Qianfan-VL: Domain-Enhanced Universal Vision-Language Models
Abstract: We present Qianfan-VL, a series of multimodal LLMs ranging from 3B to 70B parameters, achieving state-of-the-art performance through innovative domain enhancement techniques. Our approach employs multi-stage progressive training and high-precision data synthesis pipelines, which prove to be critical technologies for enhancing domain-specific capabilities while maintaining strong general performance. Qianfan-VL achieves comparable results to leading open-source models on general benchmarks, with state-of-the-art performance on benchmarks such as CCBench, SEEDBench IMG, ScienceQA, and MMStar. The domain enhancement strategy delivers significant advantages in OCR and document understanding, validated on both public benchmarks (OCRBench 873, DocVQA 94.75%) and in-house evaluations. Notably, Qianfan-VL-8B and 70B variants incorporate long chain-of-thought capabilities, demonstrating superior performance on mathematical reasoning (MathVista 78.6%) and logical inference tasks. All models are trained entirely on Baidu's Kunlun P800 chips, validating the capability of large-scale AI infrastructure to train SOTA-level multimodal models with over 90% scaling efficiency on 5000 chips for a single task. This work establishes an effective methodology for developing domain-enhanced multimodal models suitable for diverse enterprise deployment scenarios.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Qianfan-VL: A Simple Explanation
1) What is this paper about?
This paper introduces Qianfan-VL, a family of smart computer models that can understand both images and text. They are built to be good at everyday tasks and also extra good at specific jobs like reading text in pictures (OCR), understanding documents (like invoices and PDFs), and solving math problems with diagrams. The models come in three sizes (about 3B, 8B, and 70B parameters), and they were trained using a special plan to improve these “domain” skills without losing general abilities.
2) What questions did the researchers want to answer?
The team focused on three simple goals:
- Can we train a vision-LLM that is strong at general tasks and also excellent at specific jobs like OCR, documents, charts, and math?
- Can we create large amounts of high-quality practice data for those specific jobs automatically?
- Can we prove that training huge models on our own hardware (Kunlun P800 chips) scales efficiently?
3) How did they build and train the models?
Think of the model like a student with three parts:
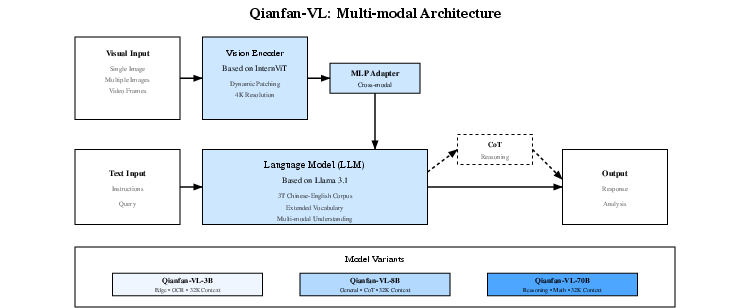
- Eyes: a “vision encoder” that turns pictures into numbers the model can understand.
- Brain: a “LLM” that reads text, reasons, and writes answers.
- Translator: a “cross-modal adapter” that helps the eyes and brain talk to each other smoothly.
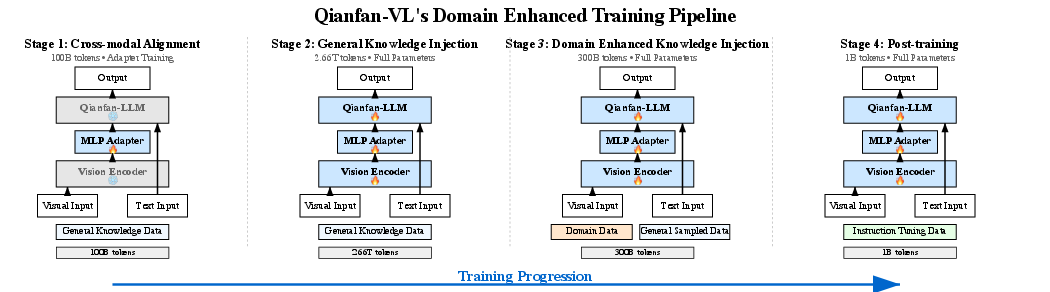
They used a four-stage “school plan” to train the models:
- Stage 1: Learn to connect vision with language Like learning how to describe what you see, they trained only the adapter (the translator) while keeping the eyes and brain frozen. This makes the connection stable and avoids confusion later.
