthetic photorealistic augmentation close this gap?
- Benchmark diversity and realism: Motion-80 uses normalized objects, fixed camera viewpoints, and curated motions. Does this dataset cover challenging real-world conditions (motion blur, rolling shutter, specularities, complex lighting, soft materials, hair/cloth, fluids)? What additional benchmarks are needed for broader generalization claims?
- Comparative baselines: The paper does not compare against dynamic NeRF/Gaussian reconstruction methods that jointly estimate camera/object motion (e.g., dynamic NeRF variants, point-map approaches like CUT3R/StreamVGGT in dynamic settings). How does Motion 3-to-4 fare against these in geometry, temporal consistency, and novel-view synthesis?
- Uncertainty estimation: The model produces deterministic motion flows with no confidence measures. Can uncertainty-aware decoding (e.g., probabilistic flow fields, ensembles, Bayesian attention) help identify unreliable motion predictions and guide refinement?
- Failure case diagnostics: Vertex sticking and topology-change failures are reported, but no ablation pinpoints contributing factors (encoder design, token count K, alternating attention depth L, point sampling N/M). Systematic ablations are needed to identify root causes and effective remedies.
- Computational efficiency and resource constraints: Training requires 8 H100 GPUs; inference speed is reported (≈6.5 FPS over 512 frames) but memory and latency profiles across mesh resolutions and sequence lengths are not detailed. What optimizations (quantization, sparse attention, token pruning) enable deployment on modest hardware or real-time use?
- Camera-aware conditioning: Video features use DINOv2 with temporal embeddings, but explicit camera parameters are not incorporated. Would conditioning on estimated intrinsics/extrinsics or learning camera-aware tokens improve correspondence and motion decoding, especially under perspective changes?
- Motion metrics beyond FVD/DreamSim: Geometry metrics (CD, F-Score) and appearance metrics are reported, but motion-specific evaluations (e.g., acceleration smoothness, temporal consistency of correspondences, cycle-consistency under forward-backward flow) are missing. What motion-focused metrics best capture temporal fidelity?
- Robustness to noise and artifacts: The effect of common video artifacts (noise, compression, motion blur, occluders crossing the object) on reconstruction quality is untested. Controlled stress tests are needed to quantify robustness and guide augmentation strategies.
- Integration with rigging/animation pipelines: While the method can animate static meshes, it does not address conversion to standard rigged formats (skeletons, skin weights) or support animator controls. How can reconstructed motion be parameterized for downstream editing and reusability in DCC tools?
Glossary
- 3D Gaussians: A scene representation that models surfaces or volumes with anisotropic Gaussian primitives for fast rendering and reconstruction. "Our baselines include feedforward approaches that predict 3D Gaussians, i.e, L4GM~\cite{L4gm} and GVFD~\cite{gvfd}."
- 3D generative priors: Pretrained generative models or learned distributions over 3D shapes used to guide or initialize 4D synthesis. "Another line of work adopts pretrained 3D generative priors as a foundation for 4D synthesis."
- Alternating-Attention: A transformer design that alternates between global attention across frames and frame-wise attention to separate shared context from per-frame specifics. "To distinguish motion features across frames, inspired by VGGT~\cite{VGGT}, we adopt an Alternating-Attention architecture."
- Azimuth angles: Angular positions around the vertical axis used to define camera viewpoint directions in rendering or evaluation. "we render each asset at a resolution of from fixed viewpoints with uniformly sampled azimuth angles."
- Canonical reference mesh: A static, standardized mesh state used as the reference geometry for estimating motion over time. "Using a canonical reference mesh, our model learns a compact motion latent representation and predicts per-frame vertex trajectories to recover complete, temporally coherent geometry."
- Chamfer Distance (CD): A bidirectional distance metric between two point sets that measures average nearest-neighbor discrepancies in geometry. "For geometric evaluation, we follow the protocol of Shape2VecSet~\cite{3dshape2vecset} to compute the Chamfer Distance (CD) and F-Score."
