V-DPM: 4D Video Reconstruction with Dynamic Point Maps
Abstract: Powerful 3D representations such as DUSt3R invariant point maps, which encode 3D shape and camera parameters, have significantly advanced feed forward 3D reconstruction. While point maps assume static scenes, Dynamic Point Maps (DPMs) extend this concept to dynamic 3D content by additionally representing scene motion. However, existing DPMs are limited to image pairs and, like DUSt3R, require post processing via optimization when more than two views are involved. We argue that DPMs are more useful when applied to videos and introduce V-DPM to demonstrate this. First, we show how to formulate DPMs for video input in a way that maximizes representational power, facilitates neural prediction, and enables reuse of pretrained models. Second, we implement these ideas on top of VGGT, a recent and powerful 3D reconstructor. Although VGGT was trained on static scenes, we show that a modest amount of synthetic data is sufficient to adapt it into an effective V-DPM predictor. Our approach achieves state of the art performance in 3D and 4D reconstruction for dynamic scenes. In particular, unlike recent dynamic extensions of VGGT such as P3, DPMs recover not only dynamic depth but also the full 3D motion of every point in the scene.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces V-DPM, a smart computer system that turns regular videos into 3D “movies” of the real world—showing not just where things are in 3D, but also how every point moves over time. The authors build on a strong 3D tool called VGGT (which was originally made for still scenes) and teach it to handle moving scenes using a new idea called Dynamic Point Maps (DPMs). The result is fast, accurate “4D” reconstruction (3D plus time) from ordinary video clips.
What questions were the researchers trying to answer?
- How can we reconstruct not only the 3D shape of a scene from a video, but also the motion of every point over time (called scene flow), quickly and accurately?
- Can we extend successful “static” 3D methods (made for things that don’t move) to handle real, moving scenes without starting from scratch?
- Is there a simple representation that works well for both the background (which might be still) and moving, bending objects (like people, animals, or flowing water)?
- Can we do this in one forward pass of a neural network, instead of relying on slow “fix it later” optimization after the fact?
How did they do it? (Plain-language explanation)
Think of a video as a flipbook. Each frame is a picture taken from a camera at a certain time. The big challenge is to figure out, for every pixel in every frame, where that point is in 3D space and how it moves over time.
The authors use “point maps” to do this:
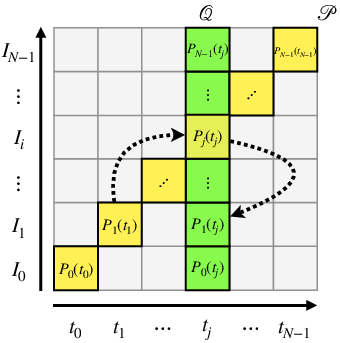
- Point map: Imagine an image where each pixel doesn’t just store color—it stores a tiny GPS-like 3D coordinate telling you where that point is in space. If all frames use the same “reference camera” to describe coordinates, their 3D points can be compared and fused easily. That’s called viewpoint invariance.
- Dynamic Point Maps (DPMs): They extend point maps to include time. You can ask: “Where is the 3D point seen in frame i, but at time j?” This lets the system match and track points even as things move, which is crucial for real videos.
V-DPM builds these maps in two simple stages, like solving a puzzle in steps:
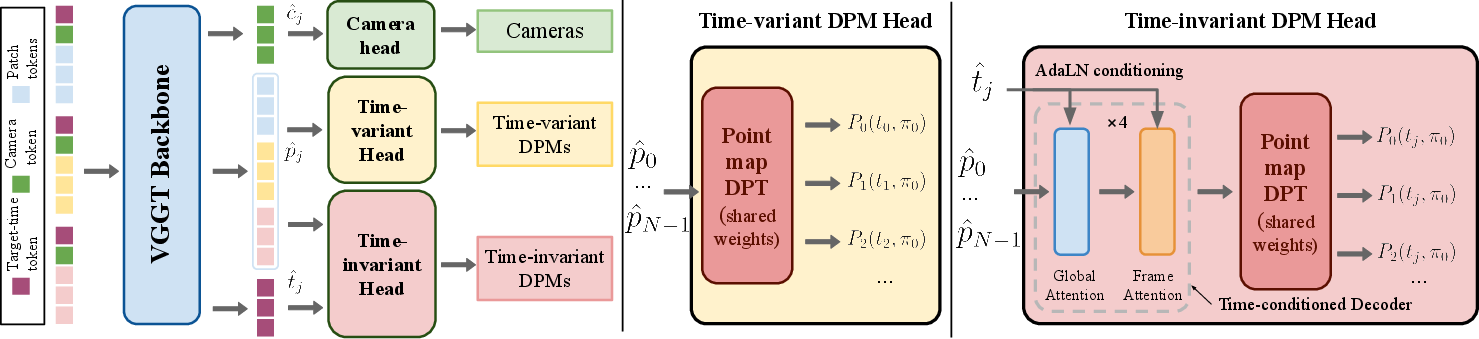
- Stage 1 (time-variant, viewpoint-invariant): For each input frame, the network predicts a point map that tells where the 3D points are at that frame’s exact time, all described in the same reference camera. This is a lot like what the older static system (VGGT) already does, so the authors reuse and fine-tune it rather than training a brand-new model.
