Infinite-Homography as Robust Conditioning for Camera-Controlled Video Generation
Abstract: Recent progress in video diffusion models has spurred growing interest in camera-controlled novel-view video generation for dynamic scenes, aiming to provide creators with cinematic camera control capabilities in post-production. A key challenge in camera-controlled video generation is ensuring fidelity to the specified camera pose, while maintaining view consistency and reasoning about occluded geometry from limited observations. To address this, existing methods either train trajectory-conditioned video generation model on trajectory-video pair dataset, or estimate depth from the input video to reproject it along a target trajectory and generate the unprojected regions. Nevertheless, existing methods struggle to generate camera-pose-faithful, high-quality videos for two main reasons: (1) reprojection-based approaches are highly susceptible to errors caused by inaccurate depth estimation; and (2) the limited diversity of camera trajectories in existing datasets restricts learned models. To address these limitations, we present InfCam, a depth-free, camera-controlled video-to-video generation framework with high pose fidelity. The framework integrates two key components: (1) infinite homography warping, which encodes 3D camera rotations directly within the 2D latent space of a video diffusion model. Conditioning on this noise-free rotational information, the residual parallax term is predicted through end-to-end training to achieve high camera-pose fidelity; and (2) a data augmentation pipeline that transforms existing synthetic multiview datasets into sequences with diverse trajectories and focal lengths. Experimental results demonstrate that InfCam outperforms baseline methods in camera-pose accuracy and visual fidelity, generalizing well from synthetic to real-world data. Link to our project page:https://emjay73.github.io/InfCam/








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Infinite-Homography as Robust Conditioning for Camera-Controlled Video Generation”
Overview
This paper is about a new way to change how a camera moves in a video after the video has already been recorded. Think of it like editing your video so the camera smoothly backs up, swings around, or zooms out—even if the original camera didn’t do that. The authors introduce a method called IHCG that makes these edits look realistic and follow the exact camera path you want.
Objectives and Research Questions
The paper asks:
- How can we change the camera’s viewpoint in a video so it exactly matches a user’s chosen path (like rotating, moving forward, or zooming), without messing up what the scene looks like?
- Can we avoid relying on depth (how far things are) estimates, which often contain errors and cause visual glitches?
- Can we train a model to work well across many different camera movements and zoom levels, not just the ones found in limited training datasets?
Methods and Approach (explained with everyday analogies)
The authors build on a powerful video-generating AI model and add two key ideas to control the camera accurately:
- Infinite Homography Warping (the rotation trick)
- Imagine turning your head without moving your body: the world appears to rotate, but how far away things are doesn’t matter for that rotation. “Infinite homography” is a mathematical way to align the video to the new camera rotation without needing depth.
- The model first “warps” (reorients) the video’s hidden features to match the requested camera rotation. This removes the biggest source of error.
- Then it only has to learn the smaller part: how things shift when the camera moves through space (parallax), which does depend on distance. This “parallax” is like how nearby objects seem to slide more than faraway ones as you walk.
- Smart Data Augmentation (more varied practice)
- Many datasets have limited, repetitive camera moves (like always starting from the same position). That makes models biased—they get stuck recreating the first frame or the original zoom.
- The authors created a new training setup by mixing and matching parts of existing synthetic video datasets to produce diverse camera paths (backwards, arcs, rotations) and different focal lengths (zoom levels). This gives the model richer “practice,” so it generalizes better.
How it’s implemented (in simple terms):
- The base video model is kept mostly frozen, so it retains its strong visual quality.
- A camera encoder tells the model what rotation, movement, and focal length (zoom) the target camera should have.
- A special “homography-guided attention” layer helps the model stay aligned frame-by-frame, using the warped rotation version as a clean reference and focusing only on the small shifts caused by movement.
Main Findings and Why They’re Important
Here are the core results, explained simply:
- More accurate camera control: The new method follows the requested camera path more precisely than other leading methods. The camera rotates and moves exactly as instructed.
- Better visual quality: Generated videos look clearer and more consistent over time, with fewer glitches.
- Works without depth maps: Because it avoids depending on depth estimates (which are often wrong), it reduces artifacts like wobbling, stretching, or misaligned objects.