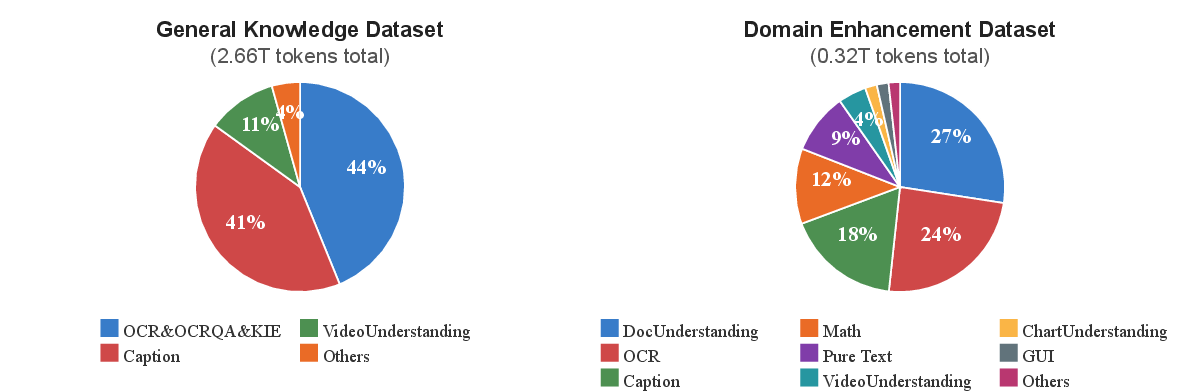
- Stage 2: Absorb general knowledge The whole model studies a massive amount of mixed data (pictures, captions, videos, questions) to become broadly smart.
- Stage 3: Extra classes for special skills The model gets focused training on important areas: OCR, document understanding, tables, charts, formulas, and math. They still mix in some general data so it doesn’t forget what it learned before.
- Stage 4: Practice following instructions and showing work
The model trains with complex instructions and learns long “chain-of-thought” reasoning. This is like writing out step-by-step solutions. They even use special tokens like
"> "and""to mark reasoning steps.
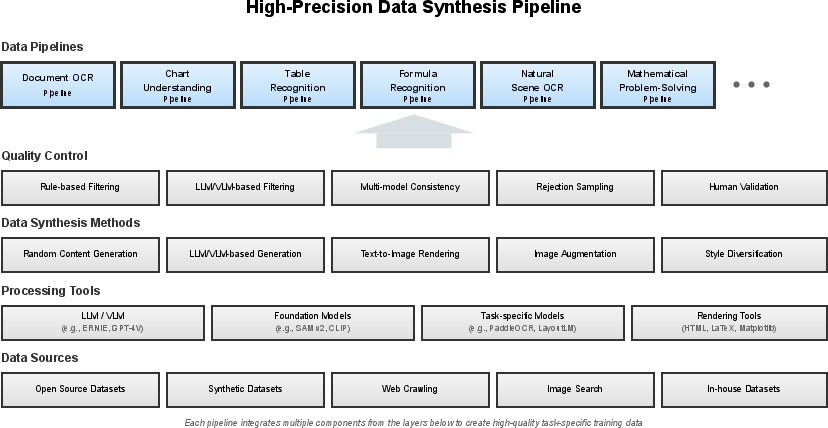
To create enough training material, they built data “factories” (pipelines) that:
- Make realistic documents with different layouts, languages, and noise (like blur and stains).
- Generate math problems from school level up to university, with step-by-step solutions.
- Produce charts and questions that require reading values and reasoning about trends.
- Render tables with complex structures (merged cells, headers) and questions about them.
- Produce formulas and their meanings, including handwritten styles.
- Embed text naturally into everyday scenes (signs, menus, labels) in many languages.
Finally, they trained everything on large clusters of Kunlun P800 chips (over 5000 at once), using smart parallel strategies to keep efficiency high.
4) What did they find, and why does it matter?
Here are the most important results, explained simply:
- Strong general skills: Qianfan-VL performs competitively on many standard tests that check if a model understands images and answers questions correctly.
- Best-in-class in key areas: It reaches top or near-top scores on several benchmarks, especially:
- Document understanding (DocVQA around 94.75%)
- OCR (OCRBench score up to 873)
- Science and reasoning tasks (ScienceQA up to about 98.8%)
- Math with visuals (MathVista up to 78.6%)
- Chain-of-thought boosts reasoning: The 8B and 70B versions show clear improvements on math and logical tasks when they are trained to “show their work” step by step.
- Domain training works: When they add the Stage 3 “extra classes,” performance increases across OCR, documents, and math without hurting general ability.
Why it matters:
- Businesses need models that don’t just “see” pictures but can read them like documents, extract key information, and reason with charts and tables. Qianfan-VL is designed exactly for that.
- The results show you can improve special skills without breaking general intelligence.
- Training at scale on proprietary chips proves you can build strong models without relying on external hardware.
5) What is the impact and what comes next?
Practical impact:
- Faster, more accurate document processing: contracts, invoices, reports, forms.
