- The paper introduces an iterative, self-improving framework using a generate–evaluate–refine loop to enhance VQA and grounding annotation quality.
- It employs a Chain-of-Thought based consistency evaluation module to ensure high-fidelity visual question answering and precise grounding verification.
- Memory-augmented prompt optimization refines annotation precision, outperforming state-of-the-art models and even surpassing human-generated data in grounding scores.
AutoVQA-G: A Self-Improving Agentic Framework for Automated Visual Question Answering and Grounding Annotation
Framework Overview
AutoVQA-G introduces a modular, self-improving agentic system for scalable, high-fidelity annotation of visual question answering with grounding (VQA-G) data, directly addressing fundamental limitations in prior VQA-G automation. Key components are an iterative "generate–evaluate–refine" protocol, a Chain-of-Thought (CoT) based Consistency Evaluation module, and a memory-augmented Prompt Optimization agent, collaboratively optimizing annotation precision and fidelity.
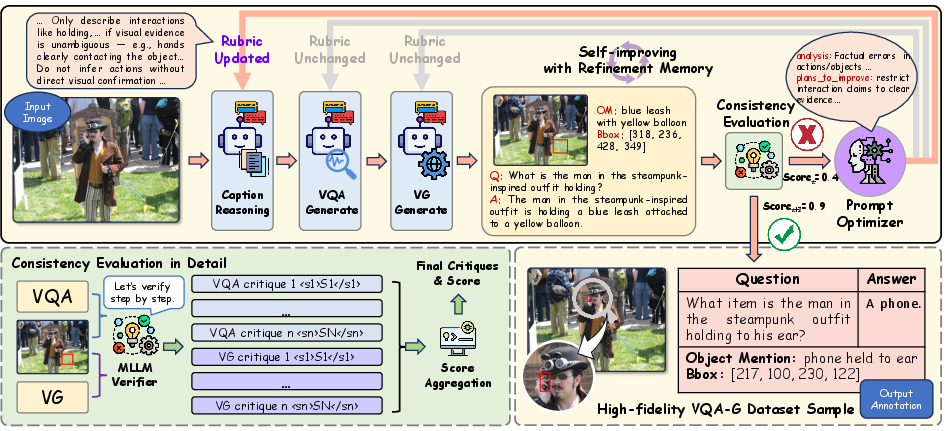
Figure 1: Overview of the AutoVQA-G automated annotation framework, which refines VQA-G data iteratively via systematic visual consistency evaluation and prompt optimization.
The system orchestrates draft annotation generation, evaluates via detailed visual reasoning, and applies critiques to memory-tracked generation rubrics. This process robustly avoids the brittle heuristics and single-pass hallucination issues persistent in prior works, progressing until annotation quality reaches a high-consistency accept threshold or exhausts an iteration budget.
Methodological Components
Modular VQA-G Annotation Construction
Each iteration, given an image I, the system constructs: (1) a rich caption via a structured Caption Reasoning module; (2) visual question-answer pairs, conditioned on the caption and context; (3) an object mention for visual grounding and a bounding box via a two-stage reference and spatial localization mechanism. Each step is governed by explicit, dynamically updated generation rubrics, with module specialization promoting high cognitive diversity and grounding precision.
CoT-Based Consistency Verification
Draft annotations are assessed by separate CoT-empowered verifiers for VQA consistency and visual grounding integrity. The verifiers produce interpretable, step-wise logical critiques and verifiable quality scores, synthesized into aggregate consistency metrics. Model acceptance is strictly thresholded, forcing rejection and refinement of drafts that fail nuanced, multi-step visual reasoning checks, effectively filtering hallucinated, ambiguous, or unfaithful content.
Memory-Augmented Prompt Optimization
Upon rejection, the Prompt Optimization agent leverages historical memory of drafts and associated critiques, executing targeted, non-cyclic rubric refinements. This memory-driven optimization prevents recursive policy collapse and redundant updates, ensuring each iteration exploits available error signals to directly address discovered failure modalities. The agentic loop continues until strict acceptance or forced termination.
Quantitative and Qualitative Evaluation
Annotation Quality and Efficiency Metrics
AutoVQA-G achieves high annotation acceptance rates (91.8% on Visual7W, 89.2% on VizWiz), with the required mean iterations increasing for more challenging, out-of-distribution inputs. Generated samples exhibit strong diversity: a high fraction of complex relational and counting questions, fine-grained reference to object details, and variable object bounding box size distributions suited to the data domain.
AutoVQA-G surpasses both single-pass and tool-assisted state-of-the-art multimodal LLMs (GPT-4o, Gemini 2.5) on composite VQA-G annotation benchmarks, including VQAScore, TIFA, CLIPScore, mIoU, and [email protected]. Notably, visual grounding scores from AutoVQA-G annotations are higher than those from human-generated data in re-evaluation, indicating superior consistency enforcement. The framework demonstrates the capacity to elevate weaker, smaller-scale VLMs in annotation tasks, matching or exceeding much larger models when equipped with agentic refinement.
Ablation Study
Component ablations confirm substantial performance degradation when removing any of the core elements, with the iterative agentic loop and CoT verification being indispensable for optimal grounding accuracy. Lesser, but still notable, drops occur without dynamic routing and memory, validating the architectural choices for iterative self-improvement.
Qualitative Sample Diversity
Qualitative inspection reveals the system's ability to generate nuanced, context-specific, and visually-grounded question–answer pairs, including complex spatial reasoning (e.g., reflections, occlusions) and fine, hard-to-localize objects. Output consistency persists across diverse domains and visual complexities.

Figure 2: Qualitative examples from AutoVQA-G showing consistent, complex QA pairs with precise visual grounding across scenarios.
Implications and Potential Future Directions
AutoVQA-G demonstrates that rigorous agentic annotation protocols—driven by self-improving loops and granular CoT vision-language verification—enable the scalable and automated creation of high-quality VQA-G data, even with modest-generation models. The methodological synergy between memory-augmented optimization and comprehensive consistency checking sets a new practical bar for dataset curation in multimodal AI pipelines.
The ability to outperform human annotators on visual grounding consistency poses significant implications for high-throughput data pipeline standardization, reducing costly human labor and raising expectations for future dataset quality. The agentic structure facilitates adaptation to novel data domains and robust handling of ambiguous, specialized, or difficult inputs.
Efforts to mitigate current computational overhead—potentially through more efficient verifier distillation, streamlined iteration policies, or joint generation–verification architectures—could further accelerate adoption. The modularity of AutoVQA-G suggests viable integration with cross-modal data synthesis, task-conditional dataset bootstrapping, and closed-loop model training scenarios.
Conclusion
AutoVQA-G introduces a robust, agentic, and self-improving framework for VQA-G annotation, leveraging iterative CoT-guided consistency checks and memory-guided prompt optimization. Empirical evaluation confirms its superior capacity for producing consistent, precisely grounded, and cognitively diverse annotation data relative to prevailing multimodal LLMs and human benchmarks, with notable potential to enhance and scale multimodal data pipelines for vision-language system development.