- Generalizes to real-world videos: Even when tested on internet videos (which don’t come with camera info), the method still works well, showing strong pose accuracy and good visuals.
This matters because editors, creators, and filmmakers can:
- Reframe or stylize videos after filming, without expensive reshoots.
- Add smooth, cinematic movements (like pans, arcs, or rotations) that match a plan or storyboard.
- Keep scenes stable and consistent across frames while changing viewpoint.
Implications and Potential Impact
- Practical video editing: IHCG can become a tool for post-production, making camera moves flexible and reliable after the fact.
- Less reliance on perfect 3D: By separating rotation (which doesn’t need depth) from translation (which the model learns robustly), it bypasses a major pain point in current techniques.
- Better training strategies: The augmentation approach (varied trajectories and zoom levels) can improve other camera-control systems too, reducing dataset bias.
- Future directions: Extending this to longer videos or more extreme camera motions could make virtual camera work even more powerful—imagine smoothly “flying” a camera through a scene captured on a phone.
In short, IHCG offers a cleaner, smarter way to edit camera movement in videos, making the results more accurate and visually pleasing, without depending on fragile depth estimates.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for follow-up research:
- Sensitivity to camera intrinsics errors: The method assumes known and accurate intrinsics (, ). Real-world intrinsics were estimated with UniDepth at inference, but no robustness analysis was conducted. Quantify performance degradation under noise in focal length, principal point, skew, and radial distortion, and explore self-calibration or intrinsics-robust conditioning.
- Non-pinhole and non-global-shutter cameras: The framework assumes a central pinhole, global-shutter model. Evaluate and extend IHCG to handle rolling shutter, lens distortion, digital stabilization, and variable intrinsics across frames (e.g., smartphone zoom/crop pipelines).
- Large-baseline translations and severe occlusions: Infinite homography handles rotation; translation/parallax are learned implicitly. Characterize failure regimes for large and near-field content, and investigate geometry-aware constraints or explicit occlusion/disocclusion handling to improve fidelity under strong parallax.
- Implicit depth learning without explicit geometry outputs: The claim of “implicit refinement” of depth is not validated. Measure the induced depth (e.g., via photometric/epipolar consistency) and assess whether adding geometric losses or weak supervision improves pose fidelity and scene consistency.
- Long-horizon temporal consistency and drift: The warping module description suggests special handling of the initial frame latent; it is unclear how drift accumulates over long sequences. Evaluate on longer sequences (hundreds–thousands of frames), and test per-frame warping or recurrent state to mitigate drift and maintain global pose coherence.
- Domain generalization beyond synthetic training: Training relies on synthetic UE5 data (MCV) and internal augmentation (AugMCV). Systematically test on diverse real datasets (handheld footage, sports, documentaries) with varied motion blur, grain, lighting, and dynamic content; assess domain adaptation strategies and data mixing ratios.
- Evaluation dependence on external estimators: Camera pose fidelity on WebVid is measured via ViPE-estimated trajectories. Quantify metric sensitivity to estimator errors, add alternative pose estimators, and—where possible—use scenes with ground-truth camera trajectories for validation.
- Appearance and identity preservation under viewpoint changes: While the paper argues improved “source appearance” maintenance, no explicit metrics (e.g., identity consistency, feature matching) are reported. Introduce identity/appearance consistency measures for people/objects across generated viewpoints.
- Disocclusion and hallucination quality: The approach relies on generative filling of previously unseen regions. Evaluate content plausibility in disoccluded areas (e.g., via semantic consistency, object permanence metrics) and investigate constraints to reduce hallucinations.
- Text conditioning effects: Prompts are extracted from source videos via LLaVA, but their impact on adherence to camera control vs. content fidelity is not studied. Ablate prompt quality, prompt-free conditioning, and mismatched prompts to quantify effects on pose and appearance.
- Intrinsics augmentation scope: Focal length augmentation only increases focal length and does not vary principal point, skew, aspect ratio, or distortion. Expand intrinsics augmentation to a fuller intrinsics model and evaluate the gains from each component separately.
- Robustness to per-frame intrinsics variation: Real videos may have frame-wise changes from stabilization/cropping. Test and adapt IHCG to per-frame variations and propose strategies for time-varying intrinsics conditioning.
