VisionCoach: Reinforcing Grounded Video Reasoning via Visual-Perception Prompting
Abstract: Video reasoning requires models to locate and track question-relevant evidence across frames. While reinforcement learning (RL) with verifiable rewards improves accuracy, it still struggles to achieve reliable spatio-temporal grounding during the reasoning process. Moreover, improving grounding typically relies on scaled training data or inference-time perception tools, which increases annotation cost or computational cost. To address this challenge, we propose VisonCoach, an input-adaptive RL framework that improves spatio-temporal grounding through visual prompting as training-time guidance. During RL training, visual prompts are selectively applied to challenging inputs to amplify question-relevant evidence and suppress distractors. The model then internalizes these improvements through self-distillation, enabling grounded reasoning directly on raw videos without visual prompting at inference. VisonCoach consists of two components: (1) Visual Prompt Selector, which predicts appropriate prompt types conditioned on the video and question, and (2) Spatio-Temporal Reasoner, optimized with RL under visual prompt guidance and object-aware grounding rewards that enforce object identity consistency and multi-region bounding-box overlap. Extensive experiments demonstrate that VisonCoach achieves state-of-the-art performance under comparable settings, across diverse video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA), while maintaining a single efficient inference pathway without external tools. Our results show that visual prompting during training improves grounded video reasoning, while self-distillation enables the model to internalize this ability without requiring prompts at inference time.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
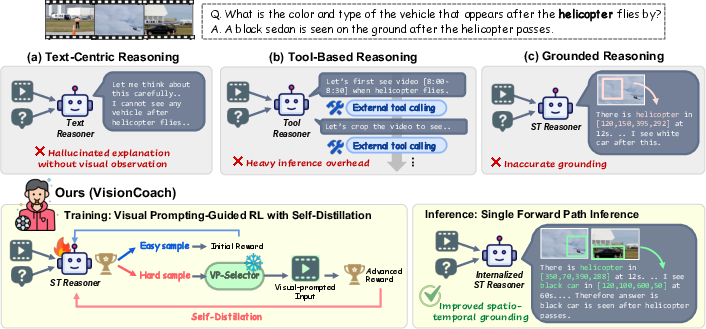
This paper introduces VisionCoach, a new way to train AI to understand and reason about videos. The key challenge is not just answering questions about a video, but also showing exactly when (which moment) and where (which region) the important evidence appears. VisionCoach acts like a “coach” during training: it highlights helpful parts of the video and dims distractions so the model learns to focus on the right things. After training, the model can answer questions accurately and point to the right evidence without any extra tools or highlighting.
What questions the researchers asked
The authors focused on a few simple questions:
- How can we make video AIs stop “guessing from text” and instead look at the right objects at the right times in the video?
- Can we teach a model to ground its reasoning (show when and where the evidence is) without relying on expensive extra tools at test time?
- Does giving the model smart visual hints during training help it learn this behavior for good?
How VisionCoach works (in everyday terms)
Think of training a player with a coach:
- The “player” is the Spatio-Temporal Reasoner, the main model that answers questions and must point to the right times and places in the video.
- The “coach” is a Visual Prompt Selector, which decides what kind of visual hint would help on a tricky question—like circling an object, darkening the background, or adding frame numbers.
Here’s the training routine, using simple analogies:
- Spot the hard questions
- The model tries answering questions on a video. If it struggles, we mark that example as “hard.”
- Add visual hints (visual prompts) during training
- For hard examples, the coach chooses a hint to help the model focus:
- Darken distractions so important areas pop out.
- Draw a circle around a key object.
- Add frame numbers to help track time.
- These hints are like a teacher putting a highlighter on the textbook.
- For hard examples, the coach chooses a hint to help the model focus:
- Reward the right behavior (reinforcement learning)
- The model gets “points” (rewards) for:
- Answering correctly.
- Using the required output format.
- Finding the right time in the video (temporal grounding).
- Pointing to the right object and region (spatial grounding).
- Spatial grounding uses an “overlap score” (IoU). Imagine two boxes: one is the correct area and one is the model’s guess; the score increases as the overlap grows.
