- The paper presents Degradation-Driven Prompting (DDP), which uses aggressive input downsampling and tool invocation to enforce global structural reasoning in VQA.
- The methodology integrates multi-stage image degradation with agentic tool use and Chain-of-Thought prompting to reduce reliance on spurious local cues.
- Empirical results show DDP achieves up to a 10% improvement over baselines, notably enhancing performance on adversarial and high-frequency distractor tasks.
Degradation-Driven Prompting for VQA: Agentic Perception via Detail Reduction
Motivation and Problem Statement
Modern Vision-LLMs (VLMs) have achieved high benchmarks in Visual Question Answering (VQA), yet they systematically fail on images containing visual illusions, occlusions, and high-frequency distractors. These failures are intrinsic, rooted in the models' tendency to exploit local textures and spurious pixel-level cues instead of reasoning about global structure and semantics. The underlying perception-logic gap between human and machine visual understanding manifests as hallucinations and brittle predictions when VLMs are exposed to adversarial or ambiguous stimuli. The paper "Less Detail, Better Answers: Degradation-Driven Prompting for VQA" (2604.04838) introduces Degradation-Driven Prompting (DDP), an agentic, hierarchical framework that leverages multi-stage input degradation, targeted visual prompting, and external tool invocation, with the explicit goal of enforcing global structural reasoning.
Methodological Framework
DDP’s architecture is motivated by the cognitive dual-process theory—moving VLMs from passive, single-shot inference to an iterative, active, and tool-augmented perception.
The pipeline begins with aggressive input downsampling, using Gaussian smoothing followed by systematic reduction of input resolution to suppress high-frequency details. The initial classifier routes each image-query pair into two tracks: Physical Attributes (e.g., size, color, geometric properties) and Perceptual Phenomena (e.g., illusions, occlusions, motion artifacts). This early separation allows allocation of specialized toolsets and prompts tailored to the input’s visual complexity.
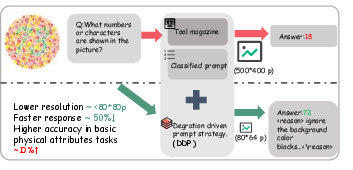
Figure 1: A low-resolution DDP pipeline eliminates background noise, achieving ≈50% reduction in response time and ≈50% improvement in accuracy on basic physical attribute tasks.
In the second stage, the Tool Manager, acting as an autonomous agent, iteratively applies context-dependent visual primitives: auxiliary lines for geometric rectification, cropping for context isolation, white-out masks to neutralize global distractors, blurring to attenuate local textures, and contrast enhancement for fragile feature extraction. Each tool is deployed based on the output of the prior classifier and the current state of the visual evidence set.
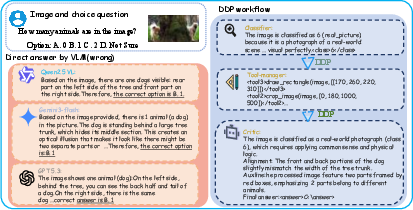
Figure 2: The DDP toolchain overcomes visual reasoning bottlenecks, e.g., resolving occlusion-based illusions via divide-and-conquer and region-specific tool application.
This agentic, programmatic approach shifts the VLM’s role from direct pixel-to-answer mapping toward hypothesis generation and verification, grounded in manipulated and purified evidence.
Structural Bottleneck and Chain-of-Thought Prompting
In the final inference step, all evidence—including raw, degraded, and tool-augmented images—is further downsampled to ≤80 pixels in the largest dimension, establishing an information bottleneck that excludes nearly all textural noise. The target "Critic" module then executes Chain-of-Thought (CoT) reasoning leveraging task-specific prompts and explicit alignment templates to perform rigorous logical verification and deduce the final answer.
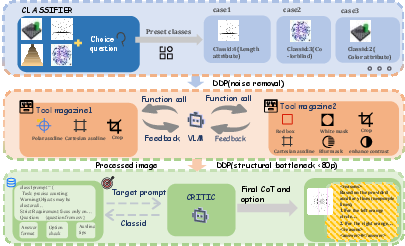
Figure 3: The DDP-based enhancement framework integrates task classification, agentic tool application, and low-res CoT reasoning in a structured inference pipeline.
Empirical Evaluation and Results
The DDP framework is subjected to extensive evaluation on multiple international benchmarks, including MMBench, SEED-Bench, ScienceQA, VQAv2, and the adversarial V*Bench and ColorBlind datasets. It is tested as an augmentation layer on leading VLM backbones such as Gemini-3-Pro and GPT-4o.
Key quantitative findings include:
- Across standard and adversarial VQA benchmarks, DDP delivers 3–10% absolute improvements over state-of-the-art VLM backbones in zero-shot and perturbed settings.
- On MMBench, SEED-Bench, and VQAv2, DDP (with Gemini-3-Pro) achieves 92.1%, 94.5%, and 89.4% accuracy, significantly outperforming the unmodified backbone (up to +8.7%).
- On highly challenging visual tasks (ColorBlind, V*Bench), all standard VLMs achieve close to 0% on Pass@1; DDP achieves 29.33%.
- Robustness to noise and adversarial perturbation is empirically validated: e.g., on perturbed images (DataCV CVPR Challenge), DDP demonstrates a +20% increase in accuracy over the baseline.
Ablation studies demonstrate that aggressive degradation (downsampling/blurring), autonomous tool invocation, and prompt engineering each contribute substantial, non-redundant gains. Removal of the image degradation yields the sharpest drop in performance (−8.7%), confirming the central hypothesis of the work.
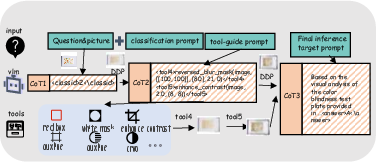
Figure 4: DDP pipeline case: external tools and degradation yield purified intermediate images, enabling robust reasoning on perception-intensive edge cases.
Theoretical and Practical Implications
The primary theoretical contribution is the demonstration that deliberately constraining perceptual bandwidth via multi-level degradation compels VLMs to suppress spurious local features, thereby enforcing semantic and structural reasoning. This setup is explicitly supported by the Data Processing Inequality: reduction of input entropy via downsampling minimizes the mutual information between high-frequency noise and model predictions.
Practically, the DDP framework validates agentic, tool-augmented inference—treating modern VLMs not as static classifiers but as active, recursive reasoners capable of self-correction and hypothesis testing. The strategy is inherently extensible: new tools, prompts, and domain-specific augmentations can be incorporated to target additional failure modes.
Prospects and Future Directions
DDP establishes that "less is more" for VQA: detail reduction outperforms parameter scaling for tasks dominated by local noise and adversarial visual structure. Its agentic design paradigm aligns closely with future directions in multi-modal cognition, human-in-the-loop decision making, and robustness to distributional shift.
Potential future developments include automated toolset expansion (via meta-learning or neural-symbolic search), dynamic resolution tuning driven by uncertainty estimation, and deeper integration with external physical measurement or simulation engines for real-world robotic perception. Furthermore, interpretability and auditability are substantially enhanced, as the pipeline exposes intermediate reasoning states and tool invocations, directly supporting diagnostics and regulatory transparency.
Conclusion
Degradation-Driven Prompting (DDP) reframes multi-modal vision from passive observation to active, tool-rich reasoning, providing empirical and theoretical evidence that strategic downsampling and agentic tool-use systematically resolve failure cases endemic to modern VLMs. By focusing on global structure and leveraging modular evidence synthesis, DDP not only advances VQA accuracy but also opens explicit pathways for interpretable, reliable, and robust artificial vision architectures.