- Stage 2 (time-invariant): Next, a special “time-conditioned decoder” takes the Stage 1 results and “rewinds” or “fast-forwards” them to a single chosen time. Think of it like asking, “Show me where everything was at time t_j, even if I’m looking from different frames.” This step aligns the whole scene to one moment, so the network can compare points across time and recover motion (scene flow).
Why this is smart:
- The first stage gives a strong per-frame 3D guess in a shared coordinate system.
- The second stage adds time alignment, using a small extra module that is told which moment you want (like turning a dial to pick the time).
- If you want the scene at different times, you don’t have to redo everything—just re-run the lightweight decoder for the new time, which is faster.
Under the hood (in everyday terms):
- The “backbone” (the main part of the network) is VGGT, which was trained for static 3D. The authors fine-tune it to output per-frame point maps for moving scenes.
- The “time-conditioned decoder” is a small add-on that adjusts its processing based on the chosen target time—think of it as letting the network “focus” on the exact moment you care about.
- Training uses a mix of easy-to-get static datasets and a modest amount of synthetic (computer-generated) moving scenes. This reduces the need for huge, hard-to-label 4D datasets.
What did they find, and why is it important?
Main findings:
- Strong 4D performance: V-DPM achieves state-of-the-art results on reconstructing both 3D shape and 3D motion from videos across several benchmarks (PointOdyssey, Kubric, Waymo). It often cuts errors by more than half compared to recent feed-forward methods like DPM, St4RTrack, and TraceAnything.
- Full motion, not just depth: Unlike many video methods that only predict per-frame depth (how far things are), V-DPM recovers the motion of every 3D point (scene flow). That’s a big step toward truly understanding dynamic scenes.
- Efficient and scalable: Because V-DPM reuses a powerful static backbone (VGGT) and adds a lightweight time module, it needs only modest extra training on dynamic data. It also reuses computations when you switch target times, making it faster to explore motion across a clip.
- Competitive camera estimation and depth: On video-depth and camera pose benchmarks (like Sintel, Bonn, and TUM-dynamics), V-DPM is competitive with top methods. One very recent method (π3) does slightly better on some camera/depth scores, but it uses more training data and a stronger backbone. Crucially, V-DPM can do motion reconstruction too.
Why this matters:
- You get a single, compact representation that handles both still backgrounds and complex moving, bending objects. That makes it simpler and more reliable for real-world videos.
What’s the impact and where could this be useful?
Potential impact:
- Movies and VFX: Turn regular videos into accurate 3D scenes that move realistically, making effects and edits easier and more precise.
- Robotics and AR/VR: Robots and AR devices need to know where things are and how they move to navigate, interact, or place virtual objects convincingly.
- World modeling and video generation: Better 4D reconstructions help build realistic digital twins and improve AI systems that generate or understand videos.
- Practical training recipe: The work shows you can learn a lot about motion with a strong static 3D model plus a small amount of synthetic dynamic data, which is far easier and cheaper than collecting massive 4D datasets.
In short, V-DPM shows how to turn fast, feed-forward 3D methods into full 4D tools that understand both shape and motion—reliably, efficiently, and with less training data than you might expect. It’s a solid template for the next generation of video understanding systems.
