Self-Improving VLM Judges Without Human Annotations
Abstract: Effective judges of Vision-LLMs (VLMs) are crucial for model development. Current methods for training VLM judges mainly rely on large-scale human preference annotations. However, such an approach is costly, and the annotations easily become obsolete as models rapidly improve. In this work, we present a framework to self-train a VLM judge model without any human preference annotations, using only self-synthesized data. Our method is iterative and has three stages: (1) generate diverse multimodal instruction-response pairs at varying quality levels, (2) generate reasoning traces and judgments for each pair, removing the ones that do not match our expected quality levels, and (3) training on correct judge answers and their reasoning traces. We evaluate the resulting judge on Multimodal RewardBench and VL-RewardBench across domains: correctness, preference, reasoning, safety, and visual question-answering. Our method improves a Llama-3.2-11B multimodal judge from 0.38 to 0.51 in overall accuracy on VL-RewardBench, often outperforming much larger models including Llama-3.2-90B, GPT-4o, and Claude 3.5 Sonnet, with particularly strong gains in general, hallucination, and reasoning dimensions. The overall strength of these human-annotation-free results suggest the potential for a future self-judge that evolves alongside rapidly improving VLM capabilities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Self-Improving VLM Judges Without Human Annotations”
Overview
This paper is about teaching a computer model to be a fair judge of other computer models’ answers to questions about images. The special part: it learns to judge without any help from humans. Instead, it creates its own practice data and improves itself step by step.
The model is a “VLM judge,” which means it can read text and look at images (Vision-LLM), and then decide which of two answers is better. This helps make other AI systems more trustworthy and more aligned with what people want.
Key Objectives
The paper aims to:
- Show that a VLM can train itself to be a good judge using only its own generated answers—no human labels needed.
- Build a simple system to create “practice pairs” of answers where one is better than the other.
- Improve the judge model over several rounds, using its own reasoning to learn what makes a good evaluation.
- Test how well this self-trained judge works compared to bigger, more expensive models.
Methods (in everyday language)
Think of training a judge like training a referee who needs lots of practice matches with clear winners and losers. The trick here is to create those practice matches automatically.
The approach has three main parts:
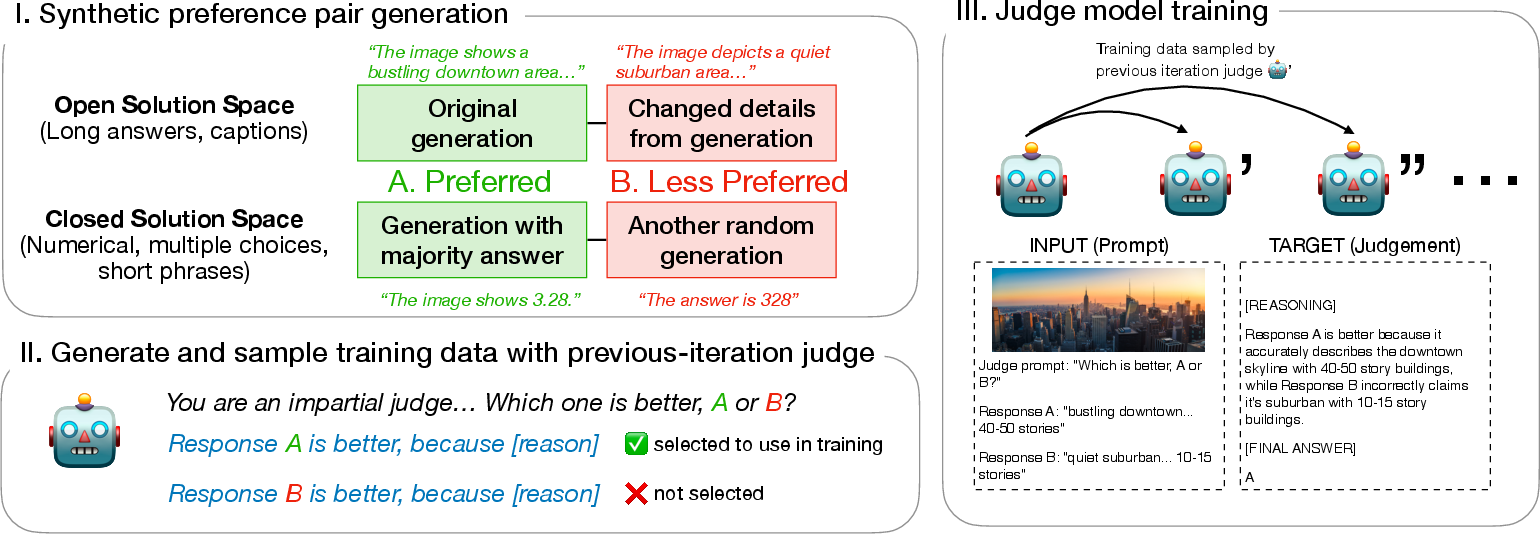
1) Making practice answer pairs with a known “better” choice
There are two types of questions:
- Closed-ended questions: These have short, clear answers (like picking A/B/C/D or a number).
