Qwen3-VL Technical Report
Abstract: We introduce Qwen3-VL, the most capable vision-LLM in the Qwen series to date, achieving superior performance across a broad range of multimodal benchmarks. It natively supports interleaved contexts of up to 256K tokens, seamlessly integrating text, images, and video. The model family includes both dense (2B/4B/8B/32B) and mixture-of-experts (30B-A3B/235B-A22B) variants to accommodate diverse latency-quality trade-offs. Qwen3-VL delivers three core pillars: (i) markedly stronger pure-text understanding, surpassing comparable text-only backbones in several cases; (ii) robust long-context comprehension with a native 256K-token window for both text and interleaved multimodal inputs, enabling faithful retention, retrieval, and cross-referencing across long documents and videos; and (iii) advanced multimodal reasoning across single-image, multi-image, and video tasks, demonstrating leading performance on comprehensive evaluations such as MMMU and visual-math benchmarks (e.g., MathVista and MathVision). Architecturally, we introduce three key upgrades: (i) an enhanced interleaved-MRoPE for stronger spatial-temporal modeling across images and video; (ii) DeepStack integration, which effectively leverages multi-level ViT features to tighten vision-language alignment; and (iii) text-based time alignment for video, evolving from T-RoPE to explicit textual timestamp alignment for more precise temporal grounding. Under comparable token budgets and latency constraints, Qwen3-VL achieves superior performance in both dense and Mixture-of-Experts (MoE) architectures. We envision Qwen3-VL serving as a foundational engine for image-grounded reasoning, agentic decision-making, and multimodal code intelligence in real-world workflows.
First 10 authors:
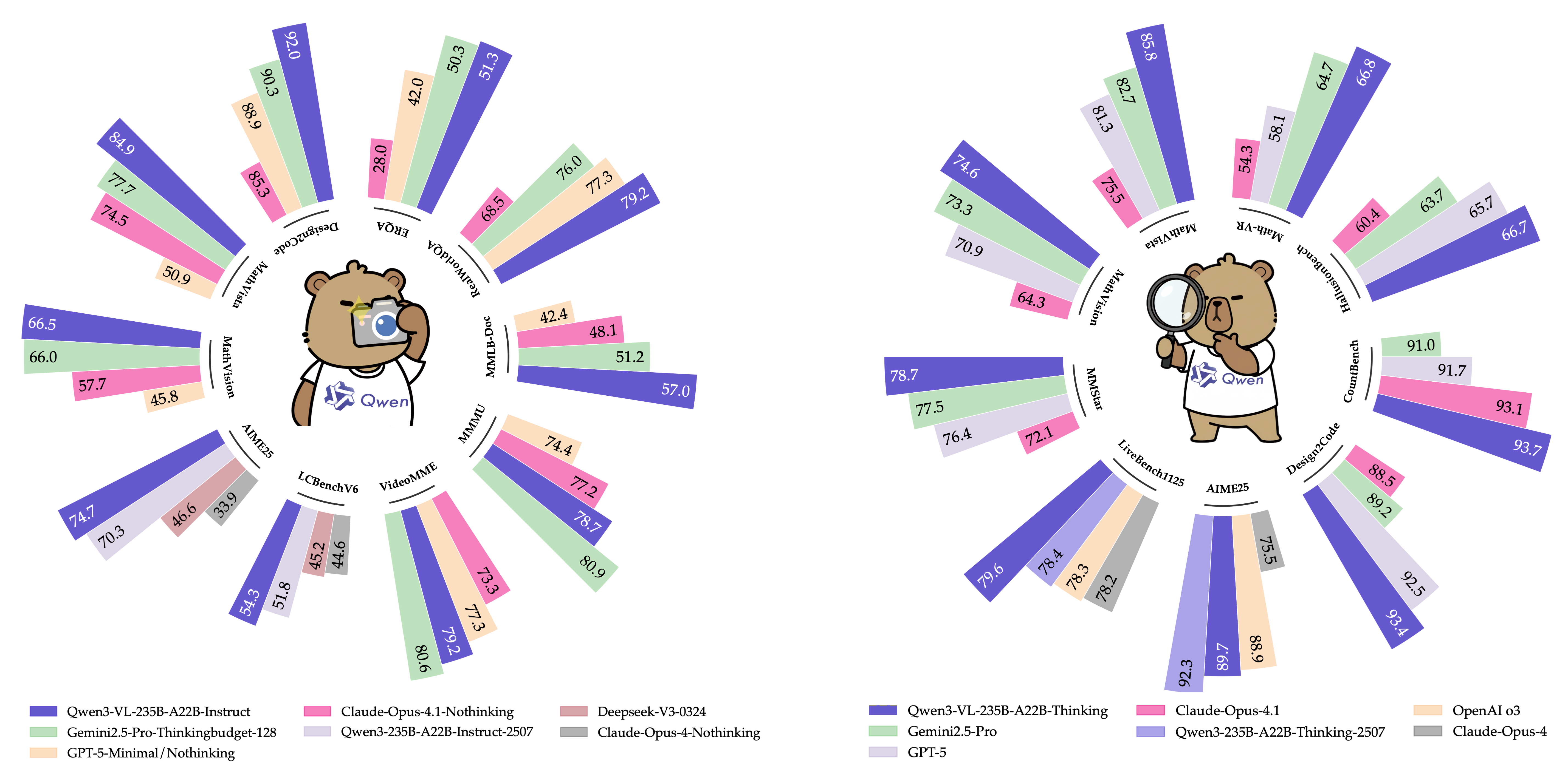

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the Paper
This paper introduces Qwen3‑VL, a powerful AI model that can understand both language and visuals. That means it can read text, look at images, watch videos, and connect all of that information to answer questions, solve problems, and follow instructions. It’s built to handle very long inputs—like entire books or hour‑long videos—and still remember and reason across everything it saw.
