GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Abstract: Visual grounding, localizing objects from natural language descriptions, represents a critical bridge between language and vision understanding. While multimodal LLMs (MLLMs) achieve impressive scores on existing benchmarks, a fundamental question remains: can MLLMs truly ground language in vision with human-like sophistication, or are they merely pattern-matching on simplified datasets? Current benchmarks fail to capture real-world complexity where humans effortlessly navigate ambiguous references and recognize when grounding is impossible. To rigorously assess MLLMs' true capabilities, we introduce GroundingME, a benchmark that systematically challenges models across four critical dimensions: (1) Discriminative, distinguishing highly similar objects, (2) Spatial, understanding complex relational descriptions, (3) Limited, handling occlusions or tiny objects, and (4) Rejection, recognizing ungroundable queries. Through careful curation combining automated generation with human verification, we create 1,005 challenging examples mirroring real-world complexity. Evaluating 25 state-of-the-art MLLMs reveals a profound capability gap: the best model achieves only 45.1% accuracy, while most score 0% on rejection tasks, reflexively hallucinating objects rather than acknowledging their absence, raising critical safety concerns for deployment. We explore two strategies for improvements: (1) test-time scaling selects optimal response by thinking trajectory to improve complex grounding by up to 2.9%, and (2) data-mixture training teaches models to recognize ungroundable queries, boosting rejection accuracy from 0% to 27.9%. GroundingME thus serves as both a diagnostic tool revealing current limitations in MLLMs and a roadmap toward human-level visual grounding.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at whether modern AI systems that can read text and look at pictures (called multimodal LLMs, or MLLMs) can truly “understand” pictures the way people do. In particular, it studies visual grounding: finding the exact object in an image that matches a natural-language description. The authors built a new, tougher test called GroundingME to see how well these AIs can handle tricky, real-life situations.
The main questions the paper asks
- Are today’s vision-language AIs actually grounding language in images, or are they just matching simple keywords?
- Can they tell apart very similar objects, understand complex spatial directions, handle hard-to-see things, and admit when a description doesn’t match anything in the image?
- How do different models compare on a more realistic, harder benchmark?
- Can simple strategies at test time or during training help them do better?
