- The paper presents a novel architecture that integrates adaptive visual resolution compression and dual visual encoders for efficient on-device inference.
- It employs a dynamic task-adaptive framework with Dual Consistency Learning to balance accuracy and latency across heterogeneous hardware.
- Benchmark results demonstrate state-of-the-art performance on multimodal tasks with significant reductions in latency and memory usage.
HyperVL: Dynamic, Efficient Multimodal LLMs for Edge Devices
Motivation and Positioning
There is a pronounced need for multimodal LLMs (MLLMs) that meet resource and latency constraints in edge deployment, particularly on mobile and embedded hardware. While recent MLLMs have closed the capability gap with proprietary cloud-scale models, high computational and memory complexity—especially from Vision Transformer (ViT) visual encoders—remains a deployment bottleneck. HyperVL (2512.14052) directly targets these constraints, proposing an architecture, data, and training stack optimized for on-device inference without compromising performance on established multimodal benchmarks. Its approach enables adaptive allocation of compute via novel architectural elements and demonstrates state-of-the-art results in the sub-2B parameter regime.
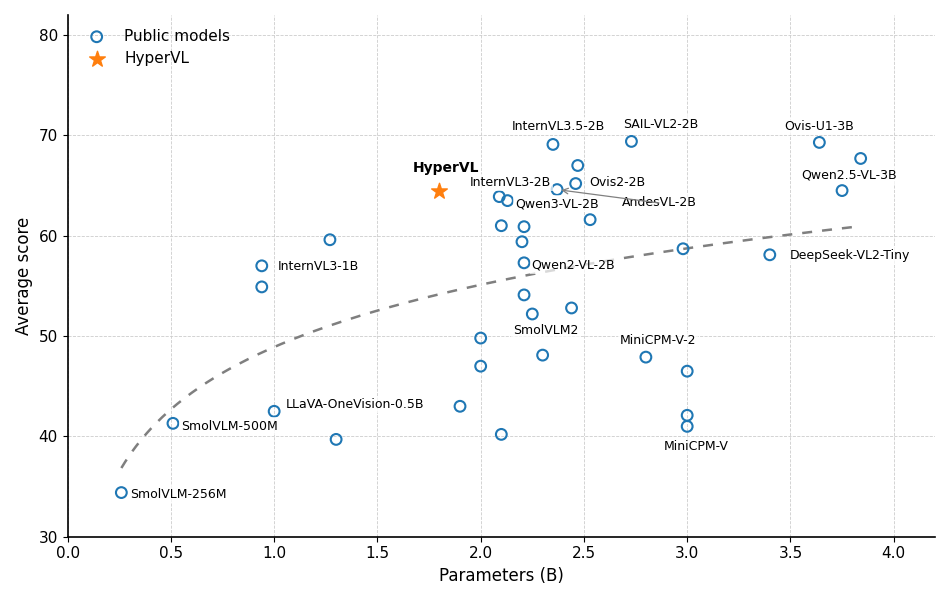
Figure 1: HyperVL achieves strong OpenCompass average scores relative to parameter count, exceeding many larger open-source models while remaining highly compact.
System Architecture
HyperVL introduces a modular architecture, combining techniques for on-device viability with dynamic task-adaptive visual representation. The system comprises four primary components: (1) a Visual Resolution Compressor (VRC), (2) two ViT-based visual encoders of different capacities, (3) a vision-language projector utilizing pixel-shuffling for token compaction, and (4) a shared LLM backbone (Qwen3-1.7B).