- The model also gets credit for naming and tracking the right object (not just any box)—like consistently following the same person across frames.
- The model gets “points” (rewards) for:
- Learn to perform without hints (self-distillation)
- After hints boost performance, the model learns from its own best “hinted” answers, so it can repeat that success on raw videos later—no hints needed.
- Think of practicing with training wheels and then practicing the same route without them.
- Keep inference simple
- At test time, there’s no circling, cropping, or extra tools. The model answers with a single pass on the original video.
A few technical terms explained:
- Reinforcement learning (RL): Training by trial-and-reward—like a game where good moves earn points.
- Visual prompts: Tiny visual edits (circles, darken, labels) that guide attention, like sticky notes on a page.
- Self-distillation: Learning from your own best, guided solutions to perform just as well without guidance.
- IoU (Intersection-over-Union): A measure of how much two regions overlap; higher is better alignment.
What the researchers found (main results)
Across several tough benchmarks, VisionCoach:
- Achieved state-of-the-art results on a spatio-temporal reasoning benchmark (V-STAR), beating both well-known open-source models and even strong proprietary systems in key grounding metrics.
- Consistently improved performance on general video understanding tests (VideoMME, WorldSense, VideoMMMU, PerceptionTest), especially in categories that require precise perception.
- Matched or slightly improved zero-shot temporal grounding on Charades-STA compared to specialized systems.
- Did all this without needing extra tools at test time, keeping inference fast and simple.
Why this matters:
- Better grounding means fewer “hallucinations” (made-up explanations) and more trustworthy answers, with evidence tied to specific frames and objects.
- Because hints are only used during training, the model stays efficient when actually used.
Why this is important and what it could change
- More reliable video assistants: Systems can give answers and also show you where they looked, making them easier to trust.
- Lower costs at deployment: No need for extra tool-calls or heavy processing during inference.
- A training recipe you can reuse: The idea of “guided practice + learn to go without” can be applied to other tasks where models must connect explanations to evidence (like medical videos, sports analysis, or surveillance).
In short, VisionCoach shows that giving a model the right kind of help while it learns—then teaching it to do the same without help—can produce accurate, well-grounded video reasoning that stays fast and simple in real use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored, organized to guide follow-on research and targeted ablations.
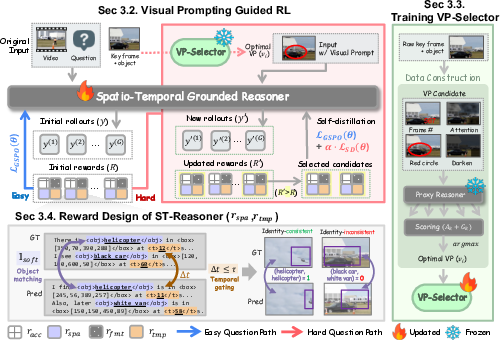
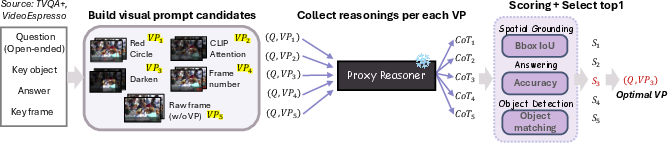
- Prompt generation mechanics are under-specified: the paper applies prompts to “key frames and objects,” but does not detail how key frames and object regions are derived without external tools. Clarify whether detectors/trackers/attention maps or GT annotations are used during training-time prompting, and evaluate alternatives that are tool-free versus tool-assisted.
- Limited prompt vocabulary: only a small set of hand-crafted prompts (red circles, darkening, frame numbering, “attention-based” overlays) is explored. Systematically expand and compare prompt types (e.g., masks, arrows, scribbles, contrast/blur modulation, per-object tags, saliency contours), and quantify gains per type across tasks/domains.
- Coarse prompt selection granularity: VP-Selector chooses a prompt type but not where/when/how strongly to apply it. Study fine-grained policies that also select spatial regions, temporal spans, intensity/opacity, and per-object targeting, potentially as a structured action space.
