VerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control
Abstract: Video world models aim to simulate dynamic, real-world environments, yet existing methods struggle to provide unified and precise control over camera and multi-object motion, as videos inherently operate dynamics in the projected 2D image plane. To bridge this gap, we introduce VerseCrafter, a 4D-aware video world model that enables explicit and coherent control over both camera and object dynamics within a unified 4D geometric world state. Our approach is centered on a novel 4D Geometric Control representation, which encodes the world state through a static background point cloud and per-object 3D Gaussian trajectories. This representation captures not only an object's path but also its probabilistic 3D occupancy over time, offering a flexible, category-agnostic alternative to rigid bounding boxes or parametric models. These 4D controls are rendered into conditioning signals for a pretrained video diffusion model, enabling the generation of high-fidelity, view-consistent videos that precisely adhere to the specified dynamics. Unfortunately, another major challenge lies in the scarcity of large-scale training data with explicit 4D annotations. We address this by developing an automatic data engine that extracts the required 4D controls from in-the-wild videos, allowing us to train our model on a massive and diverse dataset.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces VerseCrafter, a new way for computers to make realistic videos where both the camera and multiple objects move exactly as you want. It does this by thinking about the world in “4D” (3D space + time), instead of just 2D pixels. The key idea is to give the video model a clear, editable “world state” that describes where the camera is and where objects are moving in 3D over time, so the video follows those motions precisely.
What questions are the researchers asking?
They mainly ask:
- How can we control both the camera and several moving objects in a video at the same time, in a way that makes sense in 3D?
- How can we make videos that look sharp and stay consistent when the viewpoint changes (for example, when the camera turns or moves closer)?
- How can we train such a system even though most videos don’t come with true 3D labels?
How did they do it?
The big idea: 4D Geometric Control
Instead of controlling videos with 2D tools like boxes or masks drawn on frames, VerseCrafter controls videos using a 3D world that changes over time.
- Static background as a “point cloud”: Imagine the scene (buildings, trees, roads) as a 3D painting made of tiny dots. This dot cloud stays still, like a real environment.
- Moving objects as “soft 3D bubbles”: Each object (like a person, car, or dog) is represented as a squishy 3D ellipsoid that moves over time. Think of it like a balloon that shows where the object probably is and how big and tilted it is. The center of the balloon is the path the object follows. The shape of the balloon shows its size and orientation. This is called a “3D Gaussian trajectory.”
- Shared world space: Both the background dots and the moving balloons live in the same 3D coordinate system. That means when the camera moves, everything shifts correctly, and when an object moves, it does so in the right place in the world.
Why this helps:
- 3D “bubbles” are flexible and work for many object types (not just humans).
- They’re better than 2D boxes when the camera swings around, because they’re tied to the 3D world.
- They avoid rigid shapes (like strict 3D boxes) and can handle changing sizes and orientations smoothly.
Turning 3D control into video
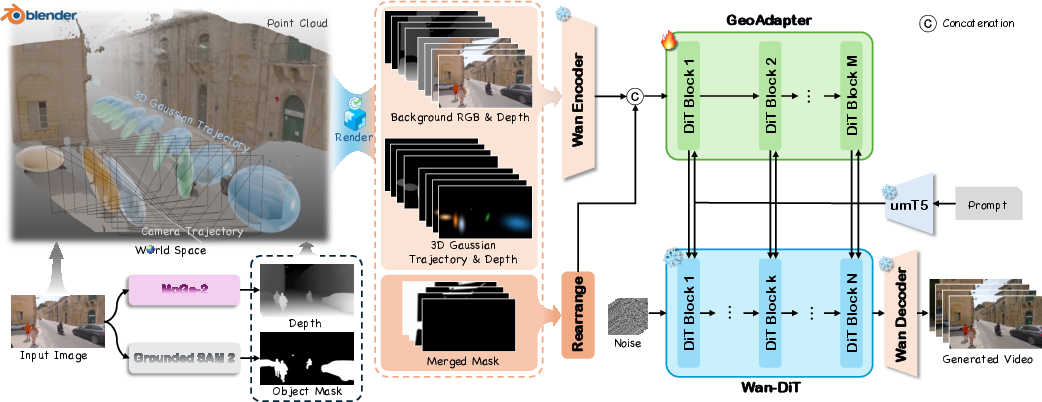
- The team “renders” their 4D control (the background dots and moving bubbles) into per-frame helper images: color, depth (how far things are), and soft masks that tell the model what to update.