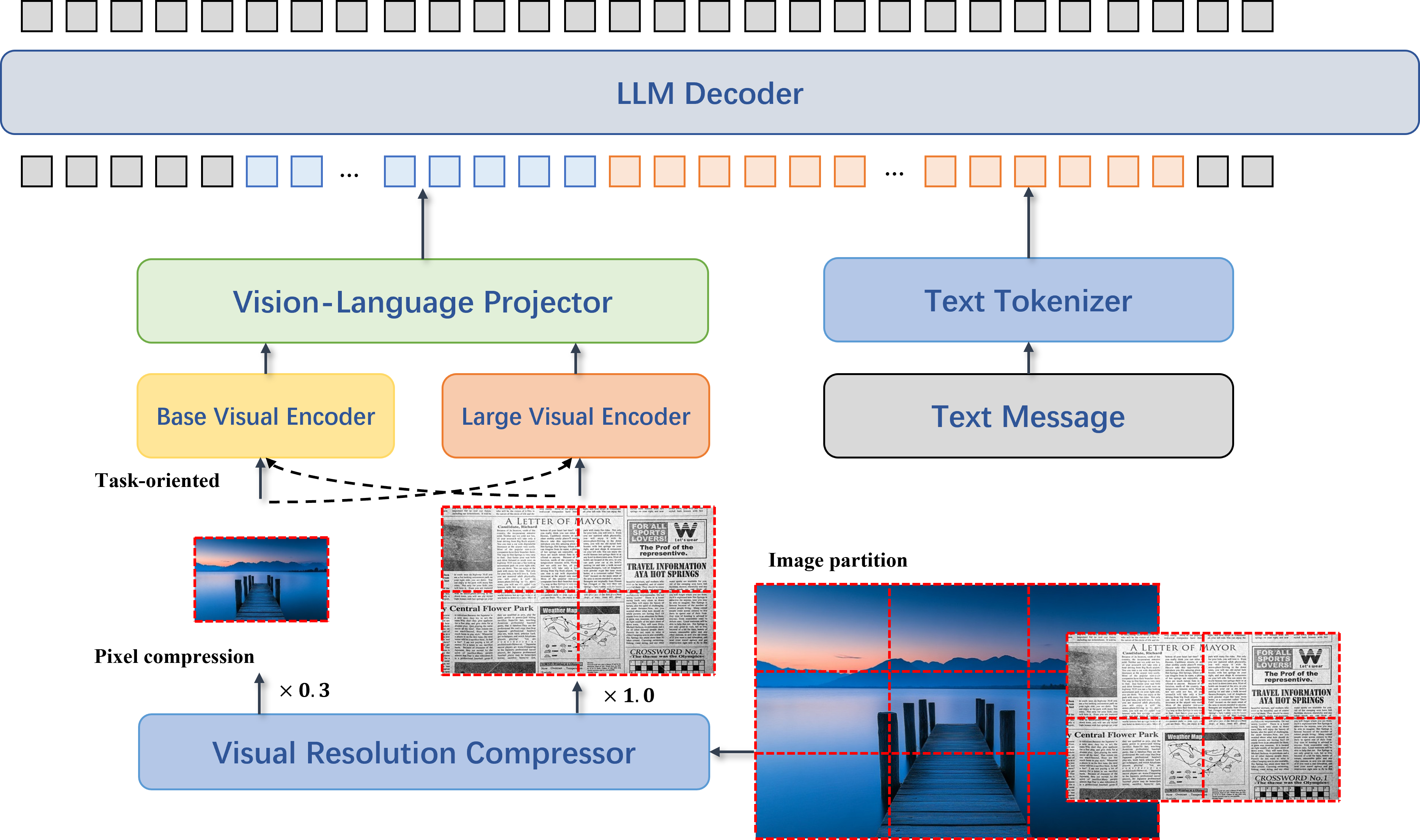
Figure 2: System-level overview of the HyperVL architecture, highlighting its dual visual encoding branches, plug-and-play visual resolution compressor, and unified language modeling core.
Key properties:
Visual Resolution Compression Strategy
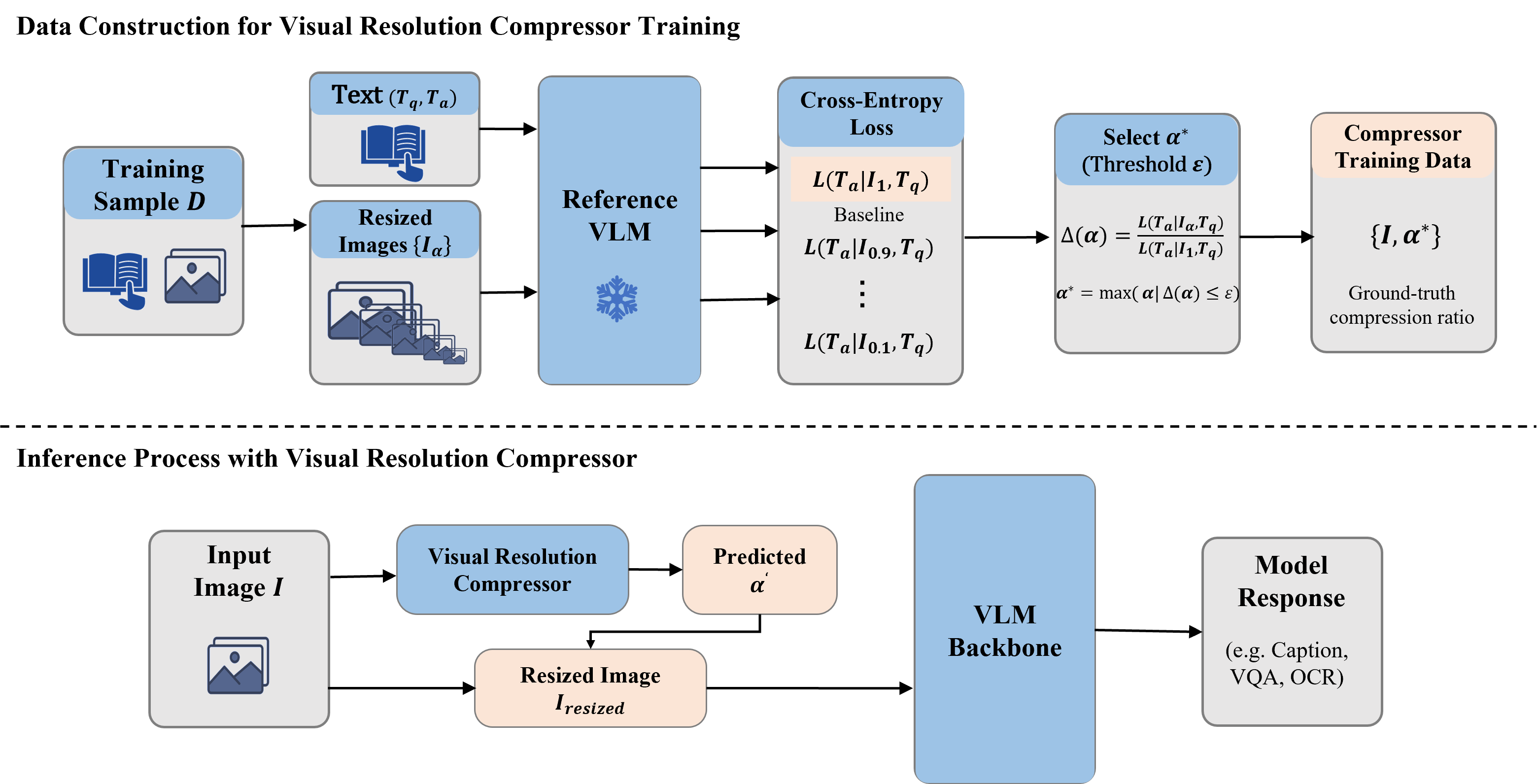
HyperVL’s VRC moves beyond static compression or handcrafted heuristics by employing a supervised, content-adaptive approach. Given ground-truth output stability under various compressions (measured against an L(Ta∣Iα,Tp) loss under increasing compression), the VRC is trained to output the maximal compression preserving task accuracy. A lightweight MobileNet-like architecture ensures actual deployability, yielding fine-grained scaling (10–100%) with negligible (<2ms) latency overhead.
Main features:
- Cross-benchmark Consistency: VRC achieves up to 49.5–63.4% token reduction on redundancy-rich benchmarks (e.g., DocVQA), while conservatively preserving resolution for detail-sensitive tasks (<3% reduction on ChartQA).
- Plug-and-play: The compressor is architecture-agnostic and integrable with any pretrained MLLM.
Dual Consistency Learning for Visual Branches
To maximize adaptability across heterogeneous edge hardware, HyperVL implements a dual-branch vision stack, linking both ViT branches to a common LLM via DCL. The DCL paradigm consists of alternating optimization of the two vision branches (teacher and student) under a semantic distillation regime, minimizing temperature-tuned KL divergence on textual outputs to enforce output consistency.
Findings:
- Empirical Δ: DCL yields notable improvements on fine-grained visual tasks (+5.0 points on AI2D, +22.0 on OCRBench), enabling the lightweight branch to match or closely approach the output distributions of the larger, high-fidelity branch.
- Dynamic Routing: Real-time adaptation to task type or device performance budget becomes feasible, optimizing responsiveness without sacrificing output quality.
Data Pipeline and Corpus Construction
HyperVL is trained on a rigorously curated corpus leveraging both multi-domain, open-source, and synthetic data. The three-stage data governance pipeline emphasizes (i) hierarchical categorization and sampling, (ii) automated large-scale multimodal deduplication (SSCD vector-based), and (iii) multi-dimensional quality filtering. Resulting datasets exhibit high task diversity, cross-linguality, and low contamination, critical for on-device generalization.