Knowledge Gaps
Below is a concise list of the key knowledge gaps, limitations, and open questions that remain after this paper. Each item is phrased to guide concrete follow-up research.
- Scaling without post-optimization: The method requires sliding-window bundle adjustment for long sequences; a fully feed-forward, streaming alternative for hundreds/thousands of frames remains open.
- Computational efficiency and memory: Training/inference were limited to snippets of ≤20 frames (generalizing to ~50 at test); runtime, memory footprint, and real-time feasibility are unreported and need optimization and benchmarking.
- Continuous-time capability: Although a time token conditions the decoder, it’s unclear whether the model can interpolate to arbitrary (non-frame) timestamps; training and evaluation for continuous-time reconstruction is needed.
- Reference frame selection: Sensitivity to the choice of reference viewpoint π0 and reference time tj is not analyzed; strategies to automatically select or learn optimal canonical frames are unexplored.
- Robustness to severe occlusions and visibility changes: How the model handles dis/occlusions, object entry/exit, and persistent invisibility across many frames is not quantified; per-pixel validity/confidence usage needs assessment and explicit modeling.
- Identity consistency for long-term tracking: The approach infers dense correspondences via 3D alignment but provides no explicit identity management; stability under long occlusions or similar-looking structures is untested.
- Domain gap and real-world generalization: Dynamic training is largely synthetic; systematic evaluation on diverse, real-world dynamic 4D datasets (with ground truth) and targeted domain adaptation strategies are missing.
- Motion structure exploitation: The method predicts per-point motion without explicit factorization into rigid bodies/articulations; incorporating motion segmentation or kinematic priors could improve performance and interpretability.
- Pose accuracy gap to SOTA: Camera pose accuracy lags π3; it remains open whether stronger backbones, larger-scale training, or improved losses would close the gap without sacrificing motion quality.
- Metric scale recovery: Ground-truth point maps are normalized and absolute scale is ambiguous; integrating metric cues (e.g., IMU, known object sizes, stereo) for scale-consistent 4D reconstruction is an open direction.
- Intrinsics variability and lens distortion: Assumptions about per-frame intrinsics and lens distortion aren’t explicit; robustness to varying intrinsics, rolling shutter, and calibration errors requires study.
- Handling challenging photometrics: Robustness to motion blur, severe lighting changes, specular/transparent surfaces, and non-Lambertian effects is not analyzed and likely a failure mode.
- Wide baselines and low overlap: Performance under extreme camera motion, wide baselines, and minimal view overlap is not reported; limits and mitigation strategies are unknown.
- Temporal gap generalization: The effect of varying frame spacing (Δt) on accuracy and stability is underexplored; curricula or augmentation for large and non-uniform Δt need investigation.
- Causal/online inference: The time-conditioned decoder uses all frames; designing a causal version that uses only past frames for robotics/control applications is an open challenge.
- Uncertainty modeling and use: While a confidence-calibrated loss is used, the role of per-pixel uncertainty in inference, fusion, and bundle adjustment (e.g., weighting constraints) is not studied.
- Learned multi-window fusion: The current long-sequence fusion relies on BA; learning to fuse overlapping windows without optimization (or integrating uncertainty into learned fusion) remains open.
- Architectural ablations: The impact of decoder depth, attention patterns (global vs frame), adaptive LayerNorm design, and DPT head sharing vs dedicated heads is not ablated; optimal designs are unknown.
- Evaluation breadth and diagnostics: Beyond EPE and first-frame track metrics, comprehensive diagnostics (e.g., error vs motion magnitude, occlusion handling, drift over long sequences, identity switches) are missing.
- Output representation limitations: The model outputs point maps; producing temporally consistent surfaces/meshes/Gaussians or canonicalized 4D fields with topology awareness is an open extension.
- Multi-sensor and multi-camera fusion: Extensions to synchronized multi-view rigs and fusion with IMU/LiDAR have not been explored and could address scale, drift, and robustness.
- Learned canonicalization: The method reconstructs at chosen timestamps; learning a canonical (time-invariant) template space and explicit forward/backward warps (scene flow fields) could improve consistency and editability.
- Training data generation: Procedures to auto-label real videos with pseudo-4D supervision (e.g., cycle consistency, self-distillation, synthetic-to-real sim2real) are not developed.