- These helper images guide a powerful, pre-trained video generator (Wan 2.1-14B). The main video model’s weights stay frozen; a small “GeoAdapter” module is added to feed the 3D guidance into the generator. Think of the GeoAdapter as a translator that tells the video model: “Here’s where the camera is going; here’s where the objects are moving—follow this.”
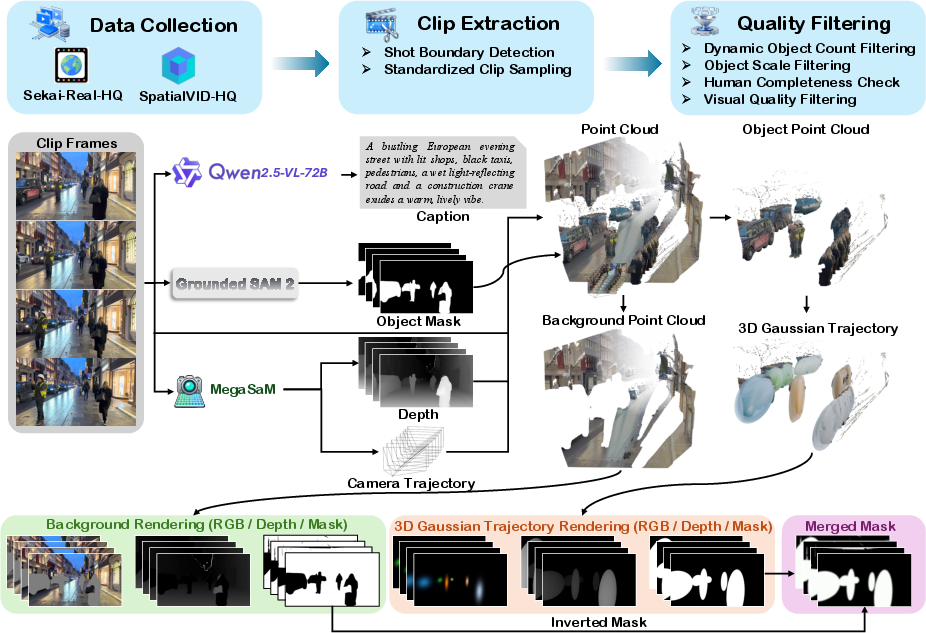
Building training data automatically
Real videos usually don’t come with 3D object paths or camera trajectories. So the authors built VerseControl4D, a large training set with automatically extracted 3D controls:
- They start with long, real-world videos.
- They split them into clips, filter for quality, and detect controllable objects (like people and cars).
- Using depth estimation and masks, they reconstruct background point clouds and fit moving 3D “bubbles” for each object over time.
- This becomes paired training data: each video clip comes with its 4D controls.
What did they find and why is it important?
