- The paper introduces VideoDR, a benchmark that uniquely integrates multi-frame visual anchors and open-web search for comprehensive agentic video QA evaluation.
- The benchmark enforces multi-hop reasoning that demands joint analysis of video and web evidence, exposing challenges like goal drift and long-term state maintenance.
- Comparative experiments reveal that high-capacity closed-source models outperform open-source ones, underscoring persistent issues in multimodal evidence integration.
A Benchmark for Agentic Video Deep Research: VideoDR
Introduction
VideoDR targets a high-fidelity evaluation of agentic, open-domain video question answering where models must synthesize information from both dynamic video content and the open web. Unlike prior closed-evidence video QA or deep research benchmarks that use text-only queries, VideoDR uniquely integrates multi-frame visual anchor extraction, interactive web retrieval, and multi-hop evidence-based reasoning. The benchmark, annotated through rigorous multi-stage quality control, systematically excludes instances solvable with either video or web content alone, enforcing tasks that demand joint video--web evidence integration. This approach specifically exposes major, unsolved challenges in agentic multimodal reasoning, including persistent bottlenecks in goal drift and long-horizon consistency in agentic architectures.
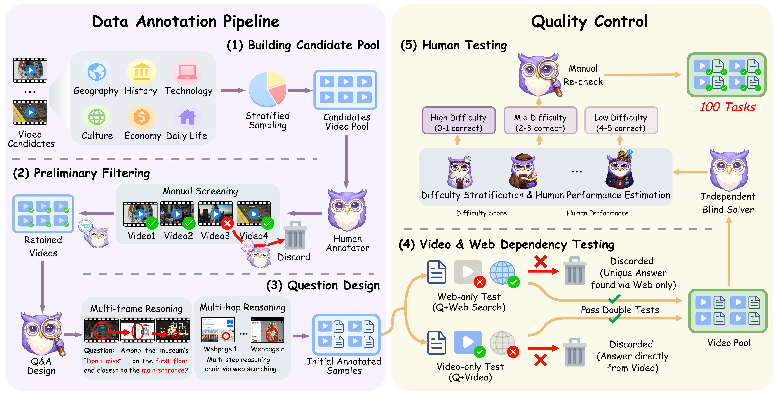
Figure 1: Overview of the VideoDR construction pipeline.
VideoDR formalizes task instances as (V,Q;S)→A, where, given a video V, a natural language question Q, and browser-based search tool S, agents must extract cross-temporal visual anchors, iteratively interact with the open web, and construct a verifiable answer A. The construction pipeline involves: stratified video selection from diverse sources and semantic domains, aggressive filtering to exclude trivial or non-verifiable facts, and expert-made multi-hop questions that strictly require multi-frame reasoning and interleaved search.
An example task illustrates the required capabilities: recognizing a museum from video cues, then finding and outputting a specific exhibit's accession number via multi-hop web search. The design expressly precludes single-frame sufficiency and ensures web search alone is insufficient, demanding joint spatiotemporal analysis and text-based retrieval.

Figure 2: An example of the VideoDR task, highlighting cross-modal, multi-hop reasoning anchored by multi-frame video cues and open-web search.
Data Statistics and Structural Properties
The final dataset comprises 100 samples balanced across six domains--Daily Life, Economics, Technology, Culture, History, and Geography. Natural language question lengths are concise, averaging 25.54 tokens, minimizing input complexity and emphasizing reasoning over multi-modal evidence. Video durations feature a long-tailed distribution, supporting both short- and long-horizon anchor localization evaluations.
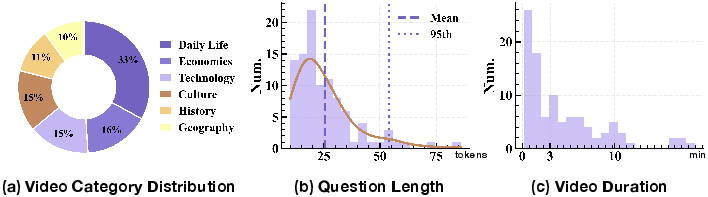
Figure 3: Data statistics of VideoDR, including domain balance, question length distribution centered at 25 tokens, and a long-tailed video duration profile.
