Vision-Zero: Scalable VLM Self-Improvement via Strategic Gamified Self-Play
Abstract: Although reinforcement learning (RL) can effectively enhance the reasoning capabilities of vision-LLMs (VLMs), current methods remain heavily dependent on labor-intensive datasets that require extensive manual construction and verification, leading to extremely high training costs and consequently constraining the practical deployment of VLMs. To address this challenge, we propose Vision-Zero, a domain-agnostic framework enabling VLM self-improvement through competitive visual games generated from arbitrary image pairs. Specifically, Vision-Zero encompasses three main attributes: (1) Strategic Self-Play Framework: Vision-Zero trains VLMs in "Who Is the Spy"-style games, where the models engage in strategic reasoning and actions across multiple roles. Through interactive gameplay, models autonomously generate their training data without human annotation. (2) Gameplay from Arbitrary Images: Unlike existing gamified frameworks, Vision-Zero can generate games from arbitrary images, thereby enhancing the model's reasoning ability across diverse domains and showing strong generalization to different tasks. We demonstrate this versatility using three distinct types of image datasets: CLEVR-based synthetic scenes, charts, and real-world images. (3) Sustainable Performance Gain: We introduce Iterative Self-Play Policy Optimization (Iterative-SPO), a novel training algorithm that alternates between Self-Play and reinforcement learning with verifiable rewards (RLVR), mitigating the performance plateau often seen in self-play-only training and achieving sustained long-term improvements. Despite using label-free data, Vision-Zero achieves state-of-the-art performance on reasoning, chart question answering, and vision-centric understanding tasks, surpassing other annotation-based methods. Models and code has been released at https://github.com/wangqinsi1/Vision-Zero.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Vision-Zero, a new way to train vision-LLMs (VLMs) without using expensive human-made labels. A VLM is a computer system that looks at images and reads text to answer questions or explain what it sees. Vision-Zero teaches these models by turning learning into a visual “Who Is the Spy?” game, so the model improves by playing—no humans needed to prepare data or correct answers.
What are the main questions?
The researchers wanted to know:
- Can a VLM teach itself to reason better using games instead of human-labeled data?
- Can this game work with almost any kind of image (charts, simple shapes, real photos) and still help the model?
- How do we keep improving the model over time, instead of getting stuck at “good enough”?
- Can this label-free training match or beat methods that rely on large, expensive datasets?
How does Vision-Zero work?
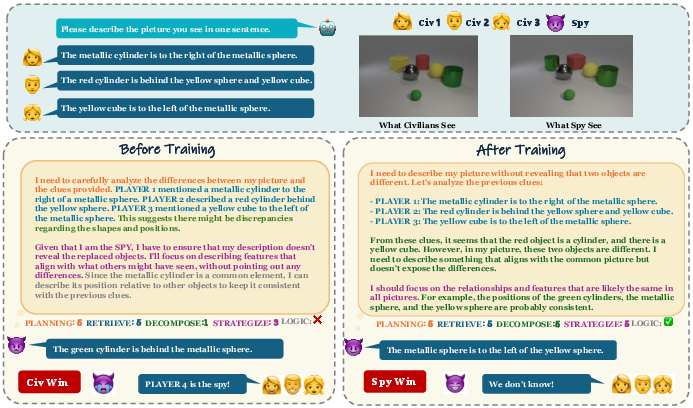
The game: “Who Is the Spy?”
Think of a strategy game like Mafia or Among Us, but with images:
- Several “civilian” players each get the same image.
- One “spy” gets a slightly different image (maybe a color changed, an object added or removed, or a number swapped in a chart).
- In the clue stage, players take turns giving short descriptions of their image. The spy tries to sound normal and hide the difference. Civilians try to be accurate without giving away too much.
- In the decision stage, civilians vote on who they think the spy is, based on everyone’s clues and their own image.
Because the model plays all roles, it generates its own training examples and gets feedback from the game’s outcome.
Training without human labels
Vision-Zero only needs pairs of images: one original and one slightly edited. No labels like “correct answer,” “object name,” or “bounding boxes” are required. The game itself produces feedback:
- If civilians correctly identify the spy, they get positive points.
- If they pick the wrong person, they lose points.
- The spy earns points by tricking civilians. This is called “verifiable rewards” because the game can check whether votes were correct.
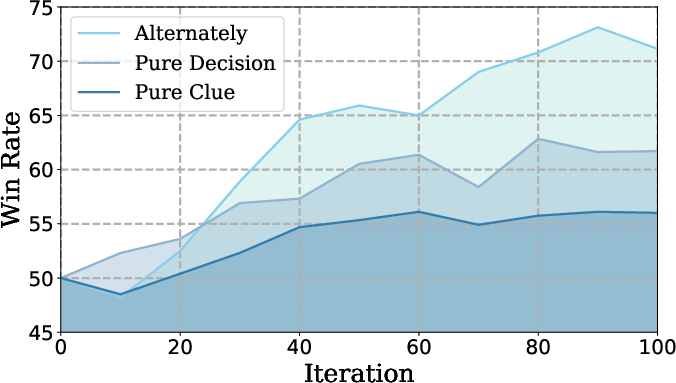
Alternating training to keep improving
The team created a two-part training method called Iterative-SPO:
- Self-play phase (clue stage): The model learns how to give better clues. Rewards are “zero-sum,” meaning one side’s gain is the other side’s loss—this encourages smarter strategies.
