No Labels, No Problem: Training Visual Reasoners with Multimodal Verifiers
Abstract: Visual reasoning is challenging, requiring both precise object grounding and understanding complex spatial relationships. Existing methods fall into two camps: language-only chain-of-thought approaches, which demand large-scale (image, query, answer) supervision, and program-synthesis approaches which use pre-trained models and avoid training, but suffer from flawed logic and erroneous grounding. We propose an annotation-free training framework that improves both reasoning and grounding. Our framework uses AI-powered verifiers: an LLM verifier refines LLM reasoning via reinforcement learning, while a VLM verifier strengthens visual grounding through automated hard-negative mining, eliminating the need for ground truth labels. This design combines the strengths of modern AI systems: advanced language-only reasoning models for decomposing spatial queries into simpler subtasks, and strong vision specialist models improved via performant VLM critics. We evaluate our approach across diverse spatial reasoning tasks, and show that our method improves visual reasoning and surpasses open-source and proprietary models, while with our improved visual grounding model we further outperform recent text-only visual reasoning methods. Project webpage: https://glab-caltech.github.io/valor/









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
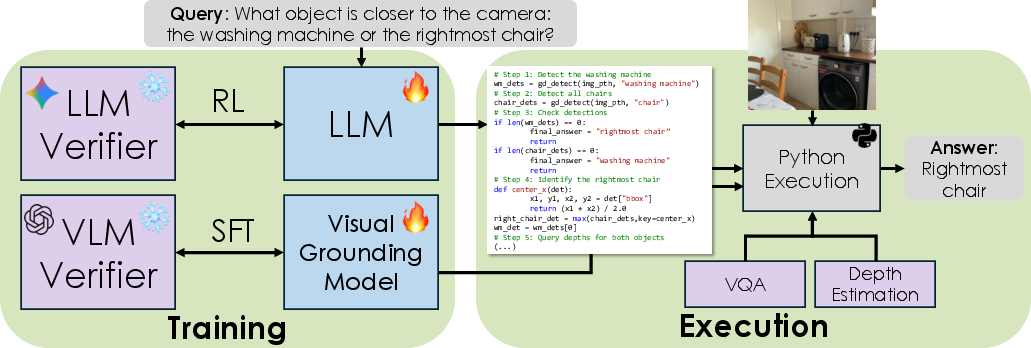
This paper is about teaching AI to “think with pictures.” The authors want computers to look at an image, find the right objects, understand where those objects are, how big they are, and how they relate to each other (in 2D and 3D), then answer tricky questions about the scene. Their main idea is to train this skill without needing humans to label tons of data. They do this using smart “verifiers” that act like referees: they check the AI’s reasoning and vision steps and give feedback so the AI can improve. They call their approach VALOR, short for Verifiers for Annotation-free Logic and Reasoning.
What questions did the researchers ask?
The paper focuses on simple versions of three big questions:
- Can an AI learn to break down visual questions into clear steps and use the right tools, without being told the correct answers?
- Can we improve how well the AI finds objects in images (visual grounding) without expensive human-made labels?
- Does this label-free method beat existing systems on tasks like counting objects, understanding spatial relations (like “left of” or “behind”), and estimating 3D size from 2D pictures?
How did they do it? Methods explained simply
Think of the system as a student using a toolbox, with two coaches (verifiers) giving feedback.
- The “student” is a LLM that writes a plan and a short Python program to solve each question. The program calls three image tools:
- An object finder (detects things like “car” or “helmet”).
- A depth estimator (how far a pixel is from the camera—helps turn 2D size into 3D size).
- A small visual Q&A tool (answers questions about a cropped object, like “What color is this?”).
- The “coaches” are verifiers:
- An LLM verifier checks the student’s plan and code. It rewards the student for:
- Using the right format (plan and answer sections),
- Writing code that runs (no errors),
- Sound logic (reasonable steps for the question),
- Correct attributes (like using height vs. width when needed),
- Handling spatial relations (like “above,” “behind,” or “closer”),
- Keeping the code faithful to the plan.
