- The paper introduces Xuanwu VL-2B, a compact 2B-parameter model that balances fine-grained visual perception with robust business content moderation under compute constraints.
- It leverages an InternViT-300M visual backbone and a progressive three-stage training pipeline, achieving significant improvements in both moderation recall (94.38%) and adversarial OCR (82.82%).
- The study offers practical insights for scalable multimodal architectures, highlighting low inference costs and potential future enhancements in policy compliance and explainable AI.
Xuanwu VL-2B: A Compact, Industrial-Grade Multimodal Foundation Model for Content Ecosystems
Motivation and Problem Setting
The paper addresses the operational deficiencies of mainstream multimodal LLMs (MLLMs) in industrial content moderation and adversarial scenarios. While models such as LLaVA, Qwen-VL, and InternVL demonstrate strong open-domain cross-modal capabilities, their utility is compromised in real deployments due to inference overhead, catastrophic forgetting, insufficient granularity in moderation, and weak adversarial robustness. Key industrial requirements—high-precision moderation and adversarial-content defense—demand structures capable of fine-grained perceptual discrimination and robust policy alignment under compute constraints. Xuanwu VL-2B is proposed as a compact, approximately 2B-parameter multimodal foundation model that achieves a balance between fine-grained visual perception, language-semantic alignment, business performance, and inference cost.
Model Architecture
The core architecture adopts InternViT-300M as the visual backbone and Qwen3 1.7B as the language backbone, connected via a lightweight MLP projector, eschewing complex MoE or Q-Former connectors to maximize training stability and deployment efficiency. Quantitative evaluation across vision encoder candidates (InternViT-300M, AIMv2-Huge, SAILViT-Huge) establishes InternViT-300M as the optimal trade-off between multimodal capability, OCR robustness, and inference cost. Dual-encoder fusion experiments (e.g., pairing with GOT-ViT) indicate only marginal gains and increased overhead, hence a single vision backbone is retained.
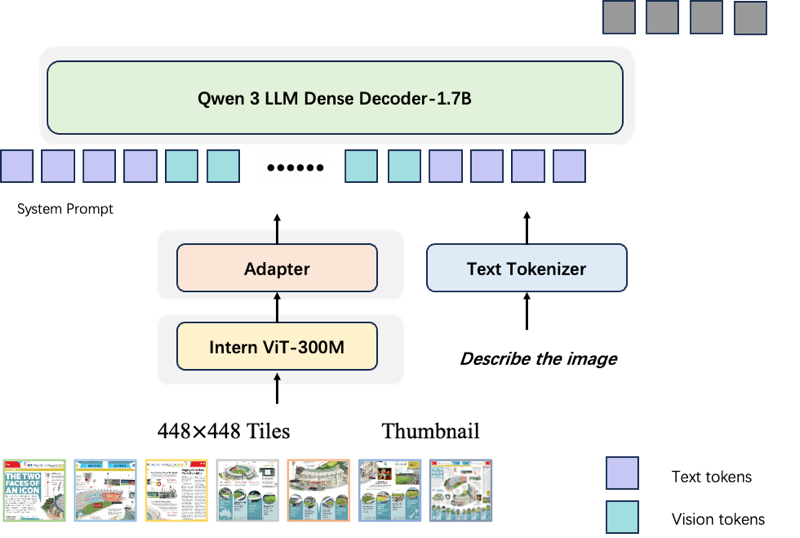
Figure 1: Xuanwu VL-2B utilizes InternViT-300M as the visual backbone and Qwen3 1.7B as the language backbone, interfaced through an MLP projector.
A Dynamic High-Resolution Perception mechanism is implemented: images are adaptively tiled (up to 12×448×448 tiles) based on aspect ratio, with global thumbnails preserved and visual features pixel-unshuffled to constrain token proliferation. This preserves both local granularity and global context under fixed compute budgets.
Training Pipeline
The model is trained via a progressive three-stage pipeline:
- Pre-training: Foundation image-text alignment (1.3M high-quality alignment samples; 17.33M paired image-text samples), optimizing multimodal autoregressive cross-entropy loss.
- Mid-training: Injection of business knowledge, instruction-following enhancement, moderation, and adversarial SPAM data; includes base-retention sampling to mitigate catastrophic forgetting, quality filtering via LLM judge and CLIP scoring, and diversity balancing with K-Means clustering.
- Post-training: Supervised fine-tuning with high-fidelity SFT data curated by model-in-the-loop teacher verification, RL alignment using GRPO, and extensive Chain-of-Thought (CoT) annotation for explainable moderation.
The RL reward formulation combines classification, output-format compliance, and OCR alignment, specifically penalizing missed and hallucinated characters. GRPO alignment improves adversarial weighted OCR recall from 76.42% to 82.82%. CoT systematically structures reasoning output for transparent policy violation attribution.
Evaluation and Results
General Capability Retention
On seven OpenCompass multimodal metrics, Xuanwu VL-2B outperforms InternVL 3.5 2B (67.90 vs. 64.27). On text-only benchmarks, the model maintains a competitive average-9 score (58.38 vs. 59.02) but loses ground on C-Eval and arithmetic code tasks due to format non-compliance and business data compression.
Business Moderation
Average recall across seven moderation labels reaches 94.38%, a 46.4-point improvement over InternVL 3.5 2B. Recall is high across ad, high-risk, illegal, pornographic, vulgar, and normal categories, demonstrating robust specialization without sacrificing general perception.

