- The paper introduces GRVS, which employs a recurrent architecture and dynamic plane sweep volumes for efficient monocular dynamic view synthesis.
- The method effectively disentangles camera and scene motion, improving reconstruction fidelity in both static and dynamic regions.
- Experimental results on UCSD and Kubric-4D-dyn demonstrate that GRVS outperforms Gaussian Splatting and diffusion-based models in image quality and temporal coherence.
GRVS: Generalizable and Recurrent Monocular Dynamic View Synthesis
Monocular dynamic view synthesis (NVS) aims to synthesize novel views of dynamic scenes from a single video stream. The entanglement of camera and scene motion, in the absence of multi-view cues, presents well-recognized ill-posedness compared to static or multi-view dynamic NVS. Dominant approaches fall into scene-specific methods, leveraging explicit 4D representations with deformation fields (e.g., Gaussian Splatting, NeRF variants), and diffusion-based video generation conditioned on estimated geometry or camera poses. The former handles static regions but is computationally intensive and fails at motion reconstruction in highly dynamic regions; diffusion approaches produce plausible videos but suffer from geometric misalignments and blurry outputs due to noisy priors and indirect camera conditioning. Existing methods frequently require scene-specific optimization and lack generalization, suffering efficiency drawbacks and limited control fidelity.












Figure 1: Scene-specific approaches optimized under motion priors typically reconstruct static regions well but struggle with dynamic elements; diffusion models handle dynamics plausibly but lose fine geometry; GRVS reconstructs both with high fidelity.
Approach: The GRVS Architecture
The proposed GRVS model reframes monocular dynamic NVS as asynchronous 4D mapping from input to target video frames and extends generalizable static NVS pipelines to this setting. GRVS's architecture incorporates two main innovations: an explicit recurrent loop and dynamic plane sweep volumes (DPSV).
Recurrent Framework
The recurrent structure propagates a learned hidden representation between target frames. At each inference step, the network assimilates information from both global (large temporal context) and local inputs via controlled selection of temporally-dilated frames, dynamically balancing static and dynamic region reconstruction. Recurrence brings three dividends:
- Efficient computation through reuse of previously generated renderings.
- Aggregation of temporal context, decoupling dynamics from viewpoint changes.
- Enhanced temporal coherence in generated videos.
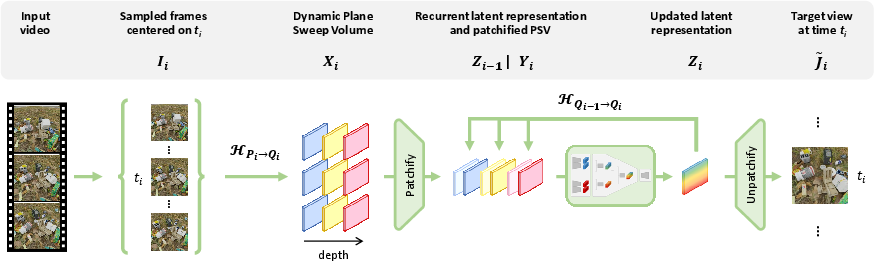
Figure 2: The GRVS pipeline for predicting a novel target view comprises staged input selection, DPSV generation, patchification, recurrent latent rendering, and image decoding.
Dynamic Plane Sweep Volumes
DPSV serve as a differentiable multi-view encoding: input images are projected onto multiple depth planes relative to the target view, capturing the geometry in a 5D tensor. DPSV disentangle camera and scene motion—static scene components remain sharp across planes; dynamic elements become defocused, providing explicit spatiotemporal cues for the network to focus its capacity accordingly.