Key Objectives and Questions
The paper focuses on three main goals:
- Can a model understand and use text as well as top text‑only models, even while learning from images and videos?
- Can it keep track of information in very long contexts (up to 256,000 “tokens,” which are like pieces of text or visual markers), and connect details across many pages or minutes?
- Can it reason well about visuals—like solving math problems using diagrams, understanding complex images, and following events in videos?
How They Built and Trained the Model
The researchers designed both the model’s “brain” and the training process to make language and vision work together smoothly.
Architecture Upgrades (explained in everyday terms)
- Interleaved MRoPE (positional encoding): Think of this like giving the model a sense of “where” and “when” each piece of information belongs. For images and video, you need to know horizontal (left‑right), vertical (up‑down), and time (frame order). Earlier methods were unbalanced, which hurt long‑video understanding. The new “interleaved” method spreads these signals evenly, so the model tracks space and time more reliably.
- DeepStack (multi‑level vision features): A vision encoder (like a “camera brain”) sees low‑level details (edges, colors) and high‑level concepts (objects, scenes). DeepStack passes features from several vision layers directly into matching language layers. It’s like feeding the LLM both the raw details and the big picture at the same time, so it aligns words with visuals more precisely.
- Text‑based timestamps for video: Instead of relying only on math‑based position signals, they insert clear text markers such as “<3.0 seconds>” before frames. This makes time in video more explicit and understandable, improving tasks like finding when an event happens.
- Balancing text and multimodal training: They adjust the “weight” of training examples using a square‑root rule. Think of it like turning knobs so neither text nor image/video training dominates. This keeps language skills strong while boosting visual reasoning.
- Dense and MoE versions: “Dense” models process everything with the same parameters. “Mixture of Experts (MoE)” models have many expert blocks but only a few are active per input, which can be faster for similar quality—like consulting the right specialist for each question.
Training Process (four stages)
The model learns in steps, like a school curriculum:
- Stage 0 (Alignment): Only the part that connects vision and language is trained, so the model learns how to map images/video to words cleanly.
- Stage 1 (Full Multimodal Pretraining, 8K tokens): Everything trains together on huge amounts of mixed data (text plus images and some video), so language and vision skills grow side by side.
- Stage 2 (Long‑Context Pretraining, 32K tokens): The model is trained to handle much longer inputs, with more long text, more video, and multi‑step tasks.
- Stage 3 (Ultra‑Long Context, 256K tokens): Final training to master very long inputs—think entire textbooks or hour‑long videos—while staying coherent and accurate.
Data They Used (high‑level overview)
They carefully assembled and cleaned many kinds of data, so the model can handle real‑world tasks:
- Image captions and interleaved text+image documents: High‑quality descriptions and long multimodal pages (like books and websites) to learn grounded understanding.
- Knowledge and entities: Data about animals, landmarks, food, devices, and more, with rich descriptions to improve recognition and reasoning.
- OCR and document parsing: Reading text inside pictures and PDFs, understanding layouts, tables, and diagrams across many languages.
- Grounding and counting: Finding objects with boxes or points and counting them—important for precise visual tasks.
- Spatial and 3D reasoning: Understanding relationships like “left of,” “behind,” and predicting object positions in 3D from a single image.
- Code: Text‑only coding and multimodal coding (like turning UI screenshots into HTML/CSS, or converting diagrams to markup).
- Video: Dense captions, time‑aware grounding, and balanced sampling to capture both short moments and long stories.
- STEM reasoning: Millions of math and science exercises, diagrams, and step‑by‑step solutions to strengthen problem‑solving.
- Agents and tools: Data for interacting with apps (GUIs), calling functions (like search), and planning multi‑step tasks.
Post‑Training (polishing the model)
After pretraining, they fine‑tune the model for real tasks:
- Supervised Fine‑Tuning (SFT): Teaching the model to follow instructions, including “thinking” versions that show their reasoning steps, and “non‑thinking” versions that go straight to answers.
- Distillation: A stronger teacher model guides a smaller student model, helping it learn good reasoning from text without hurting vision skills.
- Reinforcement Learning (RL): The model practices tasks where answers can be checked (like math or grounding), and gets feedback to improve accuracy and alignment to user preferences.