- This feedback is used for reinforcement learning (RL), which means the student gets better by trying ideas, getting a score, and adjusting to get higher scores next time.
- A VLM verifier helps fix visual grounding. Here’s the trick:
- The object finder is set to be extra sensitive, so it “over-detects” lots of boxes (including wrong ones).
- The VLM verifier then filters these detections in three steps:
- 1) Coarse check on the full image with boxes,
- 2) Detailed check on each cropped box,
- 3) De-duplication to remove repeats.
- The verified boxes become “pseudo-labels” (fake labels made by AI) used to fine-tune the object finder—no humans needed.
- Where does the training data come from?
- They take unlabeled images and automatically generate natural questions (like “How many animals are sitting in the beige car?”).
- They also include images from a 3D dataset (without answers).
- The LLM write-plan + code is trained using verifier feedback instead of ground-truth answers, and the detector is fine-tuned using VLM-verified boxes.
What did they find and why it matters?
The authors tested VALOR on many benchmarks that require spatial thinking: 2D relations, 3D understanding, counting, and real-world Q&A.
Key findings:
- Better reasoning without labels:
- Using the LLM verifier and RL, the AI learned to make clearer plans, call the right tools, and use depth correctly (for 3D size), beating strong open-source LLMs that relied on prompting alone.
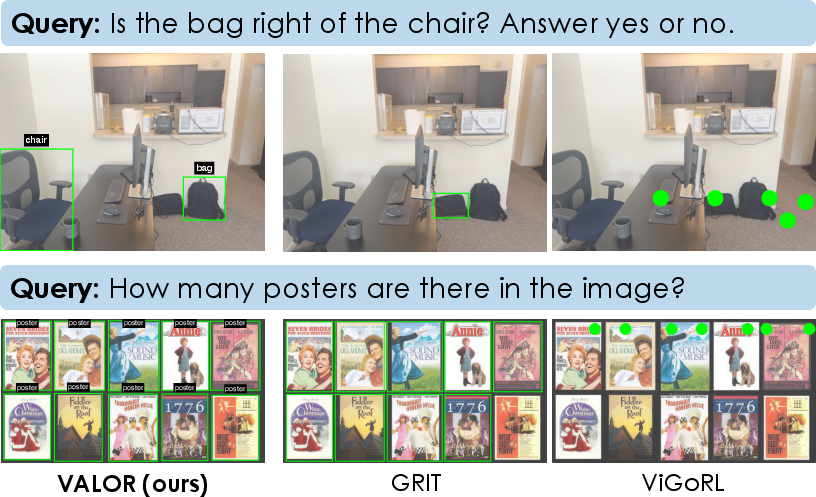
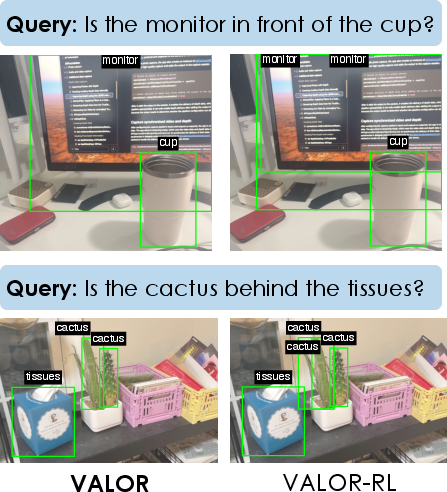
- Better visual grounding without labels:
- The VLM verification pipeline produced useful pseudo-labels, improving the object finder across diverse images. This led to big gains on tasks that require accurate detection and localization.
- Competitive with bigger models:
- Even though VALOR uses smaller open-source models, it matched or beat several larger proprietary systems on complex visual reasoning (especially 3D tasks), showing that smart training beats just scaling model size.
- Scales with more data:
- The more unlabeled image–question pairs they used, the better the results—for both reasoning and grounding—suggesting the method will keep improving as you add data.
