- The paper introduces a self-supervised framework that generates pseudo multi-view triplets from monocular videos to enable robust 4D reshooting under novel camera trajectories.
- The methodology leverages dense pixel tracking, forward warping, and a Diffusion Transformer with Offset RoPE to achieve high fidelity and temporal consistency in dynamic scenes.
- Extensive ablations demonstrate that integrating real monocular data with 15% synthetic input markedly enhances camera generalization and preserves intricate texture details.
Self-Supervised Video Reshooting with Implicit 4D Spatiotemporal Learning
Introduction
"Reshoot-Anything: A Self-Supervised Model for In-the-Wild Video Reshooting" (2604.21776) presents a novel paradigm for dynamic video reshooting—generating high-fidelity videos of complex scenes under novel, user-defined camera trajectories—using only monocular video for training. The severe scarcity of paired, multi-view, dynamic video data is addressed through a highly scalable, domain-agnostic self-supervised training protocol. The core methodological insight is the generation of pseudo multi-view training triplets, enabling robust 4D-aware model learning from 2D data and minimal reliance on synthetic datasets.
Pseudo Multi-View Triplet Generation and Self-Supervised Pipeline
The foundation of this approach is a self-supervised pipeline that constructs synthetic triplets (Vs,Va,Vt) from a single monocular video, bypassing the intractable logistics of acquiring synchronized multi-view, dynamic ground truth. Two independent dynamic crop trajectories, parameterized as smooth random walks via control points and splines, extract source (Vs) and target (Vt) clips from the same video, effectively simulating independently moving synchronized cameras.
The anchor (Va), serving as geometric guidance, is synthesized by forward-warping the reference frame of Vs to the target crop trajectory using dense pixel-tracking via AllTracker, along with a flow-based offset to account for relative crop motion. The use of forward splatting induces artifacts (holes, occlusions) analogous to inference-time anchor representations produced by 3D projections, ensuring distributional consistency between training and deployment.

Figure 1: The pseudo multi-view triplet is constructed by independently cropping source and target videos from a monocular clip and synthesizing the anchor by forward warping with dense tracking and structured augmentations.
This self-supervised triplet generation is entirely agnostic to video domain, requiring only robust dense 2D tracking. It generalizes to diverse content—real, animated, or generated—and complex camera or subject motion.
Implicit 4D Spatiotemporal Reasoning
The proposed self-supervised strategy enforces a non-trivial learning objective: reconstruct Vt under the target camera trajectory, using the geometrically informative but artifact-prone anchor Va while routing and re-projecting high-fidelity textures from the source Vs. Due to intentional misalignment and partial occlusion, the model cannot simply copy content and is forced to search through Vs temporally, discovering frames where missing textures are visible.

Figure 2: The model learns implicit 4D structure by associating dis-occluded target regions with unseen spatial locations in different temporal source frames, even in dynamic (nonrigid) scenes.
This "search-and-stitch" behavior leads the model to develop an implicit 4D world prior, capable of solving arbitrary texture routing and dynamic semantic tracking. In effect, dynamic 4D re-rendering emerges as a byproduct of the model learning to solve a 2D-based routing task with 4D structure underlying the generation.
The core model is a pre-trained Diffusion Transformer (DiT, WAN 2.2 I2V architecture), adapted to the reshooting task via dual-stream token-based conditioning. Both Va (anchor) and (Vs)0 (source) are encoded by a causal 3D VAE to latent sequences, with each latent stream concatenated and projected through the self-attention backbone—eschewing dedicated cross-attention for direct joint processing.
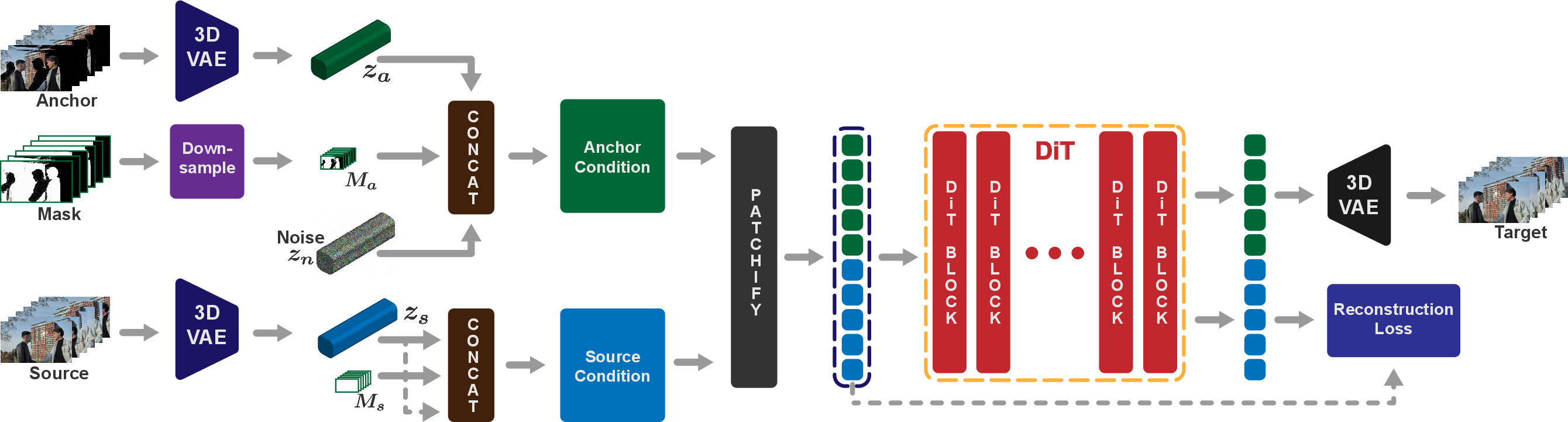
Figure 3: Overview of joint anchor-source token conditioning: VAE-encoded anchor and source latents are concatenated temporally, with tailored masks, and processed in a unified DiT self-attention stack for joint spatiotemporal reasoning.
A key innovation is the Offset Rotary Positional Embedding (Offset RoPE), which applies a fixed temporal offset to the source video tokens, cleanly decoupling source and target frame alignment and enabling flexible-length inference.
Robustness is further enhanced with targeted augmentations: fluorescent backgrounds highlight anchor disocclusions, 3D-aware structured noise is injected into anchor reference frames (enforcing geometric but not textural trust), and the source pathway is regularized with an auxiliary reconstruction loss. Ablations demonstrate that token concatenation via self-attention is essential; cross-attention or synthetic-only training leads to marked performance drops.

