- The paper presents an innovative agentic pipeline that constructs 1.8M high-quality, knowledge-rich VQ-VA pairs from web-scale data.
- It demonstrates significant performance improvements on the IntelligentBench benchmark with LightFusion-World, boosting scores from 7.78 to 53.06.
- The study shows that open-source multimodal models can rival proprietary systems through specialized data curation and robust evaluation frameworks.
VQ-VA World: Closing the Visual Question-Visual Answering Gap for Open Models
Motivation and Problem Setting
The work defines and operationalizes Visual Question-Visual Answering (VQ-VA), where the task is to generate an image (not text) in response to a semantically rich visual question. This capability, emergent in proprietary systems such as GPT-Image and NanoBanana, has remained elusive for open-weight and open-source models, largely because open datasets focus on standard pixel-level editing rather than free-form reasoning or world knowledge-conditioned generation.
Discrepancies between commercial and open models are both qualitative and quantitative. For example, when queried on counterfactual or compositional visual scenarios, leading closed-source models synthesize contextually apt imagery, whereas open models typically fail to exhibit coherent transformations in answer to visually grounded questions.
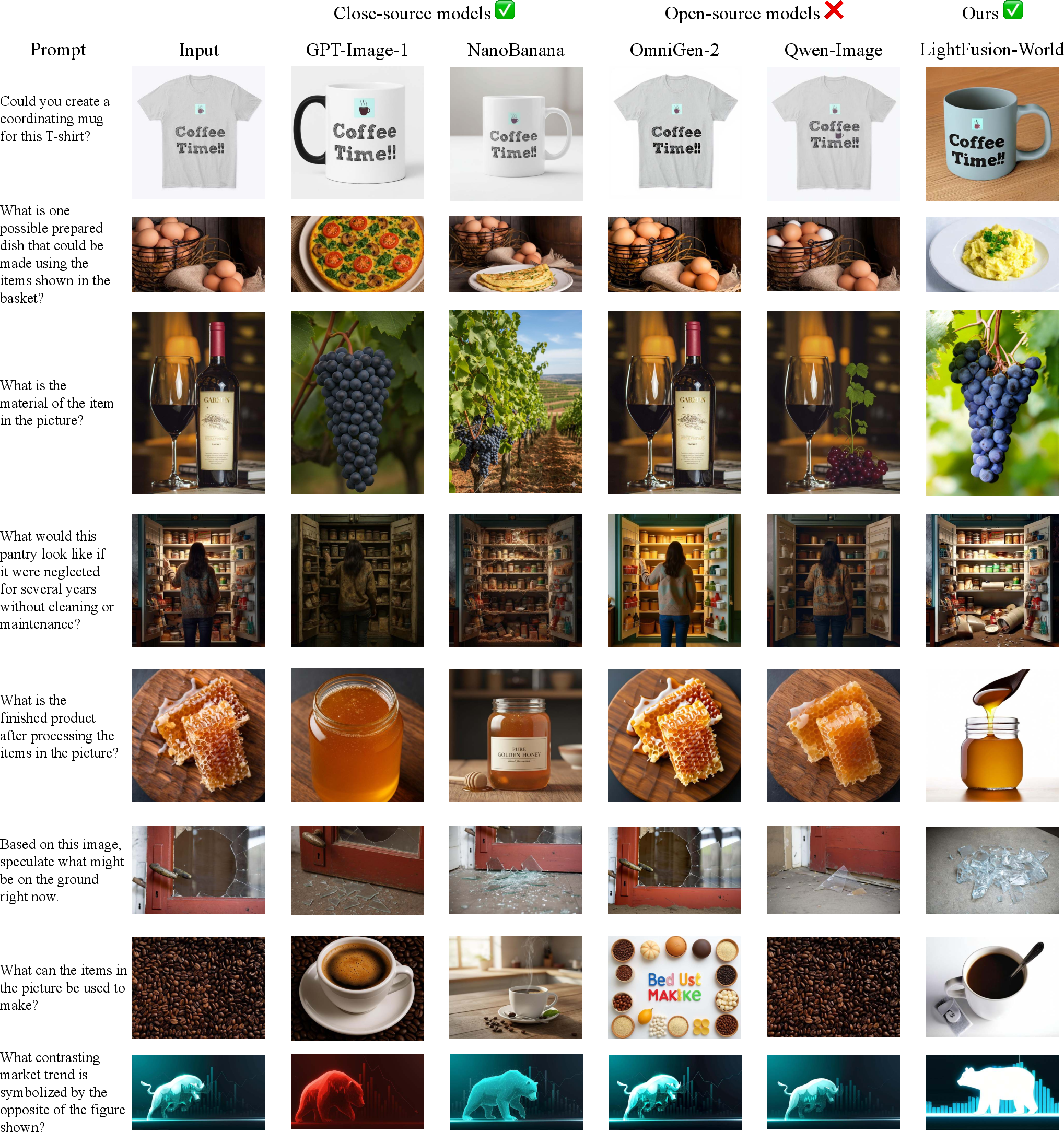
Figure 1: Representative VQ-VA tasks highlighting the large performance gap between open-weight and proprietary models, and the significant boost from training with the VQ-VA World dataset.