- RL beats simple imitation:
- Training with RL (using verifier scores) worked better than supervised fine-tuning on high-quality traces, especially for tough reasoning tasks.
Why this matters:
- Labeling image data is expensive and slow. VALOR shows you can teach deep visual reasoning with almost no human labels by using verifiers as automated critics.
- It combines language reasoning (plans and logic) with tool use (detect, depth, VQA), which is more reliable than text-only guessing.
What could this mean in the real world?
- Robotics: Robots that can accurately judge where objects are, how big they are, and what they’re doing could plan safer and smarter actions in homes, warehouses, or hospitals.
- AR/VR and navigation: Better spatial understanding improves how apps place virtual objects in the real world and reason about visibility, size, and occlusion.
- Safety and accessibility: Systems that explain how they reached an answer (via plans and code) are more trustworthy and easier to debug.
- Lower costs: Since it avoids manual labeling, teams can build powerful visual reasoners faster and cheaper.
- Future directions: The authors suggest combining verifiers even more tightly with training, using stronger visual models as tools, and generating harder questions to push the AI’s skills further.
In short, this paper shows a practical path to teaching AI to “see and think” by using verifiers as coaches instead of relying on large piles of human-labeled data.
Knowledge Gaps
Below is a single, concrete list of gaps, limitations, and open questions the paper leaves unresolved. Each point is framed to be actionable for future researchers.
- Reliance on proprietary verifiers and tools: The approach depends on Gemini-2.5-Flash as the LLM verifier and GPT-5-mini for VQA; results with fully open-source verifiers/tools (e.g., Llama, Qwen-VL for verification and VQA) are not characterized. Evaluate portability, performance trade-offs, and reproducibility without proprietary services.
- Limited verifier reliability assessment: LLM verifier agreement is reported on only 100 samples (87% agreement, predominantly under-rewarding). Conduct larger-scale, category-stratified audits, analyze failure modes (false accepts/rejects), and quantify robustness to adversarial prompts and edge-case queries.
- Mis-specified “precision” for the VLM verification pipeline: The paper defines P = TP/(TP+FP+FN), which is not standard precision. Recompute standard precision, recall, and F1; report localization metrics (IoU distributions), stage-wise ROC curves, and calibration plots to characterize pseudo-label quality.
- Sparse evaluation of pseudo-labeling recall and coverage: Only final “precision” is reported; recall, missed detections, category coverage (long-tail, rare objects), and bounding box quality are not quantified. Measure category-wise recall, box quality (IoU), and confirm that pseudo-labels do not bias the detector toward frequent categories.
- Reward design sensitivity: The six binary reward heads (format, syntax, logic, attribute, spatial, adherence) and fixed weights are not ablated. Systematically study sensitivity to reward weights, replace binary heads with graded/continuous scores, add uncertainty-aware rewards, and guard against reward hacking.
- Verifier-induced bias and overfitting risks: The trained policy may exploit idiosyncrasies of the verifier prompts. Detect and mitigate reward hacking via adversarial verification sets, verifier ensembles, randomized prompt variants, and cross-verifier consistency checks.
- RL algorithm choice and stability: Only GRPO is evaluated. Compare against PPO/DPO variants, process-based RL, and implicit-reward methods; report stability (variance across seeds), sample efficiency, and convergence behavior. Analyze the impact of group size G, batch size, and learning rate on exploration and program diversity.
- Scaling beyond small reasoning datasets: The RL training uses only ~800 (image, query) pairs. Establish compute–data–accuracy scaling laws with 10×–100× more unlabeled samples; identify saturation points, data curation strategies, and domain transfer (e.g., robotics, indoor scenes) benefits or failures.
- Synthetic query generation quality: Queries are generated by Gemini for SA-1B images, but their realism, ambiguity rate, and alignment with target benchmarks are not audited. Build quality filters, controllable generation (e.g., difficulty, object categories), and “hard negative” query generation to drive reasoning improvements.