- Open-ended questions: These need longer answers (like writing a caption or explaining a scene).
To create training examples:
- Closed-ended (short answers): The model answers the question many times. The most common answer is treated as the “likely better” one. A different, randomly chosen answer becomes the “worse” one. This is like asking the same question to a crowd and trusting the majority.
- Open-ended (long answers): The model first writes a normal answer (like a caption). Then it creates a second version with deliberate mistakes—changing details like colors, numbers, or object positions. For example, turning “a red car” into “a blue car” when the car is actually red in the image. The original answer is preferred over the altered one. This builds realistic examples where one answer is clearly better.
This way, the team always knows which answer in the pair should be preferred, without needing human judges.
2) Collecting the judge’s reasoning and filtering it
For each pair, the current judge model explains its decision and picks which answer is better. The system keeps only the cases where the judge agrees with the known preferred choice. It also checks for “position bias” (some models just prefer the first answer), so it swaps the order and only keeps cases where the judge is correct both ways. This helps make sure the judge is learning based on solid reasoning, not lucky guessing.
3) Training the judge and repeating
The judge is fine-tuned (trained) on these filtered examples and the reasoning it produced. Then the whole process repeats several times, each time with the improved judge generating better reasoning and better training data. This is like a coach who reviews only the correct plays to teach better habits, over multiple practice rounds.
Main Findings and Why They Matter
The researchers trained a relatively small model (Llama-3.2-11B Vision) to be a judge using this method and tested it on standard benchmarks:
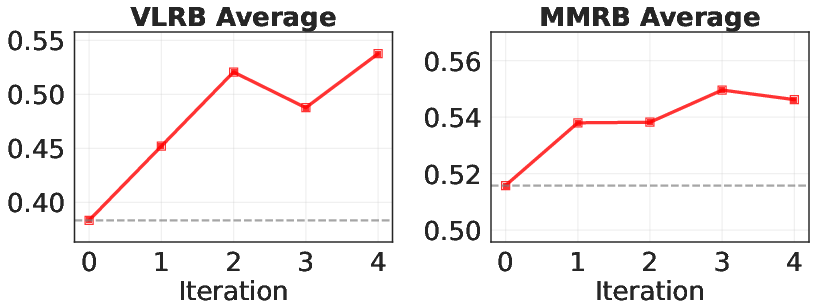
- On VL-RewardBench (VLRB), the judge’s accuracy rose from about 0.38 to about 0.54 after four iterations. That’s a big improvement, and it sometimes beat much larger models, including a 90B-parameter version and a popular commercial model (Claude 3.5 Sonnet), especially on general instruction-following.
- On Multimodal RewardBench (MMRB), the judge went from about 0.50 to about 0.54. It improved notably on VQA (Visual Question Answering) and stayed competitive on other tasks.