- Better help with math and visual reasoning: tutoring, grading, and analytics.
- Smarter business tools: reading charts, extracting numbers, and answering complex questions about visual data.
Limitations and future plans:
- Current context length is 32K tokens, so very long documents or long chats are hard. They plan to extend this (e.g., to 128K+) and make the models more efficient for devices with limited power.
- The models are great at images and text, but still need more training for video, 3D understanding, and time-based reasoning.
- They plan to make lighter versions for edge devices, support more languages, and build specialized variants for areas like medicine or engineering.
In short, Qianfan-VL shows a clear way to build vision-LLMs that are both generally capable and specially skilled. This helps turn AI research into tools that can handle real-world tasks in schools, offices, and industries.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Data transparency and reproducibility: The paper does not disclose dataset sizes per category, licensing status, or the exact composition/sources of proprietary and synthesized data; a data card with statistics (per-domain/per-language), licensing, and contamination checks is missing.
- Benchmark contamination risk: No procedure is described to detect/remove overlap between training data (including synthesized or crawled content) and evaluation benchmarks (e.g., DocVQA, MathVista, ChartQA, MMStar), leaving SOTA claims vulnerable to leakage concerns.
- Multilingual coverage and fairness: Despite training on “multilingual mixed data” and scene OCR in 12+ languages, there is no per-language evaluation, script coverage analysis (e.g., Arabic, Devanagari, Thai), or fairness bias assessment across languages and writing systems.
- Safety and privacy for OCR/document tasks: No evaluations on PII exposure, redaction robustness, content filtering, or compliance for sensitive documents; policies for handling regulated data (financial, medical) are unspecified.
- Hallucination and faithfulness: Beyond POPE and HallusionBench, there is no deeper analysis of visual hallucinations, justification faithfulness, or attribution in document/math reasoning outputs.
- LLM-as-a-judge validity: The claimed >95% judge accuracy with Ernie-4.5-Turbo-VL is not supported with calibration methodology, inter-annotator agreement, bias analysis, or release of a validation set for external replication.
- CoT faithfulness and exposure: The > token mechanism lacks evaluation of reasoning faithfulness (are intermediate steps correct and causally used?) and guarantees that hidden chains cannot leak to users or logs across deployment stacks.
- CoT efficiency trade-offs: No measurements of inference-time/latency overhead, token-length growth, or user-controllable accuracy/latency trade-offs when enabling
"<think>...".
- CoT efficiency trade-offs: No measurements of inference-time/latency overhead, token-length growth, or user-controllable accuracy/latency trade-offs when enabling
Reward/process supervision details: The reward models and process-supervision criteria for selecting CoT solutions are not described (model architecture, training data, target signals), hindering reproducibility and assessment of biases.
- Underperformance diagnosis on MMMU/MMVet: The paper attributes gaps to “insufficient coverage,” but provides no controlled ablations, data augmentation experiments, or error taxonomy to confirm causes or guide data mixture remedies.
- Model merging methodology: The “model merging” step lacks specifics (algorithm, layer-wise strategy, coefficient selection, compatibility constraints), ablations, and reproducibility artifacts.
- Hyperparameters and training schedule: Critical training details (optimizer, LR schedule, batch sizes, gradient clipping, warmup, regularization, exact curriculum schedule, stopping criteria) are absent, obstructing replication.
- Vision tiling aggregation: The dynamic 448×448 tiling method does not specify how tile embeddings are aggregated, ordered, or positionally aligned across tiles/pages, nor the effect on long-text/long-page reading order.
- Multi-page document handling: It is unclear how multi-page PDFs are represented (image pagination strategy, inter-page linking), how the 32K context is budgeted across pages, and how performance scales with page count.
- Video understanding gap: Although video data is used in training, no video architecture details (temporal modeling, frame sampling, fusion) nor video benchmarks are provided; temporal reasoning/3D motion understanding remain unevaluated.
- 3D spatial reasoning: The paper notes the lack of 3D capabilities but offers no interim experiments (e.g., synthetic 3D scenes) or architectural plans for 3D-aware encoders and evaluation protocols.
- Table structure evaluation: Table-to-HTML/LaTeX reconstruction is claimed but only in-house metrics are reported; public, standardized evaluations (e.g., PubTables-1M structure recovery) and exact scoring criteria are not provided.
- Mathematical diagram grounding: The math pipeline mentions Asymptote/LaTeX rendering but does not evaluate geometric diagram parsing/grounding (e.g., symbol-to-entity mapping, figure-text alignment) on public benchmarks.
- Robustness to document noise and shifts: Augmentations are described, but there is no robustness evaluation under realistic degradations (extreme blur, skew, low-light scans, compression), unseen document templates, or adversarial text overlays.