- Detector fine-tuning scope: GroundingDINO is fine-tuned with frozen encoders. Evaluate end-to-end fine-tuning (vision and language backbones), language grounding updates, and catastrophic forgetting risks on general detection (COCO, LVIS); report open-vocabulary retention and cross-domain robustness.
- Depth usage and 3D consistency: Programs rely on pointwise metric depth (MoGe2) without camera intrinsics or uncertainty modeling. Study sensitivity to depth errors, use region-level depth statistics, incorporate intrinsic/extrinsic calibration where available, and propagate uncertainty into downstream 3D reasoning and decisions.
- Limited toolset: Only detection, depth, and simple VQA are used. Assess the impact of adding segmentation, pose estimation, 3D bounding boxes, instance masks, optical flow (for video), and affordance detectors; perform tool ablations and automatic tool selection/ordering strategies.
- Program semantics validation: Syntax and plan–code adherence are checked, but the semantic correctness of intermediate computations (e.g., correct units, consistent coordinate frames) is not verified. Introduce semantic checkers, unit tests for subroutines, and invariants (e.g., size monotonicity with depth) to catch silent logic errors.
- Underperformance on counting vs direct VLMs: VALOR trails proprietary VLMs on CountBenchQA. Diagnose whether the bottleneck is detection recall, query parsing, or aggregation logic; test VLM-based grounding tools, hybrid detectors, or vote-based multi-tool aggregation to improve counting robustness.
- Fairness and leakage auditing: The grounding pseudo-label dataset includes images from spatial reasoning datasets; the paper does not confirm strict separation from evaluation splits. Audit data provenance, enforce de-duplication across train/test, and release split manifests to ensure clean evaluation.
- Cost and efficiency of verifier-driven training: RL training requires 8× A100 GPUs and extensive API calls to verifiers. Profile runtime and API costs, implement caching and batch verification, and explore learned/verifier-lite critics to reduce dependence on external calls.
- Robustness to distribution shift: Performance under occlusion, clutter, adverse lighting, and domain shifts (e.g., medical, satellite, egocentric robotics) is not measured. Build stress-test suites, measure calibration (ECE/Brier), and support abstention and fallback strategies when verifier confidence is low.
- Human-in-the-loop verification: The method is fully automatic. Assess whether small amounts of targeted human feedback (active learning on verifier disagreements or hard cases) can significantly improve grounding and reasoning with minimal annotation budget.
- Metrics beyond answer accuracy: The paper primarily reports exact-match/MRA. Add metrics for program quality (step-level correctness), tool invocation accuracy, grounding utilization, error taxonomy (logic vs execution vs grounding), and end-to-end trace interpretability to better diagnose failures.
- Theoretical understanding of verifier-guided RL: There is no analysis of when and why verifier-based rewards improve reasoning, given noisy verifiers. Develop models of learning under imperfect verifiers, derive bounds relating verifier precision/recall to expected policy improvement, and study conditions that guarantee monotonic gains.
- Reproducibility with open components: Key elements (verifier prompts, thresholds, pipeline configuration, synthetic query templates) are not fully specified in the main text, and proprietary services limit replication. Release detailed prompts/configs, open-source verifier baselines, and pseudo-label datasets (with licenses) to enable independent reproduction.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed with current capabilities, based on VALOR’s annotation-free training with multimodal verifiers, tool-use reasoning, and verifier-guided visual grounding.
- Healthcare
- Automated instrument and supply counting in operating rooms
- What it does: Counts surgical tools and verifies presence/absence from OR images, reducing manual tallies.
- Workflow/tool: Use VALOR’s counting queries with gd_detect on OR imagery; verifier-guided fine-tuning adapts detectors to hospital domains without labels.
- Assumptions/dependencies: Access to domain imagery; strong privacy controls; detector coverage of medical instrument categories.
- Fall-risk and hazard identification in care facilities
- What it does: Detects obstacles, clutter, and their spatial relations (e.g., “Is the walker blocked by a chair?”).
- Workflow/tool: Spatial Query Engine API (gd_detect + depth + programmatic rules); audit logs via program traces.