How the researchers tested this
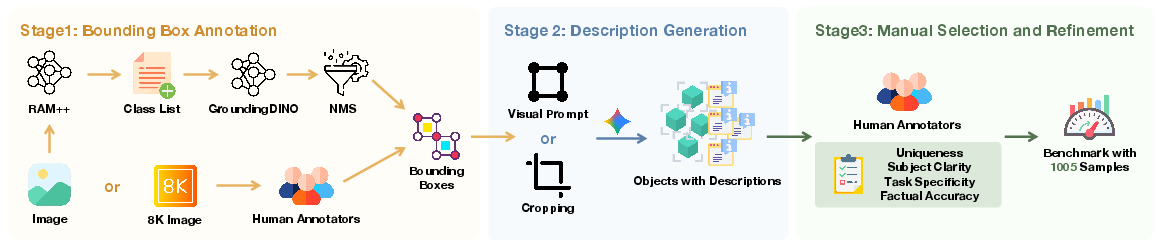
They created a new benchmark (a carefully built test set) called GroundingME with 1,005 examples. Each example is an image plus a description, and the task is to draw a rectangle (a “bounding box”) around the exact object the description refers to—or say “nothing matches” when it doesn’t.
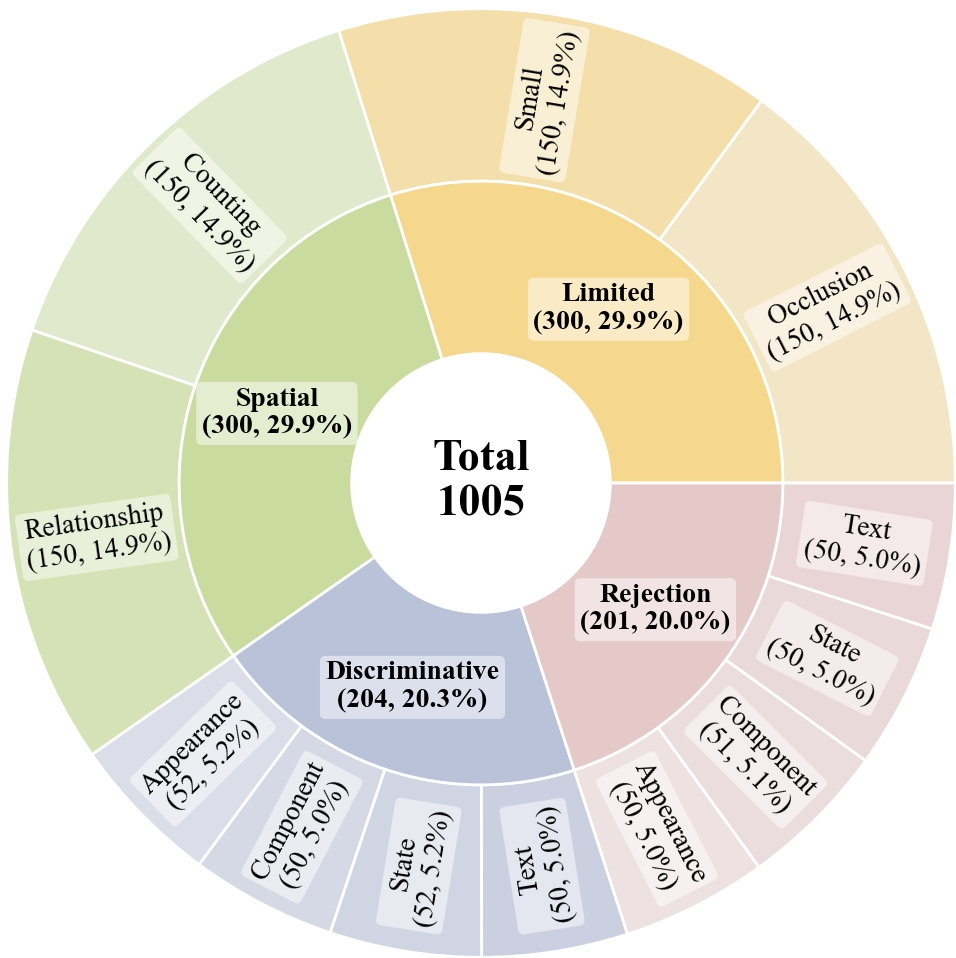
To make the benchmark realistic and challenging, they covered four key skill areas:
- Discriminative: Can the model spot subtle differences to pick out the correct object among very similar ones?
- Spatial: Can it understand complex positions and relationships (like “the third mug from the left, under the shelf, next to the red book”)?
- Limited: Can it handle tough visuals, like tiny objects or objects partly hidden (occluded)?
- Rejection: Can it recognize that the description does not match any object and correctly say “no answer”?
How they built it, in everyday terms:
- Picking images: They used big, high-quality image sets with complex scenes and very high resolution (like 8K). High resolution lets you test tiny details.
- Drawing boxes around objects: They used tools to suggest rectangles around objects (RAM++ and GroundingDINO) and then cleaned up duplicates with a filtering step. For especially high-res images, humans drew boxes to be precise.
- Writing descriptions: An AI wrote draft descriptions of what an object looks like and where it is. Then human annotators refined them to ensure the description:
- Points to exactly one object (or none, for rejection cases),
- Is clear about what the target is,
- Fits the subtask (e.g., uses counting words for counting),
- Is factually correct (or intentionally incorrect for rejection).
- Final checks: Humans verified that the examples are hard but fair, removed overly simple cases, and kept a balanced mix across the four categories.
How they measured performance:
- Models must output a box for the target object. They used accuracy based on overlap between the predicted box and the correct box. If the overlap is big enough, it counts as correct. For rejection cases, the model must output “no object.”
What they found and why it matters
Big picture:
- Even the best model only got 45.1% correct overall. Many models scored much lower.
- Most models did extremely poorly on rejection—often 0%. This means they “hallucinate” objects and claim something is there when it isn’t, which can be unsafe.
Key patterns:
- Larger models tend to do better, but still struggle on the hardest parts.
- Models are better at “discriminative” tasks (spotting differences) than at rejecting wrong descriptions.
- Spatial tasks are hard, especially counting correctly.
- Limited-visibility tasks (tiny or occluded objects) are also challenging.