- Generalization to unseen domains: No targeted out-of-distribution tests (e.g., novel form layouts, previously unseen chart types, rare scripts) are reported to quantify domain-specific overfitting vs. genuine generalization.
- GUI understanding: The training mixture includes GUI tasks, yet there are no benchmarks (e.g., screen QA, UI grounding) to quantify performance and practical utility for RPA or UI agents.
- KIE (key information extraction): Despite substantial KIE data in Stage 2, there is no dedicated evaluation on KIE benchmarks (form/receipt/ID extraction) or metrics like field-level precision/recall and schema generalization.
- Instruction-following complexity: The “complex instruction” synthesis (~200K) lacks difficulty stratification and ablations (with/without multi-constraint data), and no public benchmarks for multi-constraint OCR/math/DocQA are used to validate gains.
- Long-context scaling: While 32K context is supported, there is no stress test of multi-image + long-text co-reasoning, nor analysis of context fragmentation, retrieval, or hierarchical strategies within current limits.
- Deployment performance: Claims about edge/server/cloud targets lack measured latency, throughput, memory footprints, and cost-per-token across model sizes and typical workloads (e.g., multi-page OCR, math CoT).
- Quantization and distillation: Future plans are stated, but the current models provide no empirical results on 4–8 bit quantization or distilled variants, and no accuracy–efficiency trade-off curves.
- Hardware portability and reproducibility: Training is specialized for Kunlun P800 with custom communication-compute fusion; portability to mainstream GPUs/TPUs, performance parity, and open tooling are not addressed.
- Energy and carbon reporting: No training/inference energy, carbon footprint, or cost estimates are provided, limiting sustainability assessment and comparison.
- Security and prompt injection: There is no evaluation of robustness to malicious content (prompt injections within images/documents), jailbreak attempts, or steganographic attacks in OCR-heavy pipelines.
- Ethical sourcing and bias in synthetic data: The large use of synthesized content is not accompanied by audits for demographic bias, stereotype amplification, or error propagation from teacher models (e.g., DeepSeek-R1) into student behaviors.
- Licensing and release plan: It is unclear whether model weights, data pipelines, or checkpoints (Stage 2/3) will be released under what licenses, limiting community validation and downstream research.
- Comparative cost-effectiveness: No standardized cost-versus-quality comparison against peer open models (e.g., tokens to reach a target accuracy, inference ms/query at a given resolution) is reported.
- Ablations per training stage: Although an ablation on Stage 3 is provided, there are no ablations for Stage 1 (adapter-only alignment vs partial unfreeze), Stage 2 (mixture ratios), or Stage 4 (instruction data composition, CoT proportion), nor interactions among stages.
- Failure-mode taxonomy: Beyond high-level benchmark scores, there is no qualitative error analysis for OCR (character/word-level), table/structure errors, or math reasoning (algebraic slips vs. diagram parsing vs. numeric calculation).
- Document grounding and citation: For document Q&A, the model’s ability to cite spans/regions (token/box-level grounding) and support verifiable answers is not evaluated.
- Multi-image and interleaved tasks: The ability to reason over multiple related images (e.g., cross-page references, charts + tables) and interleaved text-image sequences is not benchmarked.
- Modality extension: Audio, speech, and layout-aware PDF ingestion (native PDF structure vs. image-rasterized pages) are not covered; it is unclear how hard-copy vs. born-digital PDFs differ in performance.
- Legal/compliance implications: The paper does not discuss compliance with data protection laws (e.g., GDPR/CCPA) for OCR content, retention policies, or on-device processing strategies to minimize data exposure.
Practical Applications
Immediate Applications
The following bullet points summarize practical, deployable use cases that can be implemented now using the Qianfan-VL models and their training/data pipelines.
- Enterprise document automation [sectors: finance, insurance, logistics, public sector, legal, healthcare]
- Use case: End-to-end processing of invoices, contracts, delivery notes, claim forms, medical intake forms, and government applications with OCR, key information extraction (KIE), layout understanding, and summarization.
- Tools/products/workflows: Document-to-Markdown/HTML converter API; “DocAI” pipelines that run image tiling → OCR/KIE → CoT-based validation → structured export (JSON/Markdown/HTML); ERP/claims system plugins that auto-populate fields and attach summaries.
- Assumptions/dependencies: High-quality scans or camera input; domain-specific fine-tuning via Stage 3/4 recommended; data governance for PII/PHI; compliance alignment (e.g., HIPAA, GDPR).
- Chart and table intelligence for business reports [sectors: BI/software, finance, consulting, manufacturing]
- Use case: Extract values, trends, anomalies, and perform computational Q&A on embedded charts and tables in presentations and PDFs; table-to-HTML/LaTeX conversion for downstream analytics and reformatting.