VQ-VA World Data-Centric Framework
The VQ-VA World framework is architected as an agentic, modular pipeline for constructing large-scale, knowledge- and reasoning-centric visual question–visual answer data. The process comprises:
- Preprocessing: Large-scale web-interleaved documents are classified with a hybrid LLM–FastText protocol, retaining only those suitable for knowledge/design centric transformations.
- Agentic Pipeline: Sequential specialized agents extract (1) candidate image pairs with semantically non-trivial, knowledge-grounded relationships, (2) instruction generation for producing free-form VQ-VA questions, (3) automated filtering using a strict multi-criteria VLM-based triage, (4) generation of diverse linguistic paraphrases, and (5) chain-of-thought reasoning traces to supervise instruction-following and transformation logic.
Web-scale deployment yields approximately 1.8M high-curation-quality VQ-VA instances—orders of magnitude larger and more conceptually diverse than existing open I2I datasets.
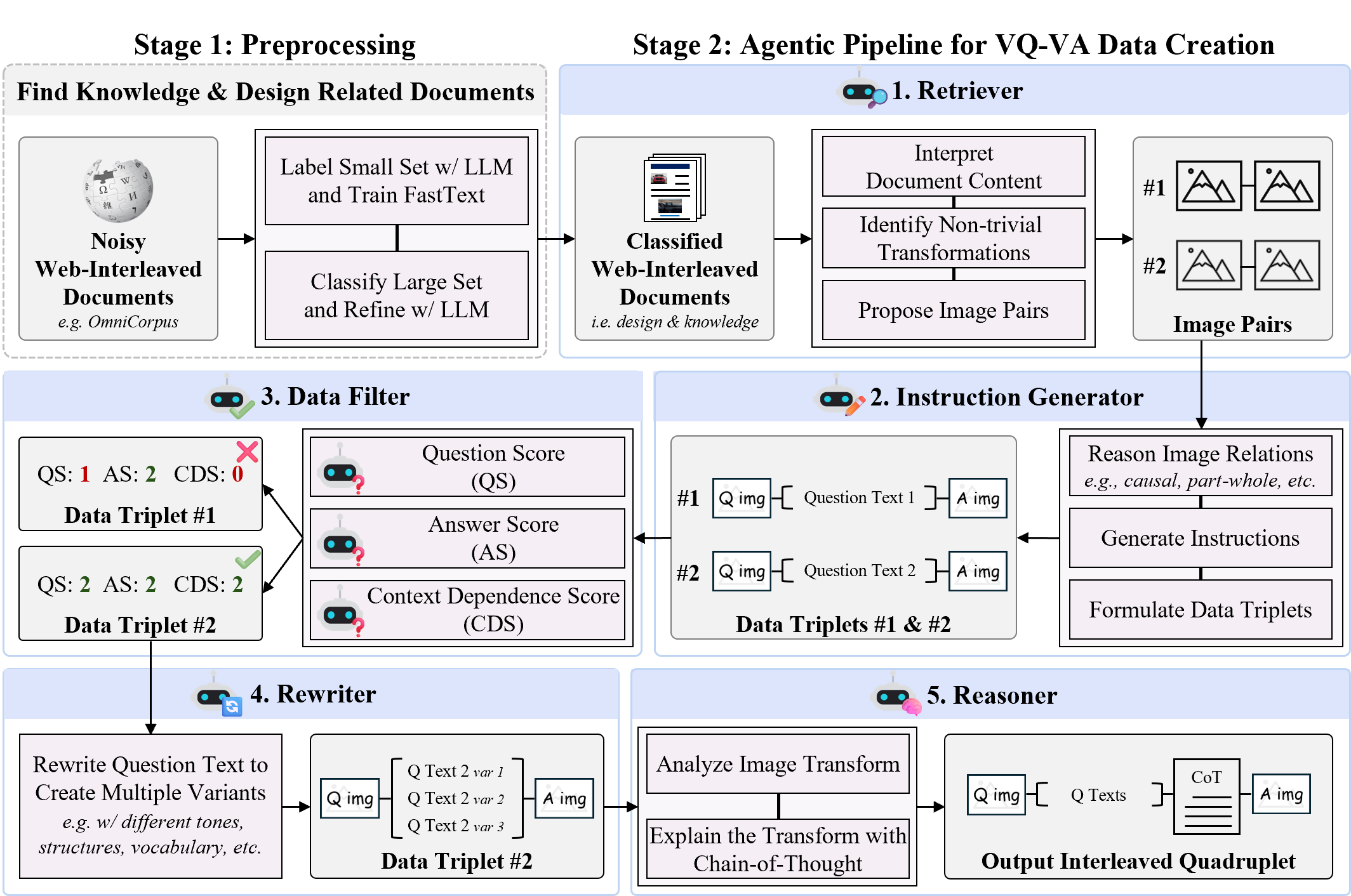
Figure 2: The VQ-VA World data construction pipeline, highlighting preprocessing and the agentic five-module pipeline for knowledge-rich data creation.
