- The paper presents a novel structured annotation schema that formalizes five key aspects of video language: subject, scene, motion, spatial, and camera.
- It introduces the Critique-Based Human–AI Oversight (CHAI) framework, leveraging iterative human critique to refine model-generated captions.
- Empirical results demonstrate that high-fidelity critiques and enriched caption data significantly boost video model performance and alignment.
Building a Precise Video Language with Human–AI Oversight: An Expert Synthesis
Motivation and Limitations of Prior Video–Language Datasets
Contemporary video–LLMs (VLMs) are constrained by the quality and granularity of their textual supervision. Existing video–text datasets often lack clear specification regarding what and how to describe visual dynamics, resulting in inconsistent annotations, missing details, and frequent hallucinations—especially in fine-grained aspects such as motion, spatial framing, and camera work. Systematic manual inspection reveals pervasive problems: imprecise terminology, omission of essential cinematic and spatial elements, and conflation of observable content with subjective emotional interpretations. Furthermore, prior works typically operate either with raw crowdsourcing or direct model generation, neither of which establish scalable mechanisms for consistent high-fidelity oversight.
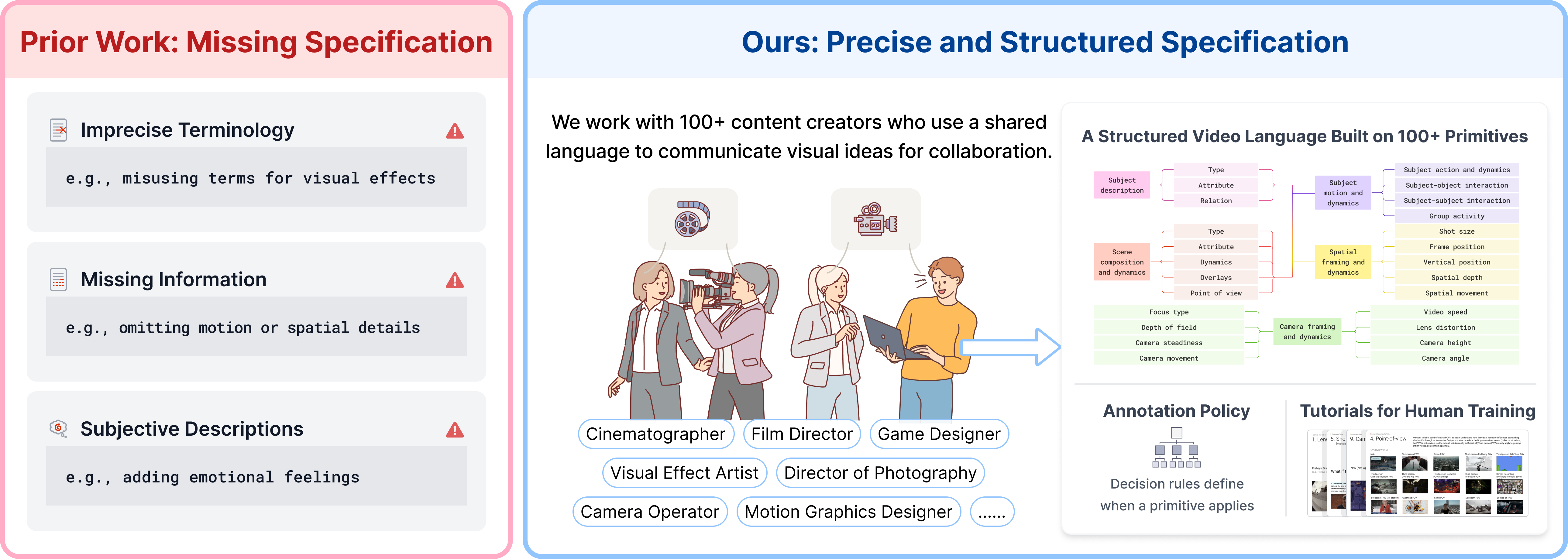
Figure 1: Lack of rigorous annotation specification leads to critical errors, including misuse of technical vocabulary, omission of critical shot details, and injection of subjectivity.
Structured Specification for Video Captioning
This paper addresses the foundational gap in video annotation with a structured, teachable specification for video language, developed in collaboration with over 100 professional content creators, including filmmakers and cinematographers. The schema enforces separation and explicit description of five orthogonal aspects:
- Subject (salient entities, attributes, and their visual relationships),
- Scene (point of view, context, overlays),
- Motion (action sequences, interactions, group activities),
- Spatial (referential shot size, spatial positions, and shifts),
- Camera (playback speed, lens, focus, dynamic camera operations).