- CLIP: A vision–LLM used as a metric to assess semantic alignment between generated renderings and reference content. "We adopt LPIPS~\cite{LPIPS}, CLIP~\cite{clip}, FVD~\cite{FVD}, and DreamSim~\cite{dreamsim} to assess overall quality and temporal consistency, which are widely used in video-to-4D tasks."
- Cross attention: An attention mechanism where a set of query tokens attends to a different set of key/value tokens to aggregate relevant information. "we compress the sampled points into a compact 1D latent representation by performing cross attention to aggregate shape information."
- DINOv2: A self-supervised vision transformer producing robust image features used for correspondence and generalization across frames. "we take a monocular video $\bV$ ... and extract patch-level features using a pretrained DINOv2~\cite{dinov2} encoder."
- DreamSim: A learned perceptual similarity metric for images/videos that correlates with human judgments of visual similarity and consistency. "We adopt LPIPS~\cite{LPIPS}, CLIP~\cite{clip}, FVD~\cite{FVD}, and DreamSim~\cite{dreamsim} to assess overall quality and temporal consistency"
- Dynamic NeRF: A time-varying neural radiance field that models appearance and geometry changes across frames. "then reconstructs 4D assets using dynamic NeRF~\cite{nerf} or Gaussian Splatting~\cite{3dgs}."
- Feed-forward: An inference paradigm that predicts outputs in a single forward pass without slow, per-instance optimization. "We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video and an optional 3D reference mesh."
- F-Score: A harmonic mean of precision and recall used here to evaluate geometric reconstruction quality between predicted and ground-truth surfaces. "For geometric evaluation, we follow the protocol of Shape2VecSet~\cite{3dshape2vecset} to compute the Chamfer Distance (CD) and F-Score."
- FVD (Fréchet Video Distance): A distribution-level metric that measures the quality and temporal coherence of generated videos compared to real ones. "We adopt LPIPS~\cite{LPIPS}, CLIP~\cite{clip}, FVD~\cite{FVD}, and DreamSim~\cite{dreamsim} to assess overall quality and temporal consistency"
- Gaussian Splatting (3DGS): A rendering technique using 3D Gaussian kernels that enables efficient novel-view synthesis of complex scenes. "then reconstructs 4D assets using dynamic NeRF~\cite{nerf} or Gaussian Splatting~\cite{3dgs}."
- Iterative Closest Point (ICP): An algorithm that aligns point clouds or meshes by estimating a rigid transformation minimizing point-to-point distances. "To address this, we apply an Iterative Closest Point (ICP) algorithm for alignment prior to evaluation."
- Mean squared error (MSE): A regression loss equal to the average of squared differences between predicted and ground-truth values. "We train Motion 3-to-4 with straightforward direct supervision by minimizing the mean squared error (MSE) between the predicted and ground-truth point positions"
- Monocular video: A single-camera video lacking multi-view geometry cues, making 3D/4D reconstruction more ambiguous. "We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video"
- Motion retargeting: Transferring motion captured from one source to animate a different target object or mesh. "our framework can animate static articulated objects with motion retargeted from videos of different sources."
- Novel-view synthesis: Rendering or generating views of a scene from camera poses not observed in the input data. "Because the 3DGS representation is tailored for novel-view synthesis, the predicted Gaussians are not constrained to lie exactly on the surface"
- Objaverse: A large-scale dataset of 3D assets used for training and evaluating generative and reconstruction models. "filtering 16,000 objects from a pool of approximately 50,000 models sourced from Objaverse~\cite{Objaverse} and Objaverse-XL~\cite{Objaverse-xl}."