Two ways they tried to improve performance:
- Test-time thinking and selection:
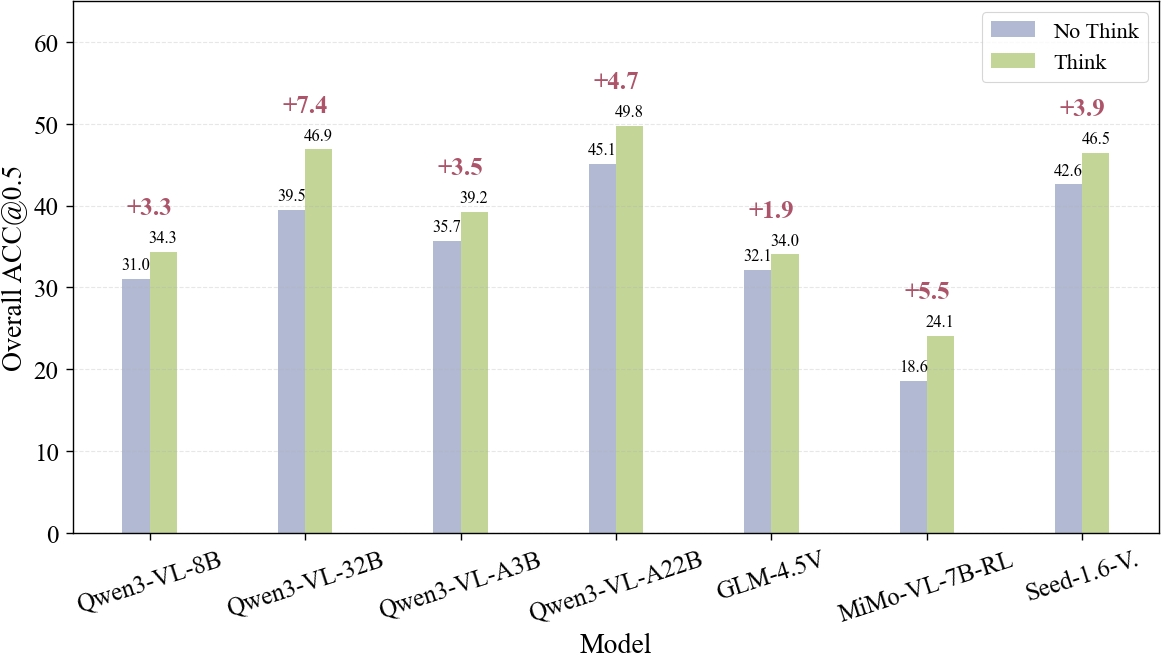
- “Thinking mode” means the model writes out its reasoning steps before answering.
- Generating multiple “reasoning paths” and using a separate text-only AI judge to pick the best one improved accuracy by up to 2.9%, especially on spatial and rejection tasks.
- This suggests that careful reasoning, not just perception, helps in complex grounding.
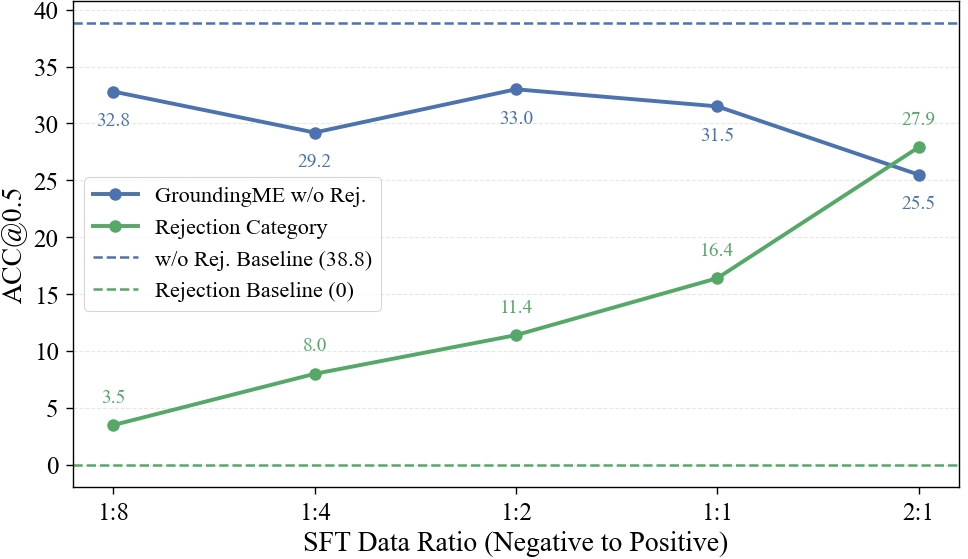
- Training with “negative” examples:
- They fine-tuned a model on a mix of normal (positive) examples and negative (rejection) examples where the description doesn’t match the image.
- This taught the model to say “no answer” more often when appropriate, boosting its rejection accuracy from 0% to 27.9% on GroundingME’s rejection tests.
- However, this sometimes reduced performance on other tasks outside the training set, showing there’s a trade-off to manage.
Why this is important
- Safety and reliability: If a model can’t say “I don’t see that,” it may give wrong answers that cause harm in real-world situations, like robotics, autonomous driving, or medical tools.
- Honest understanding: High scores on older, simpler tests can hide the fact that models are relying on shortcuts (like keyword matching) instead of genuine visual understanding.
- A roadmap forward: GroundingME reveals where models fail and points to practical fixes—better reasoning at test time and training with realistic negative examples.
Bottom line and future impact
GroundingME shows that today’s vision-language AIs still have a big gap in truly grounding language to vision, especially in tricky, real-life conditions. The paper highlights:
- We need harder, more realistic tests to measure true ability.
- Models should learn to reject mismatches, not guess.
- Combining better test-time reasoning with smarter training data can make models more precise and trustworthy.
This work is a step toward AI systems that understand images and language more like humans do—and that know when not to answer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and unresolved questions that emerge from the paper, intended to guide actionable future research.
- Dataset scale and coverage
- The benchmark contains only 1,005 items; does performance and ranking stability hold at larger scales?