- RLVR phase (decision stage): The model learns to judge clues and vote correctly. RLVR stands for reinforcement learning with verifiable rewards, which means the model receives clear points for correct or uncertain answers and penalties for wrong ones.
They switch between these phases based on how well the model is doing. If identifying the spy gets too easy, they train the clue stage to make the game harder. If it gets too hard or the model guesses too much, they train the decision stage. This back-and-forth avoids getting stuck and keeps progress steady.
Works with many types of images
Vision-Zero is “domain-agnostic,” which means it can use:
- Synthetic scenes with simple shapes (CLEVR)
- Charts (bar, line, pie) with numbers swapped
- Real-world photos slightly edited
These can be created quickly and cheaply with modern image-editing tools.
What did they find, and why is it important?
The main results show:
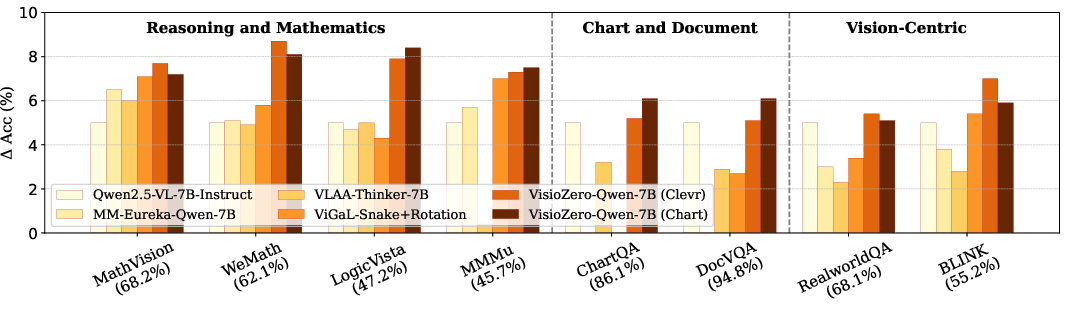
- Better reasoning: Models trained with Vision-Zero improved on multiple reasoning and math-related benchmarks, beating or matching methods that use large, human-labeled datasets.
- Generalization: Even though the game doesn’t directly teach math, the skills learned—careful observation, logical clues, spotting inconsistencies—carry over to math and logic tasks.
- Fewer trade-offs: Other methods often improve one skill (like math) but hurt others (like understanding charts). Vision-Zero improved several abilities at once and reduced these negative side effects.
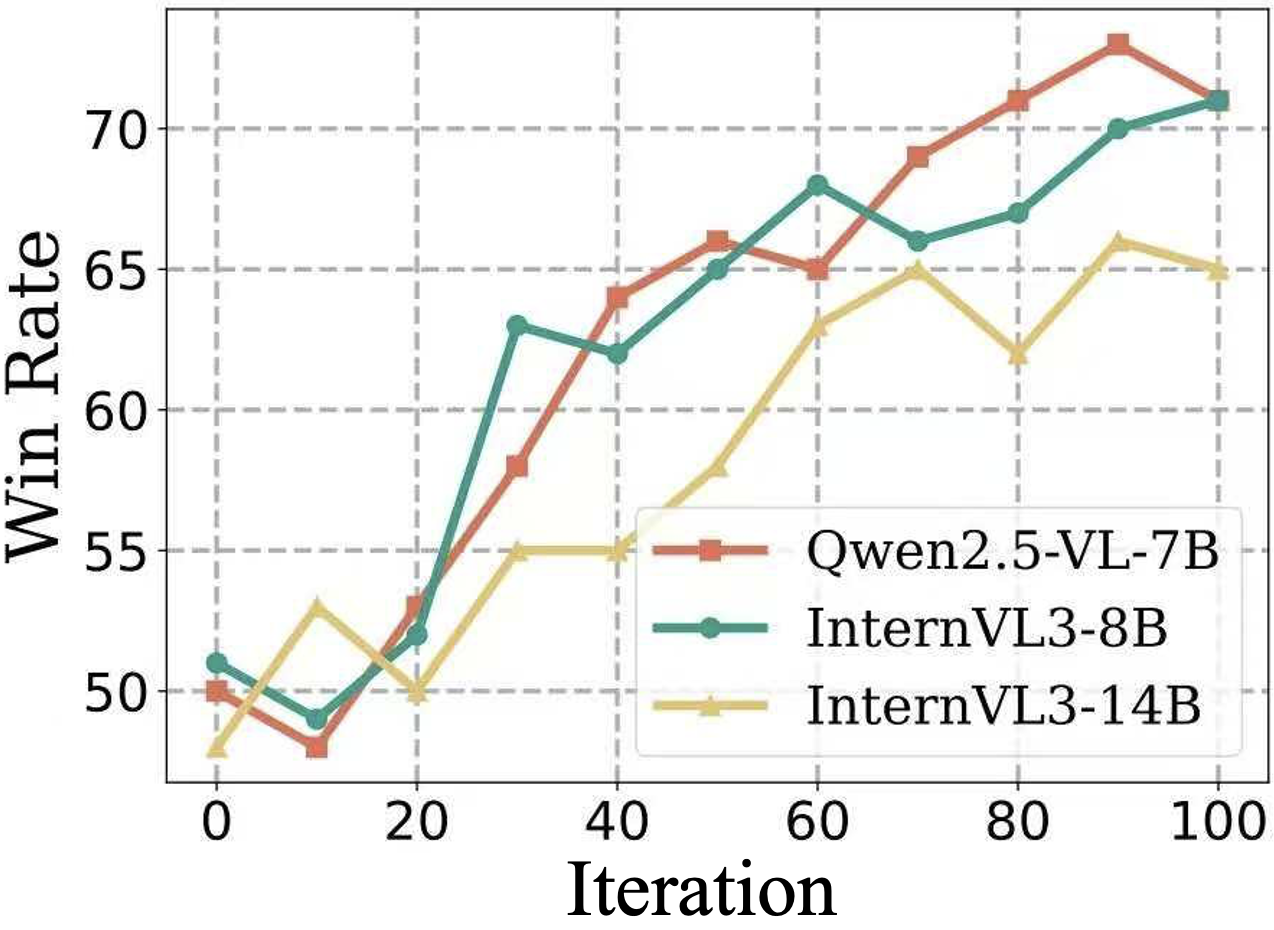
- Sustainable growth: The model keeps getting better over time, rather than hitting a plateau, thanks to the alternating training phases.
- Low cost: Instead of months of human labeling, Vision-Zero uses simple image edits and game outcomes. It’s far cheaper and faster to build datasets this way.
In short, Vision-Zero shows that self-play with smart game design can produce strong, broad improvements without human labels.
Why does this matter?
- Lower barriers: Training powerful VLMs no longer requires massive, expensive, hand-labeled datasets.
- Faster progress: Teams can build new, specialized datasets quickly using image edits and still get good results.