- Rigging: Building internal skeletal structures for meshes to enable articulation and animation controls. "introduce intermediate rigging structures~\cite{UniRig,Magicarticulate,RigNet,Pinocchio,Anymate, he2025category,riganything, ponymation} with skinning-based animation"
- Scene flow: The 3D vector field describing point motions in space across time, generalizing optical flow to 3D. "we animate the generated explicit 3D mesh with the reconstructed scene flow"
- Score Distillation Sampling (SDS): An optimization technique that distills guidance from diffusion models into target representations like NeRFs or meshes. "Score Distillation Sampling (SDS)~\cite{Dreamfusion} is also widely adopted to optimize 4D representations from multi-view or video diffusion models"
- Simultaneous Localization and Mapping (SLAM): Estimating a camera’s trajectory while reconstructing the environment’s structure from sensor data. "Simultaneous Localization and Mapping (SLAM)~\cite{mur2015orb,davison2007monoslam,Droid} have long been the foundation for 3D structure and camera pose estimation."
- Skinning-based animation: Mesh deformation driven by bones/joints where vertex positions are weighted by influencing bones. "skinning-based animation~\cite{animax_video,Pinocchio,Puppeteer,Magicpony,3dfauna,Motion2Motion,makeani,makepose}"
- Structure-from-Motion (SfM): Recovering 3D structure and camera motion from multiple 2D images. "Structure-from-Motion (SfM)~\cite{agarwal2011building,Schoenberger2016CVPR,snavely2006photo} and Simultaneous Localization and Mapping (SLAM) ... have long been the foundation"
- Temporal embeddings: Encodings injected into tokens to represent frame order or temporal position within a sequence. "Additionally, we inject temporal embeddings into the patch tokens to make them explicitly aware of frame ordering."
- Topology drift: Changes or inconsistencies in mesh connectivity over time that break temporal coherence. "This generate-then-align strategy is slow and prone to topology drift due to independently conditioned frame generations."
- Transformer (frame-wise transformer): An attention-based neural architecture; here used per frame to process varying-length sequences robustly. "A scalable frame-wise transformer further enables robustness to varying sequence lengths."
- VAE (Variational Autoencoder): A generative model that learns latent distributions; used here to build motion latent spaces. "several approaches such as GVFD~\cite{gvfd} and AnimateAnyMesh~\cite{AnimateAnyMesh} build motion latent spaces via VAEs"
- VGGT: A vision transformer variant used for geometric tasks that inspires the alternating-attention design. "inspired by VGGT~\cite{VGGT}, we adopt an Alternating-Attention architecture."
- Voxel-based structured latents: Grid-like latent representations over 3D space that can be decoded into explicit shapes. "or adopt voxel-based structured latents that can be decoded into explicit 3D representations"
Practical Applications
Practical, real-world applications of Motion 3-to-4
Below are actionable applications that follow directly from the paper’s findings, methods, and innovations. Each item notes the relevant sector(s), the kind of tool/product/workflow that could emerge, and assumptions or dependencies that affect feasibility.
Immediate Applications
- Rapid video-to-4D asset creation for previsualization and editorial (media, VFX, animation)
- What: Convert a single on-set or storyboard video into a temporally coherent 4D mesh for shot blocking, previs, and animatic refinement in minutes.
- Tool/workflow: “Motion 3-to-4 Studio” plugin for Blender/Unreal/Unity; batch feed-forward conversion at ~6.5 FPS over long sequences; export to standard formats (e.g., Alembic/FBX).
- Assumptions/dependencies: Optional initial mesh (first frame) or reliance on a pretrained image-to-3D model (e.g., Hunyuan3D 2.0) for mesh bootstrap; monocular scale/orientation ambiguity may require ICP alignment; topology must remain stable.
- Rig-free motion transfer to existing 3D assets (software, gaming, VFX)
- What: Animate static meshes (e.g., marketplace assets, concept sculpts) by transferring motion from a source video without traditional rigging/skin weights.
- Tool/workflow: “Motion Retargeter” add-on that ingests source video + target mesh and outputs per-frame vertex trajectories.