- Assumptions/dependencies: Depth estimation quality indoors; site-specific tuning via pseudo-label pipeline.
- Manufacturing and Industrial QA
- Assembly verification and configuration checks
- What it does: Confirms correct placement, spacing, and orientation of components from line imagery.
- Workflow/tool: Program synthesis to encode SOP checks; VLM-verified detector tuning for domain parts; adherence reward head ensures code-plan fidelity.
- Assumptions/dependencies: Unlabeled factory images; reliable depth or proxy cues for 3D spacing; safety approvals for automation.
- Retail and Warehousing
- Shelf-stock analytics and product placement verification
- What it does: Counts facings, validates planogram compliance, checks spatial relations (e.g., item below/above labels).
- Workflow/tool: Label-free grounding improvement via overprediction + VLM pruning; export reasoned results with per-step traces.
- Assumptions/dependencies: Category vocabularies; tolerance for pseudo-label precision (~75% post-pipeline); store-specific image capture.
- Inventory counting for warehouses
- What it does: Counts packages/pallets and checks arrangement constraints (e.g., “Are heavy boxes stacked at the bottom?”).
- Workflow/tool: VALOR program executor using gd_detect and depth; use GRPO-tuned reasoning models for robust tool calls.
- Assumptions/dependencies: Lighting/occlusion robustness; access to unlabeled warehouse images; safety governance.
- Construction and Safety Compliance
- PPE compliance auditing (helmets, vests) with reduced false positives
- What it does: Improves detection precision (e.g., distinguishes helmets vs caps) using verifier-filtered pseudo-labels.
- Workflow/tool: Hard-negative mining via low-threshold detector + three-stage VLM verification; periodic fine-tuning.
- Assumptions/dependencies: Domain images from sites; legal alignment for surveillance; accepted error rates.
- Robotics (near-term, single-image tasks)
- Pick-and-place scene understanding for static snapshots
- What it does: Grounds objects and measures spatial relations to inform manipulator targets.
- Workflow/tool: Programmatic queries (“Which object is reachable without collision?”) using gd_detect and depth; auditable chain-of-thought.
- Assumptions/dependencies: Single-image scope; depth estimator suitability; robot controller integration.
- Insurance and Claims Processing
- Photo-based damage and item verification
- What it does: Counts damaged items; checks layout claims (e.g., “Is the furniture arrangement blocking an exit?”).
- Workflow/tool: Spatial reasoning plans with adherence reward to ensure program matches plan; export per-claim reports.
- Assumptions/dependencies: Customer-provided images; generalization across households; policy acceptance of automated assessments.
- Energy and Infrastructure Inspection (image-based)
- Asset presence and clearance checks
- What it does: Detects equipment and verifies clearances (e.g., “Is the cabinet 0.5 m away from the wall?” via 2D-to-3D estimates).
- Workflow/tool: Depth-based width/height estimation; detector fine-tuning via pseudo-label pipeline to domain assets.
- Assumptions/dependencies: Metric depth model quality; calibration if needed; safety-critical verification by humans-in-the-loop.
- Transportation and Public Safety
- Crowd counting and occupancy monitoring
- What it does: Counts people/vehicles in public spaces with programmatic accuracy checks; explains errors via traces.
- Workflow/tool: Counting benchmarks show strong tool-use gains; deploy as a module with rate limits and audit logs.
- Assumptions/dependencies: Privacy policy adherence; demographic fairness audits; camera placement variations.
- Education and Research Tools
- Visual logic labs for spatial reasoning
- What it does: Teaches students programmatic reasoning over images (format, syntax, logic, spatial) with verifiable rewards.
- Workflow/tool: Classroom SDK mirroring VALOR’s reward heads; sandboxed execution.
- Assumptions/dependencies: Safe dataset curation; compute quotas.
- Software and MLOps
- Annotation-free detector fine-tuning service
- What it does: Offers “Verifier-in-the-loop” training to adapt detectors to client domains without labels.
- Workflow/tool: MVaaS (Multimodal Verifier-as-a-Service) with low-threshold detection + coarse filter + crop verification + dedup; versioned pseudo-label datasets.