What improved most:
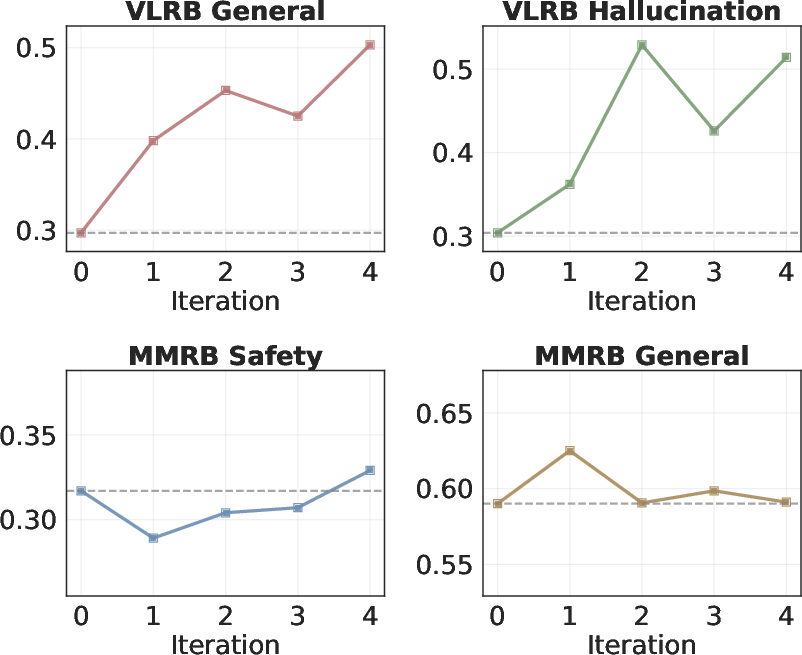
- General instruction-following and hallucination detection (spotting when a model mentions things not in the image) had strong gains. This means the judge got better at preferring answers that are grounded in what’s actually visible.
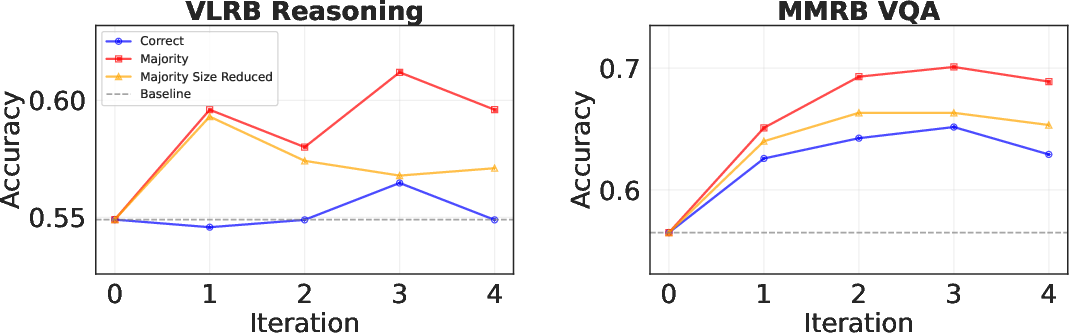
- VQA (short answers about images) also improved, showing the “majority vote” trick works well.
Where improvements were smaller:
- Safety-related judgments (detecting harmful or inappropriate content) improved only a little because the training didn’t include special safety-focused examples.
- Some reasoning tasks peaked around the third iteration and then leveled off, suggesting too many rounds can lead to overfitting.
Why this matters:
- It shows you don’t need expensive human labels to train a useful judge.
- A smaller, cheaper model can learn to evaluate well enough to rival bigger, pricier systems on some tasks.
- The method works on new image collections where there are no correct answers provided.
Implications and Potential Impact
- Cheaper and faster training: Because it needs no human annotations, this approach can be used widely to build judges for many tasks.
- Useful for new domains: It can handle brand-new image sets or topics where ground-truth answers don’t exist.
- Better alignment: As a judge gets better, it can help improve other models by rewarding accurate, well-grounded answers and discouraging hallucinations.
Future directions:
- Safety: To truly improve safety judgments, the method should include synthetic examples designed to test for bias, toxicity, or policy violations.
- Diversity: Using more varied images and tasks could help the judge generalize better across different visual domains.
- Specialized judges: Building multiple “expert” judges for specific skills (like reasoning, safety, or factual accuracy) and routing tasks to the right expert could boost performance further.
Overall, this paper shows a practical, clever way to train a strong multimodal judge using self-generated data, making high-quality AI evaluation more accessible and scalable.
Collections
Sign up for free to add this paper to one or more collections.