- Tools/products/workflows: BI assistant for dashboards; Excel/Sheets add-ins; “ChartQA/TableQA” microservices; report reviewer that flags inconsistencies and computes aggregates using CoT traces.
- Assumptions/dependencies: Consistent rendering styles; access to original figures improves accuracy; integration with calculators/databases for high-stakes computation.
- Math tutoring and grading with visual inputs [sectors: education]
- Use case: Step-by-step assistance on math problems including images of handwritten work, diagrams, and formula recognition; automated grading and feedback with CoT.
- Tools/products/workflows: LMS plug-ins; mobile scanning apps for homework; instructor dashboards highlighting reasoning steps, misconceptions, and rubric-aligned feedback.
- Assumptions/dependencies: Controlled CoT disclosure (> tokens) as needed; robust formula parsing; school-specific privacy policies. > > - Multilingual natural-scene OCR and translation [sectors: retail, travel, logistics; daily life] > - Use case: Reading storefront signs, menus, labels, and packaging across 12+ languages; instant translation and structured extraction (e.g., ingredients, prices) on mobile. > - Tools/products/workflows: AR translator app; smart scanner for inventory and shelf auditing; handheld device with the 3B model for edge inference. > - Assumptions/dependencies: Edge compute constraints (use quantized/distilled 3B); variable lighting and occlusion; local language fonts. > > - GUI/screen understanding for software QA and support [sectors: software] > - Use case: Parse app screenshots to identify UI elements, generate test steps, or assist users with on-screen tasks (e.g., “click the settings icon; toggle option X”). > - Tools/products/workflows: QA automation that converts screenshots into structured UI trees and test scripts; support copilots that guide users via visual instructions. > - Assumptions/dependencies: Availability of representative GUI training data; permissioned screen captures; stable UI versions. > > - Knowledge worker productivity for document-heavy tasks [sectors: consulting, legal, academia; daily life] > - Use case: Summarize long PDFs, extract key facts, compare versions, and answer visual Q&A about embedded charts/figures; generate meeting minutes from slides + notes. > - Tools/products/workflows: “DocQ&A” assistants; firm-wide search with multimodal RAG that indexes text, tables, and charts; batch converters (image/PDF → structured). > - Assumptions/dependencies: Current 32K context constraint may require chunking; improved general knowledge coverage needed for broad MMMU/MMVet-style queries. > > - Model customization with cost-effective domain tuning [sectors: all] > - Use case: Start from Stage-2 checkpoints and perform only Stage 3 (domain enhancement) + Stage 4 (instruction tuning) with small, curated domain datasets to rapidly obtain specialized VLMs (e.g., contract analysis, blueprint reading). > - Tools/products/workflows: “Domain-tuning recipes” and data synthesis pipelines (documents, formulas, charts, tables, scene OCR); A/B evaluation using VLMEvalKit and LLM-as-a-judge. > - Assumptions/dependencies: Quality curated domain data; rights to fine-tune base models (Llama/Qwen licenses); evaluation alignment for target tasks. > > - High-resolution image workflows via dynamic tiling [sectors: engineering/architecture, manufacturing] > - Use case: Parse architectural drawings, manufacturing schematics, and large documents while preserving detail using 4K-aware tiling plus a global snapshot. > - Tools/products/workflows: Blueprint reader assistant; CAD-to-text/QA microservices; discrepancy detection between drawings and BOM tables. > - Assumptions/dependencies: Tiling configuration tuned to image characteristics; reliable mapping from tiles to global context. > > - Dataset synthesis and quality control [sectors: AI/ML academia and industry] > - Use case: Generate large-scale training/evaluation datasets across OCR, math, charts, tables, formulas, and scenes with multi-model voting and rule-based verification. > - Tools/products/workflows: Research-grade synthesis pipelines; cross-VLM agreement thresholds; rejection sampling and process supervision for CoT data. > - Assumptions/dependencies: Access to synthesis stack (renderers, MathJax/KaTeX, depth/segmentation models); careful governance to avoid synthetic bias. > > ## Long-Term Applications > > The following bullet points describe strategic use cases that will benefit from the paper’s roadmap (longer context, video/3D, efficiency improvements) and may require further research, scaling, or productization. > > - Whole-book, multi-document, and extended dialogue analysis [sectors: legal, compliance, publishing, research] > - Use case: Analyze entire books, multi-hundred-page contracts, and large regulatory filings with persistent context and cross-referencing across documents. > - Tools/products/workflows: 128K+ context “Compliance Copilot” that links clauses to exhibits; research assistants that connect figures/tables across chapters; briefing generators with source provenance. > - Assumptions/dependencies: Successful context extension beyond 32K via sparse/hierarchical attention; scalable memory; robust citation tracking. > > - Multimodal video understanding and temporal/3D reasoning [sectors: security, robotics, manufacturing, sports analytics] > - Use case: Detect events, summarize surveillance streams, reason about sequences and 3D spatial relationships; analyze