- Robustness to topology and volumetric dynamics: Scenarios with topology changes (e.g., tearing, contact) or volumetric phenomena (smoke, fluids) are unaddressed.
- Frame-rate variability: The impact of non-uniform frame rates and timestamp noise is not evaluated; explicit time-encoding schemes and augmentations could help.
- Reference-frame failure cases: If the first view has poor coverage or severe motion/blur, degradation is likely; policies for dynamic re-referencing or multi-reference fusion are unexplored.
- Integration with generative priors: Combining V-DPM with diffusion- or NeRF-based priors for robust reconstruction under sparse/degenerate conditions is an open avenue.
Glossary
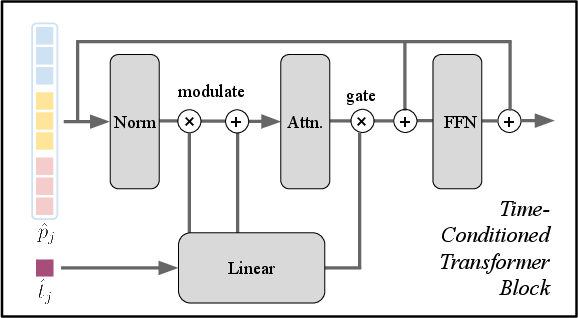
- Adaptive LayerNorm (adaLN): A conditioning mechanism that modulates LayerNorm parameters based on an external signal (here, target time) to guide transformer processing. "Conditioning is implemented via adaptive LayerNorm"
- Alternating Attention Transformer: A transformer architecture that alternates between different attention scopes (e.g., frame and global) to process tokens. "their concatenation is processed by an Alternating Attention Transformer to produce the output tokens ."
- Average Translation Error (ATE): A camera pose metric measuring the average discrepancy in translation between estimated and ground-truth trajectories. "we report Average Translation Error (ATE), Relative Translation Error (RPE trans), and Relative Rotation Error (RPE rot)."
- Bundle adjustment: An optimization procedure that jointly refines camera poses and 3D structure over multiple frames/windows. "use a bundle-adjustment optimisation scheme similar to DUSt3R~\citep{wang24dust3r:,zhang24monst3r:} to fuse the windows."
- Camera extrinsics: Parameters specifying the camera’s position and orientation in the world coordinate frame. "the viewpoints (camera extrinsics) associated to each image ."
- Camera intrinsics: Parameters defining a camera’s internal geometry (e.g., focal length, principal point) for projecting 3D points to 2D pixels. "given an image pair, estimate 3D shape as well as camera intrinsics and extrinsics in a single pass."
- Camera token: A learned token representing per-image camera information that the backbone uses to regress camera parameters. "a camera token "
- Confidence-calibrated loss: A training loss that weights errors by predicted confidence to improve robustness in 3D predictions. "We supervise V-DPM with the confidence-calibrated loss from DPM plus camera pose regression as in VGGT."
- Dense tracking: Tracking trajectories for every pixel (or densely sampled points) through time in 3D. "Tracking EPE error reported for 10-frame snippets, evaluating dense tracks of all pixels in the first frame."
- DiT: Diffusion Transformer; a transformer design used as a reference for conditioning via adaptive LayerNorm. "following FiLM~\cite{perez18film:} and DiT~\cite{peebles23scalable}."
- DPT head: A Dense Prediction Transformer head used to decode backbone tokens into dense outputs like point maps. "decoded into point maps by a DPT head"
- Dynamic Point Maps (DPMs): A viewpoint- and time-invariant representation that encodes 3D shape, motion, and camera parameters across time. "Dynamic Point Maps (DPMs)~\cite{sucar25dynamic} extend point maps to a viewpoint- and time-invariant representation."
- End-Point Error (EPE): A measure of the average distance between predicted and ground-truth points or flows. "report the End-Point Error on four predicted point maps"
- Feed-forward reconstruction: One-shot inference of 3D/4D structure without test-time optimization or iterative refinement. "capable of feed-forward 4D reconstruction of a dynamic scene."
- FiLM: Feature-wise Linear Modulation; a conditioning technique that scales and shifts normalized features based on auxiliary inputs. "following FiLM~\cite{perez18film:} and DiT~\cite{peebles23scalable}."