- Domain breadth is limited (consumer photos from SA-1B and HR-Bench). How do results transfer to specialized domains (e.g., medical, remote sensing, scientific figures, documents/infographics) and to non-photographic imagery (diagrams, charts, UI)?
- Only single-image, static grounding is evaluated; no video/temporal grounding, multi-image grounding, or 3D/embodied settings.
- Language scope
- All descriptions appear to be in English. How do grounding and rejection behaviors generalize to other languages, code-switched inputs, or low-resource linguistic phenomena?
- Annotation pipeline validity
- Bounding boxes for SA-1B images are seeded by RAM++ and GroundingDINO, then filtered; the residual error rate after human refinement is not quantified. What is inter-annotator agreement and remaining annotation noise?
- “Component” references can blur part–whole boundaries. Are annotation policies consistent for parts vs whole-object targets, and are they reliable across annotators?
- Uniqueness was enforced, but alternative valid groundings might exist. How often are models penalized for selecting a plausible alternate referent?
- Negative/rejection data construction
- Rejection cases are “intentionally introduced or retained” errors; the taxonomy, frequency, and realism of these error types (e.g., subtle attribute mismatch vs semantic negation vs impossible counts) are not characterized.
- The generalization failure of rejection-capable models OOD suggests negative examples may not reflect real user queries. How to build naturalistic, diverse, and hard negative sets that transfer?
- Input resolution and fairness
- Images include 8K content, but many MLLMs downsample internally. How much of the failure on Small/Occlusion stems from model input-resolution limits rather than reasoning deficits?
- No control for per-model preprocessing, image tiling/zooming, or tool-assisted cropping; comparisons may be confounded by disparate visual front-ends.
- Evaluation protocol sensitivity
- Results are highly prompt- and format-sensitive (e.g., Gemini requires a different coordinate order). How robust are rankings to prompt variants, few-shot exemplars, or output formatting constraints?
- Greedy decoding is used for main results; the effect of decoding strategies (temperature, nucleus sampling, self-consistency) on grounding and rejection is not systematically studied.
- Metrics and diagnostics
- Main metric is [email protected]; there is limited analysis of IoU sensitivity, bounding-box localization errors (center/size bias), or mAcc across thresholds for all subtasks.
- No calibration/abstention metrics (e.g., selective risk, AUROC for reject vs accept), nor precision–recall trade-offs for rejection.
- No per-class, per-attribute, or per-factor (occlusion level, instance area ratio, clutter density, description length) breakdowns to isolate specific failure modes.
- No human baseline on the full benchmark (only a small rejection verification subset); the claimed “human-like sophistication” remains unquantified.
- Comparison baselines
- The study evaluates MLLMs only. How do state-of-the-art specialized grounding systems (e.g., GLIP/Grounding DINO derivatives, REC-specific models) perform under identical protocols?
- Test-time scaling (TTS) methodology
- The text-only judge selects “best” trajectories without seeing the image. Does it favor verbal fluency/length over visual correctness (Goodhart risk)? Human audits of selected vs rejected trajectories are missing.
- Computational cost, latency, and energy for N=16 sampling + judging are not reported; practicality for deployment is unclear.
- Variance across seeds (N, temperature) and statistical significance of the 2–3% gains are not established.
- Training strategy for rejection
- Data-mixture SFT improves rejection but harms OOD positive grounding. How to avoid this trade-off (e.g., multi-task curricula, contrastive “no-object” objectives, consistency regularization, uncertainty-aware training)?
- What is the impact of richer negative taxonomies (negation, quantifier mismatch, relational contradictions, text OCR mismatches) and hard-negative mining?
- Tool use and perception enhancement
- Tool-use evaluation (zoom/crop) is limited and yields unexpectedly low gains. What systematic tool pipelines (sliding windows, multi-scale tiling, adaptive zoom) are needed to fairly test and boost Small/Occlusion cases?
- Safety and interaction
- Rejection is binary; no evaluation of safer interactive behaviors (clarifying questions, deferral) or calibrated abstention thresholds that trade off misses vs false assertions.
- No analysis of hallucination persistence after incorrect rejection decisions or of compounded risk in multi-turn settings.
- Generalization and contamination risk
- Although only raw images are used, model pretraining may include these images. Is there any leakage detection (near-duplicate checks, image hashing) or sensitivity analysis to rule out contamination effects?
- Reproducibility and reporting
- Confidence intervals, bootstrap CIs, or multiple-run variance are not reported; ranking stability is unknown.
- Judge prompts and selection criteria are provided, but there is no study on judge choice sensitivity (model family, size) or rubric designs.
- Granularity of supervision
- The benchmark uses bounding boxes; some references (fine parts, thin structures, text glyphs) may be better evaluated with segmentation or keypoint-level ground truth.
