NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Abstract: In this paper, we propose NeoVerse, a versatile 4D world model that is capable of 4D reconstruction, novel-trajectory video generation, and rich downstream applications. We first identify a common limitation of scalability in current 4D world modeling methods, caused either by expensive and specialized multi-view 4D data or by cumbersome training pre-processing. In contrast, our NeoVerse is built upon a core philosophy that makes the full pipeline scalable to diverse in-the-wild monocular videos. Specifically, NeoVerse features pose-free feed-forward 4D reconstruction, online monocular degradation pattern simulation, and other well-aligned techniques. These designs empower NeoVerse with versatility and generalization to various domains. Meanwhile, NeoVerse achieves state-of-the-art performance in standard reconstruction and generation benchmarks. Our project page is available at https://neoverse-4d.github.io








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces NeoVerse, a “4D world model.” In simple terms, it’s a system that turns regular videos from a single camera (like a phone) into a moving 3D scene you can explore from new camera angles. It can also help make new, high‑quality videos that stay consistent over time and space, and it supports handy tools like video editing, stabilization, and super‑resolution.
Think of NeoVerse like building a tiny moving 3D diorama from a regular video, then letting you move a virtual camera through that diorama to create new shots.
What were they trying to do?
The authors saw two big problems with existing methods that try to make 3D/4D (3D over time) scenes from videos:
- They needed special, hard‑to‑collect data (like many synchronized cameras filming at once), which doesn’t scale well.
- They required heavy, slow pre-processing before training, which made it hard to train on lots of everyday videos.
So they asked: Can we build a 4D system that:
- Works directly on ordinary, single‑camera (“monocular”) videos from the internet,
- Trains efficiently without long pre‑processing,
- Keeps videos stable and consistent when making new views,
- And performs well across many different scenes?
How did they do it?
The NeoVerse pipeline has two main parts: reconstruction (building the 4D scene) and generation (making new, clean videos from rough renders). Here’s how each piece works, with simple analogies.
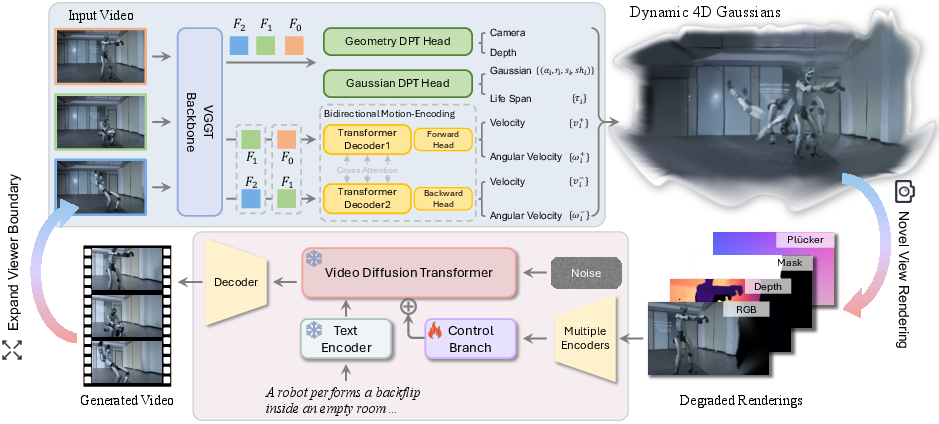
1) Pose‑free, feed‑forward 4D reconstruction
- Monocular video: A plain video from one camera.
- Feed‑forward: The model processes the video in one pass, rather than optimizing for each scene for a long time.
- Pose‑free: It doesn’t require known camera positions ahead of time.
NeoVerse uses a backbone (VGGT) to understand geometry, then “Gaussianizes” it. What does that mean?
- 4D Gaussians: Imagine the scene as lots of tiny, colored, soft “puffballs” (Gaussians) floating in 3D space. Over time (the 4th dimension), they can move and rotate. Each puffball has:
- A position, size, color, and transparency,
- Plus a “life span” (when it appears/disappears),
- And forward/backward motion (where it’s going and where it came from).