Figure 4: Technical augmentations for anchor video construction—background treatment and 3D-aware noise—force robustness to geometric and textural artifacts during training.
Synthetic Data Mixture and Hybrid Training
While monocular self-supervised training yields strong performance under typical camera motion, extreme or out-of-distribution (OOD) camera paths, especially large 6DoF rotations or displacements, remain challenging for models exposed only to cropped real video. To remedy this, approximately 15% synthetic paired multi-view video is incorporated (random subsample from ReCamMaster). This modest synthetic mixture injects priors for extreme trajectory alignment without imposing the severe synthetic-to-real domain gap observed in synthetic-only pipelines.

Figure 5: Inclusion of synthetic data is critical for extreme camera generalization, while real monocular data grounds physical realism and texture fidelity.
The hybrid dataset empirically secures both generalization and detail retention, confirmed via quantitative and qualitative ablations.
Experimental Validation and Ablations
Quantitative and qualitative evaluations on a curated 100-video test set show that this approach achieves state-of-the-art performance in temporal consistency (CLIP-F, VBench), camera pose accuracy (RotErr, TransErr), and view synchronization (FVD-V, CLIP-V, inlier matches) relative to TrajectoryCrafter, EX-4D, and ReCamMaster.

Figure 6: Comparative outputs indicate superior fidelity, temporal coherence, and alignment in dynamic and complex settings, especially under challenging camera motion and OOD scenarios.
Critical ablations confirm that removing source video conditioning or substituting cross-attention significantly degrades view synchronization and textured detail. Further, synthetic data alone cannot capture complex real-world spatiotemporal structure or dynamics. Technical augmentations (fluorescent background, random reference, 3D-aware noise) are each validated for their contributions to robustness and artifact suppression.

Figure 7: Ablation visualizations—synthetic-only and cross-attention baselines suffer from detail loss and structural hallucinations, contrasted with the preservation of complex dynamics in the full model.
Additional Qualitative Results and Extended Capabilities
Extended qualitative analysis demonstrates that the model reliably preserves intricate texture, geometry, and semantic structure across a broad spectrum of urban, natural, and animated scenes, outperforming baselines that exhibit blurring, drift, and loss of fidelity.

Figure 8: The proposed model consistently maintains high texture fidelity and scene structure, unlike baseline artifacts: blur, texture loss, and geometric distortion.
In addition to novel view reshooting, the architecture supports generative video outpainting and robustness to large viewpoint jumps, handling scenarios where initial target viewpoints are spatially disjoint from source video coverage.

Figure 9: Generative outpainting: The model plausibly completes large unseen regions through full-context, temporally-coherent synthesis by attending to the entire source sequence.
Implications and Future Directions
This work establishes a scalable, generalizable protocol for dynamic novel-view video synthesis directly from monocular data, with broad application to post-production, robotics, and creative domains. The self-supervised regime induces implicit 4D modeling capabilities foundational for video understanding and controllable generation.
Limitations and prospects for future work include:
- Computational cost: The token concatenation strategy doubles sequence length and thus inference compute. KV-caching and more efficient token routing could mitigate this.
- Blank anchor edge cases: When target trajectories venture beyond source video coverage, anchor signals vanish. Hybrid conditioning (visual anchors + explicit camera poses) and autoregressive anchor generation (forward-warping previously generated frames) are proposed next steps.
- Toward 4D world models: These advances pave the way for higher-fidelity, scene-complete, and temporally persistent 4D generative world models, with applications in simulation, robotics, and digital media.
Conclusion
"Reshoot-Anything" delivers a compelling, self-supervised solution for video reshooting in the wild, demonstrating that robust 4D-aware synthetic viewpoint generation is tractable with only monocular data, provided thoughtful architectural adaptation and self-supervised training. Its methods and insights significantly extend the limits of generalization and fidelity in camera-controllable video synthesis, informing future advances in conditional video modeling and implicit world understanding.