- Broader coverage of relational reasoning
- Spatial tasks include Relationship and Counting only. Compositional, nested, and multi-hop relational reasoning (e.g., “the bottle left of the mug that is on the tray nearest the sink”) is not separately probed.
- Counting rigor
- Counting difficulty (object density, uniformity, occlusion, distractor similarity) and error modes (off-by-one, ordinal vs cardinal confusion) are not dissected.
- Prompted description generation biases
- Initial descriptions are produced by Gemini-2.5-Flash; this may introduce stylistic or semantic biases. How do results change if descriptions are authored by humans or other LLMs, or if linguistic style varies?
- Ethics and licensing
- The paper does not discuss licensing/consent for SA-1B/HR-Bench images in the context of new annotations, nor potential demographic biases in source imagery and their impact on grounding performance.
Glossary
- [email protected]: A localization metric counting predictions whose IoU with ground truth exceeds 0.5. "we adopt the widely-used [email protected], which represents the proportion of total samples where the Intersection over Union (IoU) between the ground-truth and predicted bounding box exceeds 0.5."
- Best-of-16: A selection strategy that compares multiple candidate outputs and chooses the best one. "to perform a \"Best-of-16\" selection: the judge compares the 16 full responses in a pairwise manner, selecting the one with the superior thinking trajectory quality, and repeats until only one response remains."
- Bounding box: A rectangular region used to localize an object in an image via coordinates. "The green bounding box indicates the correct ground-truth object, while the red bounding box shows the answer of Qwen3-VL-30B-A3B-Instruct."
- Data contamination: Overlap between evaluation tasks and training data that can inflate performance. "This ensures that even if models encountered the source images during training, the task itself remains novel, thus effectively mitigating the risk of data contamination."
- Data-mixture training: Fine-tuning with both positive and negative samples to teach rejection capability. "data-mixture training teaches models to recognize ungroundable queries, boosting rejection accuracy from 0% to 27.9%."
- DeepSeek-R1: A text-only LLM used as a judge in test-time selection. "We test DeepSeek-R1 and MiMo-7B-RL-0530 as judges."
- Greedy decoding: Deterministic generation with temperature set to zero. "all experiments are conducted using greedy decoding (set as temperature=0)."
- GroundingDINO: An open-vocabulary detector used to generate bounding boxes from text queries. "we develop an automated pipeline that combines RAM++~\cite{zhang2024recognize}, GroundingDINO~\cite{liu2024grounding}, and a customized Non-Maximum Suppression (NMS) rule."
- GroundingME: A benchmark designed to expose visual grounding gaps across multiple dimensions. "we introduce GroundingME, a benchmark that systematically challenges models across four critical dimensions"
- HR-Bench: A high-resolution image dataset used for small-object grounding evaluation. "HR-Bench offers ultra-high resolution with its 8K subset essential for creating tasks where minute objects are clearly resolvable."
- Human-in-the-loop: An annotation process where humans refine and validate automatically generated data. "a three-stage human-in-the-loop annotation pipeline"
- Intersection over Union (IoU): The area overlap ratio between predicted and ground-truth boxes. "the Intersection over Union (IoU) between the ground-truth and predicted bounding box exceeds 0.5."
- Instance Area Ratio: The ratio of an instance’s bounding box area to the image area. "the Instance Area Ratio (the area of an instance's bounding box divided by the image area) Quartile measures only (0.16%, 1.0%, 2.7%)"
- Intra-Class Count Quartile: Quartile statistics of the number of instances per class, indicating distractor density. "The challenge of intra-class confusion is quantified by the high Intra-Class Count Quartile of (5, 7, 12), indicating a large number of similar distracting objects in the image."
- L-1 category: The top level in the benchmark’s taxonomy defining broad challenge dimensions. "We design a challenge taxonomy that systematically evaluates models across four L-1 dimensions, as shown in \cref{fig:example}."
- L-2 subcategory: The second-tier taxonomy offering fine-grained diagnostic challenge types. "we provide a fine-grained L-2 hierarchy covering twelve subcategories to enable a deeper, diagnostic analysis of model performance."
- mAcc: Mean accuracy computed across a range of IoU thresholds. "New metrics include [email protected], [email protected], and mAcc."
- Mixture-of-Experts (MoE): A model architecture that routes inputs among specialized expert subnetworks. "This scaling trend is consistently verified across model families, including Qwen3-VL-Dense (2B to 32B: 21.1% to 39.5%), Qwen3-VL-MoE (A3B to A22B: 35.7% to 45.1%), and Qwen2.5-VL 7B to 72B: 15.1% to 29.6%."