Here are the main results in simple terms:
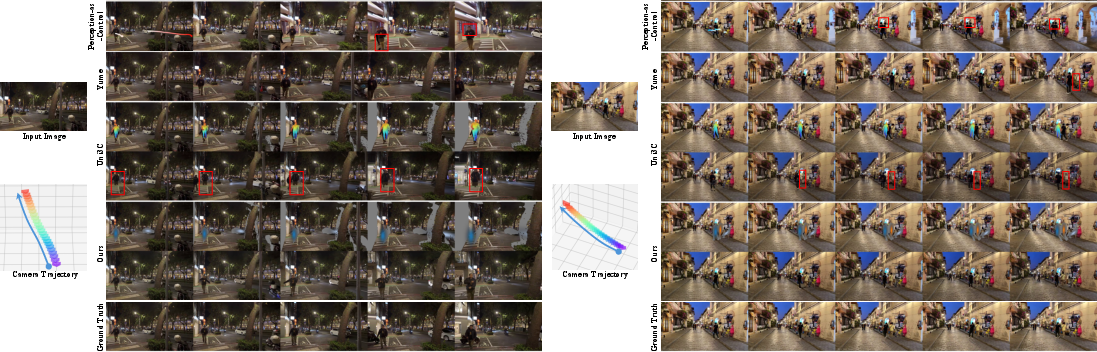
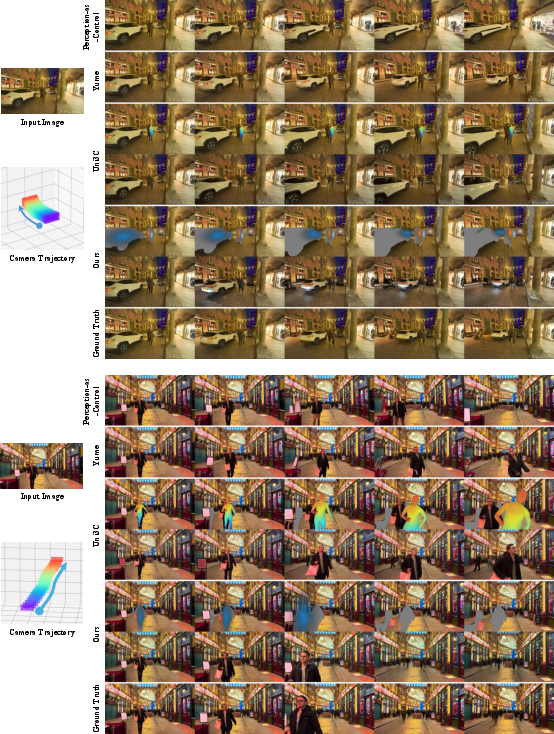
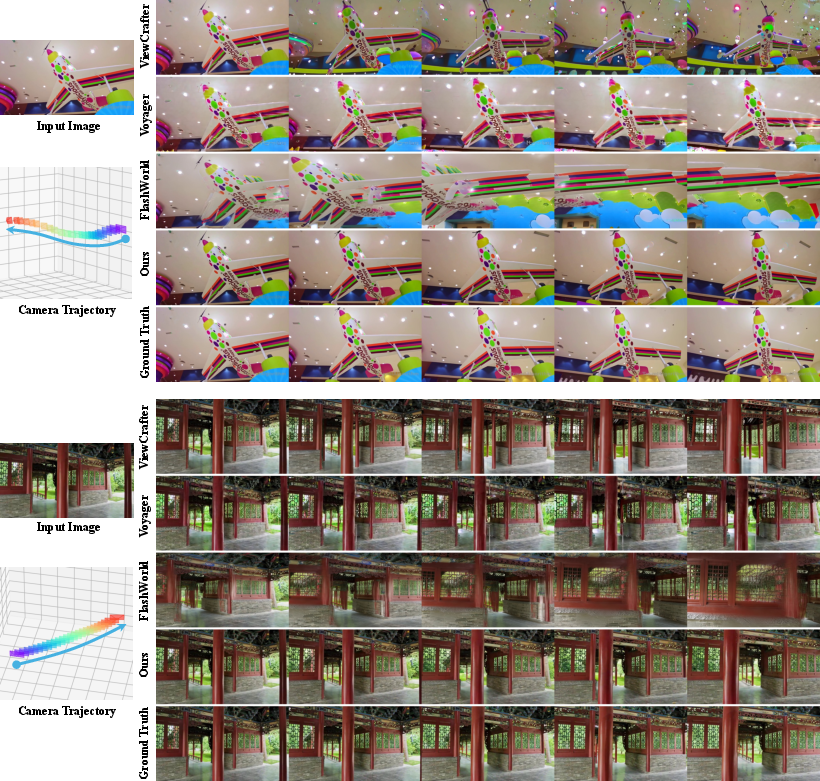
- More precise control: VerseCrafter follows both camera paths and object motions more accurately than previous methods. If you tell the camera to pan left while a car turns right, it does exactly that—cleanly and consistently.
- Better video quality: The videos look sharper and more stable across frames, with correct parallax (near things move faster across the screen than far things) and proper occlusions (objects in front block those behind).
- Works for many object types: Because the “bubble” representation is general, it’s not limited to people or any specific category.