Each axis is grounded in primitives with formal definitions, corner-case rules, and decision procedures to maximize clarity and inter-annotator consistency. Taxonomic coverage is on the order of 200+ primitives, extending and subsuming prior camera and cinematography benchmarks.
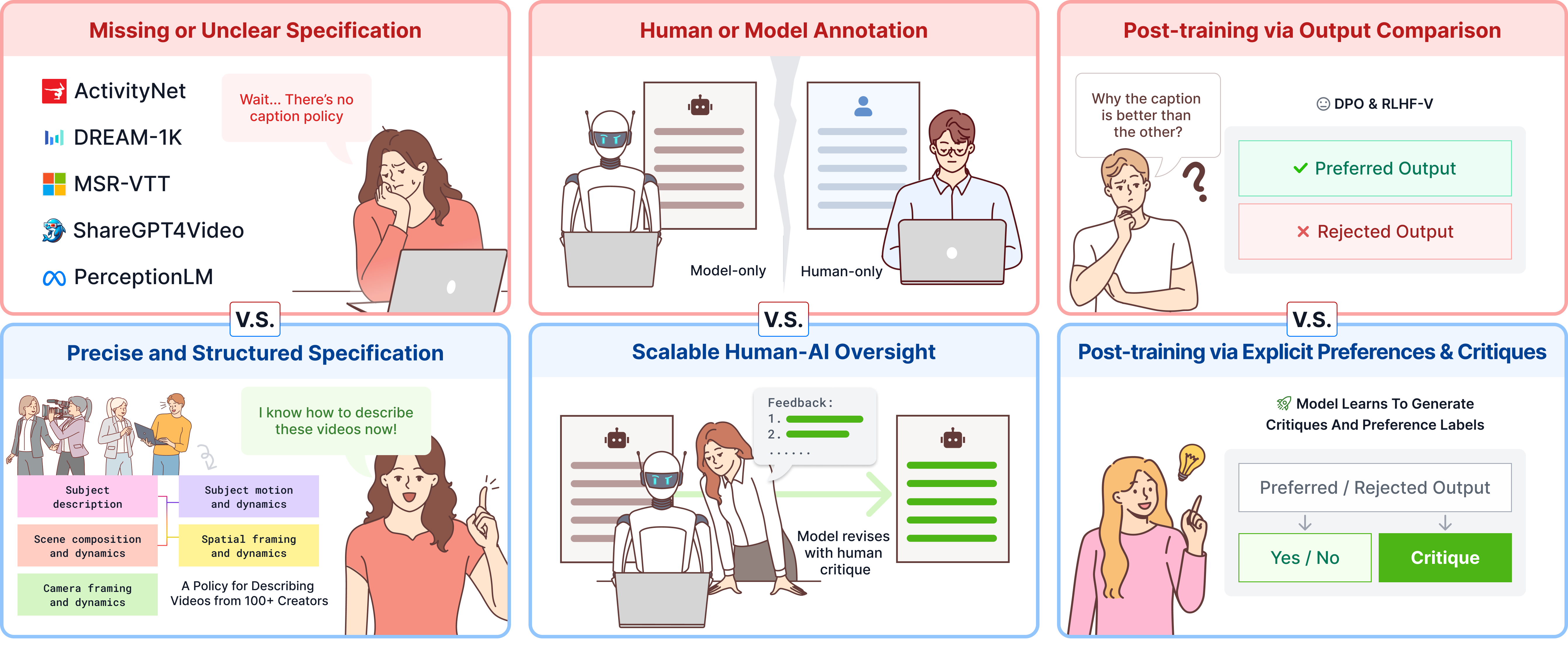
Figure 2: The annotation architecture enforces complete video understanding by decomposing captions into detailed primitives, each supported by precise professional specifications.
Critique-Based Human–AI Oversight (CHAI)
Manual captioning of video—especially at professional detail (200–400+ words per clip)—is cognitively demanding and error-prone. The CHAI framework operationalizes scalable high-quality annotation by dividing the core workflow:
- Humans annotate visual/motion primitives and input these as constraints.
- A video–LLM drafts a first-pass caption (pre-caption) targeting high recall.
- A human provides a critique, identifying and explaining inaccuracies, omissions, or misapplied rules, along with constructive revision guidance.
- The model incorporates the critique to generate a refined post-caption; this process iterates with quality-controlled human review and incentives for error detection.
- The critique and final caption are logged, creating (pre-caption, critique, post-caption) triplets.