- Broader skills: Because it blends visual detail, language, and strategy, Vision-Zero strengthens multiple abilities at once—reasoning, spatial understanding, OCR for text in images, and more.
- Practical impact: This approach could help create smarter assistants for education, data analysis, science, and everyday tools that need to understand both pictures and words.
Overall, Vision-Zero shows a promising path toward “zero-human-in-the-loop” training: models that improve themselves through play, becoming more capable while saving time, money, and effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, articulated to be actionable for future research.
- Difficulty scaling of the environment is not operationalized: there is no mechanism to progressively increase the subtlety or number of visual differences, the number of rounds, or the complexity of strategic constraints; alternation between stages adjusts agent behavior but not task difficulty itself.
- Ambiguity and quality control of edited images are unaddressed: no automatic validation ensures a single, visible, unambiguous difference per pair (or that differences are not inadvertently trivial or undetectable), which risks noisy rewards and mislabelled “spy” rounds.
- Reward design vulnerability to collusion or reward hacking: since rewards depend on votes from model copies, agents could learn to coordinate (e.g., under-disclose or over-disclose) to inflate group rewards; anti-collusion mechanisms, opponent diversity, or audit checks are not explored.
- Lack of theoretical guarantees: Iterative-SPO has no convergence, stability, or monotonic improvement guarantees; conditions under which the alternating scheme avoids equilibrium stagnation or oscillations are not analyzed.
- Sensitivity to hyperparameters is unknown: no systematic sweeps or robustness analysis for β, λ, α, KL weights, group normalization parameters, and phase-switch thresholds; their impact on performance and stability remains unclear.
- Verifiable signals are confined to the decision stage: the clue stage relies solely on peer voting; there are no semantic consistency checks of clues against ground-truth diffs (e.g., automated object/attribute detectors), leaving truthfulness and relevance of clues unverified.