- Strong under big camera moves: Unlike 2D controls (like drawn boxes), the 3D approach stays consistent even when the camera swings around or moves a lot.
To support these claims, the authors did careful comparisons and ablation tests:
- 3D “bubbles” (Gaussians) beat 3D boxes and point-only paths. Boxes and points often cause wrong scales or misaligned motion. Bubbles give smoother, more realistic motion and shape.
- Depth matters. Including depth information helps the model handle what’s in front and what’s behind, and keeps boundaries clean when objects pass each other.
- Separating background and foreground controls helps. Treating the static scene and the moving objects in separate channels improves stability and realism.
What could this change?
This research pushes video generation closer to being a true “world model” that understands 3D space and time. Possible impacts:
- Filmmaking and animation: Creators could plan camera moves and multi-character motions in 3D and get realistic video results quickly.
- Robotics and self-driving: Simulating realistic, controllable worlds helps train and test intelligent agents safely.
- AR/VR and games: Generating scenes that stay consistent as you move your head or navigate a space makes experiences more immersive.
- Video editing: Editors could tweak camera paths or object movements after the fact, without reshooting anything.
In short, VerseCrafter shows that giving a video model a clear, editable 4D world state—made of a 3D background and soft-moving 3D “bubbles” for objects—leads to videos that look better and follow instructions more precisely. It’s a step toward AI that doesn’t just paint frames, but understands and controls a 3D world over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of unresolved issues that future research could concretely address:
- Static background assumption: How to model and control time-varying backgrounds (e.g., waving trees, crowds, water) when the method assumes a static background point cloud and only moves objects via Gaussians.
- Limited occlusion modeling between dynamic entities: The approach renders background and per-object ellipsoids but does not explicitly reason about inter-object occlusions or contact constraints; develop occlusion-aware, collision-aware rendering and control.
- Monocular depth and segmentation dependency: Quantify and mitigate failure modes from MoGe-2/UniDepth V2 and Grounded SAM2 (e.g., depth scale errors, segmentation leaks, temporal jitter); study sensitivity and robustness to these upstream errors during inference.
- Camera intrinsics/pose sensitivity: The method requires camera intrinsics and first-frame pose; analyze performance under miscalibrated intrinsics/poses and devise autocalibration or self-consistent pose refinement for single-image inputs.
- Representation limits for articulated/deformable objects: A single Gaussian (ellipsoid) per object per frame cannot capture articulation, nonrigid deformations, or topology changes; investigate mixtures of Gaussians, articulated kinematic chains, or learned deformable shape priors within the same 4D control.
- Lack of physics or scene interaction priors: No support for contact, collisions, gravity, or friction; explore differentiable physics or constraint-based regularizers that keep trajectories physically plausible.
- Lighting, shadows, and reflections are uncontrolled: The control space does not encode illumination; study light-aware control signals (e.g., estimated environment maps) and metrics for light/reflectance consistency across views.
- First-frame immutability: The pipeline fixes the first frame (M1 = 0), preventing edits to initial content; extend to consistent first-frame editing and full-clip re-synthesis under changed controls.
- Large viewpoint extrapolation beyond the first frame: A single-frame point cloud leaves unseen regions underconstrained; quantify degradation vs. camera displacement and explore multi-frame/panoramic conditioning or learned scene completion to expand controllable view ranges.
- Long-horizon generation and efficiency: Only 81-frame (720p) clips are evaluated and generation is computationally heavy (~1152s on 8×96GB GPUs); investigate hierarchical rollouts, latent caching, or distillation for minute-long sequences and interactive speeds.
- Dataset bias and coverage: VerseControl4D filters to 1–6 foreground objects, excludes large masks (>20% area) and border-touching humans, and is dominated by outdoor/urban scenes; broaden to indoor scenes, crowded scenes, tiny/large/occluded objects, adverse weather/night, and fast motion.
- Generalization beyond datasets with known camera poses: The data engine relies on sources providing camera trajectories; develop robust camera pose estimation for generic videos without pose metadata.
- Temporal association and identity consistency in annotations: Per-object trajectories are assembled from framewise masks; quantify identity switches and tracking errors, and improve association through joint 3D tracking or multi-frame matching.