Main Findings and Why They Matter
- Stronger language skills: Qwen3‑VL often beats similar text‑only models on language tests, showing that adding vision doesn’t weaken reading or writing—it can even help.
- Leading visual reasoning: It performs very well on tough multimodal benchmarks involving images, diagrams, and videos, including math‑related visual tasks.
- Long‑context mastery: With a native 256K token window, it can ingest and recall information across very long documents and videos, keeping track of multiple references and cross‑links.
- Flexible sizes and speed: From smaller dense models to large MoE versions, you can choose a model that fits your speed and quality needs. The flagship MoE (235B total, ~22B active per token) leads on many tasks while managing latency.
Overall, under similar training budgets and speed limits, Qwen3‑VL outperforms other models in both text and multimodal work.
Implications and Potential Impact
Qwen3‑VL can be a strong foundation for many real‑world tools:
- Reading and summarizing long documents or textbooks, and understanding the figures inside them.
- Watching and analyzing long videos, finding events by time, and explaining what happens.
- Solving math and science problems that involve diagrams or multi‑step reasoning.
- Acting as an agent that understands app screens (GUIs), plans actions, and uses tools like web search.
- Bridging visuals and code, turning screenshots or diagrams into working markup or programs.
In simple terms: this model helps computers see, read, and think together—at scale. That makes smarter assistants possible for schoolwork, research, creative projects, and complex workflows where understanding both text and visuals—and doing it over long spans—really matters.
Knowledge Gaps
Below is a single, concrete list of the paper’s knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Interleaved MRoPE specifics and ablations: The paper claims improved long-video modeling with interleaved t/h/w frequency allocation but provides no formal specification (exact dimension allocations, frequency schedules) or ablations isolating its impact across image, multi-image, and video tasks—especially under ultra-long contexts.
- DeepStack design trade-offs: Details are missing on which ViT layers feed which LLM layers, the merger configurations per level, and the quantitative impact on latency, memory, and stability; no ablations vary the number/placement of injected layers or compare additive vs. concatenative fusion.
- KV-cache compatibility and inference cost: It is unclear how multi-layer visual token injection (DeepStack) affects KV caching, attention caching reuse, streaming, and 256K-window inference throughput; no measurements of memory footprint, latency, or batching efficiency are provided.
- Text-based timestamp tokens efficacy: The timestamp strategy adds tokens and claims better temporal grounding, but there is no analysis of overhead, accuracy under variable fps, dropped/duplicated frames, or robustness to non-uniform sampling; comparisons to alternative time encodings (e.g., learned temporal embeddings, discretized bins) are absent.
- Loss reweighting clarity: The “square-root-normalized per-token loss” lacks a formal definition, sensitivity analyses (to mixture proportions), and ablations showing its effect on text vs. multimodal performance and on catastrophic forgetting across stages.
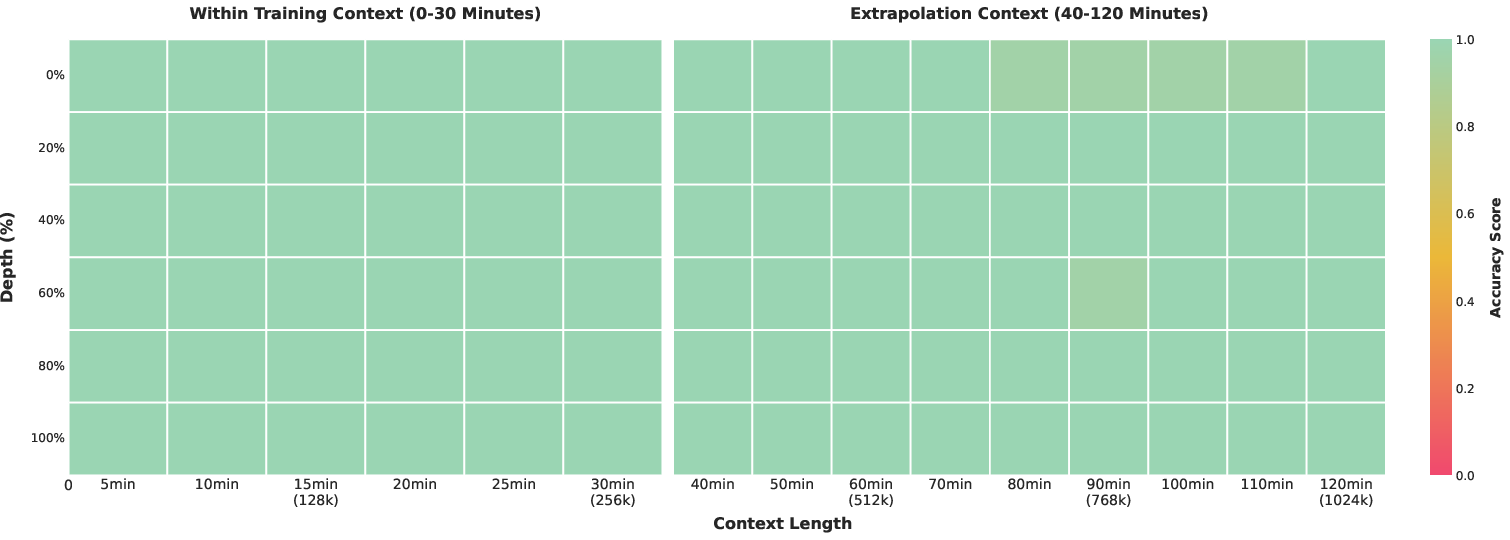
- Long-context stability and retention: Despite a 256K window, there are no quantitative retention/faithfulness evaluations (e.g., needle-in-haystack, cross-referencing across interleaved image/video-text) nor training stability diagnostics (gradient norms, optimizer schedules, context-length curriculum effects).