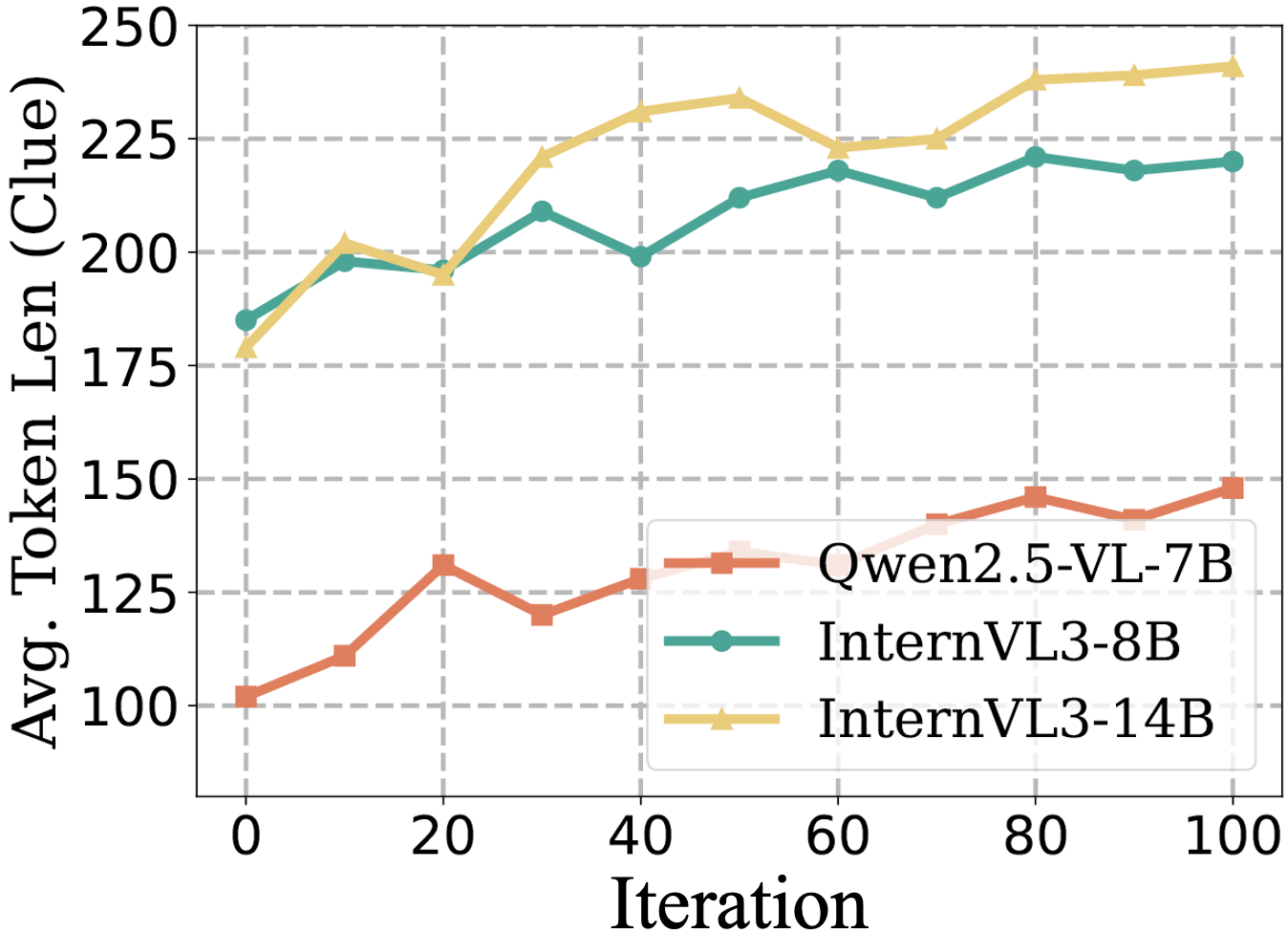
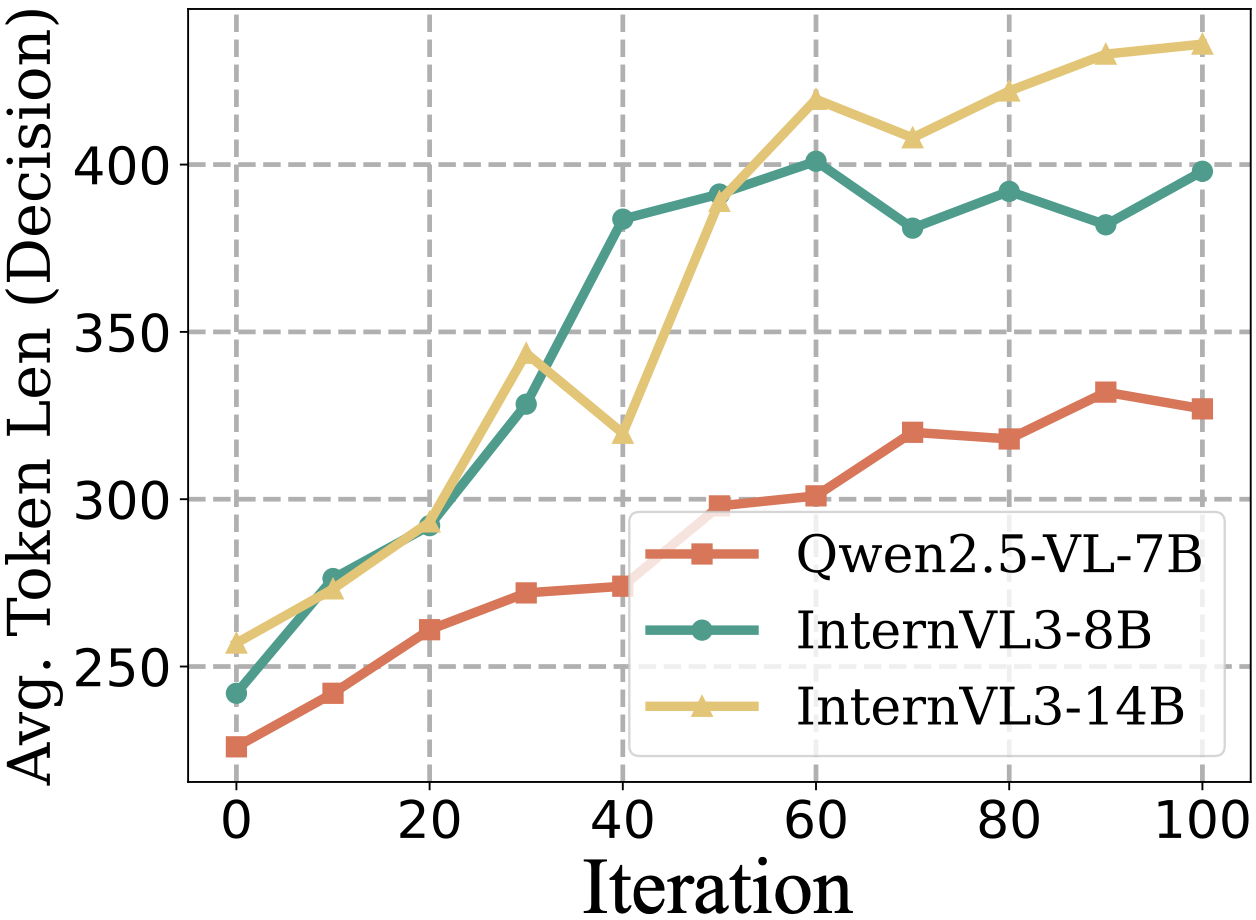
- Token length as a proxy for reasoning quality is unvalidated: longer outputs are reported, but the relationship to actual reasoning correctness, structure, or faithfulness is not quantified; more rigorous reasoning metrics are needed.
- Statistical rigor is limited: results lack confidence intervals, multiple seeds, or variance reports; significance of the 2–3% gains versus noise is unclear across tasks and models.
- Baseline comparability is imperfect: some baselines are missing or reported from original papers under different settings; compute budgets, data sizes, and training recipes are not controlled, limiting fairness of comparisons.
- Scalability to larger models and longer training horizons is unknown: only 7B–14B models and ~100 iterations are tested; scaling laws, sample efficiency, and asymptotic behavior with more data/compute remain unexplored.
- Opponent diversity is narrow: self-play occurs against current/reference policies without a league or archive; whether a population-based or curriculum league improves robustness and prevents overfitting is an open question.
- Fixed game configuration is unablated: number of civilians (n_c=4), number of clue rounds (two), and role assignment strategies are fixed; the effect of varying these parameters on learning dynamics and transfer is not studied.
- Environment difficulty gating is heuristic: phase switching relies on hand-tuned thresholds (accuracy, “n/a” rate) without principled derivation or generalization evidence across datasets/models; alternative gating signals are not tested.
- Transfer mechanisms are not causally identified: the paper shows generalization gains but does not analyze which learned behaviors (e.g., inconsistency detection, visual grounding, strategic discourse) drive improvements on math/reasoning benchmarks.