- Non-differentiable prompt policy: VP-Selector is trained via SFT using offline labels. Investigate joint training with the reasoner (e.g., RL for the selector, bi-level optimization, or GFlowNets) so prompt selection directly maximizes downstream grounding/answer rewards.
- Reliance on proxy reasoners for labeling VP-Selector data: prompt labels are obtained with GPT-4o/Gemini/Qwen. Assess (i) bias transfer from proprietary teachers, (ii) robustness when teachers disagree, (iii) agreement with the final ST-Reasoner, and (iv) performance when only open-source teachers are used.
- Domain coverage of VP-Selector training: VP-Selector is trained on TVQA+ and VideoEspresso. Test generalization across broader distributions (egocentric/wearable, sports, surveillance, animation, synthetic scenes) and investigate domain-adaptive or continual prompt-selection training.
- Hard-sample detection via a static reward threshold: the threshold k is fixed (e.g., median). Explore adaptive thresholds that account for non-stationary reward distributions during RL, uncertainty-aware selection (e.g., variance across rollouts), or curriculum schedules.
- Self-distillation from prompted to raw inputs: current distillation minimizes NLL on prompted trajectories only. Evaluate distilling paired prompted/unprompted trajectories, bidirectional consistency, and teacher-forcing on unprompted inputs to reduce train–test distribution shift.
- Textual hint leakage: training appends hint(v_i) while inference omits hints. Quantify the contribution of textual hints vs visual prompting and test ablating hints during training to ensure behavior truly transfers without auxiliary text cues.
- Reward design gaps for spatial grounding: object identity consistency uses string heuristics (exact/substring match). Replace with semantically grounded identity matching (e.g., CLIP/OWL-ViT embeddings, synonym/alias resolution, coreference) and test robustness to synonyms, pluralities, and attributes.
- Limited set-based and tracking-aware supervision: spatial reward averages per-box IoU and gates temporally but does not enforce cross-frame identity persistence, ordering, or smooth trajectories. Add multi-object set matching (Hungarian assignment), track-level consistency, motion smoothness, and occlusion handling.
- Temporal reward limitations: matching to the nearest GT time with Gaussian decay does not model durations, event ordering, or multi-interval dependencies. Introduce interval-level IoU, sequence constraints, causal ordering rewards, and penalties for repeated/overlapping spurious timestamps.
- Ground-truth dependence for RL rewards: the approach requires GT answers/boxes/timestamps. Explore weakly supervised/self-supervised reward signals (e.g., cycle-consistency, caption-QA agreement, retrieval consistency), human preference signals, or verifier models to reduce annotation dependence.
- Scalability and training cost: VP-guided RL doubles rollouts on hard samples and requires proxy-reasoner labeling for VP-Selector. Report and compare training compute/memory/energy vs baselines, and study compute–performance trade-offs (e.g., fewer rollouts, early stopping for easy samples).
- Long-video constraints and frame sampling: the paper claims efficient single-pass inference but does not analyze sensitivity to frame rate, max frames, shot changes, or extremely long videos. Provide scaling laws with video length, and compare sampling/segmenting policies.
- Multi-modal omissions: many real-world video reasoning tasks require audio; prompts and rewards are purely visual. Examine audio-aware prompting (e.g., transcribed cues, audio-synchronized overlays) and audio-visual grounding rewards.
- Robustness and stress testing: evaluate under occlusion, fast motion, camera shake, compression artifacts, lighting changes, clutter, adversarial edits, and irrelevant distractor overlays to ensure the model does not overfit to prompt-like visual patterns.
- Out-of-distribution and open-world objects: assess grounding when queried objects are unseen, fine-grained, or ambiguous; measure how string-based identity matching and the reward behave with novel labels and zero-shot categories.
- Safety and reward gaming: ensure the model cannot inflate rewards by outputting plausible boxes/timestamps without visual support or by exploiting format rules. Add verifiers/critics and measure hallucination under contradictory prompts or misleading textual hints.
- Comparison breadth and fairness: results are on a 7B backbone with specific datasets. Provide scaling experiments (3B–70B), cross-backbone transfer, and standardized training budgets to isolate method gains from model size/data.