This “puffball” model makes rendering fast and flexible.
- Bidirectional motion modeling: The system learns motion both forward and backward in time. That helps smooth interpolation between frames and supports time‑based controls (like slow motion).
- Sparse keyframes for speed: Instead of reconstructing from every frame (which is slow), the model uses just a few keyframes to build the 4D scene, then fills in the rest by smartly interpolating movement using the learned forward/backward motion. You can think of it like plotting a few points on a path and drawing the smooth curve between them.
2) Reconstruction‑guided video generation
The second part is a video generator that turns rough “preview” renders into sharp, high‑quality videos from new camera paths (“novel trajectories”). To make that work with single‑camera videos, NeoVerse does something clever:
- Degradation simulation: During training, NeoVerse intentionally makes the “preview” renders worse in realistic ways, so the generator learns to fix them. Two simple examples:
- Visibility‑based culling: When you move the virtual camera, some parts become hidden. NeoVerse removes “puffballs” that would be hidden, leaving holes. The generator learns to plausibly fill those in.
- Average geometry filter: Around object edges, depth can be messy and cause “flying pixels.” NeoVerse simulates this by averaging depth in those regions, creating realistic artifacts for the generator to learn to clean up.
- Control branch: These rough renders (RGB, depth, and masks for empty areas), plus simple camera motion signals, are fed into a large video model via a “control branch.” The generator is trained to use these hints to produce clean, consistent videos that follow the desired camera path.
Training and inference extras
- Training in two stages: First, train the reconstruction model on diverse static and dynamic datasets. Second, train the generator using on‑the‑fly reconstruction and degradation simulation on many internet videos.
- Global motion tracking: At test time, NeoVerse separates static background from moving objects more reliably, improving aggregation of the “puffballs” across time.
- Temporal aggregation and interpolation: It can merge frames for more complete 3D, and handle time tricks (like slow motion) using its bidirectional motion.
What did they find?
- Strong reconstruction quality: On both static and dynamic benchmarks, their reconstruction (the 4D “puffball” scene) produced higher fidelity than other methods, with better pose (camera) estimates and fewer visual artifacts.
- Strong generation quality and control: Compared to other systems:
- Methods that prioritize camera control often look less clean,
- Methods that look very clean often can’t follow a precise camera path.
- NeoVerse balances both: it generates high‑quality videos while following the camera trajectory accurately.
- Much faster inference: Because it reconstructs from sparse keyframes and uses fast rendering plus a control branch, NeoVerse runs faster than comparable systems.
- Works on “in‑the‑wild” data at scale: The pipeline was designed to work on a large set of ordinary internet videos (over 1 million clips), without heavy pre‑processing. This helps the model generalize to many real‑world scenes, including challenging ones like people in motion.
- Rich applications: With its 4D scene and generator, NeoVerse supports:
- Novel‑view video generation (move the camera however you like),
- Video editing (change objects using masks and text),
- Video stabilization (smooth camera paths),
- Super‑resolution (render at higher resolution),
- 3D tracking (follow objects in 3D over time),
- Background extraction, and more.
Why does this matter?
- Scalable and practical: By avoiding special multi‑camera setups and heavy offline steps, NeoVerse can learn from the kinds of videos people actually record. That makes it more useful and easier to improve over time.
- Consistent and controllable: It keeps objects stable across frames and lets you precisely control the camera. That’s important for filmmaking, virtual tours, simulation, robotics, and AR/VR.
- A foundation for creative tools: Because it builds a 4D model you can render from any angle, it’s a powerful base for editing, upscaling, and creating new content that feels grounded in the original scene.
Limitations
- It relies on real 3D cues in the video. It doesn’t work well on flat 2D content like cartoons that don’t contain 3D structure.
- While trained on a large dataset, even more data could improve it further.