Experimental Paradigms and Baselines
VideoDR supports comparison between two distinct agent architectures:
- Workflow paradigm: A two-stage system first extracts structured multi-frame video cues, then passes these as input for search and reasoning, externalizing visual cues to a stable textual intermediate representation.
- Agentic paradigm: An end-to-end agent receives video and question as input, autonomously performing perception, query generation, search, evidence integration, and answer synthesis in a single execution loop, without explicit intermediate state persistence.
Mainstream MLLMs are benchmarked under both paradigms, spanning closed-source (GPT-4o, Gemini-3-pro-preview, GPT-5.2) and open-source (MiniCPM-V 4.5, Qwen3-Omni-30B-A3B, InternVL3.5-14B) models. An LLM-as-judge protocol (DeepSeek-V3) is employed to ensure robust, semantically-aligned evaluation.
Main Results: Performance Stratification and Bottleneck Analysis
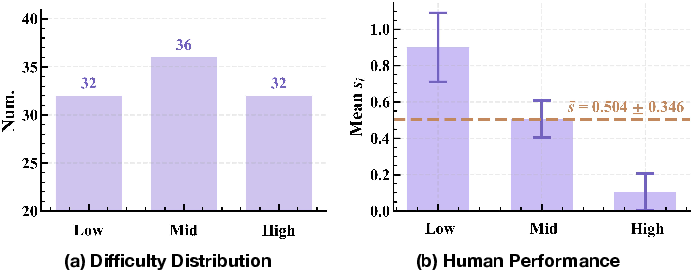
The results expose a clear stratification of model capabilities. Top closed-source models (Gemini-3-pro-preview, GPT-5.2) achieve upper-bound accuracies of 76% and 69%, respectively, considerably outperforming open-source systems, which peak at 37%. Human upper-bound accuracy is estimated at 50.4%, underscoring task challenge and annotation fidelity.
Difficulty, video duration, and semantic domain stratifications provide insight into core agentic reasoning barriers:
Tool usage analysis indicates that search/think call count alone does not account for outcome variance; rather, tool-use effectiveness is a function of evidence path quality and anchor retention. For example, Gemini-3-pro-preview's increased search/think usage corresponds to more reliable multi-modal evidence integration, but for mid/low tier models additional tool use often amplifies drift and error rates.
Error analysis confirms that Categorical Error (incorrect anchor categorization and alignment) dominates, increasing in agentic settings without persistent intermediate cues. Numerical errors remain a distinct, persistent challenge across all models, highlighting ongoing limitations in fine-grained information extraction from imperfect, multi-modal web evidence.
Implications and Future Directions
Practically, VideoDR exposes the limits of current agentic MLLMs in long-horizon, information-seeking tasks where precision spatiotemporal grounding and stable query propagation are necessary. The strong performance of Gemini-3-pro-preview and GPT-5.2 underlines the promise of closed-source, large-scale models, but no current architecture reliably solves the state maintenance and goal alignment problems highlighted by the benchmark.
Theoretically, these findings frame open questions in the development of next-generation video agents:
- How can agentic systems maintain robust, persistent visual-textual state for long-horizon, multi-modal tasks without drift?
- What forms of externalized memory or anchor-persistent intermediate representations most effectively support high-yield, error-resistant multi-hop search?
- How can benchmark design further isolate compositional and grounding errors for more targeted architectural innovation?
Conclusion
VideoDR establishes a challenging, systematic benchmark for agentic video deep research, incorporating diverse video categories, cross-frame anchor extraction, open-web retrieval, and multi-hop reasoning. Comprehensive benchmarking and stratified analysis reveal critical inadequacies in current multimodal LLM architectures, especially with regard to anchor propagation and long-horizon reasoning consistency. Progress on VideoDR will require research into state-persistent agentic systems, memory-augmented architectures, and enhanced visual-textual grounding for verifiable, real-world QA.