- Evaluation metric reliability: RotErr/TransErr/ObjMC are computed via the same automatic pipeline used to annotate data; validate against independent ground-truths, add metrics for covariance (size/orientation) accuracy, occlusion correctness, and human evaluations.
- Control of covariance/orientation is unevaluated: Current ObjMC only measures means; define and report metrics for covariance alignment (scale/orientation) and shape evolution over time.
- Scalability to many objects: The method is validated up to 6 controllable objects; assess performance, contention, and occlusions with tens to hundreds of moving entities.
- Robustness to control errors at inference: Analyze failure modes under noisy masks, depth artifacts, or trajectory perturbations; incorporate uncertainty-aware controls and confidence-weighted conditioning.
- Automatic text-to-4D control: Currently, users keyframe ellipsoids or provide masks; build models that translate natural-language motion/camera instructions into 4D Gaussian trajectories and camera paths.
- Object insertion/removal: The pipeline controls objects present in the first frame; enable introducing new objects (with geometry and appearance) and removing existing ones while keeping geometric consistency.
- Camera-only vs object-only disentanglement under strong motion: Quantify leakage (e.g., camera edits affecting objects and vice versa) and improve decoupling under rapid motions or tight occlusions.
- Adapter design choices are underexplored: Study where and how often to inject GeoAdapter (value of k), depth of the adapter, modulation strategies, and the trade-offs of partially fine-tuning the backbone vs. adapters.
- Multi-view/multi-frame conditioning at input: Extend from single-image conditioning to multi-frame or short video inputs to improve background geometry fidelity and reduce hallucinations.
- Metric scale alignment across scenes: Even with “metric” depth, residual scale drift may exist; investigate global scale alignment and cross-video scale consistency for comparable physical units in control.
- Panoramic/360° and rolling-shutter cameras: Evaluate and adapt the control/rendering to panoramic/360° imagery and rolling-shutter artifacts common in mobile videos.
- Rendering fidelity of control maps: Assess whether Gaussian-to-ellipse rasterization introduces biases (e.g., thin structures, concavities) and explore differentiable volumetric rendering or learned geometric encoders for richer control signals.
- Exportable 3D assets/worlds: The approach controls video, not reconstructable 3D assets; explore inverse rendering to export textured geometry or dynamic 4D Gaussian scenes consistent with generated videos.
- Cross-benchmark generalization: Results are reported on VerseControl4D; test on additional benchmarks (e.g., other I2V datasets with/control signals) to establish broader generalization.
- UI and interactive tooling: The paper suggests Blender-based editing but does not deliver an integrated, responsive UI; develop streamlined interfaces for interactive 4D control authoring and live previews.
Glossary
- 3D Gaussian trajectories: A time-ordered sequence of 3D Gaussian distributions whose means trace motion paths and covariances capture spatial extent and orientation. "per-object 3D Gaussian trajectories"
- 3D VAE: A variational autoencoder operating on spatio-temporal video latents for diffusion backbones. "a 3D VAE and a DiT-based denoiser."
- 4D Geometric Control: An explicit, editable world state combining a static background point cloud and per-object 3D Gaussians in a shared 4D frame for unified camera and object control. "a 4D Geometric Control representation"
- adapter-style branch: A lightweight module attached to a frozen backbone to inject conditioning signals without altering backbone weights. "an adapter-style branch inspired by ControlNet"
- back-projection: Mapping pixels with depth into 3D coordinates using camera intrinsics and extrinsics. "each pixel ... is back-projected as"
- background point cloud: A static 3D point set representing scene geometry that remains fixed across frames. "a static background point cloud"
- backbones: Core neural architectures that provide representational capacity for generative models. "diffusion backbones to roll out high-fidelity videos"
- camera extrinsics: External camera parameters describing rotation and translation in the world coordinate system. "camera intrinsics and extrinsics "
- camera pose: The position and orientation of the camera in the world coordinate frame. "with the camera pose "
- classifier-free guidance: A diffusion conditioning technique that drops conditions during training and scales guidance at inference to control adherence. "We adopt classifier-free guidance during training"
- control mask: A soft map indicating regions where the model should synthesize or overwrite content during generation. "a soft control mask "
- DiT: Diffusion Transformer architecture used for denoising in diffusion models. "a DiT-based denoiser"
- eigenvalues: Scalars indicating principal spreads of a covariance along its principal axes. "through the eigenvalues of "
- eigenvectors: Principal directions of a covariance that define orientation in space. "through its eigenvectors"
- flow-matching: A training paradigm that aligns model dynamics with probability flow to improve sampling efficiency. "latent video diffusion / flow-matching backbone"
- full-covariance Gaussian: A Gaussian distribution with a non-diagonal covariance capturing axis correlations. "fit a full-covariance Gaussian"
- Gaussian smoothing: Applying a Gaussian filter to smooth masks or signals. "followed by Gaussian smoothing."