- Hyperparameter sensitivity and reproducibility: report sensitivity to α (distillation weight), σ/τ (temporal reward), reward coefficients, rollout count G, and random seeds; release VP-Selector training data and prompt rendering code to facilitate replication.
- VP-Selector plug-and-play evaluation is narrow: beyond TVQA+ and PerceptionTest, test more datasets and tasks (e.g., activity recognition, dense captioning, tracking, procedural reasoning), and quantify failure modes where VP-Selector harms performance.
- Granular attribution of gains: disentangle contributions of visual prompting, self-distillation, and the new spatial reward via controlled ablations on more datasets and tasks; report per-category gains (e.g., motion vs appearance vs interaction questions).
- Prompt rendering artifacts: study whether color/shape/style of overlays bias the model or hinder generalization; evaluate alternative render styles, colorblind-safe schemes, and less intrusive cues to minimize distribution shift.
- Multi-lingual generalization: assess VP-Selector and ST-Reasoner on multilingual video QA and grounding; investigate cross-lingual prompt selection and identity matching beyond English.
- Integration with differentiable attention control: compare input-level prompting to learned feature-space attention steering or spatial-temporal routers, and explore hybrid methods that learn when to use visual prompts vs internal attention reweighting.
- Extension to segmentation- or keypoint-level grounding: bounding-box IoU may be too coarse for fine-grained actions/poses. Add mask- or keypoint-based rewards and evaluate on datasets with dense annotations.
- Ethical/data provenance considerations: the use of proprietary models for labeling VP-Selector may embed opaque biases. Audit fairness across demographic attributes and scenes; provide an option to train VP-Selector solely with open-source teachers.
Practical Applications
Immediate Applications
Below is a concise set of real-world use cases that can be deployed now, drawing on VisionCoach’s training-time visual prompting, self-distillation, and grounded reward design. Each bullet indicates the sector, the application, potential tools/products/workflows, and key assumptions/dependencies.
- Healthcare — surgical video review and training analytics
- Tools/Workflows: offline analysis pipelines that process surgical recordings to identify critical moments (temporal intervals) and instrument/tissue interactions (bounding boxes), auto-generate grounded rationales for teaching or QA review
- Assumptions/Dependencies: domain fine-tuning on medical video, privacy/IRB compliance, clinical validation and regulatory approvals for decision-support use
- Sports analytics — play detection, highlight generation, and officiating support
- Tools/Workflows: single-pass inference services that tag key events (goals, fouls) with timestamps and localized regions; dashboards for analysts showing grounded evidence
- Assumptions/Dependencies: domain-specific tuning (team/league datasets), reliable object identity mapping (players, ball), multi-camera calibration optional for broader coverage
- Retail and security — real-time incident monitoring from CCTV
- Tools/Workflows: lightweight, tool-free inference on edge/NVR hardware to flag unusual events, track suspect items with object-aware boxes, generate explainable incident reports with time-stamped frames
- Assumptions/Dependencies: deployment hardware capacity (GPU/accelerator), privacy and compliance policies, lighting and camera quality, site-specific fine-tuning to reduce false positives
- Media and entertainment — automatic chaptering and content editing assistance
- Tools/Workflows: post-production tools that extract grounded timelines and frame-level regions for scene detection; “explain with evidence” captions aligned to video segments
- Assumptions/Dependencies: alignment to editing workflows (e.g., Premiere/Resolve integrations), domain adaptation for cinematic content, acceptable latency at scale
- Education — video tutoring and lab demonstration Q&A
- Tools/Workflows: interactive assistants that answer questions about recorded experiments/lectures and cite time ranges and spatial regions; grading assistance for lab submissions (grounded rubrics)
- Assumptions/Dependencies: curriculum/domain fine-tuning, bias and fairness checks, appropriate student privacy data governance
- Robotics (industrial) — grounded video reasoning for task monitoring and diagnostics
- Tools/Workflows: on-robot or near-edge modules that track tools/parts over time, surface grounded rationales for error states (misplaced component, occlusion), support human-in-the-loop debugging
- Assumptions/Dependencies: real-time constraints and hardware compatibility, integration with robot stack (ROS/PLC systems), controlled environments with predictable visuals
- Transportation/insurance — post-hoc crash analysis from dashcam footage
- Tools/Workflows: claims systems that automatically extract temporal segments and spatial evidence (objects, maneuvers), generate explainable narratives referencing frames
- Assumptions/Dependencies: domain-specific tuning for driving scenes, reliability and auditability requirements, legal admissibility considerations
- Smart home and consumer apps — camera summaries and event highlights