- Compute, energy, and reproducibility: Training compute (FLOPs), hardware setup, optimizer/hyperparameters per stage, checkpointing/memory strategies, and energy/carbon costs are not reported, hindering reproducibility and scalability assessments.
- Data transparency and licensing: Large internal corpora and synthesized datasets (OCR, documents, GUI, video, STEM, 3D grounding) lack source/licensing disclosure, demographic/topic coverage statistics, and contamination checks against evaluation sets.
- Bias and fairness assessments: No auditing or evaluation is provided for demographic bias, domain imbalance, or regional bias in multimodal and text-only data mixtures, nor fairness across languages, scripts, and cultural contexts—especially beyond Chinese and English.
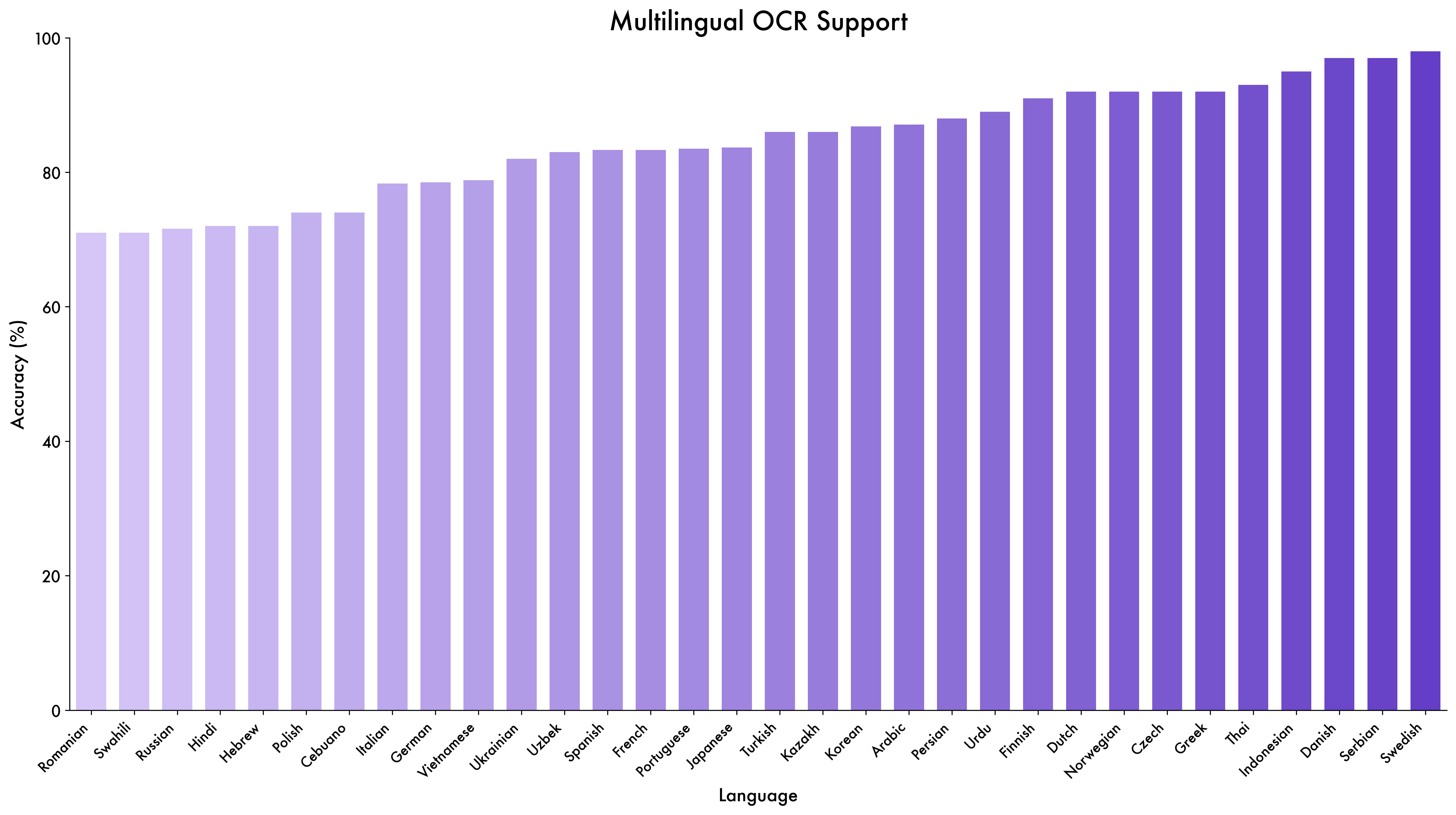
- Multilingual generalization: Apart from OCR in 29 additional languages, the extent of multilingual VL capabilities (VQA, grounding, document parsing, STEM) and cross-lingual transfer are not evaluated; language-specific performance and error analysis are missing.