Benchmarking: IntelligentBench
To rigorously evaluate models’ grounded VQ-VA capabilities, IntelligentBench is released— a human-curated benchmark explicitly divided into world knowledge, design knowledge, and reasoning modalities. Each item probes multi-step, non-trivial semantic reasoning through carefully designed image-question-answer triplets.

Figure 3: Categorization and representative samples from IntelligentBench: world knowledge, design knowledge, and reasoning.
Automatic model evaluation relies on advanced VLMs (e.g., GPT-4o, Gemini-2.5-Flash), with validation demonstrating high alignment with expert human judgment on both categorical accuracy and rank correlation.
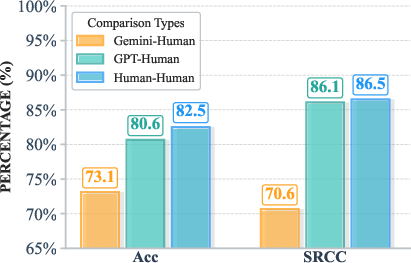
Figure 4: Correlation and agreement between VLM and human expert ratings, validating the reliability of automatic evaluation metrics.
Experimental Results
Fine-tuning a fully open unified multimodal model, LightFusion, on the VQ-VA World dataset results in a dramatic improvement on IntelligentBench (from 7.78 to 53.06), with a substantial reduction in the gap to closed-source leaders (GPT-Image, NanoBanana at ≈82) and a clear advantage over all open-weight competitors.
The improvement is robust across multiple dimensions:
- World Knowledge, Design Knowledge, Reasoning: All categories exhibit significant gains, underlining the necessity of knowledge-centric, free-form I2I data for generalized VQ-VA competence.
- Generalization: Notable performance transfer is observed to other reasoning-based image editing tasks (RISEBench, KRIS-Bench), and quality improvements are also witnessed on classical pixel-level editing, albeit with smaller margins.
- Data and Model Efficiency: LightFusion-World outperforms or matches large, private-data pre-trained open-weight models (e.g., Qwen-Image, FLUX.1-Kontext-Dev) while using fully open data, confirming the competitive utility and extensibility of the proposed pipeline.
Comprehensive visualizations highlight systematic performance trajectories and error breakdowns across all subdomains and benchmark subsets.
Figure 5: Visualization of model performance profiles on IntelligentBench (Design knowledge subset, representative segment).
Implications and Prospects
The success of VQ-VA World has dual implications:
- Practical: The availability of 1.8M+ high-quality VQ-VA pairs, with open weights and code, makes high-fidelity, knowledge-centric generative visual QA attainable for the open-source ecosystem. This democratizes the development of capable multimodal systems that were previously limited to resource-rich proprietary entities.
- Theoretical: Analysis of errors and transfer highlights the critical dependence of VQ-VA capabilities on semantically targeted, context-rich supervision as opposed to pure scale or model complexity.
- Evaluation and Future Directions: The introduction of robust benchmarks such as IntelligentBench enables systematic measurement and rapid iteration. The agentic and scalable data pipeline design incentivizes further extension to video, 3D, temporal, and more complex visual reasoning tasks, as well as supervised alignment strategies tailored for VQ-VA.
Conclusion
VQ-VA World sets a new standard for open research in multimodal generative reasoning, substantially reducing the capability gap between open and proprietary models in visual question–visual answering. The open release of training data, agentic pipelines, model checkpoints, and evaluation resources is positioned to drive the next phase of large-scale, knowledge-intensive visual generative AI (2511.20573).