- Tools/Workflows: privacy-conscious on-device or home-hub inference that summarizes baby/pet activity and alerts with grounded evidence (time stamps and bounding boxes)
- Assumptions/Dependencies: on-device optimization and data minimization, variability of home lighting and camera angles, user controls for privacy
- Software/AI tooling — VP-Selector as a plug-and-play training module for VideoLLMs
- Tools/Workflows: integrate VisionCoach’s VP-Selector and rewards into existing RL/SFT pipelines to cheaply improve grounding without inference-time tool-calling; release “VisionCoach Trainer” SDK
- Assumptions/Dependencies: access to RL infrastructure (GSPO or similar), GPUs, proxy reasoners or curated prompt-choice heuristics, availability of spatio-temporal labels or weak signals for rewards
- Academia — benchmarking and analysis of grounded reasoning
- Tools/Workflows: use VisionCoach-7B and code to reproduce SoTA baselines, run ablations on reward design and self-distillation, extend to new datasets (e.g., science or egocentric videos)
- Assumptions/Dependencies: dataset licensing and annotations for temporal/spatial GT, compute resources; reproducibility of VP-Selector training (TVQA+/VideoEspresso baseline)
Long-Term Applications
The following use cases require further research, scaling, productization, or regulatory maturation before broad deployment.
- Autonomous driving (real-time onboard grounded reasoning)
- Tools/Workflows: integrate VisionCoach-like grounded reasoning into perception stacks to produce explainable decisions (time/region evidence) during driving
- Assumptions/Dependencies: hard real-time guarantees, robustness under extreme conditions (weather, occlusion), safety certification; optimized models for automotive-grade hardware
- Multi-camera/multi-sensor facility understanding
- Tools/Workflows: fuse streams from diverse cameras, LiDAR, and IoT signals to track identities across views and time with consistent grounded rationales
- Assumptions/Dependencies: multi-view identity linking, synchronization, scalability, privacy-preserving multi-sensor fusion
- Edge deployment at scale (low-power devices)
- Tools/Workflows: compression/distillation pipelines to run VisionCoach-like models on embedded accelerators (Jetson, NPUs) with maintained grounding quality
- Assumptions/Dependencies: model optimization (quantization, pruning), memory/compute constraints, robust performance under limited bandwidth
- Professional video editing assistants with grounded timelines
- Tools/Workflows: deep integration into NLEs (Adobe, Blackmagic), auto-generate structured timelines, evidence-backed captions, and object-region overlays for editorial decisions
- Assumptions/Dependencies: UX design for editors, domain-specific fine-tuning on cinematic content, rights and licensing for content analysis
- Embodied agents and household robots
- Tools/Workflows: couple grounded video reasoning with action planning to improve task monitoring, failure recovery, and explainable autonomy
- Assumptions/Dependencies: closed-loop control integration, robust perception amidst motion blur/hand occlusions, safety and reliability testing
- Medical decision support (real-time intraoperative assistance)
- Tools/Workflows: assist surgeons with grounded prompts during procedures (instrument detection, phase recognition, complication alerts)
- Assumptions/Dependencies: extremely high accuracy and reliability, clinical trials, regulatory clearance; robust handling of rare events and domain shifts
- Emergency response and public safety (drone/bodycam analysis)
- Tools/Workflows: triage systems that produce time-stamped, region-grounded situational awareness across dynamic scenes (crowds, hazards)
- Assumptions/Dependencies: adversarial conditions (smoke, low light), bias and civil liberties auditing, cross-agency data-sharing policies
- Compliance and audit standards for “grounded AI” video analytics
- Tools/Workflows: develop policy frameworks and standardized metrics (e.g., mAM/mLGM-style) to certify explainability and evidence quality in automated video reports
- Assumptions/Dependencies: stakeholder consensus (industry, regulators, civil society), transparent benchmarking, governance around error modes and appeals
- Active-learning and annotation reduction pipelines
- Tools/Workflows: leverage VP-guided RL to generate high-confidence, grounded pseudo-labels for hard examples, reducing annotation cost; human-in-the-loop corrections
- Assumptions/Dependencies: reliable reward signals without dense labels, uncertainty estimation, scalable data ops
- Finance/trading floor and compliance monitoring
- Tools/Workflows: analyze surveillance streams to ensure rules adherence (restricted zones, device usage), produce grounded incident evidence for audits
- Assumptions/Dependencies: strict privacy/security, domain adaptation for indoor scenes, policy and labor implications
- Educational assessment at scale (grounded evaluation of student lab videos)
- Tools/Workflows: auto-extract time-aligned evidence for rubric-based grading; support formative feedback with visual references
- Assumptions/Dependencies: fairness and bias evaluations, consent and data protections, institutional procurement and integration
Cross-cutting assumptions and dependencies to consider
- Data and rewards: grounded RL depends on availability or construction of temporal/spatial supervision signals; reward design quality and domain fit matter significantly.