Takeaway
NeoVerse is a new way to turn everyday videos into explorable, moving 3D scenes and to generate high‑quality, stable videos from new camera paths. By designing the whole pipeline to work directly and efficiently on single‑camera videos, it’s both scalable and versatile—pushing forward what’s possible in video creation, editing, and world modeling. The authors also plan to release the code, which can help the community build even better 4D tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide follow-up research:
- Applicability to non-3D content: The method assumes data with recoverable 3D structure and is inapplicable to 2D cartoons or stylized content; how to extend to non-physical or weak-geometry domains (e.g., via learned priors or style-aware geometric surrogates) is open.
- Motion modeling assumptions: Inter-frame motion is assumed locally linear with constant angular velocity; investigate non-linear motion fields, piecewise or spline-based temporal models, and learned deformation fields for fast, non-rigid, or long-interval motion.
- Scale ambiguity and camera modeling: The pose-free monocular setup implies unknown absolute scale and potential intrinsics/extrinsics errors; quantify pose/intrinsics accuracy (vs. COLMAP/GT), study scale alignment strategies, and assess robustness to rolling shutter/lens distortion/auto-exposure.
- Degradation simulation realism: The visibility culling and average-geometry filters are heuristic; quantify how well they match real novel-view artifact distributions, benchmark each component’s contribution, and explore learned, data-driven degradation simulators.
- Extreme trajectory generalization: Limits under large out-of-distribution camera motions (large baselines, extreme rotations, far extrapolations) are not characterized; define failure envelopes and training-time augmentation or constraint strategies.
- Long sequence drift and consistency: Online reconstruction from sparse keyframes may accumulate drift in long clips; study loop-closure, global alignment, or keyframe resectioning schemes and quantify temporal consistency over minutes-length videos.
- Keyframe selection policy: The strategy to choose K keyframes is unspecified; evaluate adaptive selection (e.g., motion/entropy-aware), its effect on quality/speed, and provide bounds on maximal frame gaps before quality degradation.
- Static–dynamic separation robustness: Global motion tracking relies on a threshold on visibility-weighted max velocity; analyze sensitivity to the threshold, cases with intermittent motion, and develop learned segmentation or joint optimization to reduce misclassification.
- Material and illumination modeling: 3DGS with SH limits specular/transparent/anisotropic effects and time-varying illumination; evaluate on challenging materials and explore view-dependent appearance/BRDF models or relightable Gaussians.
- Handling of dynamic, non-rigid and topological changes: Performance under severe non-rigidity (cloth, fluids, crowds), topological events, or motion blur is underexplored; design stress tests and extensions (e.g., layered Gaussians, visibility-aware life-span learning).
- Quantitative camera pose evaluation: Only qualitative pose comparisons are shown; provide standardized pose/scale metrics and ablative links between pose errors and downstream generation quality.
- Evaluation breadth and baselines: Comparisons omit several contemporary methods due to availability; broaden baselines (including alternative feed-forward 4DGS) and add human studies alongside VBench to validate perceptual gains and camera-control fidelity.
- Dataset transparency and ethics: The 1M internet videos lack disclosed composition, licensing, consent, and bias analysis; release curation statistics, auditing tools, and ethical guidelines, or a de-identified subset where feasible.
- Reproducibility constraints: Code is promised but dataset is not; heavy reliance on proprietary large video models (Wan-14B) may limit reproducibility; evaluate alternative open generators and report sensitivity to the base model choice.
- Control-branch-only training: Freezing the base generator may cap attainable quality/control; compare against partial/full fine-tuning and hybrid adapters, and quantify quality–speed–stability trade-offs.
- Distillation/acceleration details: Acceleration via LoRA/distillation is stated but not detailed; report training/inference recipes, speed–quality curves on commodity GPUs, and real-time feasibility for target resolutions.
- Plücker embedding and modality ablations: Contribution of each conditioning modality (RGB/depth/mask/Plücker) is not quantified; perform modality and sparsity ablations to inform lighter, faster conditioning designs.