- Multimodal LLMs (MLLMs): Models that jointly process and reason over text and images. "The rise of Multimodal LLMs (MLLMs) represents a paradigm shift in artificial intelligence, offering unprecedented capabilities in joint vision and language understanding"
- Non-Maximum Suppression (NMS): An algorithm to remove redundant detections by suppressing overlapping boxes. "we apply a customized NMS rule. Instead of prioritizing boxes by area, our NMS strategy favors those belonging to classes with a higher instance count"
- Occlusion: Visual obstruction where parts of an object are hidden, complicating grounding. "Limited—handling occlusions or tiny objects"
- Open vocabulary: Settings where object categories are not restricted to a fixed label set. "progressing from closed set, single objects, brief phrases to open vocabulary, generalized targets, and complex descriptions."
- RAM++: A model used to recognize object categories in images to form text queries. "we develop an automated pipeline that combines RAM++~\cite{zhang2024recognize}, GroundingDINO~\cite{liu2024grounding}, and a customized Non-Maximum Suppression (NMS) rule."
- RefCOCOg: A referring-expression grounding dataset used for fine-tuning and evaluation. "By fine-tuning Qwen3-VL-8B-Instruct on RefCOCOg~\cite{mao2016generation} augmented with negative samples"
- Referring Expression Comprehension (REC): Grounding an object specified by a natural-language phrase. "also known as Referring Expression Comprehension (REC)"
- Rejection (visual grounding): The capability to output “no object” when a description is ungroundable. "Rejection—recognizing ungroundable queries."
- SA-1B: A large-scale dataset from Segment Anything used as an image source. "The SA-1B dataset, which is widely used~\cite{li2025denseworld,shen2024aligning}, offers extensive resources of complex scenes and high object density, with 11 million images and 1.1 billion masks."
- SFT (Supervised Fine-Tuning): Fine-tuning a model on labeled examples to adapt its behavior. "These 60,000 instances serve as the source pool for generating various SFT datasets."
- Test-Time Scaling (TTS): Sampling multiple responses at inference and selecting the best to improve accuracy. "we design a Test-Time Scaling (TTS) method~\cite{llm_monkey,Snell2024ScalingLT,InferenceSL} specifically tailored to analyze the efficacy of the thinking trajectory."
- Thinking mode: A generation mode where models explicitly produce reasoning steps. "we observe that enabling thinking mode generally improves performance and enables basic rejection behavior."
- Thinking trajectory: The chain of reasoning content produced by the model before its final answer. "we conduct a detailed case study focusing on the relationship between the quality of the generated thinking trajectory and the final grounding accuracy."
- Visual grounding: Localizing image regions from natural-language descriptions. "Visual grounding—localizing objects from natural language descriptions—represents a critical bridge between language and vision understanding."
- Visual prompting: Guiding an MLLM with visual cues (e.g., highlighted boxes) to elicit descriptions. "we utilize the model’s visual prompting capability by framing the objects in the full-size image with a red bounding box"
Practical Applications
Practical Applications of GroundingME and Its Methods
Below are actionable, real-world applications that leverage the benchmark (GroundingME), its taxonomy (Discriminative, Spatial, Limited, Rejection), and the paper’s improvement methods (test-time scaling via thinking-trajectory selection and data-mixture training with negative samples). Each item names target sectors, suggests concrete tools/workflows, and lists key assumptions/dependencies.
Immediate Applications
These can be deployed or piloted now with existing MLLMs and the released benchmark/pipeline.
- Bold model benchmarking and vendor procurement checks
- Sectors: software/AI, robotics, autonomous systems, UX tooling
- What to do: Use GroundingME as an acceptance test for products claiming “visual grounding,” requiring minimum scores per L-1/L-2 category (e.g., Spatial→Counting, Limited→Small, Rejection). Rank/rout models by subtask strengths.
- Tools/workflows: CI test suites, model scorecards, routing tables that dispatch queries to models strong in specific subtasks.
- Assumptions/dependencies: Benchmark licensing and reproducible evaluation; domain representativeness; agreed pass/fail thresholds.
- Safety auditing and red-teaming for hallucination rejection
- Sectors: healthcare imaging UX, AV/HRI telemetry review, surveillance, content moderation
- What to do: Stress-test products with Rejection cases to ensure systems say “no object found” when grounding is impossible. Use results to set guardrails or trigger clarifying prompts.
- Tools/workflows: Rejection test harness; “reject-or-clarify” prompts; incident playbooks.
- Assumptions/dependencies: Domain-specific calibration; clear UX for refusals; logging for auditability.
- Test-time scaling via “Best-of-N thinking trajectory” selector
- Sectors: robotics, AR assistants, e-commerce visual search, industrial inspection
- What to do: Generate N candidate answers with rationales and select the best using a text-only LLM judge to boost Spatial and Rejection accuracy with minimal engineering.
- Tools/workflows: Reasoning-Trajectory Selector microservice; latency-aware N tuning; caching.
- Assumptions/dependencies: Models that support thinking/rationales; cost/latency budget; rationale privacy policies.