- GeoAdapter: The geometry-conditioning module that injects rendered 4D control signals into the frozen backbone. "the proposed GeoAdapter"
- monocular depth: Depth estimated from a single image without multi-view information. "estimate monocular depth with MoGe-2"
- ObjMC: An object-motion control metric measuring average Euclidean distance between estimated and ground-truth 3D Gaussian means. "ObjMC is computed as the average Euclidean distance between the estimated and ground-truth 3D Gaussian means"
- occlusion: Visibility blocking where foreground objects obscure background regions in a view. "robust to occlusions"
- optical flow: 2D motion field between frames used as a control signal for object motion. "optical flow"
- oriented 3D bounding box: A rotated 3D box aligned to an object’s principal directions and sized by principal spreads. "an oriented 3D bounding box"
- parallax: Apparent relative motion of foreground and background due to camera movement and depth differences. "inconsistent parallax along the camera path."
- point cloud: A set of 3D points representing surfaces reconstructed from images or video. "reconstructed point cloud"
- residual modulation: Adding conditioning outputs to backbone activations via residual connections to modulate behavior. "added as a residual modulation"
- RotErr: Rotation error metric for camera control accuracy. "rotation error (RotErr)"
- SMPL-X: A category-specific parametric 3D human body model with expressive hands and face. "parametric human models like SMPL-X"
- spatio–temporal geometry tensor: A multi-frame tensor encoding spatial and temporal geometric features for conditioning. "yields a spatio–temporal geometry tensor"
- TransErr: Translation error metric for camera trajectory accuracy. "translation error (TransErr)"
- umT5: A text encoder used to produce embeddings for conditioning the video diffusion model. "text embeddings from umT5"
- VBench-I2V: A benchmark suite for evaluating image-to-video quality and consistency. "We report VBench-I2V scores"
- Wan2.1-14B: A large-scale video diffusion backbone used as a frozen prior in the system. "Wan2.1-14B video diffusion backbone"
- world coordinate frame: A global coordinate system shared by camera and objects for coherent control. "a shared world coordinate frame"
Practical Applications
Immediate Applications
Below are actionable, near-term use cases that can be deployed with existing tooling and compute, leveraging the paper’s 4D Geometric Control (background point cloud + per‑object 3D Gaussian trajectories), GeoAdapter, and the VerseControl4D data engine.
- Film, VFX, and Animation Previsualization (Sector: media/entertainment)
- Use VerseCrafter to block and iterate camera moves and multi-object motion with view-consistent geometry before principal photography.
- Workflow: Import an establishing frame, auto-lift the background point cloud and per-object Gaussians, edit ellipsoid keyframes in Blender, render control maps, and generate previz clips via the GeoAdapter + frozen Wan2.1-14B.
- Potential tool/product: “VerseCrafter Studio” Blender/Houdini add-on for Gaussian trajectory editing and control map export.
- Assumptions/dependencies: Reliable monocular depth and instance masks (MoGe-2, Grounded SAM2), high VRAM GPUs (∼90 GB peak for 720p, 81 frames), and licensing for Wan2.1-14B.
- Camera Path Planning for Drone and Steadicam Shoots (Sector: media/production; robotics/drones)
- Simulate target view sequences for proposed camera trajectories over a reconstructed static background; adjust for parallax, occlusions, and motion smoothness before on-site filming.
- Workflow: Back-project a location scout frame to a background point cloud; author candidate camera extrinsics; generate video previews to choose safe and aesthetic routes.
- Assumptions/dependencies: Accurate camera intrinsics/extrinsics or reasonable estimates, outdoor scene coverage, and safety/compliance for actual drone flights.