- Hyperparameter sensitivity: Opacity decay (γ), life-span bounds, motion-segmentation threshold (η), and degradation transform distributions lack sensitivity analyses; provide ranges and auto-tuning strategies.
- Robustness to photometric variations: Effects of auto-exposure, white balance shifts, compression artifacts, and sensor noise are not studied; add photometric robustness evaluations and augmentation strategies.
- 3D tracking evaluation: The proposed Gaussian-based 3D tracking is only visualized; benchmark on standard 3D MOT datasets with ID-switch, MOTA/HOTA, and long-occlusion recovery metrics.
- Super-resolution claims: SR is shown qualitatively; quantify SR with PSNR/LPIPS/NIQE at higher resolutions and analyze when rendering resolution exceeds learned appearance fidelity.
- Editing reliability and locality: Mask/text editing risks geometry drift or unintended changes; establish edit-fidelity/locality metrics and constraints to preserve unedited regions and camera control.
- Hallucination safety: “Contextually grounded imagination” can introduce non-existent content in occluded regions; develop controls (uncertainty-aware masking, user constraints) and evaluate hallucination rates and user trust.
- Memory and representation size: 4DGS storage/compute footprint per clip and streaming/compression strategies are not reported; profile memory, propose pruning/quantization, and assess trade-offs for deployment.
- Domain coverage and OOD generalization: Performance on egocentric, drone, driving, underwater, low-light, and adverse weather domains is not analyzed; create OOD test suites and domain-adaptive training protocols.
- Multi-camera or auxiliary inputs: The pipeline is monocular; explore optional multi-view, IMU, or event data to improve geometry and motion robustness when available.
- Audio–visual consistency: No handling of audio or synchronization; investigate conditioning or preservation of input audio under novel-view generation.
- Legal and licensing considerations: Clarify licenses for used backbones (VGGT, Wan, DINOv2) and resulting constraints on commercial/academic use; provide compliant alternatives where needed.
Practical Applications
Below are practical applications that emerge from NeoVerse’s findings and innovations. The items are grouped into Immediate Applications (deployable now, with existing tooling and workflows) and Long-Term Applications (requiring further R&D, scaling, or ecosystem development). Each entry notes the relevant sector, likely tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These applications can be prototyped or integrated today using NeoVerse’s pose-free, feed-forward 4DGS reconstruction; bidirectional motion modeling; sparse key‑frame reconstruction; online monocular degradation simulation; and control-branch conditioning for existing text-to-video models.
- NeoVerse Re-Cam and Stabilize for Creators
- Sector: Media/Entertainment, Software (post-production), Daily life
- Tools/Products/Workflows: NLE plugin (e.g., Adobe Premiere/After Effects, DaVinci Resolve), “NeoVerse Re-Cam” workflow that reconstructs a 4D scene from a single handheld clip, lets users edit the camera trajectory (pan/tilt/dolly), stabilize shaky footage, and export smooth reframed videos for different aspect ratios (e.g., vertical shorts).
- What it does: Feed-forward 4D reconstruction from a single video, novel-trajectory rendering, camera smoothing, artifact suppression via degraded rendering conditioning; supports bullet-time-like slow motion between frames using bidirectional motion interpolation.
- Assumptions/Dependencies: Real-world footage with coherent 3D geometry; GPU-backed inference; scene not dominated by stylized 2D content; licensing/compatibility with the target NLE; relies on foundation video models (e.g., Wan-T2V) and LoRA distillation for speed.
- Single-Clip Turntable for E-commerce
- Sector: Retail/E-commerce, Advertising
- Tools/Products/Workflows: “Product Spin” generator from smartphone clip; background extraction; super-resolution; multi-view renders for marketplace listings.
- What it does: Reconstructs product geometry from a quick smartphone pass; generates consistent multi-view “turntable” videos; edits colors/materials via mask+text control; upsamples to high quality while suppressing ghosting.
- Assumptions/Dependencies: Matte/non-transparent products perform best; constrained lighting; avoidance of heavy reflectivity or transparent materials which can break monocular depth assumptions.