- Rejection-aware fine-tuning (negative-sample data mixture)
- Sectors: AR/VR assistants, on-device agents, image editing tools, e-commerce search
- What to do: Add negative samples to SFT data to teach “reject when ungroundable,” then measure trade-offs on positive samples; deploy where false positives are riskier than misses.
- Tools/workflows: Data-Mixture Trainer; automated negative-sample generator and validation; per-subtask A/B tests.
- Assumptions/dependencies: Domain shift can degrade other subtasks; continuous evaluation needed.
- Domain-specific benchmark construction using the provided pipeline
- Sectors: healthcare (radiology screenshots/clinical photos), remote sensing, retail shelf analytics, industrial QA
- What to do: Adapt the pipeline (RAM++ + GroundingDINO + LLM descriptions + human refinement) to build in-domain grounding tests with the same taxonomy and 8K/occlusion emphasis where relevant.
- Tools/workflows: Annotation guidelines by L-1/L-2; LLM-assisted description authoring; human refinement loop.
- Assumptions/dependencies: Labeling budget/expertise; privacy/compliance for domain images.
- Product QA for “select-by-description” features in creative software
- Sectors: design/photo/video editing, ad-tech
- What to do: Validate selection precision for fine-grained/occluded/tiny targets; fall back to clarify or request box hints when uncertain; explicitly handle Rejection.
- Tools/workflows: Grounding regression tests; uncertainty-aware UI; instruction templates.
- Assumptions/dependencies: High-DPI input handling; precise IoU measurement; user education.
- UI automation and accessibility testing with visual grounding
- Sectors: software QA, accessibility
- What to do: Evaluate agents that locate on-screen elements from natural language (e.g., “the third icon from left”); ensure they reject ambiguous or absent items.
- Tools/workflows: Screenshot-based testbeds; Counting/Spatial sub-benchmarks; Rejection policies.
- Assumptions/dependencies: Stable layout in screenshots; DPI/scale normalization.
- Robotics and warehouse pick-and-place instruction validation
- Sectors: logistics/warehouse robotics, service robots
- What to do: Measure grasp target selection from instructions (Discriminative/Spatial), enforce Rejection to avoid wrong picks; deploy test-time scaling on hard cases.
- Tools/workflows: Sim-to-real test harness; camera-perspective augmentation; judge-based selection.
- Assumptions/dependencies: Domain adaptation for lighting/clutter; latency constraints.
- Data strategy planning guided by the taxonomy
- Sectors: ML Ops, data engineering
- What to do: Use failure breakdowns (e.g., Limited→Small) to plan targeted data collection and labeling that closes gaps systematically.
- Tools/workflows: Subtask dashboards; collection tasks keyed to failure modes; periodic re-benchmarking.
- Assumptions/dependencies: Data acquisition channels; cost-benefit prioritization.
- Edge-readiness and capacity planning
- Sectors: mobile/embedded AI, IoT cameras
- What to do: Evaluate small models (2B–8B) on GroundingME to decide on-device vs. server offload, and where TTS is worth the latency.
- Tools/workflows: Latency/accuracy trade-off models; tiered inference paths.
- Assumptions/dependencies: Hardware constraints; privacy/ bandwidth policies.
- Continuous monitoring and regression testing
- Sectors: all production multimodal systems
- What to do: Track GroundingME metrics in CI/CD and in production (shadow eval) to detect drift (e.g., rejection accuracy collapses to 0%) and trigger rollbacks or retraining.
- Tools/workflows: Scheduled evals; alerting on subtask drops; canary releases.
- Assumptions/dependencies: Stable versioning and eval infra; cost controls.
- Policy/compliance readiness checks
- Sectors: gov/public-sector procurement, regulated industries
- What to do: Use GroundingME Rejection and Spatial categories in pre-deployment safety attestations; require disclosure of rejection behavior and limitations.
- Tools/workflows: Standard test reports; vendor attestations tied to subtask thresholds.
- Assumptions/dependencies: Contractual acceptance; interpretability of scores by non-technical stakeholders.
Long-Term Applications
These require further research, scaling, domain adaptation, or ecosystem standardization.
- Regulated “grounding safety” standards and certification
- Sectors: AV, healthcare, industrial robotics, consumer AR
- What to do: Establish standardized conformance tests (including Rejection) as part of certification (analogous to ISO/UL), tied to risk categories.
- Tools/workflows: Public test suites and leaderboards; third-party labs.
- Assumptions/dependencies: Multi-stakeholder governance; public datasets that reflect domain risks.
- Robust multimodal systems integrating tool-use for high-resolution perception
- Sectors: remote sensing, industrial inspection, medicine (non-diagnostic UX), defense
- What to do: Compose LLMs with perceptual tools (multi-scale crop/magnify/track) to solve Limited→Small/Occlusion more reliably than current benchmarks.
- Tools/workflows: Orchestrators for iterative crop-and-verify; pixel-precise box refinement.