Figure 3: DPSV encode projective relationships between multi-temporal input images and the target camera, making static elements sharp and dynamic objects blurry, aiding camera-scene motion disentanglement.
Patchification further reduces computational cost by processing spatial chunks independently at train and test time. The recurrent Unet backbone fuses DPSV and the projected recurrent state for view synthesis, followed by unpatchification to reconstruct the output image.
Datasets and Experimental Protocol
GRVS is evaluated on UCSD (real) and the new Kubric-4D-dyn (synthetic) datasets, the latter generated to provide high-resolution (512×512), high-dynamic-content multi-view sequences with diverse, unconstrained camera and object motion. This dual-dataset approach ensures model generalization and robustness to challenging real-world and simulated dynamics.
Results and Comparative Analysis
UCSD Experiments: GRVS outperforms state-of-the-art 4D Gaussian Splatting methods (D-3DGS, SC-GS, 4DGS) and achieves on-par or lower error than DynIBaR on the UCSD test set, without scene-specific optimization or reliance on extraneous priors such as explicit depth/optical flow. Notably, all GS-based methods degrade significantly in reconstructing dynamic regions due to their reliance on sparse, static-camera sequences. GRVS maintains accurate reconstruction even in the presence of challenging motion and sparse observations.







Figure 4: GRVS predictions on UCSD vastly improve dynamic element fidelity versus baseline 4DGS models, matching the ground-truth.
Kubric-4D-dyn Experiments: On synthetic sequences with complex geometry and dynamic content, GRVS not only surpasses all evaluated GS-based methods on both static and dynamic regions but also consistently outperforms recent diffusion-based video models (GCD, Gen3C). While point-cloud conditioned diffusion approaches generate visually plausible but geometrically incoherent result, GRVS preserves both fine spatial structure and temporal consistency, including for motion trajectories far from the input camera path.

































Figure 5: Qualitative evaluation on Kubric-4D-dyn shows GRVS outperforms both Gaussian Splatting and diffusion-based baselines in capturing geometric detail and motion fidelity.
Quantitatively, GRVS achieves the highest PSNR, SSIM, and lowest LPIPS on both full images and dynamic masks, particularly as the evaluation viewpoint deviates from input trajectories. This robustness is absent in all prior methods.
Analysis of Recurrent and Architectural Components
Ablation studies reveal recurrence as the key for integrating large temporal context, yielding monotonic increases in both static and dynamic region PSNR with iterative passes over shrinking dilation factors, a property not observed in purely feedforward architectures.
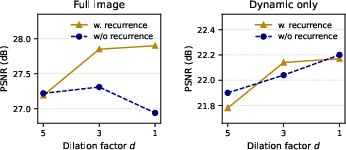
Figure 6: Recurrence experiment: PSNR increases with iteration and context when recurrence is enabled.
Patchification trades off accuracy and inference speed; increases in number of input views and depth planes benefit reconstruction but at computational cost. The design supports flexible deployment for high-resolution, real-time tasks.
Theoretical and Practical Implications
By eschewing explicit geometric priors, GRVS demonstrates that lightweight, geometry-aware NVS is feasible using recurrence and DPSV alone. It sidesteps diffusion models’ resource intensity and ambiguity in camera control, achieving fine-grained, six-DoF free viewpoint synthesis unconstrained by fixed training trajectories. The recurrence module brings the benefits of temporal smoothing, traditionally restricted to post-processing, into the rendering backbone with minimal parameter inflation (~40M parameters, 3 FPS on high-end GPUs).
Practically, this unlocks real-time, scalable, casual NVS on both synthetic and real dynamic videography, with substantial implications for AR/VR and video editing pipelines.
Conclusion
GRVS provides a scalable, efficient, and generalizable framework for monocular dynamic NVS, clearly outperforming both classical scene-specific 4D reconstruction models and the latest diffusion-based generative pipelines. The integration of recurrent architectures with dynamic plane sweep encoding facilitates disentanglement of camera and scene motion, robust aggregation of temporal context, and accurate free-viewpoint dynamic rendering. This positions geometry-aware, feedforward models as a central paradigm for future dynamic view synthesis, eschewing heavy reliance on generative priors and computationally expensive optimization.