- Free-View Sports Replay and Player Motion Analytics
- Sector: Sports analytics, Broadcast
- Tools/Products/Workflows: Broadcaster-side pipeline that reconstructs 4D scenes from monocular broadcast feeds; “free-viewpoint replays” of key plays; 3D tracking using Gaussian association and predicted 3D flow; camera path re-synthesis for analysis segments.
- What it does: Generates coach/broadcast replays from novel angles; measures trajectories, velocities; stabilizes and reframes broadcast footage.
- Assumptions/Dependencies: Adequate visual coverage without extreme occlusions; consistency across frames; GPU acceleration; compliance with broadcast rights and processing latency constraints.
- Real Estate Walkthrough Enhancement
- Sector: Real estate, PropTech
- Tools/Products/Workflows: Smartphone walkthrough enhancer that stabilizes, re-frames, and renders additional viewpoints; background separation; super-resolution; optional slow-motion tour segments.
- What it does: Converts a single walkthrough into smoother tours; renders supplemental vantage points (e.g., around corners); reduces motion jitter; produces consistent wide and vertical formats.
- Assumptions/Dependencies: Indoor scene geometry and lighting amenable to monocular reconstruction; privacy-safe processing; device/GPU availability for inference.
- Rapid Previz and Matchmove Aid for VFX
- Sector: Film/VFX
- Tools/Products/Workflows: On-set previz from a single clip; 4DGS reconstruction; global motion tracking for static/dynamic separation; occlusion-aware compositing; novel camera path previews in seconds using GSplat render backend.
- What it does: Faster previz for blocking; camera retiming and angle exploration; reliable occlusion masks from opacity maps; plug into existing VFX pipelines via depth/mask/RGB render layers.
- Assumptions/Dependencies: Works best for scenes with good texture and depth cues; integration with studio render pipelines; governance around AI-generated elements.
- Simulation-Ready Re-Camming of Driving Scenes (Data Augmentation)
- Sector: Autonomous driving, Robotics
- Tools/Products/Workflows: “Monocular re-cam” augmentation of dashcam datasets using online monocular degradation simulation and novel trajectory generation; control-branch injection to foundation video models; compatible with datasets like Waymo/Virtual KITTI.
- What it does: Produces diverse camera paths for the same scene to stress-test perception models; simulates occlusions via Gaussian culling; induces edge distortions to teach models artifact robustness.
- Assumptions/Dependencies: Domain gap handling (street scenes vs. training data); careful curation to avoid hallucination of safety-critical details; compliance with dataset licenses.
- Instructional Content Creation (Education)
- Sector: Education, STEM communication
- Tools/Products/Workflows: Lectures and labs augmented with world-consistent re-cams, slow-motion interludes, and free-view highlights generated from a single lab video; mask+text edits to annotate or emphasize objects.
- What it does: Makes complex spatial demonstrations easier to follow; stabilizes and reframes without requiring multi-camera setups; injects depth maps and masks for pedagogical overlays.
- Assumptions/Dependencies: Scenes with clear 3D structure; institutional computing resources; fair-use of recorded content.
- Privacy and Provenance Toolkit for Reconstructed Media
- Sector: Policy/Compliance, Trust & Safety
- Tools/Products/Workflows: Organization-level guidance to watermark synthetic re-cam content, label viewpoint changes, and log reconstruction/generation parameters for auditability.
- What it does: Provides immediate governance measures to prevent misleading “impossible shots” being mistaken for original footage; documents camera trajectory edits; reduces privacy risks by using synthetic novel views rather than collecting more raw footage.
- Assumptions/Dependencies: Buy-in from platforms to display provenance metadata; policy alignment with local regulations; user education.
Long-Term Applications
These opportunities benefit from NeoVerse’s core design but will require further advances in robustness, speed, datasets, hardware support, or integrations.
- Real-Time On-Device 4D World Modeling for AR Glasses
- Sector: AR/VR, Consumer hardware
- Tools/Products/Workflows: On-device feed-forward 4DGS with sparse key-frame updates; live re-cam and stabilization; occlusion-aware AR overlays.