- Computational efficiency and scalability: Training/inference costs and memory footprints are not reported. Benchmark runtime, GPU/VRAM requirements, and scaling behavior at higher resolutions (e.g., 4K) and longer durations, and explore pruning/distillation for practical deployment.
- Backbone dependence: IHCG is implemented on Wan2.1 with frozen weights. Assess portability to other video diffusion backbones (e.g., SDV, Sora-like models), the effect of fine-tuning vs. freezing, and whether homography-guided attention generalizes across architectures.
- Latent-space warping design choices: Only the warped latent is used inside the custom attention and then discarded downstream. Compare against alternatives (retaining warped latents deeper, multi-scale warping, image-space warping, feature-level skip connections) and quantify aliasing/interpolation effects for large rotations.
- Camera parameterization: Rotations are encoded as flattened 3×3 matrices. Evaluate alternative parameterizations (quaternions, axis-angle, Lie algebra) for numerical stability and training effectiveness, and test normalization/orthogonality constraints.
- Trajectory diversity and realism: AugMCV’s reversal-and-concatenation may introduce non-physical temporal patterns. Examine how trajectory statistics affect learning (smooth vs. jerky motion, acceleration profiles), and add physically plausible, user-like camera paths (dolly, crane, handheld jitter).
- Reproducibility and data availability: AugMCV is central to the reported gains yet appears unreleased. Publish the augmentation code, dataset splits, and pose/intrinsics generation details to enable fair reproduction and comparative benchmarking.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage IHCG’s depth‑free, camera‑controlled video generation today. For each, we note sector fit, potential tools/workflows, and key assumptions/dependencies that affect feasibility.
Media and Entertainment (Post‑production, VFX, Social Video)
- Virtual camera moves in post from a single take (e.g., dolly, orbit, tilt/pan)
- Tools/products/workflows: NLE/VFX plugins for Adobe Premiere/After Effects/DaVinci; a “Camera Path Editor” timeline that exports target trajectories; batch processing API for studios.
- Assumptions/dependencies: Requires approximate intrinsics (calibration or auto‑estimation); best for moderate translations/rotations and scenes with sufficient texture; GPU inference.
- Automated reframing and aspect‑ratio adaptation with pose fidelity (e.g., 16:9 → 9:16 with realistic FOV changes)
- Tools/products/workflows: Social/video platforms integrate IHCG as a server‑side filter; mobile app for “post‑capture camera control.”
- Assumptions/dependencies: Intrinsics estimation accuracy, particularly focal length; potential artifacts under extreme FOV changes.
- Salvaging takes and continuity fixes (matching B‑roll camera motion to A‑roll without reshoots)
- Tools/products/workflows: VFX pipelines use homography‑guided attention as a node; timeline‑based pose matching.
- Assumptions/dependencies: Stable lighting and appearance across clips; moderate scene dynamics.
- Cinematography education and previz
- Tools/products/workflows: Interactive teaching modules showing how infinite homography isolates rotation and how parallax shapes motion; UE/Blender plug‑ins for previsualization.
- Assumptions/dependencies: None beyond compute and footage access.
Advertising, eCommerce, Real Estate
- Multi‑angle product videos from a single pass (spin/orbit, zooms)
- Tools/products/workflows: SaaS that ingests one studio shot and exports view‑diverse clips; Shopify/marketplace plug‑ins.
- Assumptions/dependencies: Small to moderate camera translations to avoid hallucination; consistent lighting/backgrounds.
- Smooth virtual tours and fly‑throughs from handheld footage
- Tools/products/workflows: Real estate apps that author smooth arcs/zooms from raw videos; automatic pose trajectories (presets).
- Assumptions/dependencies: Scene coverage in the source video; caution with occlusions and narrow spaces.
Broadcast and Sports (Editorial, Highlights)
- Alternate camera angles for replays from a single camera feed (storytelling, not measurement)
- Tools/products/workflows: Replay tools with trajectory presets (orbit, pull‑back) and pose timeline; server‑side batch generation.
- Assumptions/dependencies: Editorial use only—generated views are not ground truth; need on‑screen labels/watermarks for transparency.