- Robustness to imperfect or adversarial inputs is untested: performance under occlusions, compression artifacts, multiple simultaneous edits, or “no-diff” pairs (requiring systematic “n/a” responses) is unknown.
- Potential degradation of truthfulness and honesty is unmeasured: the spy role incentivizes deception; impacts on truthfulness, safety, and alignment in general-purpose use are not evaluated; countermeasures (e.g., honesty constraints, truthfulness rewards) are absent.
- Domain coverage is limited to static images: there is no exploration of video, temporal reasoning, embodied tasks, or interactive environments; extension to multimodal sequences (vision+audio) and longer-horizon games is open.
- Data generation relies on proprietary tools (Gemini/ChatGPT): reproducibility and licensing concerns exist; open-source pipelines and quantitative quality audits for edits are not provided.
- Ground-truth “spy” labels are programmatic but not semantically verified: while the spy index is known, no automated check confirms that the modified attribute is the one agents should reason about (e.g., multiple unintended differences).
- Role parameterization is unclear: it is not specified whether roles share parameters or use role-specific heads/policies; the impact of role-specific architectures versus shared weights on learning and stability is not explored.
- KL regularization and reference policy choice are under-specified: how the reference distribution is updated or selected, and its effect on exploration/exploitation and degeneration avoidance, is not ablated.
- Negative transfer analysis is shallow: while some mitigation is reported, a broader audit across safety, hallucination rates, instruction following, and OCR fidelity (especially under domain shifts) is missing.
- Difficulty curriculum via environment generation is absent: no algorithm adapts edit magnitude, object count, distractor density, or textual constraints to match agent skill; a principled curriculum could improve sustained growth.