- Assumptions/dependencies: Works best when the target mesh’s morphology roughly corresponds to motion cues in the source; may exhibit vertex sticking when mesh parts are not well separated.
- AR/VR content creation from smartphone videos (AR/VR, consumer apps)
- What: Lift real-world captures (pets, props, small objects) into dynamic 4D assets for AR stories, MR scenes, or social filters.
- Tool/workflow: Cloud API or mobile capture app that runs background removal (e.g., BiRefNet), mesh bootstrap (image-to-3D), then feed-forward motion reconstruction.
- Assumptions/dependencies: Quality sensitive to view framing, lighting, and texture; topology change across frames can break motion; mobile devices may offload compute to cloud.
- Interactive product showcase with dynamic motion (e-commerce, advertising)
- What: Produce interactive 3D product demos that include motion (e.g., opening mechanisms, fabric drape) from short video clips.
- Tool/workflow: “Video-to-4D Product Pipeline” that outputs textured meshes with per-frame motion; embed in web viewers with novel-view rendering.
- Assumptions/dependencies: Accurate initial mesh or reliable bootstrap required; object boundaries must be cleanly segmented; policy considerations around claims of physical fidelity.
- Simulation asset generation and augmentation (robotics, digital twins)
- What: Populate simulators with dynamic meshes derived from monocular footage to diversify training scenarios and synthetic datasets.
- Tool/workflow: Conversion pipeline to USD/GLTF with motion tracks; automated asset QA comparing CD/F-Score to references where available.
- Assumptions/dependencies: Not a physics engine; motion is reconstructed from appearance/semantic cues and may not obey true dynamics; topology changes are not handled.
- Benchmarking and research on 4D geometry/motion (academia, research tooling)
- What: Use Motion-80 and the paper’s evaluation protocol (CD, F-Score, LPIPS, CLIP, FVD, DreamSim) to study 4D reconstruction, motion consistency, and generalization.
- Tool/workflow: “Motion-80 Toolkit” with loaders, metrics, and baseline scripts; model-as-a-service for reproducible comparisons.
- Assumptions/dependencies: Ground-truth geometry available for Motion-80; monocular ambiguity necessitates consistent alignment practices (e.g., ICP).
- Archive and preservation of performance and choreography (cultural heritage, education)
- What: Capture dance or craft demonstrations from single-camera videos as dynamic 4D assets for teaching or archival visualization.
- Tool/workflow: “Performance-to-4D Archive” workflow integrated into museum/education platforms; export to interactive viewers.
- Assumptions/dependencies: Best for objects/performers with stable topology; privacy and consent required when people are involved.
- Content creator tooling for social platforms (consumer software)
- What: Turn short videos into interactive 3D “motion loops” for posts and AR lenses with novel-view playback.
- Tool/workflow: “4D Motion Clip” exporter; easy presets for stylized rendering; template-based motion transfer to branded assets.
- Assumptions/dependencies: Cloud inference accelerates time-to-post; asset licensing should be clear for derivatives.
Long-Term Applications
- Real-time telepresence and volumetric avatars from single cameras (AR/VR, communications)
- What: Live 4D avatars for calls or virtual events from a single webcam feed with robust motion and view-consistent geometry.
- Tool/workflow: “Live 4D Capture” with streaming transformer and low-latency mesh updating; headset integration.
- Assumptions/dependencies: Requires efficient on-device or edge inference and improved handling of topology changes (e.g., mouth opening, hair movement).
- Physics-aware 4D for robotics planning and manipulation (robotics)
- What: Use 4D assets that better respect physical constraints to simulate soft-body interactions, grasping, and non-rigid dynamics.
- Tool/workflow: “Physically Informed Motion 3-to-4” with priors from depth/scene flow or differentiable physics modules.
- Assumptions/dependencies: Incorporation of physical models or multi-sensor signals beyond monocular RGB; dataset expansion to complex deformations.