instructional videos with step tracking. > - Tools/products/workflows: Video QA agents; robotic perception modules; safety monitors for factory lines; sports performance dashboards. > - Assumptions/dependencies: Dedicated training on video/temporal data; 3D scene understanding; higher throughput inference. > > - Edge-native multimodal assistants via NaViT, quantization, and distillation [sectors: mobile/AR, field services; daily life] > - Use case: Real-time on-device OCR/translation, form filling, chart/table analysis; AR overlays for instructions and measurements in field work. > - Tools/products/workflows: AR glasses apps; offline mobile copilots; ruggedized handhelds for logistics and maintenance. > - Assumptions/dependencies: Effective NaViT integration; aggressive quantization (int8/4-bit) and distillation without major accuracy loss; thermal/power constraints. > > - Medical imaging and clinical document copilots [sectors: healthcare] > - Use case: Combine radiology/ophthalmology images with clinical notes, forms, and charts to assist with triage, structured extraction (FHIR), and patient summaries. > - Tools/products/workflows: EHR-integrated multimodal assistants; prior-image comparison modules; automated registries. > - Assumptions/dependencies: Domain-specific training with medical datasets; rigorous validation; regulatory approval; strong privacy/security guarantees. > > - Scientific diagram and formula comprehension for research automation [sectors: academia, R&D] > - Use case: Parse complex scientific figures (e.g., microscopy, spectra), extract equations and semantics, and generate reproducible summaries or method reconstructions. > - Tools/products/workflows: “Figure-to-facts” extractors; equation-to-concept mappers; reproducibility assistants that link diagrams to methods and results. > - Assumptions/dependencies: Expanded datasets covering scientific modalities; alignment with domain ontologies; precise formula grounding. > > - National-scale digitization and multilingual government services [sectors: policy/public sector] > - Use case: Bulk digitization of archives, forms, census documents across many languages and scripts; citizen-facing assistants that understand uploaded scans and issue guidance. > - Tools/products/workflows: Government DocAI platforms; multilingual form validators; public service kiosks with OCR/KIE. > - Assumptions/dependencies: Language expansion and script coverage; fairness/accessibility audits; large-scale infrastructure and governance. > > - Multimodal enterprise search and RAG with strong grounding [sectors: all] > - Use case: Index text, tables, charts, and images; answer questions with cross-document reasoning and cite visual evidence to mitigate hallucinations. > - Tools/products/workflows: Visual-text RAG pipelines; provenance-preserving answers; auditor modes leveraging HallusionBench-style robustness. > - Assumptions/dependencies: Improved general knowledge coverage (MMMU/MMVet gap); robust retrieval over heterogeneous media; CoT alignment with tool-use (calculators, databases). > > - Sovereign AI training on proprietary hardware [sectors: cloud/infrastructure, national strategy] > - Use case: Replicable training of large VLMs on Kunlun-like chips with >90% scaling, enabling independent AI capability. > - Tools/products/workflows: 3D parallelism playbooks; communication–computation fusion frameworks (AllGather+GEMM fusion); scheduling libraries for multi-stream pipelines. > - Assumptions/dependencies: Access to specialized chips; optimized kernels; skilled ops teams and data pipelines at national/cloud scale. > > - Automated audit and reconciliation across multimodal financial statements [sectors: finance/accounting] > - Use case: Cross-verify numbers from tables, charts, and narrative sections; flag inconsistencies and generate audit trails with CoT steps. > - Tools/products/workflows: “Multimodal auditor” with line-item linkage; variance analysis explainers; compliance pack generators. > - Assumptions/dependencies: Tool integration (calculation engines); standardized document formats; high accuracy thresholds and human-in-the-loop. > > - Legal contract analytics at scale with clause–figure–table linking [sectors: legal] > - Use case: Extract clauses, map references to exhibits/tables/attachments, and generate risk summaries that include visual evidence. > - Tools/products/workflows: Contract copilots; clause heatmaps with linked charts; redlining assistants that check term consistency across documents. > - Assumptions/dependencies: Extended context window; domain-specific fine-tuning; policy/legal review for acceptable automation. > > ### Notes on cross-cutting assumptions and dependencies > > - Licensing and deployment: Check licensing terms for Llama/Qwen derivatives; ensure rights to fine-tune and deploy (especially commercial). > > - Data quality and representativeness: Domain-tuned gains depend on curated datasets; synthetic pipelines should be balanced with real-world samples to avoid bias. > > - Privacy, security, and compliance: OCR/KIE over sensitive documents requires robust governance and auditability; consider on-prem or edge deployment for PHI/PII. > > - Compute and latency: High-resolution and multi-visual inputs are compute-heavy; for mobile/edge use, prioritize smaller models, quantization, and NaViT-style efficiency. > > - Reasoning control: CoT tokens (<think> ... ) allow explicit reasoning control; production systems may hide or log CoT for explainability and QA.