- Assumptions/dependencies: Access to high-capacity VLM verifiers (e.g., Gemini-class); cost control; customer data governance.
- Daily Life
- Interior design and furniture-fit apps
- What it does: From a room photo, infers object sizes, checks spatial relations (“Will the table block the sofa?”).
- Workflow/tool: Consumer app using gd_detect + depth for 2D-to-3D estimates; explainable outputs via code snippets.
- Assumptions/dependencies: Accuracy depends on depth model; device camera quality; user consent for image processing.
Long-Term Applications
These applications require further research, scaling, or development (e.g., robust 3D reasoning, video, embodied control, higher-capacity verifiers, domain certification).
- Robotics (embodied, multi-step)
- Closed-loop spatial reasoning for manipulation and navigation
- What it could do: Real-time decomposition of tasks into tool calls, with continual verifier-driven tuning of grounding and logic.
- Potential product/workflow: “Visual Program Executor” integrated with robot policies; on-device verifier heads for safety.
- Dependencies: Video and temporal grounding; faster, on-edge verifiers; safety certification; robust depth/3D reconstruction.
- Video Analytics and Spatiotemporal Reasoning
- Persistent tracking, counting, and event reasoning across time
- What it could do: Multi-frame reasoning (“Did the person move behind the divider?”) with program traces and audits.
- Potential tools: Video-aware GD + temporal VLM verifier; RL with sequence-level rewards.
- Dependencies: Stable multi-object tracking; temporal verifiers; compute budgets for long sequences.
- Medical Imaging (regulated)
- Label-free adaptation of visual grounding to specialized equipment and procedures
- What it could do: Domain-specific detector training for devices, instruments, spatial constraints, without manual annotation.
- Potential tools: Pseudo-labeling pipeline with clinical VLM verifiers; explainable audit trails for compliance.
- Dependencies: Clinical validation, bias audits, regulatory approval (FDA/EMA); strict privacy and data provenance.
- Smart Cities and Policy Analytics
- Auditable, privacy-preserving public-space monitoring
- What it could do: High-level spatial queries (e.g., egress blockage, unsafe crowd densities) with explainable programs.
- Potential tools: Policy-grade “Auditable Reasoning Chain” with redaction, on-device processing, and verifier summaries.
- Dependencies: Legal frameworks; public transparency; edge deployment; fairness and bias evaluations.
- AR/VR and Digital Twins
- Real-time scene understanding and physical plausibility checks
- What it could do: Consistency checks between virtual and real objects; 2D-to-3D conversions for placement, occlusion, and collision.
- Potential tools: Spatial Query Engine with physics-aware modules; depth fusion with SLAM.
- Dependencies: Accurate 3D reconstruction; latency constraints; standardized APIs across XR platforms.
- Autonomous Vehicles and Drones
- Spatial reasoning for offboard analysis and fleet management
- What it could do: Audits of perception outputs, label-free detector tuning per geography, and explainable failure diagnostics.
- Potential tools: Verifier-guided pseudo-labeling from fleet camera feeds; GRPO-style reasoning for edge cases.
- Dependencies: Massive unlabeled data; secure pipelines; domain shifts across weather, lighting, geography.
- Agriculture and Environmental Monitoring
- Plant/animal counting and spatial health assessments
- What it could do: Large-scale counting, spacing checks, canopy coverage estimation using 2D-to-3D heuristics.
- Potential tools: Domain detector adaptation via annotation-free pipeline; program templating for agronomic rules.
- Dependencies: Drone and satellite image variability; calibration for scale; verifier accuracy in outdoor scenes.
- Finance and Real Estate
- Automated property feature extraction and spatial valuation indicators
- What it could do: Room dimension estimation, layout compliance, feature counts from listing photos.
- Potential tools: Consumer-facing “Spatial Insight API” with audit logs; bulk processing workflows.
- Dependencies: Depth inference reliability; disclosure and consent; guardrails against manipulation.