- OCR quality and scope: The OCR pipeline relies on pseudo-labels without human annotation; there is no breakdown of accuracy across scripts (e.g., Arabic, Devanagari), curved/rotated text, low-light/motion blur, or complex layouts, nor standardized metrics (CER/WER by domain).
- Document parsing robustness: The unified QwenVL-HTML/Markdown framework lacks evaluations on real-world heterogeneity (multi-column reading order, forms, footnotes, equations, cross-page references) and fails to report layout fidelity metrics or error modes.
- Grounding metrics and normalized coordinates: Using coordinates scaled to [0,1000] promises robustness, but there is no calibration analysis across aspect ratios/resolutions, nor clear evaluation protocols for crowded scenes, occlusions, small objects, and point-vs-box agreement.
- 3D grounding from single view: The feasibility of predicting 9-DoF boxes from monocular images is asserted without reporting camera intrinsics handling, error metrics (e.g., 3D IoU, orientation error), sensitivity to noise, or cross-dataset generalization in the virtual camera space.
- Video modeling omissions: Audio is not mentioned; multimodal (audio–video–text) integration, ASR alignment, and audio-grounded reasoning remain unexplored; long-video summarization/retrieval metrics and genre-specific performance are not reported.
- STEM generalization and leakage: Heavy reliance on synthetic/programmatically generated diagrams and K–12/undergrad exercises raises questions about template overfitting, data leakage to benchmarks (MathVista, MathVision), and robustness to unconventional, noisy, or research-level problems.
- Chain-of-thought (CoT) side effects: While thinking variants are trained on long CoT, there is no analysis of verbosity control, hallucination rates in reasoning steps, or privacy risks (revealing training data) nor measures to avoid spurious long reasoning when unnecessary.
- Agentic GUI capabilities: Trajectories are partially synthetic and audited, but there is no online, executable evaluation showing success rates on unseen apps, robustness to UI changes, prompt-injection/image-injection attacks (e.g., malicious UI elements), or safety constraints (e.g., avoiding destructive actions).
- Function calling and search reliability: The function-calling trajectories use non-executable synthesized functions; there is no ground-truth verification of tool outputs, assessment of hallucinated tool responses, or study of integrating real tool execution to improve faithfulness.
- Distillation interactions with VL: Strong-to-weak distillation is performed on text-only data; the paper does not evaluate whether this shifts or degrades vision–language alignment, nor provide ablations balancing text-only vs. VL distillation.
- Robustness to OOD and adversarial inputs: There is no evaluation under domain shifts (egocentric vs. cinematic), noise/blur/compression, adversarial images (patches, stickers, steganography), or video corruptions; defenses against image-/video-based jailbreaks are not discussed.
- Safety, privacy, and content moderation: Aside from filtering out “harmful or low-value categories,” there is no systematic safety alignment evaluation (toxicity, adult content in images, face/PII recognition risks), red-teaming results, or privacy safeguards for internal data.
- Mixture-of-experts (MoE) routing details: The MoE models’ expert routing, capacity, load-balancing losses, and failure cases (expert collapse, token imbalance) are not disclosed; latency/throughput under multimodal interleaving and KV-cache compatibility are unreported.
- Evaluation transparency: Claims of “leading performance” are not backed (in this text) by per-benchmark scores, baselines, statistical significance, or error analyses across text, image, multi-image, and video tasks under comparable token budgets/latencies.
- Deployment constraints at 256K: Practical inference constraints (GPU memory per batch, streaming/chunked attention support, sliding-window strategies, early-exit policies, batch-size limits) and cost–quality trade-offs across 2B–235B models are not quantified.
- Impact of dynamic-resolution vision encoding: The combination of 2D-RoPE and absolute position interpolation is introduced without stress tests on extreme resolutions/aspect ratios, heavy crops/zoom, or scaling failures; no ablations compare alternative interpolation strategies.
- Data curation feedback loops: Many datasets are generated or filtered using prior Qwen models; the paper does not analyze amplification of pre-existing biases, error propagation, or the effect of model-generated labels on downstream evaluation fairness and reliability.
