- The paper presents a novel feedforward framework that disentangles camera pose estimation from geometry reconstruction using a dynamics-aware aggregator.
- It achieves state-of-the-art performance in depth, pose, and point cloud benchmarks by fine-tuning specific middle attention layers to handle dynamic scenes.
- Experimental results show significant improvements in dynamic scene rendering, offering robust, efficient processing for real-time 4D perception.
Disentangled Pose and Geometry Estimation for 4D Perception: An Analysis of PAGE-4D
PAGE-4D introduces a unified feedforward framework for simultaneous camera pose estimation, depth prediction, and dense 3D point cloud reconstruction in dynamic scenes. Building on the Visual Geometry Grounded Transformer (VGGT), PAGE-4D addresses the core challenge of disentangling the conflicting requirements of pose and geometry estimation in the presence of scene dynamics. The method leverages a dynamics-aware aggregator and a targeted fine-tuning strategy to achieve state-of-the-art results across multiple 4D perception benchmarks, while maintaining computational efficiency.

Figure 1: PAGE-4D takes a sequence of RGB images depicting a dynamic scene as input and simultaneously predicts the corresponding camera parameters and 3D geometry information—all within a fraction of a second. Compared to VGGT, PAGE-4D produces denser and more accurate point cloud reconstructions with better depth estimation quality.
Motivation: The Static-Dynamic Dichotomy in 4D Perception
Feedforward 3D models such as VGGT have demonstrated strong performance in static scene understanding, but their accuracy degrades significantly in dynamic environments. The core issue is the violation of geometric consistency by moving objects, which introduces noise into camera pose estimation while providing valuable cues for geometry reconstruction. Empirical analysis reveals that VGGT's attention maps tend to suppress dynamic content, leading to high depth errors in dynamic regions.