- Failure modes are not dissected: there is no taxonomy or qualitative analysis of incorrect votes (e.g., visual grounding errors, linguistic misinterpretations, strategic misjudgments), which would inform targeted improvements.
- Compute and energy accounting is opaque: claims of “tens of GPU hours” lack full details (hardware type, fp16/bf16 settings, memory footprint, optimizer schedules), hindering reproducibility and cost-benefit analyses.
- Cross-lingual and cultural generalization is untested: how clue/vote strategies transfer across languages, cultural priors, and diverse visual domains remains unknown.
- Integration with RLHF/SFT is unexplored: how Vision-Zero complements human-aligned post-training (e.g., mixing self-play with RLHF or instruction tuning) and its effects on alignment and utility are open.
- Evaluation relies partly on GPT-based scoring without human validation: the qualitative improvements in reasoning are assessed by an external model; human studies or grounded rubrics are missing.
- Data leakage risks are unaddressed: potential unintended cues (filenames, metadata, encoding artifacts) that reveal the spy or civilian identity are not audited or sanitized.
Practical Applications
Immediate Applications
The items below translate the paper’s contributions into deployable, concrete use cases. Each bullet names the application, indicates likely sectors, and outlines tools/workflows plus feasibility assumptions.
- Vision-Zero fine-tuning to reduce labeling cost for enterprise VLMs (software, AI/ML platforms)
- What: Use Vision-Zero’s “Who is the Spy?” self-play with arbitrary image pairs (product photos, slides, UI screenshots) to post-train in-house VLMs without human-annotated labels.
- Tools/workflows: Open-source Vision-Zero codebase; Qwen2.5-VL-7B/InternVL3 or similar open VLMs; automated image-editing pipelines (e.g., Gemini Flash, Photoshop APIs); Iterative-SPO training runs integrated into MLOps.
- Assumptions/dependencies: Access to model weights and GPUs; the ability to generate plausible, domain-consistent edited images; RLVR infrastructure and KL-regularized updates; governance for self-improving models.
- Chart and dashboard QA copilot (finance, BI/analytics, enterprise reporting)
- What: A copilot that reviews dashboards and slides to catch number swaps, mislabeled axes, or inconsistent legends—trained via chart-based Vision-Zero episodes.
- Tools/products: “Chart Guardian” plugin for BI suites (Tableau/Power BI/Looker); batch job that generates chart pairs via programmatic edits and runs Iterative-SPO.
- Assumptions/dependencies: Reliable chart editing to induce controlled differences; verifiable rewards mapped to correctness of “spy” identification; privacy-compliant use of business data.
- OCR and document-visual QA assistant (legal, insurance, operations)
- What: Improve OCR-centric reasoning (finding deltas across revised contracts, claims forms, SOP documents) by training on real-world edited image pairs.
- Tools/workflows: Document ingestion, programmatic diff edits (e.g., swapped dates/amounts), Vision-Zero training loops; deployment as a “DocDiff” reviewer that explains the change and flags risk.
- Assumptions/dependencies: High-quality document image rendering and edits; robust OCR back-ends; LLM/VLM access for chain-of-thought in decision stage.
- Visual UI regression tester with reasoning (software engineering, QA)
- What: Train a VLM to reason about semantic impact of UI changes (layout shifts, missing widgets) from screenshot pairs.
- Tools/products: “Screenshot Sentinel” CI step that synthesizes UI diffs, runs self-play to improve the model; report explaining functional impact (e.g., “checkout button hidden on mobile”).
- Assumptions/dependencies: Synthetic screenshot generation or captured historical versions; test data management; mapping Vision-Zero votes to pass/fail signals.
- Retail/e-commerce listing integrity checker (retail, marketplaces)
- What: Detect subtle product-photo inconsistencies (wrong color/variant/accessories) and describe them, leveraging diff-trained reasoning.
- Tools/workflows: Batch edit catalog images to simulate common listing errors; iterative training; an inference-time API that compares listing image vs reference and explains mismatches.
- Assumptions/dependencies: SKU-level canonical references; low false-positive tolerance; scalable image edit generation (color/shape/feature swaps).
- Model red-teaming and capability auditing via self-play (AI safety, compliance)
- What: Use the spy-game dynamics to elicit strategies that reveal deception tendencies, hallucination under uncertainty, and calibration (via “n/a” reward signal).
- Tools/workflows: Governance dashboards showing accuracy vs “n/a” rates; automatic curriculum of hard cases from self-play; gated phase switching as a stability check.
- Assumptions/dependencies: Clear risk thresholds; logging and reproducibility; oversight to prevent harmful deception strategies migrating to production behavior.
- Low-cost academic benchmarking and course labs (academia, education)
- What: Reproduce benchmark gains on MathVista/LogicVista with minimal data budget; run ablations on self-play vs RLVR vs Iterative-SPO for teaching.
- Tools/workflows: VLMEvalKit; CLEVR renderer; open datasets; Jupyter-based labs around switching thresholds and group-normalized rewards.