Glossary
- 2D-RoPE: A two-dimensional variant of rotary positional encoding that encodes positions across height and width for vision inputs. "we employ 2D-RoPE and interpolate absolute position embeddings based on input size"
- 3D Grounding: The task of localizing and referencing objects in three-dimensional space from visual inputs. "a specialized pretraining dataset for 3D visual grounding"
- 9-DoF 3D bounding box: A 3D box parameterization with nine degrees of freedom (position, orientation, and scale) used to annotate object poses. "the corresponding 9-DoF 3D bounding box annotations"
- Agentic: Pertaining to models or systems capable of autonomous decision-making and action planning in workflows. "agentic workflows"
- Chain-of-Thought (CoT): A training and prompting technique that elicits explicit step-by-step reasoning traces from models. "Long Chain-of-Thought (CoT) cold start dataset"
- DeepStack: A cross-layer fusion mechanism that injects multi-level visual tokens into corresponding LLM layers via residual connections. "we incorporate the pioneering DeepStack mechanism"
- Function Calling (Multimodal): A capability where the model selects and executes tool functions conditioned on visual and textual context. "a multimodal function calling trajectory synthesis pipeline"
- Grounding DINO: An open-vocabulary object detector used to localize and annotate objects with text prompts. "open-vocabulary detectors (specifically, Grounding DINO)"
- Interleaved MRoPE: A positional encoding scheme that interleaves temporal, horizontal, and vertical rotary frequencies across embedding dimensions. "we adopt Interleaved MRoPE to encode positional information"
- Knowledge Distillation: A training technique where a student model learns from outputs of a stronger teacher model. "The second stage employs knowledge distillation"
- KL Divergence: A measure of difference between two probability distributions used to align student and teacher logits. "by minimizing the KL divergence"
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of expert submodels to balance quality and latency. "mixture-of-experts (MoE) models"
- MLP-based Vision–Language Merger: A module that projects visual features into the LLM’s hidden space to create visual tokens. "MLP-based vision–language merger"
- MRoPE: Multimodal rotary positional encoding applied across text and vision axes (temporal, horizontal, vertical). "we used MRoPE as a unified positional encoding scheme for text and vision"
- Normalized coordinate system: A coordinate representation scaled to a fixed range to improve robustness across resolutions. "we adopt a normalized coordinate system scaled to the range "
- Off-policy Distillation: A distillation phase where student models learn from teacher-generated outputs not produced by the student’s own policy. "Off-policy Distillation: In the first phase, outputs generated by teacher models are combined"
- On-policy Distillation: A distillation phase where the student generates responses and is fine-tuned on its own outputs aligned to the teacher. "On-policy Distillation: In the second phase, the student model generates the responses"
- Open-vocabulary detector: A detector that recognizes and localizes categories beyond a fixed label set using text prompts. "open-vocabulary detectors (specifically, Grounding DINO)"
- QwenVL-HTML: A document parsing format with fine-grained, element-level bounding boxes for layout-aware annotations. "QwenVL-HTML, which includes fine-grained, element-level bounding boxes"
- QwenVL-Markdown: A document parsing format that localizes images and tables, encoding tables in LaTeX. "QwenVL-Markdown, where only images and tables are localized"
- Reinforcement Learning (RL): An optimization paradigm where models learn by receiving rewards for correct or preferred behaviors. "Reinforcement Learning (RL)."
- SigLIP-2: A vision encoder architecture trained with a contrastive objective, adapted here for dynamic resolutions. "We utilize the SigLIP-2 architecture"
- Square-root reweighting: A data balancing strategy that scales losses to boost multimodal performance without harming text capabilities. "we apply square-root reweighting"
- Square-root-normalized per-token loss: A loss formulation that normalizes per-token contributions by a square-root factor to balance modalities. "move from a per-sample loss to a square-root-normalized per-token loss"
- Strong-to-Weak Distillation: A pipeline where capabilities from a strong teacher are transferred to lightweight student models. "We adopt the Strong-to-Weak Distillation pipeline"
- T-RoPE: A time-aware variant of rotary positional encoding used for temporal alignment in video sequences. "evolving from T-RoPE to explicit textual timestamp alignment"
- Ultra-Long-Context Adaptation: A training stage that extends the model’s operational sequence length to hundreds of thousands of tokens. "Ultra-Long-Context Adaptation"
- ViT (Vision Transformer): A transformer-based vision model that processes images as tokenized patches across layers. "Vision Transformer (ViT)"
- Video Grounding: The task of temporally and spatially localizing events or objects within video sequences. "video grounding and dense captioning"
- Video Timestamp tokens: Explicit textual markers inserted to denote frame group times for improved temporal modeling. "introduce text-based timestamp tokens"
- Virtual camera coordinate system: A unified coordinate frame used to standardize multi-source 3D annotations. "to unify all data into a virtual camera coordinate system"
- Visual Grounding: The capability to identify and localize referenced objects or regions in images. "Visual grounding is a fundamental capability for multimodal models"
- Visual Question Answering (VQA): A task where a model answers questions about visual content, often requiring reasoning. "visual question answering (VQA)"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, directly leveraging Qwen3‑VL’s 256K interleaved context, multilingual OCR and document parsing, explicit video time alignment, advanced grounding/counting, multimodal coding, GUI-agent data, and function-calling workflows. Each item lists sectors, potential tools/products/workflows, and feasibility notes.