XR/Immersive Content
- Pseudo‑6DoF monoscopic experiences: authoring constrained camera paths for immersive replays
- Tools/products/workflows: VR content pipelines apply IHCG for small baseline changes; author path with FOV changes.
- Assumptions/dependencies: Works best for small translations; not a substitute for true multi‑view capture.
Robotics and Autonomy (R&D, Data Augmentation)
- Viewpoint augmentation for perception models (pose‑controlled synthetic variants from real robot videos)
- Tools/products/workflows: Training data pipelines generate pose‑diverse clips; synthetic‑to‑real robustness tests.
- Assumptions/dependencies: Not suitable where geometric accuracy is critical; label as synthetic to avoid data leakage.
Research and Academia
- Depth‑free camera control baselines for video diffusion
- Tools/products/workflows: Homography‑guided attention module integrated into open‑source video diffusion frameworks; reproducible augmentation pipeline (trajectory + intrinsics).
- Assumptions/dependencies: Access to a capable base model (e.g., Wan2.1 or equivalent) and compute.
Mobile and Creator Tools
- “AI Camera Moves” on smartphones for post‑capture effects (dolly zoom/orbit/arc)
- Tools/products/workflows: On‑device or cloud offload; automatic captioning of source video (e.g., via LLaVA) if the base model needs text.
- Assumptions/dependencies: Edge acceleration or fast uplink; battery/latency trade‑offs.
Long‑Term Applications
These concepts build on IHCG’s innovations but typically require further research, scaling, integration, or validation before deployment.
Live and Real‑Time Systems
- Real‑time, low‑latency camera‑controlled generation for live broadcasts
- Potential: Replay and editorial effects during events; director‑controlled camera paths on the fly.
- Dependencies: Model compression/acceleration, multi‑GPU or specialized hardware; robust intrinsics/pose estimation on live feeds.
Full 6DoF and Large‑Baseline Free‑Viewpoint Video
- Interactive free‑viewpoint video with accurate parallax and occlusions
- Potential: Hybridization of IHCG with explicit geometry (NeRFs, dynamic 4D reconstruction) for large translations.
- Dependencies: Reliable depth or learned 4D scene priors; multi‑shot or multi‑view inputs; occlusion reasoning.
Telepresence and Robotics Operations
- Operator‑controlled synthetic views in teleoperation and remote inspection
- Potential: Safer situational awareness with adjustable viewpoints.
- Dependencies: Trustworthy failure modes; certification; tight latency bounds; domain‑specific validation.
Surgical/Clinical Video Augmentation
- Alternative vantage points in surgical recordings and training simulators
- Potential: Enhanced teaching and review of procedures.
- Dependencies: Strict validation and regulatory approval; clear disclaimers to prevent clinical misinterpretation.
Autonomous Driving and Simulation
- Generation of surround‑view or alternative vantage training clips from single‑dashcam inputs
- Potential: Data efficiency for rare scenarios and corner cases.
- Dependencies: Safety‑critical fidelity; hybrid depth constraints; rigorous bias and error analysis.
Standards, Policy, and Provenance
- Camera‑trajectory metadata and provenance standards for generated videos
- Potential: Embed target trajectories, intrinsics, and model provenance; interoperable audit trails.
- Dependencies: Industry adoption, standards bodies (e.g., C2PA), watermarking/signature tech.
Creative Tooling and Workflow Automation
- “Camera choreography assistants” that translate text/storyboards into pose‑timelines
- Potential: Co‑pilot UX integrating text‑to‑trajectory, music beats, and scene semantics.
- Dependencies: Robust trajectory priors; multimodal alignment; user‑in‑the‑loop controls.
Education Platforms
- Interactive labs for epipolar geometry and cinematography
- Potential: Students manipulate homography and parallax and instantly see outcomes.
- Dependencies: Lightweight, classroom‑ready versions; open content.
Open Data and Benchmarks
- Community datasets with diversified trajectories and intrinsics for camera‑controlled generation
- Potential: Standardized evaluation of pose fidelity and visual quality.
- Dependencies: Licensing for base content; compute for large‑scale generation.