- General knowledge coverage: Current gaps on broad domain benchmarks (MMMU/MMVet) suggest augmenting training with interleaved image–text general knowledge for open-ended queries.
Glossary
- 1F1B (one forward, one backward) pipeline scheduling: A pipeline training schedule that alternates one forward and one backward pass to reduce pipeline bubbles and improve throughput. "1F1B (one forward, one backward) pipeline scheduling with bubble rate below 5%."
- 3D Parallelism Strategy: A combined parallel training approach using data, tensor, and pipeline parallelism to scale large models efficiently. "3D Parallelism Strategy:"
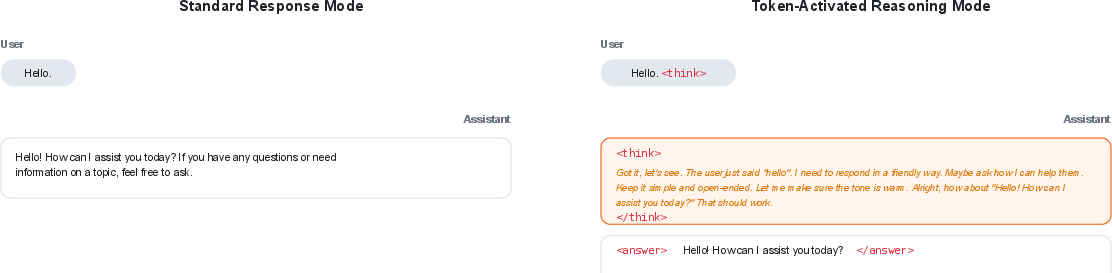
- > tokens: Special delimiter tokens used to explicitly trigger and bound chain-of-thought reasoning in model outputs. "We introduce special tokens (<think> and </think>) to delineate reasoning processes, allowing users to explicitly request reasoning by including these tokens."
Adaptive difficulty scheduling: A curriculum strategy that gradually increases task difficulty to stabilize learning and avoid overfitting. "We employ curriculum learning with adaptive difficulty scheduling, starting with simple OCR tasks and progressively introducing complex multi-step reasoning problems, ensuring stable learning and preventing overfitting to specific task patterns."
- AllGather+GEMM fusion: A performance optimization that pipelines collective communication (AllGather) with matrix multiplication (GEMM) to reduce end-to-end latency. "Taking AllGather+GEMM fusion as an example, traditional approaches complete AllGather, wait, then start GEMM sequentially."
- AllReduce gradient synchronization: A distributed training operation that aggregates gradients across devices to keep model replicas synchronized. "optimized AllReduce gradient synchronization achieving 60% communication reduction"
- Asymptote: A formal language for programmatically rendering vector graphics, often used for mathematical diagrams. "using Markdown, LaTeX, and Asymptote formal description languages."
- BypassStream: Dedicated communication streams that run in parallel to computation streams to overlap data transfer with compute. "We establish bypass streams (BypassStream) for seamless integration, enabling independent scheduling where bypass streams run parallel to main computation streams, data prefetching that initiates communication before computation needs data, and result pipelining for immediate transfer of computation results."
- Chain-of-thought (CoT): Training or inference technique where models generate step-by-step reasoning to improve problem-solving. "For the 8B and 70B variants, we implement sophisticated chain-of-thought (CoT) reasoning capabilities"
- Communication-Computation Fusion: Hardware/software co-optimization that overlaps communication with computation to reduce latency and increase scalability. "utilizing innovative parallel strategies and communication-computation fusion techniques to achieve over 90% scaling efficiency"
- Cross-Modal Alignment: A training stage or objective to align representations between vision and language modalities. "Stage 1: Cross-Modal Alignment (100B tokens)"
- Curriculum learning: A training paradigm that introduces tasks in a structured order from easy to hard to facilitate learning. "We employ curriculum learning with adaptive difficulty scheduling"
- Data Parallelism (DP): A distributed training method where different devices process different data batches and synchronize gradients. "Data Parallelism (DP) distributes batch samples across nodes with gradient accumulation"
- Dynamic batching: Adjusting batch sizes based on sequence length or resource constraints to optimize throughput and memory. "dynamic batching adapts batch sizes based on sequence length distribution"
- Dynamic image tiling: Splitting high-resolution images into tiles for efficient processing while preserving detail. "supports dynamic image tiling for variable resolution inputs"
- GELU: The Gaussian Error Linear Unit activation function used to improve training stability and performance. "The cross-modal adapter employs a two-layer MLP with GELU activation"
- GEMM: General Matrix-Matrix Multiplication, a core linear algebra operation central to deep learning workloads. "then start GEMM sequentially."