Figure 2: (a) In static scenes, geometric consistency is preserved across frames, while in dynamic scenes, moving objects violate this consistency. (b) Visualization of VGGT attention maps from the 4th, 11th, 17th, and 23rd layers of the global attention block, showing that VGGT tends to ignore dynamic content.
The theoretical underpinning is that, under static conditions, both geometry and pose estimation can be jointly optimized over all pixels. In dynamic scenes, however, only static regions satisfy the epipolar constraint required for pose estimation, while geometry estimation must account for non-rigid motion. This necessitates a mechanism to disentangle the influence of dynamic regions across tasks.
PAGE-4D Architecture and Dynamics-Aware Aggregation
PAGE-4D extends VGGT with a dynamics-aware aggregator and a selective fine-tuning strategy. The architecture consists of:
- A pretrained DINO-style encoder for image feature extraction.
- A three-stage aggregator: initial global and frame attention layers, a dynamics-aware mask prediction module, and further attention layers with mask integration.
- Lightweight decoders for depth and point maps, and a larger decoder for camera pose estimation.
The dynamics-aware aggregator predicts a soft mask that identifies dynamic regions. This mask is incorporated into the attention mechanism in a task-specific manner: it suppresses dynamic regions for pose estimation tokens, while allowing geometry tokens to attend to dynamic content. The mask is learned in a fully differentiable, self-supervised fashion, enabling robust adaptation to ambiguous or partially occluded motion boundaries.
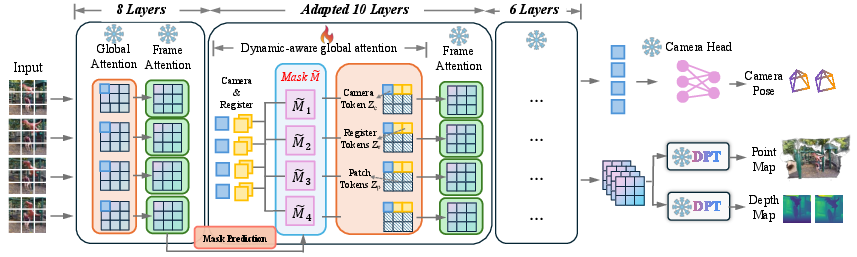
Figure 4: Fine-tuning strategy: Only the middle 10 layers of the global attention mechanism are adapted, and a dynamics-aware aggregator predicts a mask to disentangle dynamic and static content.
Training and Fine-Tuning Strategy
PAGE-4D employs a targeted fine-tuning approach, updating only the middle 10 layers of the global attention mechanism. This is motivated by the observation that these layers are most sensitive to dynamic content and are critical for cross-frame information fusion. The loss function is a multi-task objective combining Huber loss for camera pose, uncertainty-weighted depth and point-map losses, and gradient regularization. This strategy enables efficient adaptation to dynamic scenes with minimal computational overhead and without requiring large-scale dynamic datasets.
Experimental Results
Video and Monocular Depth Estimation
PAGE-4D achieves substantial improvements over prior feedforward models on video and monocular depth estimation benchmarks (Sintel, Bonn, DyCheck). For example, on Sintel with scale-shift alignment, PAGE-4D improves δ<1.25 accuracy from 0.605 (VGGT) to 0.763 and reduces Abs Rel from 0.378 to 0.212. These gains are achieved without increasing inference time or memory consumption.
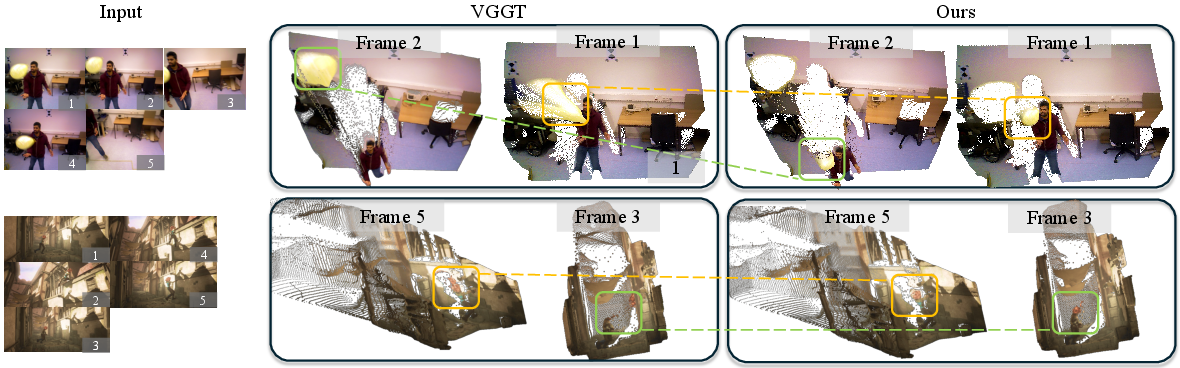
Figure 6: Qualitative comparison of point cloud estimation on the Bonn Sintel dataset. PAGE-4D captures geometric structure in complex motion scenarios, while VGGT produces fragmented and inconsistent geometry.
Camera Pose Estimation
On dynamic-scene benchmarks (Sintel, TUM), PAGE-4D reduces Absolute Trajectory Error (ATE) and Relative Pose Error (RPE) compared to VGGT and other baselines. For instance, on Sintel, ATE drops from 0.214 (VGGT) to 0.143, and RPE_rot is reduced by 17%.
Point Cloud Reconstruction
PAGE-4D demonstrates significant improvements in point cloud accuracy and completeness on DyCheck, reducing mean accuracy error by over 60% compared to VGGT. The method produces denser and more consistent reconstructions in dynamic scenes.

Figure 3: Qualitative results of point cloud estimation. PAGE-4D estimates camera poses and depth maps from RGB inputs, even in the presence of dynamic objects.
Dynamic Scene Rendering
By providing robust camera poses and dense point clouds, PAGE-4D enables high-fidelity 4D scene rendering when used as initialization for 4D-Gaussian splatting frameworks. It outperforms both static and dynamic-aware baselines in novel view synthesis on the Nerfie benchmark.
Ablation Studies
Ablation experiments confirm that fine-tuning only the middle attention layers yields performance comparable to full-model fine-tuning, validating the efficiency of the proposed strategy. The explicit disentanglement of dynamic and static content via the mask attention mechanism is shown to be critical for unlocking the backbone's capacity in dynamic scenarios.
Implications and Future Directions
PAGE-4D demonstrates that disentangling the influence of dynamic regions across tasks is essential for robust 4D perception in real-world environments. The approach achieves strong generalization with limited dynamic data and minimal architectural changes, suggesting a scalable path for future 4D scene understanding systems. Potential extensions include integrating explicit motion modeling, leveraging larger-scale dynamic datasets, and exploring self-supervised or unsupervised adaptation to novel dynamic domains.
Conclusion
PAGE-4D provides a principled and efficient solution to the challenge of 4D perception in dynamic scenes by disentangling pose and geometry estimation through a dynamics-aware aggregator and targeted fine-tuning. The method achieves state-of-the-art results across depth, pose, and point cloud reconstruction tasks, and enables robust dynamic scene rendering. The framework's modularity and efficiency make it a strong candidate for deployment in real-time 4D perception applications and a foundation for further research in dynamic scene understanding.