- What it could do: Turn single-camera AR captures into spatially consistent overlays with accurate occlusion; enable “free-view” replay on wearable devices.
- Assumptions/Dependencies: Hardware acceleration for GSplat-like renderers; compact models (quantization/pruning); robust handling of reflective/translucent materials.
- Volumetric Broadcast from Single/Minimal Camera Rigs
- Sector: Sports/Broadcast, Live events
- Tools/Products/Workflows: Near-real-time free-viewpoint generation from limited camera feeds; integration with broadcast infrastructure; automated global motion tracking for moving crowds.
- What it could do: Deliver volumetric highlights without full multi-camera arrays; reduce production cost while improving viewer experience.
- Assumptions/Dependencies: Low-latency pipelines; large-scene dynamic handling; regulatory approval for AI-generated viewpoints; failure modes that don’t mislead audiences.
- Rehabilitation and Clinical Motion Analysis from Monocular Video
- Sector: Healthcare
- Tools/Products/Workflows: 3D tracking of patient movement in clinics or at home; slow-motion, free-view replays; quantified range-of-motion and gait metrics.
- What it could do: Lower-cost motion capture for physical therapy; remote monitoring and progress visualization; enhanced explainability for clinicians.
- Assumptions/Dependencies: Clinical validation and regulatory clearance; accuracy in diverse body types and clothing; careful handling of occlusions and assistive devices.
- Household Robot Mapping and Interaction via Monocular World Models
- Sector: Robotics (home/service), Smart home
- Tools/Products/Workflows: Monocular SLAM augmentation with feed-forward 4DGS; dynamic/static separation for better manipulation planning; viewpoint synthesis for planning and explainability.
- What it could do: Improve robots’ scene understanding from a single camera; plan paths around occlusions; simulate alternative viewpoints to anticipate hazards.
- Assumptions/Dependencies: Tight integration with robot perception stacks; real-time constraints; robustness to clutter, glass, mirrors, and non-Lambertian surfaces.
- Synthetic Training Data Generation at Scale (Risk-Coverage Expansion)
- Sector: Autonomous driving, Industrial inspection
- Tools/Products/Workflows: Large-scale re-cam and trajectory diversification of in-the-wild monocular datasets; artifact-aware conditioning to teach models to ignore geometric noise; scenario remixing (weather/time-of-day via downstream generative enhancement).
- What it could do: Reduce the need for expensive multi-view captures; expand corner-case coverage; systematically test model invariances to viewpoint shifts.
- Assumptions/Dependencies: Standards for synthetic data labeling and provenance; guarding against hallucinated safety-critical details; storage and compute scaling.
- Facility Digital Twins from Monocular Walkthroughs
- Sector: Energy/Utilities, Manufacturing
- Tools/Products/Workflows: 4D reconstruction of equipment states over time; free-view replays for inspection; anomaly localization via motion and opacity maps.
- What it could do: Low-cost digital twins for maintenance planning; temporal analysis of moving machinery; training for operators.
- Assumptions/Dependencies: Controlled capture protocols; integration with CAD/BIM; handling of reflective/transparent industrial surfaces; safety and IP considerations.
- Real Estate Appraisal and Space Analytics
- Sector: Finance/PropTech
- Tools/Products/Workflows: From a monocular walkthrough, generate a world-consistent 4D model to estimate room volumes, sightlines, and upgrade planning; produce standardized free-view tours for appraisals.
- What it could do: Augment appraisal workflows; help buyers visualize modifications; provide more objective spatial metrics.
- Assumptions/Dependencies: Accuracy bounds acceptable to regulators and insurers; standardized QC; privacy of occupants.
- Standards, Watermarking, and Auditing Frameworks for Synthetic Re-Cams
- Sector: Policy/Regulation, Platforms
- Tools/Products/Workflows: Industry standards for labeling AI-generated viewpoints; embed camera-trajectory provenance and Plücker-based motion descriptors; watermark renders and masks; audit trails for edits.