- Grouped-Query Attention (GQA): An attention variant that groups queries to reduce memory and improve inference speed. "The model employs Grouped-Query Attention (GQA) to optimize memory efficiency and inference speed"
- Image-to-Markdown conversion: Transforming document images into structured Markdown that preserves layout and hierarchy. "image-to-Markdown conversion for efficient transformation of single/multi-page documents into structured format preserving formatting and hierarchy"
- InternViT: A vision transformer architecture used as the visual encoder backbone. "The vision encoder is initialized from InternViT"
- Kunlun P800 chips: Proprietary AI accelerator hardware used to train the models at scale. "All Qianfan-VL models are trained on Baidu's Kunlun P800 chips"
- LaTeX: A typesetting system used for mathematical notation and formula formatting in datasets and synthesis. "through LaTeX formatting and HTML rendering to image generation"
- Layer normalization: A normalization technique applied across feature dimensions to stabilize training. "It starts with layer normalization on the input visual features"
- LLM-as-a-judge: Using a LLM to evaluate outputs in benchmarks that need nuanced judgment. "we implement LLM-as-a-judge evaluation using Ernie-4.5-Turbo-VL"
- MathJax: A JavaScript engine for rendering LaTeX/MathML on the web, used for consistent formula visualization. "multi-engine rendering with MathJax and KaTeX ensures cross-platform consistency"
- Model merging: Combining checkpoints from different runs to aggregate complementary strengths and improve performance. "Additionally, we perform model merging on the best-performing checkpoints from different training runs to combine their complementary strengths"
- Monocular depth estimation: Predicting scene depth from a single image to aid realistic text embedding in scenes. "monocular depth estimation~\citep{yang2024depth} for region division and 3D structure."
- NaViT (Native Resolution ViT): A technique to process images at native resolutions in vision transformers without resizing. "we plan to integrate NaViT (Native Resolution ViT) techniques \citep{dehghani2024patch} to process images at their native resolutions without resizing"
- Nougat: A model/approach for converting scientific PDFs to HTML/LaTeX, referenced for precise rendering. "inspired by Nougat~\citep{blecher2023nougat}"
- Perspective transformation: A geometric transformation used to project text onto planar regions in images realistically. "plane detection with perspective transformation and random text styling for natural embedding"
- Pipeline Parallelism (PP): Splitting model layers across devices in stages to increase throughput for large models. "Pipeline Parallelism (PP) divides model depth across node groups to maximize throughput."
- Poisson blending: An image-processing technique for seamless integration of synthesized text with scene textures. "fusion enhancement through Poisson blending ensures consistent occlusion, shadows, and texture integration."
- Process supervision: Verifying the correctness of intermediate reasoning steps during training, not just final answers. "combined with process supervision to verify correctness of intermediate steps rather than just final answers."
- Qwen2.5-3B: A LLM backbone variant used in the 3B model configuration. "while the 3B model is based on Qwen2.5-3B~\citep{bai2025qwen2}"
- RMSNorm: Root Mean Square Layer Normalization, a normalization variant for stability and efficiency. "while RMSNorm~\citep{zhang2019root} is used to improve training stability."
- Semantic segmentation: Assigning class labels to each pixel to understand scene structure for text placement. "scene understanding via semantic segmentation~\citep{ravi2024sam}"
- Sequence parallelism: Splitting long sequences across devices to reduce memory usage during training. "Additionally, sequence parallelism for splitting long sequences reduces memory by 50% for 32K contexts"
- TexLive: A LaTeX distribution used for re-rendering mathematical content from scientific papers. "TexLive re-rendering for precise mathematical chart descriptions"
- Token-Activated Reasoning: A mechanism that uses special tokens to trigger and bound explicit reasoning chains. "Token-Activated Reasoning: We introduce special tokens (<think> and ) to delineate reasoning processes"
- Vision Transformer (ViT): A transformer architecture for images that treats patches as tokens. "building upon the Vision Transformer (ViT) architecture"
- VLMEvalKit: An open-source toolkit for evaluating multimodal models across diverse benchmarks. "We conduct comprehensive evaluations across general multimodal benchmarks and domain-specific tasks using the VLMEvalKit framework~\citep{duan2024vlmevalkit}, an open-source toolkit designed for evaluating large multi-modality models."
- Vocabulary expansion: Adding tokens to the LLM’s vocabulary to improve cross-lingual and domain coverage. "both enhanced with vocabulary expansion and localization improvements."
Collections
Sign up for free to add this paper to one or more collections.