- Global attention: Attention computed over tokens from all frames jointly (as opposed to per-frame) to aggregate multi-view temporal context. "with alternating frame and global attention blocks."
- LayerNorm: A normalization technique applied to neural network activations; here adapted via external conditioning. "We remove learned scale and shift parameters from LayerNorm and instead modulate normalised patch tokens..."
- Monocular video: A video captured from a single camera/viewpoint used for 4D reconstruction. "one-shot 4D reconstruction from multi-frame monocular videos."
- Patch tokens: Tokens derived from image patches that encode visual features for transformer processing. "image patch tokens "
- Point map: An image-shaped representation associating each pixel with its corresponding 3D point in a chosen reference frame. "viewpoint-invariant point maps."
- Register tokens: Tokens used to aggregate or align information within the transformer across images. "register tokens "
- Relative Rotation Error (RPE rot): A pose metric measuring frame-to-frame rotational error. "we report Average Translation Error (ATE), Relative Translation Error (RPE trans), and Relative Rotation Error (RPE rot)."
- Relative Translation Error (RPE trans): A pose metric measuring frame-to-frame translational error. "we report Average Translation Error (ATE), Relative Translation Error (RPE trans), and Relative Rotation Error (RPE rot)."
- Rigid transformation: A transformation preserving distances and angles (rotation and translation), used to relate point maps across viewpoints. "related by a rigid transformation."
- Scene flow: The 3D motion vector field of points in a scene across time. "gives instead the scene flow for pixel in image ."
- SE(3): The Lie group of 3D rigid body motions (rotations and translations) representing camera poses. "by the viewpoints (camera extrinsics)"
- Sliding-window: Processing long sequences by moving a fixed-size window along time to reconstruct and fuse segments. "we operate in a sliding-window manner"
- Time-conditioned decoder: A decoder that uses the target timestamp as conditioning to align and reconstruct points at a chosen time. "we add a time-conditioned transformer decoder"
- Time-invariant point maps: Point maps expressed at a common reference time, enabling cross-frame alignment and motion recovery. "The point maps (green) are time-invariant"
- Time-variant point maps: Point maps expressed at each input frame’s timestamp, reflecting per-frame scene states. "The point maps (yellow) are time-variant"
- Viewpoint invariance: Expressing all point maps in a common reference camera frame so they can be fused and compared consistently. "express all point maps relative to a common viewpoint (achieving viewpoint invariance)"
- Window constraints: Constraints defined over overlapping frame windows (not just pairs) used during optimization to fuse predictions. "instead of pairwise constraints used in two-view methods, we use window constraints"
- World coordinate frame: A global coordinate system (often defined by a reference camera) used to evaluate and compare reconstructions. "we evaluate reconstructions in the world coordinate frame defined by the first view "
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s feed-forward 4D reconstruction from monocular video, dense scene flow, and camera estimation. Each item lists relevant sectors, potential tools/workflows, and feasibility dependencies.
- Bold 4D matchmoving and dynamic scene relighting in post-production — Monocular videos can be turned into coherent 4D assets (camera, static background, and non‑rigid motion), enabling robust object insertion, occlusion, and view changes without multi-camera rigs.
- Sectors: Media/entertainment (VFX), advertising, gaming
- Tools/workflows:
- Nuke/After Effects/DaVinci Resolve plugins for exporting V-DPM point maps and cameras
- Blender/Maya/Unreal/Unity import via PLY/USD/Alembic/glTF for 4D point clouds, scene flow, and solved cameras
- Per-shot “time-conditioned” re-synthesis of frames at arbitrary timestamps for temporal edits (time remapping, motion exaggeration)
- Assumptions/dependencies: High-quality input video; GPU for inference; sliding-window bundle adjustment for long sequences; absolute scale may be ambiguous without external cues; reflective/textureless surfaces remain challenging
- Bold Dynamic occlusion-aware AR compositing — Accurate depth and scene flow for each pixel enable placing virtual objects that correctly occlude/are occluded by moving real objects from a single RGB stream.