- Controllable Video Editing and Motion Retiming (Sector: software/creative tools)
- Precisely modify object motion (e.g., vehicles, pedestrians) and camera motion in existing footage while preserving view consistency and occlusion ordering.
- Workflow: Extract 4D control from footage via the data engine; edit Gaussian trajectories; regenerate future frames with soft control masks to preserve the first frame.
- Assumptions/dependencies: Strong segmentation in busy scenes; users accept probabilistic ellipsoid approximation rather than exact meshes; compute budget for re-synthesis.
- Synthetic Data Generation for 3D Vision Tasks (Sector: computer vision/ML, autonomy)
- Produce videos with known camera trajectories and multi-object motion for training and benchmarking SLAM, SfM, 3D detection, and motion forecasting under realistic occlusions.
- Workflow: Author diverse 4D control states, render to conditioning maps, and generate labeled clips; use ObjMC/RotErr/TransErr as evaluation metrics.
- Assumptions/dependencies: Domain alignment with target tasks; clear licensing for generated data; sufficient diversity in VerseControl4D and user-authored scenarios.
- Sports and Motion Coaching Visualizations (Sector: sports analytics/education)
- Visualize ideal motion paths (3D Gaussian means) and spatial extents (covariances) overlayed onto play footage for tactical planning and coaching.
- Workflow: Select athletes via masks; fit Gaussians; author target trajectories; generate explanatory videos with consistent camera motion.
- Assumptions/dependencies: Mask quality for fast motion; user-friendly UI for trajectory edits; acceptance of soft occupancy visualization.
- AR/VR Authoring for Dynamic Scenes (Sector: XR/interactive media)
- Create short, view-consistent video sequences with controlled camera/object motion for XR experiences and storytelling spots.
- Workflow: Use 4D control to author motion, then generate temporally coherent clips aligned to device FOV/camera models.
- Assumptions/dependencies: Accurate device intrinsics; integration with XR toolchains; performance constraints for preview vs final output.
- Academic Benchmarking of 4D-Aware Control (Sector: academia)
- Use VerseControl4D and the paper’s control/error metrics to evaluate new camera/object control methods in realistic settings.
- Workflow: Train adapters/backbones on VerseControl4D; report VBench-I2V, RotErr/TransErr/ObjMC; ablate representations (points, boxes, Gaussians) and depth channels.
- Assumptions/dependencies: Access to dataset; reproducible pipelines; consistent metric computation via the same annotation stack.
- Marketing and E-commerce Staging (Sector: advertising/retail)
- Stage products in realistic street/room scenes and preview multi-object interactions and camera moves for ad creatives.
- Workflow: Fit product Gaussians from single shots; keyframe motion; generate variants for A/B testing.
- Assumptions/dependencies: Consent and rights for background footage; legal compliance for synthetic content disclosure; creative approvals.
- Incident Reconstruction for Training and Briefings (Sector: public safety/enterprise training)
- Create view-consistent reenactment clips from a single frame or short footage to brief teams on camera motion and object trajectories in complex scenes.
- Workflow: Auto-extract control; refine trajectories for clarity; generate instructional clips highlighting occlusions and parallax.
- Assumptions/dependencies: Data privacy; ethical use; accuracy of monocular depth and masks in low-light or crowded scenes.
Long-Term Applications
These use cases will benefit from further research, scaling, and engineering to reach real-time performance, broader generalization, and tighter integrations.
- Real-Time 4D-Aware Generative World Models for Robotics (Sector: robotics)
- Use the unified 4D control and geometry-consistent generation to simulate sensor streams with accurate occlusions for planning and manipulation in the loop.
- Potential product: “VerseCrafter RT” with streaming GeoAdapter and lightweight backbone; integration with ROS and physics engines.
- Dependencies: Faster backbones; low-latency depth/mask estimation; robust multi-object tracking/updates; safety validation and sim-to-real transfer.
- Autonomous Driving Training in Dynamic, Generative Worlds (Sector: autonomy/transportation)
- Scale to city-scale digital twins with controllable multi-agent motion; generate rare edge cases with precise camera/object control for perception and policy learning.