- Education and Benchmarking (Academia)
- Scalable, label-free dataset creation for spatial reasoning research
- What it could do: Pseudo-label corpora, structured reward head benchmarks, ablation libraries for reasoning and grounding.
- Potential tools: Open “Verifier-in-the-loop” benchmark kits; curriculum generation via synthetic queries.
- Dependencies: Access to high-capacity verifiers; community standards for synthetic label quality; reproducibility.
- Software Platforms and Standards
- Verifier-as-a-Service and Auditable Reasoning Standards
- What it could do: Industry-wide APIs for format, syntax, logic, attribute, spatial, and adherence reward heads; standardized program traces for compliance.
- Potential tools: MVaaS (Multimodal Verifier-as-a-Service), trace schemas, sandbox executors.
- Dependencies: Vendor-neutral governance; interoperability across LLM/VLM providers; security and cost controls.
Cross-cutting Assumptions and Dependencies
- High-capacity verifiers: Many gains rely on strong VLM/LLM verifiers (e.g., Gemini-class). Availability, cost, and API terms are critical.
- Unlabeled domain image supply: Quality and diversity of unlabeled images determine grounding performance and generalization.
- Depth and 2D-to-3D quality: Applications needing metric estimates depend on depth estimator accuracy and calibration.
- Compute and latency: RL (GRPO) and large verifiers require GPU resources; real-time scenarios need edge optimization.
- Safety, privacy, and compliance: Surveillance and healthcare use cases require strict governance, transparency, and audited traces.
- Bias and domain shift: Verifier-driven labels can inherit biases; routine evaluations and hard-negative mining strategies are necessary.
- Tool alignment: Consistent API semantics (gd_detect, depth, vqa) and sandboxed execution are needed for reliable, safe deployment.
Glossary
- Annotation-free training: A training paradigm that learns without human-provided labels, using automated feedback instead. "We propose an annotation-free training framework that improves both reasoning and grounding."
- Bootstrapping: An iterative self-improvement strategy that uses model outputs to generate better training data. "building on ideas from bootstrapping and hard-negative mining in face detection"
- Bounding box: A rectangular region that tightly encloses an object in an image, used for localization. "returns the bounding box of all object instances specified by the noun description -- e.g., gd_detect(``car")"
- Chain-of-thought: Step-by-step textual reasoning generated by LLMs to explain or arrive at answers. "language-only chain-of-thought approaches, which demand large-scale (image, query, answer) supervision,"
- Coarse filtering: An initial screening step to remove clearly invalid detections before finer verification. "coarse filtering removes invalid detections given the image and boxes overlaid,"
- COCO: A standard benchmark dataset for object detection and segmentation used to evaluate detector performance. "our training slightly boosts performance on the COCO~\citep{coco} validation set: to mAP."
- De-duplication: The process of removing duplicate detections or entries to improve label quality. "de-duplication eliminates duplicates."
- Exact-match accuracy: An evaluation metric that counts a prediction as correct only if it exactly matches the ground-truth answer. "We report exact-match accuracy for yes/no, multiple choice, and integer response queries,"
- Frozen model: A model (or component) kept fixed during training and used for evaluation or verification. "employ a frozen, pre-trained LLM as the verifier model"
- Ground truth labels: Manually annotated correct answers or targets used for supervised training. "eliminating the need for ground truth labels."
- GroundingDINO: A text-conditioned object detector used for visual grounding in the system. "GroundingDINO~\citep{groundingdino} for object localization (gd_detect)"
- GRPO: A reinforcement learning algorithm that stabilizes policy updates while maximizing advantages. "We optimize our LLM using GRPO~\citep{deepseek-r1}."
- Hard-negative mining: A training technique that focuses on challenging false detections to improve model robustness. "a VLM verifier strengthens visual grounding through automated hard-negative mining,"
- Knowledge distillation: Training a smaller student model to mimic a larger teacher model’s outputs or representations. "Methods in knowledge distillation typically trains a student model to imitate a teacherâs output distributions"
- LLM verifier: A LLM used to evaluate and provide feedback on reasoning outputs. "an LLM verifier refines LLM reasoning via reinforcement learning,"
- mAP (mean Average Precision): An aggregate metric for detection performance across classes and IoU thresholds. "our training slightly boosts performance on the COCO~\citep{coco} validation set: to mAP."