In effect, CHAI unlocks a division of labor where generative AI provides fluency and coverage while skilled annotators focus on verification and correction. Peer review and bonus-based incentives improve accuracy and motivation.
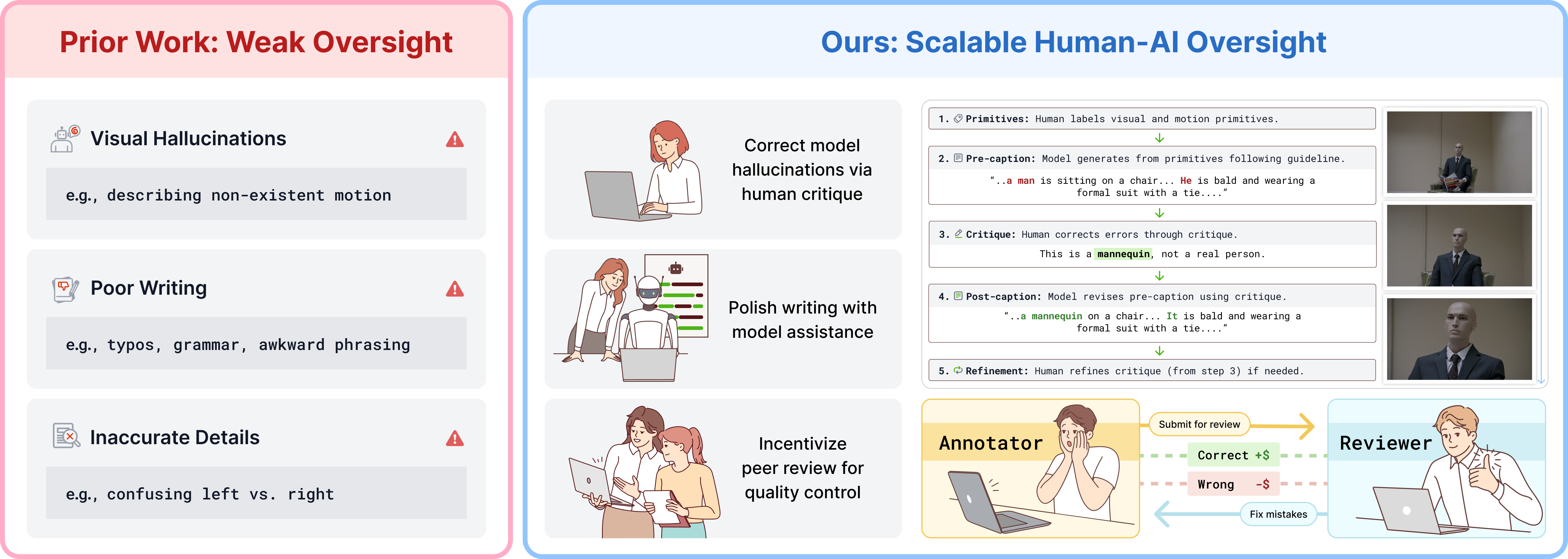
Figure 3: Human–AI collaborative curation workflow: initial model captioning, targeted critique, post-editing, and robust quality assurance.
Critique Quality as a Core Supervision Signal
The properties of annotation critiques—precision, recall, and constructiveness—are shown to have direct quantitative consequences for post-training efficacy. Ablation studies confirm that making critiques less accurate, incomplete, or non-constructive leads to significant degradation in model alignment and performance; critiques must not only identify errors but provide actionable corrections.