Edge and On‑Device Inference
- On‑device IHCG for wearables and AR glasses
- Potential: Personal media enhancement; low‑power camera control effects.
- Dependencies: Model distillation/quantization; dedicated NPUs; memory constraints.
Notes on Feasibility and Dependencies
- Scene coverage and motion scale: IHCG excels with moderate camera motion and sufficient visual coverage; large translations or unseen/occluded areas may cause hallucinations.
- Intrinsics and pose inputs: Reliable source intrinsics (estimated or calibrated) and a well‑specified target trajectory are critical; wrong intrinsics reduce fidelity, especially for FOV changes.
- Dynamic scenes: Moving objects and complex occlusions are challenging; expect artifacts where geometry must be inferred.
- Compute and licensing: High‑quality results depend on a strong video diffusion backbone (e.g., Wan2.1) and GPU resources; model and dataset licenses must be respected.
- Safety and disclosure: Generated viewpoints are not ground truth. For journalism, sports analytics, medical, or legal contexts, require visible disclosure, watermarking, and metadata provenance.
Glossary
- Camera embeddings: Learned vectors that encode camera parameters and are added to model latents to condition generation on pose and intrinsics. "then add camera embeddings for translation."
- Camera encoder: A network module that encodes camera parameters (rotation, translation, intrinsics) into embeddings used by the model. "We employ a camera encoder consisting of a linear layer with 16-dimensional input"
- Camera intrinsics: The internal calibration parameters of a camera (e.g., focal lengths and principal point) represented by a matrix. "source and target camera intrinsics "
- DiT block: A Diffusion Transformer block used in video diffusion architectures for processing latents with attention. "DiT block with homography-guided self-attention layer."
- Diffusion model: A generative model that synthesizes data (here, videos) by reversing a gradual noising process. "conditions a video diffusion model on these renderings"
- End-to-end training: Training a system so that gradients flow through all components jointly, enabling unified optimization. "End-to-end training enables the network to implicitly refine the 3D geometry"
- Epipole: The image of one camera’s center in the other view; the point where all epipolar lines intersect. "This parallax is confined to the region between the epipole and "
- Epipolar line: A line in the image along which a point’s correspondence must lie in the other view. "as visualized by the yellow segment on the epipolar line ."
- FID: Fréchet Inception Distance, a metric for assessing the quality of generated images by comparing feature distributions. "we evaluate perceptual fidelity using FID for frame-level quality"
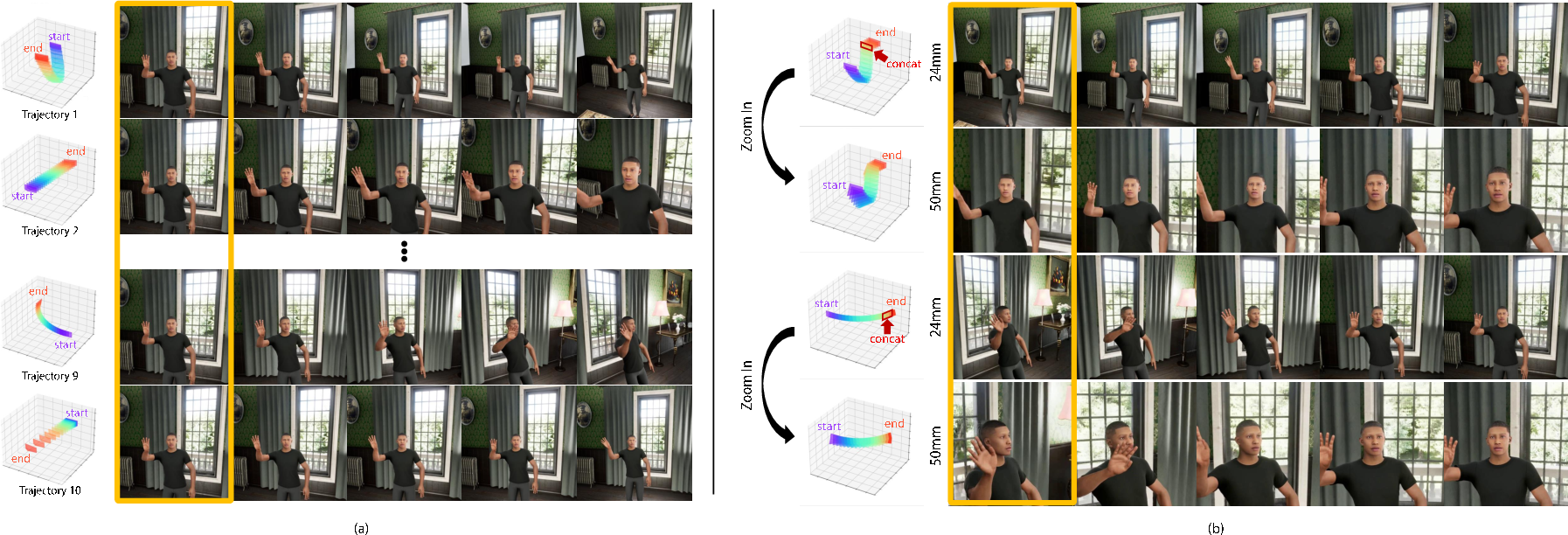
- Focal length: A camera intrinsic controlling magnification and field of view; shorter focal length yields wider views. "The rotational trajectory is generated with a shorter focal length to illustrate wide field-of-view generation."