- What it could do: Build trust in AI-mediated video; reduce misinformation risk; enable safe adoption across news/broadcast/social platforms.
- Assumptions/Dependencies: Multi-stakeholder adoption; interoperability across toolchains; legal alignment across jurisdictions.
- 4D Content Marketplaces and Creative Tools
- Sector: Media/Entertainment, Creator economy
- Tools/Products/Workflows: Platforms that accept single videos and output controllable 4D assets; APIs exposing reconstruction, trajectory editing, and artifact-suppressed generation; template camera paths for storytelling.
- What it could do: Democratize volumetric storytelling; enable novel shots from minimal capture; monetize user-generated 4D content.
- Assumptions/Dependencies: Scalable compute; content moderation and provenance; licensing for foundation models used in generation.
Notes on Cross-Cutting Assumptions and Dependencies
- Scene constraints: NeoVerse targets content with valid 3D structure; performance degrades on 2D-stylized videos (e.g., cartoons) or extreme transparency/reflectivity.
- Compute and compatibility: Inference benefits from GPUs; practical deployments rely on GSplat (rendering), VGGT backbone, and foundation video models (e.g., Wan-T2V) with control branches and LoRA distillation.
- Data governance: In-the-wild monocular datasets must comply with privacy and licensing; synthetic outputs should carry provenance/watermarking where appropriate.
- Robustness: Bidirectional motion modeling and global motion tracking improve interpolation and dynamic/static separation but may need further tuning for crowded, fast-moving or highly complex scenes.
- Quality trade-offs: Artifact suppression depends on accurate degradation simulation (Gaussian culling, average geometry filtering); failure modes should be documented for safety-critical domains.
Glossary
- Alternating-Attention blocks: Transformer blocks that alternate attention across dimensions to aggregate features; used in VGGT for frame-wise feature processing. Example: "are fed into a series of Alternating-Attention blocks~\cite{vggt}, obtaining so-called frame features."
- Axis-angle representation: A way to represent rotations by an axis and an angle around it; often converted to quaternions for computation. Example: "Angular velocities are represented in the axis-angle representation, and converts it to a quaternion."
- Average Geometry Filter: A depth-averaging operation to simulate artifacts like flying pixels and spatial distortions in rendered views. Example: "Average Geometry Filter for flying-edge-pixel and distortion simulation."
- Bidirectional linear and angular velocity: Motion parameters predicting both forward and backward translation and rotation rates of Gaussian primitives. Example: "These features will be utilized to predict bidirectional linear and angular velocity of Gaussian primitives."
- Bidirectional motion modeling: A strategy that models motion in both temporal directions (t→t+1 and t→t−1) to enable interpolation and temporal coherence. Example: "we propose a pose-free feed-forward 4DGS reconstruction model (\cref{sec:recon}) with bidirectional motion modeling."
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) needed for projection and reconstruction. Example: "camera intrinsics "
- Camera tokens: Learnable tokens that encode camera-related information within a transformer-based architecture. Example: "concatenated with camera tokens and register tokens"
- Control branch: An auxiliary input pathway that injects conditioning signals (e.g., renderings, masks) into a generative model. Example: "We introduce a control branch to incorporate them into the generation model like~\cite{controlnet, vace, voyager,layeranimate}."
- CrossAttn: Cross-attention operation used to compute motion features by querying one set of frame features with another. Example: ""
- DINOv2: A pretrained vision transformer providing robust visual features used as the backbone for feature extraction. Example: "VGGT extracts the frame-wise features using the pretrained DINOv2~\cite{dinov2}."
- Feed-forward reconstruction: One-pass, generalizable reconstruction that avoids per-scene optimization, enabling scalability. Example: "driving a shift in Gaussian Splatting from per-scene optimization to generalizable feed-forward reconstruction."
- Flying pixels: Erroneous pixels at depth discontinuities caused by averaging effects in depth estimation or rendering. Example: "another typical degradation pattern is the flying pixels in depth-discontinuous edges."