- Assumptions/dependencies: GPU access; IRB/data ethics for any student-generated images; versioned code and seeds for reproducibility.
- “Spot-the-difference” reasoning apps for learners (education, daily life)
- What: Consumer apps that generate bespoke puzzles to build observation and inference skills, with the model explaining its reasoning and uncertainty.
- Tools/products: Mobile app integrating image editors and the Vision-Zero loop; classroom mode for teachers to control difficulty.
- Assumptions/dependencies: Age-appropriate content filters; cost control for image edits and inference; simple privacy policy for user images.
- Visual change detection in slide reviews and reports (knowledge work, daily life)
- What: Assistant that compares slide versions and flags subtle inconsistencies (e.g., swapped bars, mislabeled icons), offering concise rationales.
- Tools/workflows: Office suite plugin; chart/image export and controlled edits for training; iterative evaluation on internal decks.
- Assumptions/dependencies: Access to slide assets; acceptable latency for review workflows; caching of per-deck context.
- Quality control for visual manufacturing checks (manufacturing, logistics)
- What: Train with synthetic “defect insertion” to spot subtle anomalies and reason about them (missing screw, color misprint).
- Tools/workflows: CAD-to-image pipelines with controlled edits; self-play episodes tuned to factory defect taxonomy; operator console to review explanations.
- Assumptions/dependencies: Domain-faithful synthetic edits; safety certification for advisory usage; human-in-the-loop for final decisions.
Long-Term Applications
These opportunities require further R&D, scaling, or domain adaptation before reliable deployment.
- Medical imaging difference reasoning and triage (healthcare)
- What: Train models on clinically realistic synthetic edits (lesion size changes, subtle opacities) to assist “compare-and-explain” triage across time-series scans.
- Potential product: Radiology assistant that highlights likely changes and provides calibrated “n/a” when uncertain.
- Assumptions/dependencies: High-fidelity, regulatorily acceptable simulators; stringent validation and bias audits; clinician workflow integration; FDA/CE approvals.
- Continual, on-the-fly self-improvement for deployed multimodal agents (robotics, AR)
- What: Agents that periodically self-play on freshly captured environment snapshots to stay calibrated to domain drift without labeled data.
- Tools/workflows: Edge-compatible Iterative-SPO; on-device synthetic edits; phase-gated training windows; rollback and guardrails.
- Assumptions/dependencies: Reliable on-device compute; safety guarantees against catastrophic forgetting; monitoring for drift-induced degradation.
- Synthetic curriculum generation for complex multimodal reasoning (general AI research)
- What: Use self-play to automatically generate progressively harder image-edit curricula (compositional edits, occlusions, multi-step logic) and verifiable rewards.
- Potential tools: “Curriculum Factory” that scores hardness via decision-stage accuracy/“n/a” and escalates edits accordingly.
- Assumptions/dependencies: Difficulty metrics that correlate with downstream task gains; avoidance of overfitting to game artifacts.
- Standardized governance benchmarks for self-improving VLMs (policy, standards)
- What: Regulatory-grade test suites using the Vision-Zero paradigm to quantify uncertainty calibration, deception under incentives, and cross-capability transfer.
- Potential outputs: Certification protocols that track accuracy vs “n/a” and role-advantage normalization; reporting templates for audits.
- Assumptions/dependencies: Multi-stakeholder consensus on metrics; access to reference models/environments; reproducibility and secure logging.
- Multimedia content integrity and tamper detection (media, security)
- What: Train with sophisticated image/video edits to identify subtle manipulations and produce human-readable justifications.
- Products: Newsroom verification tools; platform moderation assistants with explainable diffs.
- Assumptions/dependencies: High-quality, diverse manipulation simulators; adversarial robustness; policy alignment to avoid over-flagging benign edits.
- Cross-modal “decision-aware” training for agents using live sensory streams (autonomy, IoT)
- What: Extend the spy-game to sequences (video, depth, IMU) so agents learn to reason about subtle temporal/spatial inconsistencies and abstain when uncertain.
- Tools: Sequence-aware self-play with verifiable outcomes; group-normalized rewards adapted to time-series.
- Assumptions/dependencies: Temporal edit generation; scalable RL infrastructure; safety case for abstentions in critical control loops.
- Enterprise “Zero-Label Trainer” platforms (software, AI infrastructure)
- What: Managed services that accept customer images, auto-generate self-play curricula, and deliver domain-adapted VLMs with governance controls.
- Features: Dataset simulators, edit toolchains, Iterative-SPO orchestration, audit dashboards, policy gates for phase switching and KL constraints.
- Assumptions/dependencies: Data residency and IP protections; SLAs for model quality and rollback; robust monitoring to detect metric gaming.
- Legal and compliance review with multimodal diffs (legaltech, compliance)
- What: Cross-compare document scans, charts, and embedded images across versions to surface material changes and likely risk implications.
- Products: Compliance copilot that explains “what changed” and “why it matters,” calibrated to abstain for borderline cases.