- Workflow: Author multi-vehicle/pedestrian Gaussian trajectories; vary weather/lighting; evaluate models with 3D control metrics.
- Dependencies: High-fidelity depth in diverse conditions; multi-sensor modalities (LiDAR/radar); legal/regulatory acceptance of synthetic training data; massive compute.
- Dynamic Digital Twins for Urban Planning and Smart Cities (Sector: urban planning/energy)
- Simulate pedestrian/traffic flows, sensor viewpoints, and occlusions in planned infrastructure; iterate camera placements and sightlines (CCTV, signage).
- Potential tool: “4D Twin Planner” for camera coverage simulation using Gaussian trajectories and background point clouds.
- Dependencies: Accurate large-scale reconstruction; multi-object behavior models; governance frameworks for synthetic city data; stakeholder buy-in.
- Interactive Generative Game Worlds with 4D Control (Sector: gaming)
- Author dynamic levels with precise camera/object motion that remain view-consistent across user-driven camera changes; support multi-object interactions.
- Workflow: Integrate 4D control maps into engines; expose trajectory editing to level designers; live generation for cutscenes and gameplay transitions.
- Dependencies: Engine integration; real-time inference; content moderation; consistency across long sequences (>81 frames).
- Telepresence and Live Production Assist (Sector: XR/streaming media)
- Real-time generative augmentation of camera paths and object motion to enhance telepresence and live broadcasts with physically plausible parallax/occlusions.
- Dependencies: Low-latency models; robust online depth/mask estimation; fail-safes for content fidelity; broadcast standards compliance.
- Multi-Agent Motion Planning and Safety Simulation (Sector: robotics/AI safety)
- Use probabilistic 3D occupancy (covariances) to model uncertainty in agent extents and orientations for safety-critical planning under occlusions.
- Dependencies: Formal guarantees; integration with planners; standardized interfaces for Gaussian occupancy; validation datasets.
- Forensic Analysis and Policy Frameworks for Synthetic Media (Sector: policy/regulation)
- Establish standards for disclosure, watermarking, and provenance of 4D-controlled generative videos; build detection tools that leverage control map signatures.
- Potential product: “4D Provenance SDK” that embeds/reads control-state metadata; auditing pipelines for broadcasters and platforms.
- Dependencies: Cross-industry standards; regulatory alignment; reliable watermarking; risk assessments for deepfake misuse.
- Education and Research Platforms for 4D Vision (Sector: education/academia)
- Create interactive curricula and sandboxes where students author 4D control states and observe view-consistent outcomes; compare representations (points/boxes/Gaussians).
- Dependencies: Accessible compute; simplified UI; open datasets/licensing; stable APIs.
Notes on Assumptions and Dependencies
- Geometry extraction accuracy: Relies on monocular/metric depth (MoGe-2, UniDepth V2) and high-quality instance masks (Grounded SAM2/MegaSAM). Fast motion, low light, and heavy occlusion can degrade control fidelity.
- Backbone and licensing: The approach conditions a frozen Wan2.1-14B video diffusion backbone via GeoAdapter; commercial use depends on backbone licensing and model availability.
- Compute and throughput: Current reference inference for 81-frame 720p clips requires multi-GPU setups and minutes per clip; real-time and mobile use cases need lighter backbones and optimized adapters.
- Sequence length and scalability: Reported training/inference use 81-frame clips; very long sequences and large-scale worlds may require memory-efficient rendering, hierarchical control, and temporal stitching.
- Representation limits: 3D Gaussian trajectories provide a flexible, category-agnostic interface but approximate complex shapes; tasks needing exact mesh-level contact or physics may require hybrid representations.
- Data rights and ethics: Using in-the-wild footage for control extraction and generating synthetic videos necessitates consent, provenance, watermarking, and adherence to platform and regulatory policies.
- Integration: Practical deployment benefits from toolchain plugins (Blender/Houdini/Unreal/Unity), ROS interfaces for robotics, and APIs for exporting/importing 4D control maps.
- Metrics and validation: Adoption in safety-critical domains should pair ObjMC/RotErr/TransErr with domain-specific KPIs and human-in-the-loop validation.
Collections
Sign up for free to add this paper to one or more collections.