Figure 2: Example illustrating detection of cursive diversion codes in complex product images, demonstrative of fine-grained adversarial OCR robustness.

Figure 3: Case of low-opacity contact information hidden in image layer as watermark, intercepted and decoded.
Adversarial OCR
Weighted overall recall in adversarial OCR scenarios (eight attack types) is 82.82%, significantly higher than commercial Gemini-2.5-Pro (76.72%) and InternVL baselines (64.79%). Notable improvements are shown in AIGC-fusion, noise, warp, and watermark attacks. Ablation studies confirm that SFT curation and GRPO alignment are critical for both recall and reduction in false positives.

Figure 4: Micro-font variant-character diversion—text shrunk to extreme scales for evasion.
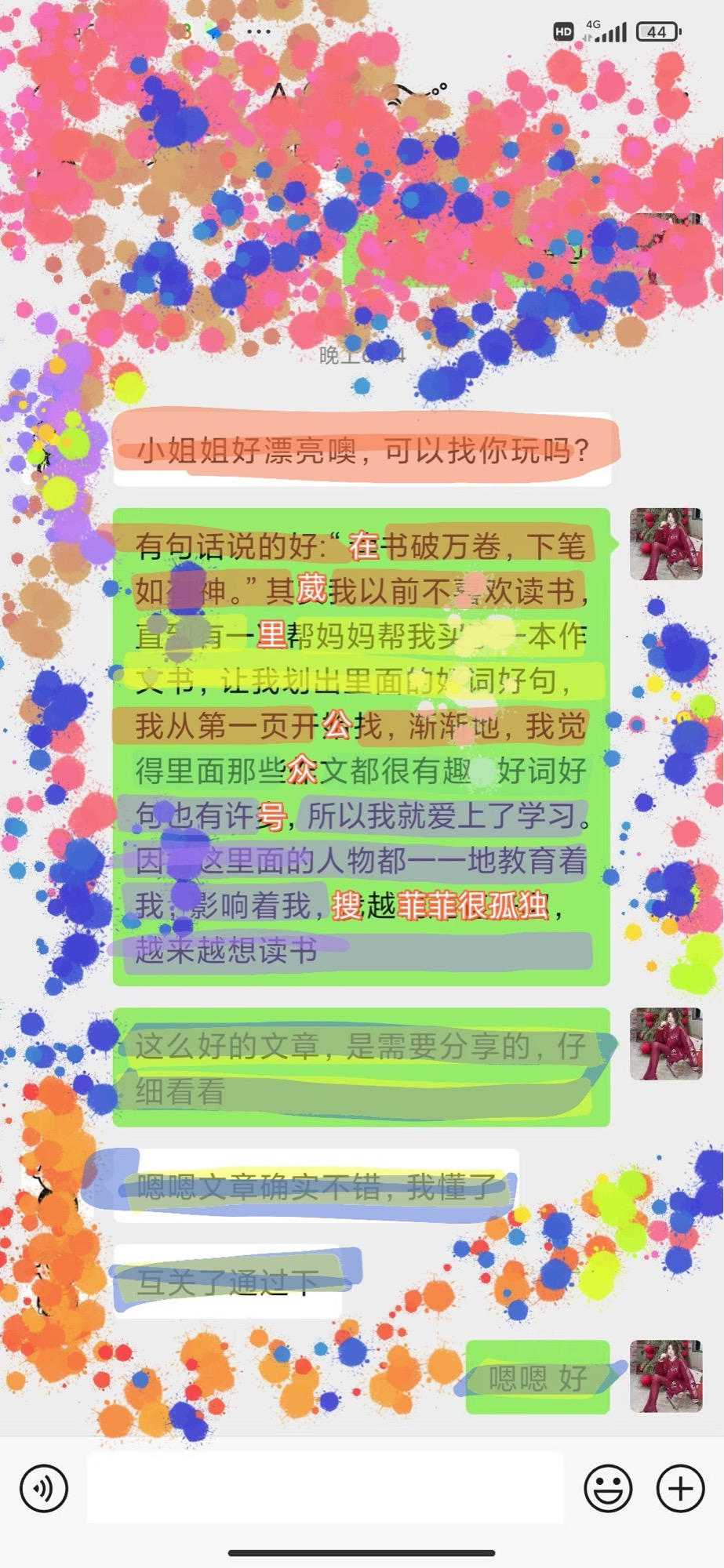
Figure 5: Diversion keywords camouflaged in long prose paragraphs, demonstrating model's context-resilient extraction.