- Clinical motion analysis and digital therapeutics (healthcare)
- What: Patient-specific 4D reconstructions for physical therapy, gait assessment, or remote monitoring from simple videos.
- Tool/workflow: HIPAA-compliant capture pipeline; clinician dashboards with measurable trajectories and anatomical landmarks.
- Assumptions/dependencies: Requires validated accuracy on human subjects, privacy-safe deployment, and robust handling of occlusions/topology changes.
- Standardized 4D asset interchange and provenance (policy, standards, software)
- What: Define formats and metadata for 4D meshes (geometry + motion tracks), including provenance and licensing to curb misuse and ensure attribution.
- Tool/workflow: “4D Asset Manifest” and validators; integration into DCCs and asset stores.
- Assumptions/dependencies: Industry consensus on schemas (e.g., USD/Alembic extensions); policy frameworks for model/data licensing and synthetic-content labeling.
- On-device 4D capture for consumer AR (mobile, consumer apps)
- What: Capture and share dynamic 4D objects locally on smartphones for AR messaging and spatial journaling.
- Tool/workflow: Lightweight model variants, quantization/pruning, and hardware acceleration (NPUs).
- Assumptions/dependencies: Model compression without quality loss; improved robustness under mobile constraints (motion blur, low light).
- Multi-object 4D scene synthesis with interactions (simulation, gaming, VFX)
- What: Extend from single-object motion to multi-object scenes with contacts, occlusions, and layered motion.
- Tool/workflow: “Scene 3-to-4” pipeline with instance segmentation, interaction modeling, and coordinated latent representations.
- Assumptions/dependencies: Requires richer datasets and architectures for interaction and occlusion reasoning; stronger scene flow priors.
- Topology-aware motion reconstruction (core technology, software)
- What: Handle topology changes (opening/closing, tearing, growth) during 4D reconstruction, expanding applicability to more real-world cases.
- Tool/workflow: Hybrid mesh–point–implicit representation; dynamic remeshing and correspondence maintenance.
- Assumptions/dependencies: New training data and algorithms beyond fixed-topology constraints; careful design to prevent artifacts.
- Enterprise digital twins with video-driven updates (manufacturing, IoT)
- What: Update factory or asset twins from periodic monocular video as components move or wear, aiding predictive maintenance and visualization.
- Tool/workflow: “Video-to-Twin Updater” service; versioned 4D states for inspection dashboards.
- Assumptions/dependencies: Requires reliable camera placement and consistent capture protocols; motion must correlate with operational states to be useful.
- Ethical and copyright governance for video-to-3D/4D (policy)
- What: Frameworks governing rights, consent, and derivative use when turning videos into 4D assets; synthetic media disclosure.
- Tool/workflow: Policy toolkits for rights management, consent collection, and automated provenance tracking at export.
- Assumptions/dependencies: Cross-jurisdictional alignment; collaboration between platforms, rights holders, and standards bodies.
- STEM education and immersive labs (education, XR)
- What: 4D lab modules where students capture and analyze motion (mechanics, materials, biology) from single videos, rendered in 3D.
- Tool/workflow: “4D Lab-in-a-Box” curricula with capture kits and interactive viewers; cloud notebooks for motion metrics.
- Assumptions/dependencies: Pedagogical validation; simplified tooling for non-experts; guardrails against overinterpreting visually reconstructed motion as ground truth.
These applications leverage Motion 3-to-4’s feed-forward, frame-wise transformer architecture, mesh-anchored motion reconstruction, and demonstrated generalization to in-the-wild videos. Feasibility hinges on key dependencies noted above, including the quality of the initial mesh (or the reliability of image-to-3D bootstrap), monocular ambiguities (scale/orientation, occlusions), stable topology across frames, and access to GPU resources or optimized deployment paths.
Collections
Sign up for free to add this paper to one or more collections.