- Assumptions/dependencies: Tool APIs; latency budgets; improved IoU precision.
- Groundability/confidence APIs and calibrated refusal UX
- Sectors: consumer assistants, enterprise workflows
- What to do: Output calibrated “grounding confidence” with explicit refusal states; route low-confidence cases to human-in-the-loop or clarification prompts.
- Tools/workflows: Confidence calibration datasets; abstention thresholds per subtask.
- Assumptions/dependencies: Reliable calibration under domain shift; clear UX patterns.
- Architecture advances targeted to GroundingME failure modes
- Sectors: AI research, platform providers
- What to do: Develop modular MLLMs with stronger fine-grained perception, quantitative counting, and rejection; aim for >80% on GroundingME.
- Tools/workflows: Structured grounding graphs; compositional reasoning modules; curriculum schedules emphasizing negatives.
- Assumptions/dependencies: Training compute; high-quality negatives at scale; reproducible ablations.
- Safe image-editing and generative tools with grounding checks
- Sectors: creative software, marketing
- What to do: Enforce edits only when targets are confidently grounded; otherwise solicit clarifications or show candidates.
- Tools/workflows: Pre-edit validation stage; think-and-select TTS; visual diffs for user validation.
- Assumptions/dependencies: Acceptable latency; intuitive UX for “no-edit” outcomes.
- Robotics/HRI assistants with explicit rejection behavior
- Sectors: domestic/service robots, warehouses
- What to do: Teach robots to refuse ambiguous/ungroundable commands; escalate or ask for disambiguation.
- Tools/workflows: Dialogue loops; grounding-aware planners; rehearsal in synthetic/joint benchmarks.
- Assumptions/dependencies: Speech/gesture fusion; safety cases; domain randomization.
- Domain-specific medical grounding assistants (with strict refusal)
- Sectors: healthcare (non-diagnostic support)
- What to do: Localize described findings in clinical photos with high rejection fidelity; solicit clinician confirmation; never guess.
- Tools/workflows: In-domain benchmark akin to GroundingME; SFT with curated negatives; audit trails.
- Assumptions/dependencies: Regulatory approval; PHI-safe pipelines; clinical validation.
- Retail shelf intelligence and planogram compliance
- Sectors: retail, CPG
- What to do: Count/locate products under occlusion; refuse when not confidently grounded; flag for human review.
- Tools/workflows: Spatial/Counting-centric datasets; TTS for hard cases; exception queues.
- Assumptions/dependencies: Frequent domain shifts (lighting, packaging); high-res capture.
- Accessibility agents for blind/low-vision users with conservative refusals
- Sectors: assistive tech
- What to do: Provide spatial guidance only when confident; otherwise ask for more context (move camera/zoom).
- Tools/workflows: Uncertainty-aware narration; multi-shot capture prompts; on-device judges when possible.
- Assumptions/dependencies: Privacy; battery/latency; ergonomic capture.
- Insurance/risk pricing informed by grounding benchmarks
- Sectors: insurance, enterprise risk
- What to do: Use subtask scores (especially Rejection) to price risk of AI-driven operations (e.g., AV fleets, robotic picking).
- Tools/workflows: Risk models tied to benchmark thresholds; SLAs tied to ongoing re-evals.
- Assumptions/dependencies: Actuarial acceptance; periodic third-party audits.
- Education and competitions for multimodal reasoning
- Sectors: academia, developer communities
- What to do: Use GroundingME to teach and compete on grounding with rejection/occlusion; develop best practices for data mixtures and TTS.
- Tools/workflows: Course kits; challenge leaderboards; open baselines.
- Assumptions/dependencies: Sustainable hosting and licensing; community engagement.
- Tooling ecosystem: Rejection Data Mixer and Trajectory Judge products
- Sectors: AI platforms, MLOps
- What to do: Offer turnkey components for negative-sample generation and TTS-based selection, with cost/latency controls and privacy options.
- Tools/workflows: SDKs, managed services, evaluators.
- Assumptions/dependencies: Vendor interoperability; telemetry for monitoring ROI.
Cross-Cutting Assumptions/Dependencies
- Data/domain shift: Gains from negative-sample SFT may not transfer cost-free to out-of-domain tasks; continuous evaluation is essential.
- Cost/latency: TTS and multi-candidate inference add inference overhead; practical deployments need N and judge size tuned to budgets.
- Privacy/compliance: Thinking traces and images may contain sensitive data; establish retention and masking policies.
- High-resolution handling: Many Limited→Small cases require 8K capture and precise box placement; tool-use integration and multi-scale perception are often necessary.
- Benchmark scope: GroundingME images are general-purpose; critical domains (e.g., medical, defense) require in-domain benchmarks with similar taxonomy.
- Transparency: Some commercial models may not output reliable box formats; standardization of output schemas is needed for broad interoperability.
Collections
Sign up for free to add this paper to one or more collections.