- Gaussian Culling: Removing invisible Gaussian primitives based on estimated visibility to simulate occlusions. Example: "Visibility-based Gaussian Culling for occlusion simulation."
- Gaussian primitives: The fundamental units in Gaussian Splatting representing scene elements with position, shape, color, and opacity. Example: "We then simply cull those invisible Gaussian primitives and render the remaining Gaussian primitives back into the original viewpoints"
- Gaussian Splatting: A rendering technique that represents scenes as collections of Gaussian primitives for efficient view synthesis. Example: "driving a shift in Gaussian Splatting from per-scene optimization to generalizable feed-forward reconstruction."
- Global motion tracking: A process to identify objects with both static and dynamic phases across a clip to separate motion components. Example: "The motivation of global motion tracking is to identify those objects undergoing both static and dynamic phases in a clip, which should be regarded as the dynamic part and cannot be easily identified using predicted instantaneous velocity."
- GSplat: An implementation/library for Gaussian Splatting used as the rendering backend. Example: "GSplat~\cite{gsplat} is adopted as the Gaussian Splatting rendering backend."
- Life span (in 4DGS): A temporal parameter controlling the persistence/opacity decay of a Gaussian over time. Example: "we adopt a life span following the common practice in 4DGS."
- LoRA: Low-Rank Adaptation technique for efficient fine-tuning and distillation of large models. Example: "to make NeoVerse accessible to powerful distillation LoRAs~\cite{lora} to speed up the generation process."
- LPIPS: A learned perceptual image similarity metric used as a loss for evaluating visual fidelity. Example: "including an loss and LPIPS~\cite{lpips} loss."
- Monocular degradation simulation: Online procedures that simulate degraded renderings from single-view videos to train robust generation. Example: "online monocular degradation pattern simulation"
- Opacity regularization: A penalty ensuring Gaussians do not become spuriously transparent, maintaining correct appearance. Example: "we introduce opacity regularization to avoid the model learning a shortcut"
- Photometric loss: Pixel-wise reconstruction loss measuring differences between rendered and ground-truth images. Example: "where is the photometric loss between rendered and ground-truth images"
- Plücker embeddings: A representation of 3D lines/camera motion providing explicit trajectory information to the generator. Example: "Plüker embeddings of the original trajectory are also computed to provide explicit 3D camera motion information~\cite{uni3c}."
- Pose-free: Operating without known camera poses, relying on learned features to infer geometry and motion. Example: "a pose-free feed-forward 4DGS reconstruction model"
- Quaternion: A four-parameter rotation representation used to apply angular velocities to Gaussians. Example: "and converts it to a quaternion."
- Rectified Flow: A diffusion modeling technique that learns velocity fields via rectified optimal transport for efficient generation. Example: "we adopt Rectified Flow~\cite{rectified} and Wan-T2V~\cite{wan} 14B to model the denoising diffusion process."
- Register tokens: Learnable tokens used alongside camera tokens to help transformers structure scene information. Example: "concatenated with camera tokens and register tokens"
- Spherical harmonics coefficients: Parameters encoding view-dependent color in Gaussians via spherical harmonics basis functions. Example: "and spherical harmonics coefficients , as inherited from 3D Gaussians~\cite{3dgs}."
- Trajectory controllability: The ability of a model to precisely follow specified camera paths during video generation. Example: "a trade-off between generation quality and trajectory controllability."
- Visibility-weighted maximum velocity magnitude: A global measure of motion for each Gaussian, accounting for visibility across frames. Example: "We define a visibility-weighted maximum velocity magnitude at the global video level as"
- VGGT: Visual Geometry Grounded Transformer; a foundation model backbone for geometry-aware feature extraction. Example: "Our feed-forward model is partially built upon VGGT~\cite{vggt} backbone."
- World-to-camera poses: Transformations mapping world coordinates into camera coordinates for each frame. Example: "given world-to-camera poses "
Collections
Sign up for free to add this paper to one or more collections.