Figure 6: Severe distortion and warping, breaking character morphology to obfuscate detection, handled by Xuanwu VL-2B.
Qualitative Explainability
Chain-of-Thought outputs illustrate the model's multi-step reasoning: meticulous extraction of concealed cues (handwriting, watermarks, micro-font, noise camouflages), rationale attribution, and explainable policy enforcement.

Figure 7: AIGC-forgery—contact info embedded into image textures via generative diffusion models.

Figure 8: Combination-camouflage—group numbers hidden in benign academic backgrounds using symbolic indirection.

Figure 9: Concealed diversion text distributed beneath long greeting images, challenging perceptual pipelines.
Implications and Future Directions
Practical Implications
Xuanwu VL-2B demonstrates that industrial-grade multimodal moderation can be achieved under tight parameter and compute budgets by integrating fine-grained perception, robust alignment, and business-oriented data curation. The architecture is deployable at scale with low VRAM/latency overhead, showing superior recall and explainability in adversarial settings. Immediate applications include content moderation, adversarial forgery interception, and explainable policy compliance on social platforms.
Theoretical Implications
The results challenge prevailing assumptions that capability and robustness in adversarial business scenarios require massive parameter expansion or complex MoE structures. Careful vision encoder selection, tailored pipeline progression, and reward-driven RL allow retention of general capabilities while achieving strong domain specialization and robustness.
Speculation on Future Developments
Plans include moving toward native multimodal architectures (unified token sequences), full sensory integration (audio/video), global multilingual expansion, and further quantized inference optimizations. This may enable more agile, agentic content ecosystem foundations, with continuous self-adversarial evolution, policy distillation, and adaptation to new regulatory/unethical threats.
Limitations
Despite strong performance, the model remains susceptible to extreme edge cases: ultra-dense overlapping watermarks, pixel-level hidden text beyond perceptual resolution, and logical shortcut errors in long-context chain-of-thought outputs. Further improvements could target receptive field expansion and format compliance.
Conclusion
The study establishes Xuanwu VL-2B as a robust, compact foundation for multimodal content ecosystems, achieving high recall in business content moderation and adversarial OCR scenarios while retaining general capability. The architectural and procedural methodologies offer a blueprint for balancing domain adaptation, robustness, and efficiency in future multimodal agent systems, pointing toward increasingly adaptive and explainable industrial moderation solutions (2603.29211).