- Enterprise-grade document OCR and parsing to structured formats
- Sectors: finance, legal, government services, healthcare administration
- Tools/workflows: PDF-to-HTML/Markdown/LaTeX converters; invoice/receipt/KYC extraction pipelines; compliance dossier ingestion; EHR attachment ingestion; multimodal ETL (images + text)
- Assumptions/dependencies: privacy and PII policies; table/diagram fidelity may need domain fine-tuning; long-context processing costs and latency; human-in-the-loop validation for critical workflows
- Long-document question answering and cross-referencing (native 256K tokens)
- Sectors: enterprise knowledge management, legal e-discovery, research teams, policy analysis
- Tools/workflows: document copilots that retain page order and figures; multi-document thread readers; meeting/report Q&A assistants with exact page/figure citations
- Assumptions/dependencies: GPU memory/throughput for 256K contexts; retrieval strategies for very large corpora; source-grounding and citation audit trails
- Cross-platform GUI automation and RPA with visual grounding
- Sectors: IT operations, customer support, back-office operations, QA/testing
- Tools/workflows: agents that perceive UI elements, plan actions, and complete multi-step tasks; test harnesses that validate UI flows via screenshots; screenshot-to-action runbooks
- Assumptions/dependencies: access control/sandboxing; reliability under UI changes; fallback/oversight and auditability; latency/quality model selection (2B/4B for speed, 32B/MoE for robustness)
- Screenshot-based support triage and resolution suggestions
- Sectors: IT helpdesk, SaaS support, consumer apps
- Tools/workflows: parse error dialogs, logs, and configuration screens to generate reproductions and fixes; enrich tickets with grounded evidence (bounding boxes/points)
- Assumptions/dependencies: secure redaction of sensitive data; integration with ticketing systems; domain-tuned knowledge bases
- Multimodal coding: design-to-code and diagram-to-markup
- Sectors: software/UX, documentation, education
- Tools/workflows: UI screenshot to responsive HTML/CSS; chart/diagram to LaTeX/SVG; flowchart-to-code; image-grounded code Q&A inside IDEs
- Assumptions/dependencies: style/framework conformity; post-processing linters and tests; human review for production code; dataset alignment to target tech stacks
- Time-aligned video summarization and indexing (explicit timestamps)
- Sectors: media, enterprise training/compliance, education
- Tools/workflows: generate timeline summaries with timecodes; chaptering for lectures/tutorials; searchable indices for long videos; meeting/call recaps with precise references
- Assumptions/dependencies: rights management; compute costs for long videos; quality varies with domain (studio vs. egocentric footage)
- Video Q&A and spatio-temporal grounding
- Sectors: L&D, customer education, quality assurance
- Tools/workflows: “Ask this video” assistants that locate when/where an event occurs; instruction video checklists that verify procedural steps with timestamps
- Assumptions/dependencies: training distributions vs. deployment domain; ambiguous scenes may require confidence thresholds and user confirmation
- Visual counting and inventory auditing
- Sectors: retail, logistics, manufacturing
- Tools/workflows: shelf audit apps; parts/asset counts from images; point-based/box-based counting with normalized coordinates for robustness
- Assumptions/dependencies: lighting/occlusion robustness; calibration to scene specifics; periodic spot checks and escalation paths
- Asset localization and affordance-aware guidance from photos
- Sectors: field service, manufacturing, smart buildings
- Tools/workflows: locate valves/switches/tools; suggest feasible actions (“pressable,” “graspable”) and ordering of steps in 2D scene
- Assumptions/dependencies: domain imagery for fine-tuning; safety guardrails; integration with AR overlays or mobile workflows
- Multilingual OCR-based translation and accessibility
- Sectors: public sector, travel, education, media
- Tools/workflows: real-time sign/label translation; alt-text generation for images and charts; reading-order aware document accessibility
- Assumptions/dependencies: device compute for on-device variants; guardrails for sensitive content; accuracy checks for critical materials
- STEM tutoring with diagrams and step-by-step reasoning
- Sectors: education (K–12, undergraduate), tutoring platforms
- Tools/workflows: multimodal solvers that parse diagrams and produce CoT solutions; interactive hints tied to figure regions; auto-generated practice problems
- Assumptions/dependencies: alignment to curricula and rubrics; safeguards against misuse/cheating; verification of final answers
- Report and figure extraction for analytics
- Sectors: energy, finance, industrials, life sciences
- Tools/workflows: extract tables/figures and link them to textual claims; cross-figure comparisons across hundreds of pages; build structured knowledge bases
- Assumptions/dependencies: citation fidelity and traceable evidence; domain lexicons and ontologies; human validation for high-stakes decisions
Long-Term Applications
These applications are enabled by Qwen3‑VL’s spatial/temporal reasoning, 3D grounding, GUI-agent trajectories, long-context comprehension, and multimodal coding, but will require additional research, scaling, integration, or validation.