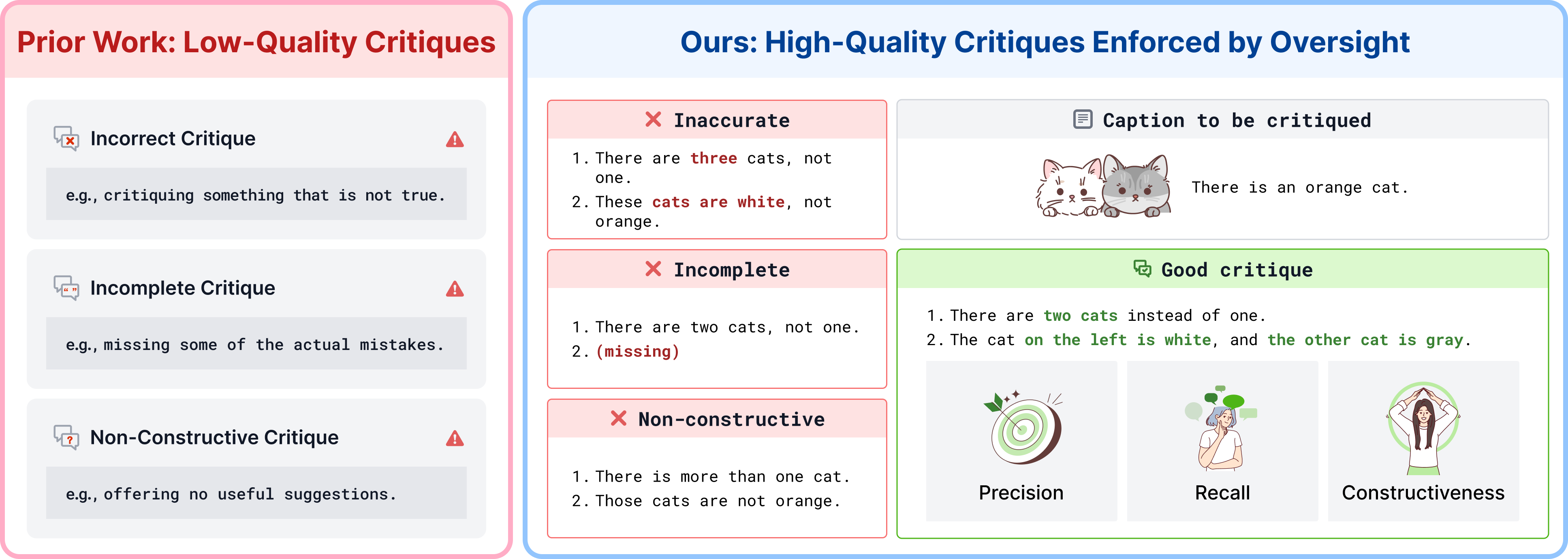
Figure 4: High-quality critiques measurably enhance post-training, while inaccurate, incomplete, or unhelpful feedback sharply reduces downstream alignment.
Unified Benchmark and Post-Training of VLMs
The authors release a 20k–triplet benchmark, the first to systematically evaluate not only caption generation but also reward modeling (caption comparison/classification) and critique generation. Comparison with state-of-the-art open and closed models reveals:
- Off-the-shelf VLMs perform adequately on subject and scene recognition, but are weak on motion and camera aspects.
- Explicitly supervised preference data and critique signals reliably elevate post-trained open models (e.g., Qwen3-VL), surpassing leading closed-source models (e.g., Gemini-3.1) in all key aspects.
- Reward and critique models can be used at inference for further performance scaling and improved sample selection.
Enabling Professional-Grade Video Generation
The enhanced annotation protocol is leveraged to re-caption 150k professional video clips from diverse cinematic domains. After fine-tuning the Wan2.2 video generation model on these re-captioned samples, the generator exhibits marked improvement in prompt adherence and fine control over advanced cinematographic concepts (e.g., dolly zoom, 2.5D isometric views, rack focus, variable playback, dynamic camera angles).


Figure 5: Conditioning video generation models on precise captions enables control of complex camera motions, shot composition, and cinematic perspectives.
Empirical Analysis and Human Study
A detailed empirical analysis—benchmarked through both BLEU-n, LLM-judged accuracy, and human preferences—confirms the strength and necessity of the authors’ approach:
- Post-training with full critique and preference signals raises open model performance by 3–4 Likert points across all aspects.
- Critique-based human–AI oversight not only scales annotation without loss of accuracy, but using higher-quality captions during training of generative models leads to significantly more faithful and professional output in human evaluation.
Practical and Theoretical Implications
This work demonstrates that precision, granularity, and oversight in video language are prerequisites for the next generation of both video understanding and text-conditioned video synthesis. By modularizing and formalizing the annotation space, the authors establish a protocol for scalable, professional-grade visual-linguistic benchmarks. Practically, this architecture supports robust fine-tuning of both discriminative and generative models on film, industrial, and creative video corpora; theoretically, it sets a new reference for the compositional grounding of vision–language tasks.
Conclusion
The paper establishes that professional video–language understanding and generation require structured, explicitly specified, and oversight-amplified caption supervision. The CHAI framework, with critique-enforced quality, provides a viable and efficient mechanism for collecting high-quality data at scale. By making both the schema and curated data openly available, this work provides a platform for future research in multimodal reasoning, scalable annotation, and controllable video generation. Directions for further extension include automating critique in the human–AI loop, scaling annotation to larger domains, and directly benchmarking controllable generation in creative and applied tasks.