- Sectors: AR/VR, live events, retail try-on
- Tools/workflows:
- Mobile/edge pipeline: precompute backbone once, decode per timestamp for interactive effects
- Engine integration: Unity/Unreal shader nodes consuming per-frame point maps and scene flow
- Assumptions/dependencies: Mobile compute constraints; latency vs quality trade-offs; privacy and on-device processing requirements; scenes with fast motion may need higher fps
- Bold 3D tracking for sports and biomechanical analysis from broadcast video — Extract dense 3D trajectories and camera paths for performance analytics, player motion studies, or tactical visualization without calibrated multicam setups.
- Sectors: Sports analytics, healthcare research, education
- Tools/workflows:
- Batch processing of broadcast clips to produce per-player trajectories and skeletal fitting initialized by 4D point tracks
- Visualization in web dashboards (WebGL/Three.js) with scene flow overlays
- Assumptions/dependencies: Camera scale ambiguity; occlusions; field/arena priors can improve camera scale and alignment
- Bold Robotics research: perception for manipulation and navigation in dynamic scenes — Use dense scene flow to predict object motion and improve grasp planning, collision avoidance, and dynamic obstacle anticipation in labs.
- Sectors: Robotics (academia/industry R&D)
- Tools/workflows:
- ROS2 node providing point maps, camera poses, and scene flow from RGB streams
- World-model modules that fuse V-DPM windows with short-horizon planning
- Assumptions/dependencies: Near-real-time GPU; absolute metric scale requires IMU/LiDAR/wheel odometry; domain adaptation to warehouse/household lighting and motion patterns
- Bold Accelerated 3D label propagation and dataset bootstrapping — Propagate annotations (instance masks, keypoints) through time via 3D correspondences, reducing manual labeling.
- Sectors: Autonomous driving, vision data ops, surveillance analytics
- Tools/workflows:
- CVAT/Label Studio plugins that consume scene flow to propagate labels across frames
- QA tools that surface inconsistency using time-invariant point map checks
- Assumptions/dependencies: Synthetic-to-real domain gap may require fine-tuning; heavy occlusion and motion blur can degrade propagation
- Bold Dashcam and bodycam video reconstruction for incident review — Offline 4D reconstruction helps disentangle moving agents and camera motion to clarify events.
- Sectors: Insurance, public safety/forensics, fleet management
- Tools/workflows:
- Cloud batch service that returns camera trajectory, per-agent motion fields, and 3D scene snapshots at key timestamps
- Assumptions/dependencies: Chain-of-custody and reproducibility requirements; calibrated uncertainty reporting; privacy/compliance constraints; absolute scale via known baselines/GPS/IMU
- Bold Digital-twin updates from monocular inspection video — Create up-to-date 4D point maps of dynamic assets (e.g., moving machinery) where full LiDAR/rigs are impractical.
- Sectors: Manufacturing, energy, construction
- Tools/workflows:
- Integration with inspection pipelines to export point clouds and track deformation/wear over time
- Assumptions/dependencies: Safety/QA standards; reflective/low-texture surfaces; scale via fiducials or known dimensions
- Bold Educational and creator tools for 4D content — Enable students and creators to convert phone videos into dynamic 3D scenes for learning, demos, and social content.
- Sectors: Education, creator economy
- Tools/workflows:
- Desktop/mobile apps that export dynamic point clouds and stabilized novel views
- Assumptions/dependencies: Consumer GPUs/phones may require reduced resolution; responsible use and privacy
Long-Term Applications
The following applications require further research, scaling, real-time optimization, or domain validation before broad deployment.
- Bold Real-time 4D perception stack for robots and autonomous vehicles — Low-latency dense scene flow and camera estimation as a core module for planning and control.
- Sectors: Robotics, automotive
- Tools/products:
- Embedded inference with model compression and streaming windows
- Fusion with VIO/IMU/radar/LiDAR for metric scale and robustness
- Dependencies: Hard real-time constraints; safety certification; adverse weather/nighttime robustness; long-horizon consistency
- Bold Live volumetric broadcast and telepresence from a single moving camera — Holographic streams for events and conferencing without multi-cam stages.
- Sectors: Media/broadcast, communications
- Tools/products:
- Edge-cloud pipeline: backbone on edge, time-conditioned decoding on cloud, low-latency mesh/point cloud streaming
- Dependencies: Bandwidth/latency; temporal stability; identity/appearance preservation; privacy and consent management
- Bold AR glasses with dynamic, occlusion-correct virtual content in unconstrained environments — Persistent 4D world models from egocentric video.