- Embodied robotics with spatial reasoning and 3D grounding
- Sectors: robotics, logistics, advanced manufacturing
- Tools/workflows: vision-language policies that infer affordances, plan grasps, and execute pick-and-place from single images; language-grounded 3D localization for manipulation
- Assumptions/dependencies: real-time latency on edge hardware; sim-to-real transfer; safety and certification; extensive domain data and feedback loops
- Autonomous GUI agents for complex digital workflows
- Sectors: enterprise automation, finance ops, HR, procurement
- Tools/workflows: “self-operating computer” agents that browse, fill forms, reconcile records, and call APIs and search tools; governance dashboards
- Assumptions/dependencies: robust function-calling ecosystems; strong observability/rollback; identity and secrets management; policy/ethics frameworks
- Video analytics for operational monitoring
- Sectors: manufacturing, transportation, utilities
- Tools/workflows: long-horizon event detection (process deviations, safety compliance) with precise time grounding; automated audit trails
- Assumptions/dependencies: domain-labeled video corpora; integration with MES/SCADA; low false positive/negative rates; privacy constraints
- AR/VR scene understanding and spatial anchoring
- Sectors: consumer AR, field service, training
- Tools/workflows: single-image 3D grounding to place virtual content accurately; on-device summarization of scenes; contextual assistance overlays
- Assumptions/dependencies: mobile/edge optimization; sensor fusion (IMU/LiDAR) for robustness; consistent calibration and lighting handling
- Cross-document scientific and patent analysis with figure grounding
- Sectors: academia, R&D, IP strategy
- Tools/workflows: assistants that connect claims to figures/tables across massive corpora; hypothesis mapping; prior-art synthesis at scale
- Assumptions/dependencies: strong source attribution, confidence scoring, and de-duplication; mitigation of hallucinations; publisher policy compliance
- Clinical video and imaging assistance
- Sectors: healthcare
- Tools/workflows: surgical video timeline summaries; timestamped detection of procedural steps; educational annotation of procedures
- Assumptions/dependencies: rigorous clinical validation; regulatory approval (e.g., FDA/CE); HIPAA/GDPR compliance; domain-specific training and bias analysis
- Legal and policy analysis over proceedings and exhibits
- Sectors: government, legal services
- Tools/workflows: long-hearing/meeting summarization with timecodes; cross-referencing attachments, exhibits, and transcripts; draft-generation assistants
- Assumptions/dependencies: fairness and bias auditing; chain-of-custody and auditing; acceptance by courts/regulators; transparency requirements
- Multimodal software copilot from sketch to app
- Sectors: software engineering, low-code/no-code
- Tools/workflows: pipeline that turns whiteboard/UI sketches and requirements into skeleton apps, tests, and deployment scripts; visual diffs-to-patches
- Assumptions/dependencies: secure code generation; integration with CI/CD and test coverage; IP/compliance checks; human code review
- Privacy-first lifelog assistants for wearable video
- Sectors: consumer, eldercare, quantified self
- Tools/workflows: daily timeline summaries, object interactions, and memory cues with time grounding; “find when I did X” queries
- Assumptions/dependencies: strong on-device models or secure enclaves; consent and bystander privacy; customizable retention/deletion policies
- Warehouse and inventory robotics with multi-camera fusion
- Sectors: retail, logistics, e-commerce
- Tools/workflows: continuous counting, location mapping, and exception handling; integration with WMS/ERP
- Assumptions/dependencies: infrastructure (cameras, networking); calibration and maintenance; worker safety and union compliance
- Automated grading and feedback for diagrammatic assessments
- Sectors: education and training
- Tools/workflows: grader assistants for diagram-based answers and lab notebooks; rubric-aligned, step-by-step feedback
- Assumptions/dependencies: fairness and transparency; alignment to standards/accreditation; dataset curation for subject coverage
- Multimodal redaction and compliance auditing
- Sectors: finance, government, legal, healthcare
- Tools/workflows: detection and redaction of PII in scanned documents and videos; compliance checkers that link rules to visual evidence
- Assumptions/dependencies: policy rule integration; extremely low error tolerance; comprehensive logging and human oversight
Notes on Deployment Choices and Risk Mitigation
- Model variants and latency/quality trade-offs: smaller dense models (2B/4B/8B) suit edge or low-latency tasks; 32B/MoE variants fit high-stakes or complex reasoning with higher compute costs.
- Thinking vs. non-thinking variants: use “thinking” for complex, multi-step reasoning (STEM, planning) and non-thinking for efficiency in straightforward tasks.
- Tooling ecosystem: many applications depend on function-calling, search integration, RPA frameworks, and data governance pipelines.
- Reliability and safety: long-context processing and multimodal reasoning reduce chunking errors but do not eliminate hallucinations; human-in-the-loop review, calibration sets, and monitoring are essential.
- Data and domain adaptation: performance in specialized domains (clinical, industrial, legal) improves with domain-tuned data, evaluation harnesses, and alignment to regulatory standards.
Collections
Sign up for free to add this paper to one or more collections.