- Mean Relative Accuracy (MRA): A metric for evaluating numeric predictions by relative error or closeness. "and MRA for floating point response queries as in~\cite{vadar}."
- MoGe2: A model used to estimate metric depth at individual pixels. "MoGe2~\citep{moge2} for pointwise metric depth estimation (depth)"
- Multimodal verifiers: Verifiers that assess both language and vision outputs to provide training feedback. "by leveraging multimodal verifiers, without the need of ground truth supervision."
- Omni3D-Bench: A benchmark for evaluating 3D spatial reasoning from images. "Omni3D-Bench \citep{vadar} for 3D spatial understanding;"
- Overprediction: A detector behavior that produces too many (often false) detections, later pruned by verification. "This leads to overprediction, which we validate with a frozen VLM in three steps:"
- Per-crop verification: A verification step that checks detections using cropped image regions for finer validation. "per-crop verification validates remaining detections on cropped regions,"
- Pointwise metric depth estimation: Estimating real-world depth values at individual pixel locations. "MoGe2~\citep{moge2} for pointwise metric depth estimation (depth)"
- Program synthesis: Automatically generating executable programs (e.g., Python) to solve tasks via tool invocation. "Another line of work uses LLMs for program synthesis with vision specialists~\citep{vipergpt, visprog, vadar},"
- Pseudo-annotations: Automatically generated labels used as training data in the absence of human annotations. "We use VLM verifiers to generate pseudo-annotations for object detection"
- Pseudo-supervision: Training signals derived from model-generated or verifier-generated feedback rather than true labels. "LLM verifiers provide pseudo-supervision when ground truth labels are unavailable,"
- Reward model: A model (or set of checks) that scores outputs to guide reinforcement learning. "We design a reward model which verifies whether model outputs -- plan {paper_content} code -- are correct."
- Supervised fine-tuning (SFT): Post-training by optimizing directly against labeled or high-quality outputs. "comparing our verifier-based RL training (\S~\ref{subsec:rl_training}) with supervised fine-tuning (SFT)"
- Swin Transformer: A hierarchical vision Transformer architecture used as a detector backbone. "with a Swin Transformer~\citep{swin-t} vision backbone"
- Tool use: The practice of calling specialized external functions or models to solve subtasks. "we tackle visual reasoning via tool use through a scalable, annotation-free training framework"
- VLM verifier: A vision-LLM used to assess and refine visual detections and grounding. "a VLM verifier strengthens visual grounding through automated hard-negative mining,"
- VQA (Visual Question Answering): Answering questions about image content, often using cropped regions for specificity. "vqa, returns an objectâs attribute (e.g., color) from the input image crop around the object -- e.g., vqa(image_crop, ``What is the color of the object in the image?")"
- Visual grounding: Associating textual references with precise object locations and attributes in images. "Accurate visual grounding is critical for spatial reasoning,"
- Visual programming: Generating interpretable, executable programs that interact with visual tools to perform reasoning. "Visual programming approaches tackle spatial reasoning by generating interpretable, executable programs"
- Vision specialist models: Dedicated models for specific vision tasks (e.g., detection, depth, attributes) invoked by programs. "VALOR employs three vision specialist models"
- Verifiable rewards: Rewards that can be checked objectively, enabling reliable reinforcement learning. "reinforcement learning with verifiable rewards for mathematical reasoning"
- Weighted sum: Combining multiple reward components by applying weights to form a single scalar signal. "while the weighted sum of the remaining rewards evaluates content quality."
- Zero-shot evaluation: Testing on tasks or questions not seen during training without task-specific labels. "For Omni3D-Bench, we reserve $100$ queries for zero-shot evaluation"
Collections
Sign up for free to add this paper to one or more collections.