- Generalization: VP-Selector trained on TVQA+/VideoEspresso may need re-training/tuning for specialized domains (medical, industrial, egocentric).
- Compute: RL training and self-distillation require GPUs; deployment benefits from VisionCoach’s single-pass, tool-free inference but still needs hardware sizing.
- Identity matching: object-aware rewards assume reliable object naming and mapping; ontology alignment may be needed in domain-specific deployments.
- Ethics and governance: privacy, consent, and auditability are crucial, particularly for surveillance, healthcare, and public safety; standardized reporting of failure cases and uncertainty is advisable.
- Robustness: performance may degrade under adverse conditions (low light, motion blur, occlusion); additional data augmentation and domain adaptation are recommended.
Glossary
- bounding-box IoU: A measure of overlap between predicted and ground-truth boxes used to assess spatial localization quality. "multi-region bounding-box IoU"
- cold-start initialization: An initial training setup where the model starts from a minimally trained or untrained state before further optimization. "starting from a cold-start initialization"
- GSPO: A reinforcement learning optimization objective; here, the policy is trained with group-based updates derived from sampled trajectories. "The ST-Reasoner is optimized using GSPO"
- grounding-aware rewards: Reward signals that explicitly evaluate and encourage correct spatial and temporal grounding during RL training. "optimized with RL using grounding-aware rewards."
- hallucinated bounding boxes: Incorrect or fabricated box predictions not supported by visual evidence, which can mislead reasoning. "hallucinated bounding boxes that propagate errors during reasoning."
- hard samples: Inputs identified as difficult based on low initial rewards and targeted for additional guidance during training. "hard samples are identified based on initial rewards"
- knowledge distillation: A training technique that transfers behavior from a stronger teacher model to a student model. "Knowledge distillation transfers behavior from a stronger teacher to a student model"
- language priors: Statistical regularities in language that can bias models to produce plausible-sounding but visually unsupported explanations. "hallucinated explanations driven by language priors"
- LoRA: Low-Rank Adaptation; a parameter-efficient finetuning method that injects small trainable rank-decomposed matrices into transformer weights. "with LoRA~\citep{hu2022lora}"
- mAM: A reported aggregate metric on V-STAR summarizing performance (exact expansion not specified in the paper). "improves over Qwen2.5-VL-7B by +15.0\% mAM and +25.1\% mLGM"
- mLGM: A reported aggregate grounding metric on V-STAR (exact expansion not specified in the paper). "improves over Qwen2.5-VL-7B by +15.0\% mAM and +25.1\% mLGM"
- MLLMs: Multimodal LLMs that process and reason over multiple modalities, such as video and text. "general vision understanding in MLLMs~\citep{vipllava, vincontext,choudhury2024video,gu2025thinking}"
- negative log-likelihood (NLL): A token-level loss that maximizes the likelihood of desired sequences, used here for self-distillation. "We then apply token-level negative log-likelihood (NLL) to the selected reasoning"
- object identity consistency: A constraint that encourages the same object identity to be referenced consistently across time and predictions. "object identity consistency and multi-region bounding-box overlap."