- Assumptions/dependencies: Domain ontologies for materiality; secure handling of sensitive documents; auditor acceptance of AI explanations.
- Human–AI collaborative games for pedagogy and assessment (education research)
- What: Classroom-scale social deduction games blending human and AI players to teach evidence-based reasoning and calibration.
- Tools: Role-aware prompts, private/public reasoning channels, adaptive difficulty via self-play metrics.
- Assumptions/dependencies: Age-appropriate scaffolding; ethics oversight; rigorous studies on learning outcomes.
Cross-cutting feasibility notes
- Transfer assumptions: The paper shows generalization from spy-game training to downstream reasoning/chart/OCR tasks with modest but consistent gains; transfer to safety-critical domains will require domain-faithful edits, stronger validation, and uncertainty calibration.
- Data generation: Success depends on generating subtle, domain-relevant image edits. For specialized fields (e.g., medical, satellite), high-fidelity simulators or expert-in-the-loop editing may be necessary.
- Compute and ops: Although cheaper than human labeling, Vision-Zero still needs GPU time and RL plumbing (self-play orchestration, KL regularization, reference policies, stage switching).
- Safety and governance: The competitive setup can incentivize deceptive strategies; alignment, red-teaming, and guardrails (e.g., calibrated “n/a” responses) are essential before real-world deployment.
- IP and privacy: Ensure rights to edit and process images; adopt privacy-preserving pipelines for sensitive enterprise data.
Glossary
- Advantage-weighted log-likelihood: An objective that weights the log-likelihood of actions by their estimated advantages to reinforce better decisions. "advantage-weighted log-likelihood of the sampled votes"
- Domain-agnostic: Not tied to any specific application domain, enabling training and evaluation across diverse image/data types. "a domain-agnostic framework enabling VLM self-improvement"
- Exponential moving averages: A running average that applies exponential decay to past values, smoothing metrics over time. "We maintain exponential moving averages with smoothing ρ∈[0,1):"
- Group normalization: Normalizing rewards/statistics across a group to reduce round-specific difficulty and stabilize learning. "To remove round-specific difficulty, we apply group normalization:"
- GRPO: Group Relative Policy Optimization; a reinforcement learning algorithm that compares group-normalized returns to guide updates. "Therefore, we adopt the GRPO objective for Decision Stage."
- Hysteresis thresholds: Separate switching criteria used to avoid rapid oscillation when toggling between training phases. "We switch phases using hysteresis thresholds"
- Iterative Self-Play Policy Optimization (Iterative-SPO): The proposed alternating training scheme that switches between self-play and RLVR to sustain improvement. "Iterative Self-Play Policy Optimization (Iterative-SPO), which alternates between Self-Play and RLVR"
- KL regularization: Penalizing divergence from a reference policy via Kullback–Leibler divergence to stabilize updates. "the KL term constrains updates to remain close to π_ref, stabilizing learning and preventing degenerate utterances."
- Local equilibrium: A stable state in self-play where strategies stop improving due to balanced competition. "A pure self-play setup typically reaches a local equilibrium"
- Negative capability transfer: Performance degradation in one capability as an unintended consequence of training on another. "reducing shortcut bias from text and negative capability transfer"
- PPO (Proximal Policy Optimization): A popular reinforcement learning algorithm that constrains policy updates to improve stability. "Collected in game environment via PPO policy"
- Reference policy: A baseline policy used to regularize training updates and prevent drift. "With a reference policy π_ref, the optimization objective of Clue Stage is,"
- Reinforcement learning from human feedback (RLHF): RL that learns from human-provided preference or feedback signals. "reinforcement learning from human feedback (RLHF)"
- Reinforcement learning with verifiable rewards (RLVR): RL that relies on automatically checkable reward signals, reducing dependence on human labels. "reinforcement learning with verifiable rewards (RLVR)"
- Role-Advantage Estimation (RAE): A baseline adjustment that compensates for information asymmetry across roles when computing advantages. "Role-Advantage Estimation (RAE)."
- Role collapse: A training failure where distinct agent roles converge to degenerate or indistinguishable behaviors. "preventing common pitfalls like role collapse"
- Self-Play: A training paradigm where agents learn by competing against copies of themselves, generating automatic feedback. "Self-Play offers a solution by eliminating human supervision through competitive dynamics"
- Shortcut bias: The tendency of models to exploit spurious cues instead of genuine reasoning. "shortcut bias from text"
- Supervised fine-tuning (SFT): Post-training with labeled examples to align model outputs with desired behavior. "supervised fine-tuning (SFT)"
- Verifiable rewards: Rewards that can be programmatically validated without human judgment. "learns from verifiable rewards"
- Zero-human-in-the-loop: A training setup requiring no human intervention during data generation or optimization. "the first zero-human-in-the-loop training paradigm for VLMs"
- Zero-sum game: A competitive setting where one side’s gain is exactly the other side’s loss, making total reward sum to zero. "the zero-sum game principle"
Collections
Sign up for free to add this paper to one or more collections.