- FVD: Fréchet Video Distance, a metric for evaluating video-level generative quality. "and FVD for video-level quality."
- Homography: A projective transformation mapping points between two images of a plane or under pure rotation. "the plane-induced homography "
- Homography-guided self-attention: An attention mechanism that incorporates homography-warped inputs to improve pose-aware reasoning. "Homography-guided self-attention layer"
- Infinite homography: The homography induced by the plane at infinity, depending only on rotation and intrinsics. "The infinite homography represents the homography induced by the plane at infinity "
- Inpainting: Filling or synthesizing missing or unobserved regions in an image or video. "predicted or inpainted to produce the final rendered video."
- Intrinsic augmentation: Data augmentation that changes camera intrinsics (e.g., focal length) via resizing and cropping to improve generalization. "Intrinsic augmentation is performed by resizing the video based on the ratio of source and target focal lengths, followed by center cropping."
- Latent representation: The hidden feature tensor processed by the model, encoding content and conditioning information. "For the latent representation "
- LPIPS: Learned Perceptual Image Patch Similarity, a metric measuring perceptual similarity between images. "using PSNR, SSIM, and LPIPS"
- Parallax: Apparent relative motion of scene points due to camera translation, inversely related to depth. "The term represents the parallax relative to the plane at infinity."
- Plane at infinity: An ideal plane in projective geometry representing directions at infinity; used to define infinite homography. "the plane at infinity "
- Pose fidelity: The accuracy with which generated views match the specified camera pose. "achieves high pose fidelity."
- Principal point: The pixel coordinates of the optical center in the image (camera intrinsic). "principal points , "
- PSNR: Peak Signal-to-Noise Ratio, a distortion metric comparing a generated video to ground truth. "using PSNR, SSIM, and LPIPS"
- Reprojection: Mapping pixels from one camera view to another using estimated depth and camera motion. "reprojects the resulting 3D structure along a target camera trajectory."
- SE(3): The group of 3D rigid body transformations combining rotation and translation. "Target camera trajectory is defined in a special Euclidean space "
- Spatio-temporal 3D cache: A representation that stores reconstructed 3D content over time to support controlled rendering. "builds a spatio-temporal 3D cache from videos via depth estimation and unprojection"
- UniDepth: A method used to estimate camera intrinsics (and depth) from monocular data at inference time. "we estimate the source intrinsics at inference time using UniDepth"
- Unprojection: Converting image pixels with depth into 3D points in camera or world coordinates. "depth estimation and unprojection"
- ViPE: A tool for estimating camera trajectories from videos to evaluate pose accuracy. "estimated from the generated videos using ViPE"
- Warping module: A component that warps latents using infinite homography to encode rotation before learning residual parallax. "Warping module. This module warps the input latent with infinite homography"
- World coordinate origin: The reference point in world coordinates used to define camera poses and trajectories. "The world coordinate origin is defined by the first frame's camera pose"
Collections
Sign up for free to add this paper to one or more collections.