- object-aware spatial grounding reward: A reward component that incorporates object identity matching and multiple box IoUs to improve spatial grounding. "we introduce an object-aware spatial grounding reward"
- oracle prompt selection: The hypothetical best-choice prompt for each input that yields the highest performance, used for analysis. "Notably, the oracle prompt selection achieves significantly higher accuracy"
- plug-and-play module: A component that can be integrated with different backbones without architectural changes to provide additional functionality. "VP-Selector functions as a plug-and-play module for enhancing grounded visual reasoning."
- policy model: The decision-making model in RL that maps inputs to actions (here, reasoning tokens), denoted as πθ. "our reasoning requires a policy model "
- proxy reasoners: External models used to approximate or evaluate the effectiveness of candidate prompts during data construction. "using multiple proxy reasoners to capture general prompt effectiveness patterns."
- rollouts: Sampled trajectories from the policy used to compute rewards and update the model in RL. "we first perform initial rollouts"
- ROI localization: Region-of-interest localization; the process of identifying relevant image regions for further processing. "progressive ROI localization"
- self-distillation: A training approach where the model learns from its own high-reward trajectories to internalize improved behaviors. "we employ self-distillation, where the prompted input serves as a coach"
- soft identity matching: A lenient matching rule that deems predicted and ground-truth object names consistent if they exactly match or one is a substring of the other. "Using soft identity matching $\mathbb{I}_{\text{soft}(o_m,o)$"
- spatio-temporal attention map: A visualization of attention weights across frames and regions showing where and when the model focuses. "Spatio-temporal attention map."
- spatio-temporal grounding: The alignment of intermediate reasoning to the correct spatial regions and time segments in a video. "reliable spatio-temporal grounding throughout the reasoning process."
- Spatio-Temporal Reasoner: The core video reasoning model that integrates grounding and answer generation under RL. "Spatio-Temporal Reasoner, optimized with RL under visual prompt guidance and object-aware grounding rewards"
- Supervised Fine-Tuning (SFT): Training with labeled data to adapt a model before RL or other optimization stages. "optimized with SFT to select the most effective visual prompt type."
- temporal clipping: Preprocessing that trims videos to time spans likely containing relevant evidence. "external perception tools such as temporal clipping or zoom-in."
- temporal gating: A mechanism that only evaluates or rewards spatial predictions when temporal alignment is sufficiently accurate. "we apply temporal gating based on the deviation "
- temporal grounding: The task of localizing when relevant events occur within a video. "temporal grounding benchmark (Charades-STA)"
- temporal IoU: Intersection-over-Union computed over time intervals to assess temporal localization accuracy. "When (Temporal IoU)"
- temporal localization: Pinpointing the correct time segments that contain evidence relevant to a query. "promotes more accurate temporal localization"
- text-centric: A modeling approach that relies heavily on linguistic patterns instead of grounded visual evidence. "Text-centric video reasoning models"
- tool-calling: Invoking external perception tools during inference to aid grounding, often incurring additional latency. "Visual tool-calling approaches"
- verifiable rewards: RL rewards that can be checked against objective criteria (e.g., correctness, IoU) rather than subjective judgments. "reinforcement learning (RL) with verifiable rewards"
- VideoLLMs: Video-focused LLMs designed for video understanding and reasoning tasks. "prior open-source VideoLLMs"
- VLM: Vision-LLM; a model jointly processing visual and textual inputs. "train the VP-Selector as a lightweight VLM classifier"
- Visual Prompt Selector: A component that predicts the most suitable visual prompt type for each video–question input. "Visual Prompt Selector, which predicts appropriate prompt types conditioned on the video and question"
- visual prompting: Adding visual cues (e.g., circles, darkening, numbering) to inputs to steer a model’s attention toward relevant content. "Visual prompting~\citep{wu2024visual} augments inputs with lightweight visual cues"
- zero-shot: Evaluation without task-specific finetuning, testing generalization to unseen data. "We evaluate the zero-shot performance"
Collections
Sign up for free to add this paper to one or more collections.