- Sectors: Consumer AR, enterprise field service
- Tools/products:
- On-device incremental 4D mapping with sliding windows and lightweight BA
- Dependencies: Power and thermal budgets; privacy-preserving on-device processing; scale resolution via auxiliary sensors
- Bold Surgical/medical video 4D reconstruction — Soft-tissue motion modeling from endoscopic videos to aid navigation and tool control.
- Sectors: Healthcare
- Tools/products:
- OR-integrated modules that provide deformable maps and flow to robotic systems
- Dependencies: Extensive clinical validation; domain adaptation to low texture/specular fluids; regulatory approval; sterilizable hardware constraints
- Bold City-scale 4D digital twins from heterogeneous cameras — Fuse streetcams/drones/vehicles into dynamic twins for traffic management, urban planning, and safety analytics.
- Sectors: Public sector, mobility, smart cities
- Tools/products:
- Cross-camera windowed V-DPM with cross-view association; streaming datalake integration
- Dependencies: Privacy and governance; cross-sensor calibration; compute cost; fairness and bias auditing
- Bold Generative video-to-4D content creation — Conditioning video diffusion or NeRF-like models with V-DPM’s time-invariant point maps for controllable 4D generation/editing.
- Sectors: Creative AI, gaming, advertising
- Tools/products:
- 4D asset editors that let users edit geometry/motion and re-render from novel views
- Dependencies: Integration with video diffusion backbones; temporal consistency; IP and authenticity safeguards
- Bold SLAM/odometry enhancement with 4D invariants — Use time-invariant point maps to stabilize and relocalize in dynamic scenes where classical SLAM fails.
- Sectors: Robotics, AR/VR
- Tools/products:
- Hybrid SLAM pipelines combining V-DPM windows with factor-graph optimization
- Dependencies: Robustness under heavy dynamics; compute on embedded platforms; drift and scale observability
- Bold Insurance and legal-grade accident reconstruction — Automated, standardized 4D reconstructions with quantified uncertainty and audit trails.
- Sectors: Insurance, legal tech, public policy
- Tools/products:
- Certified processing pipelines with error bounds and versioned models; courtroom-ready reports
- Dependencies: Standards for validation; admissibility criteria; strong provenance and chain-of-custody
- Bold Industrial inspection of moving machinery and renewable assets — Deformation and vibration analysis from routine videos, enabling predictive maintenance.
- Sectors: Manufacturing, energy (wind/solar)
- Tools/products:
- Periodic 4D scans aligned over time for change detection and anomaly scoring
- Dependencies: Domain calibration; reflective/composite materials; environmental conditions (rain, glare)
- Bold Wildlife and environmental behavior modeling — 4D tracking of animals from field cameras to study interactions and habitat use.
- Sectors: Ecology, conservation
- Tools/products:
- Research platforms that output 3D trajectories and interaction metrics
- Dependencies: Low light/camouflage robustness; multi-camera fusion for scale; ethical data handling
Cross-cutting assumptions and dependencies
- Scale and metric accuracy: V-DPM normalizes geometry and recovers relative scale; absolute metric scale often requires external cues (IMU, known objects, stereo/LiDAR).
- Compute/latency: Current approach is efficient for short snippets but may require GPU acceleration; real-time on edge needs pruning/quantization/distillation.
- Data and domain shift: Trained with modest synthetic dynamic data plus static datasets; domain adaptation may be needed for medical, underwater, infrared, or extreme lighting.
- Long sequences: Sliding-window processing with bundle adjustment is required; tuning window sizes and overlap impacts stability and throughput.
- Failure modes: Severe motion blur, heavy occlusions, specular/transparent surfaces, and textureless regions remain challenging; uncertainty estimates should be surfaced to users.
- Ethics, privacy, and compliance: Human-centric reconstructions must address consent, de-identification, and regional regulations (e.g., GDPR); for forensics, reproducibility and audit trails are essential.
These applications derive directly from the paper’s core innovations: time- and viewpoint-invariant dynamic point maps for every pixel, feed-forward multi-view video processing, time-conditioned decoding for reconstruction at arbitrary timestamps, and compatibility with existing static 3D backbones (e.g., VGGT), enabling efficient adaptation and deployment.
Collections
Sign up for free to add this paper to one or more collections.