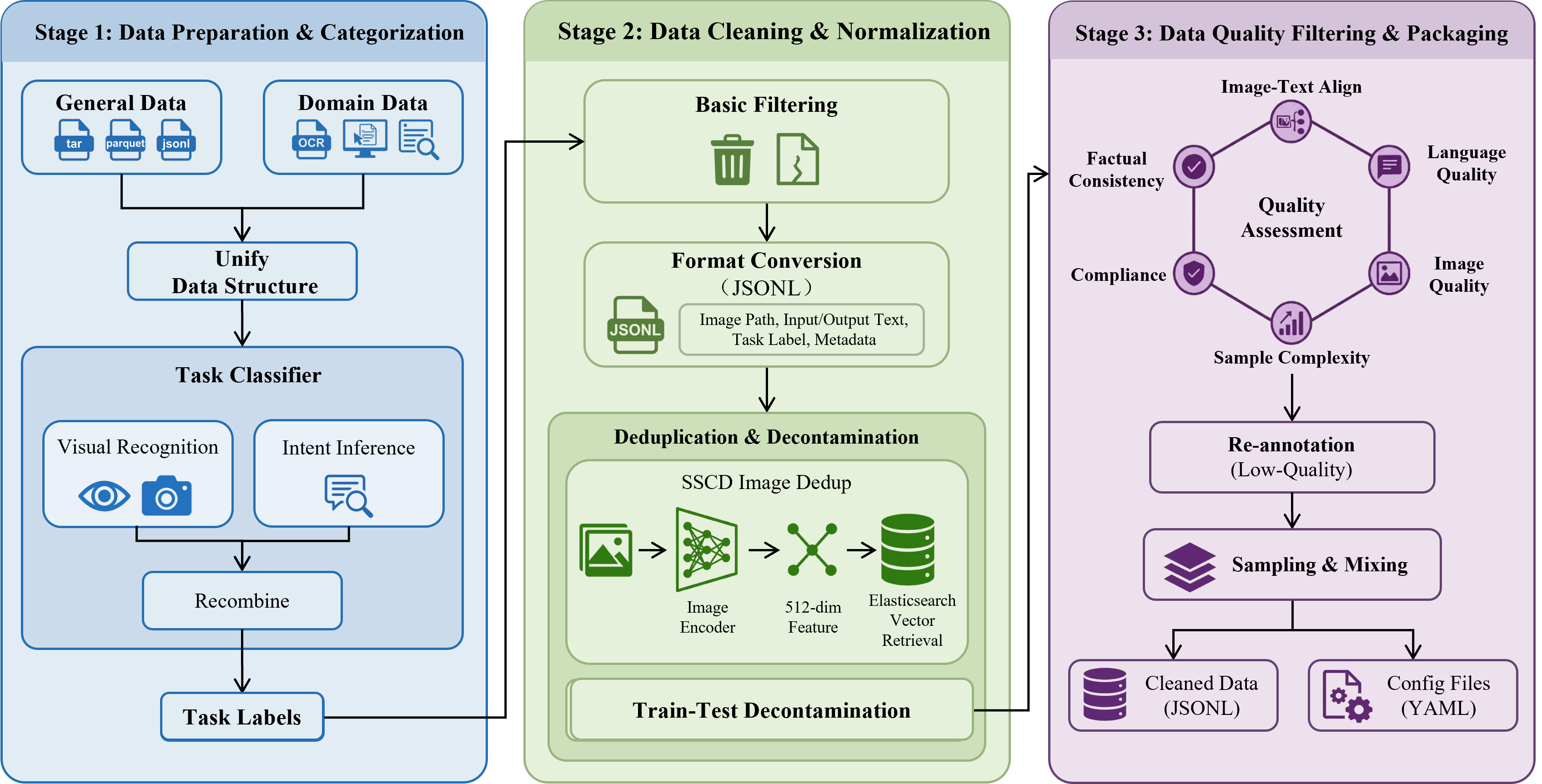
Figure 4: End-to-end data pipeline for constructing large-scale, stratified, and deduplicated multimodal corpora for HyperVL fine-tuning.
Benchmarking and Results
Public Benchmarks: HyperVL achieves an OpenCompass average of 64.5 with 1.8B parameters, outperforming most models up to 3B parameters, especially in OCR/Document/Chart QA (e.g., 83.8 on ChartQA, 81.8 on AI2D, 91.3 on DocVQA). The strong performances on hallucination robustness and visual-semantic reasoning tasks further validate the design.
Internal Benchmarks: On proprietary tasks reflecting real-world deployment domains, HyperVL demonstrates leading accuracy and relevance in UI understanding and structured parsing, creative multimodal text generation, intent extraction, and image relevance ranking.
On-Device Efficiency: Latency, Memory, and Quantization
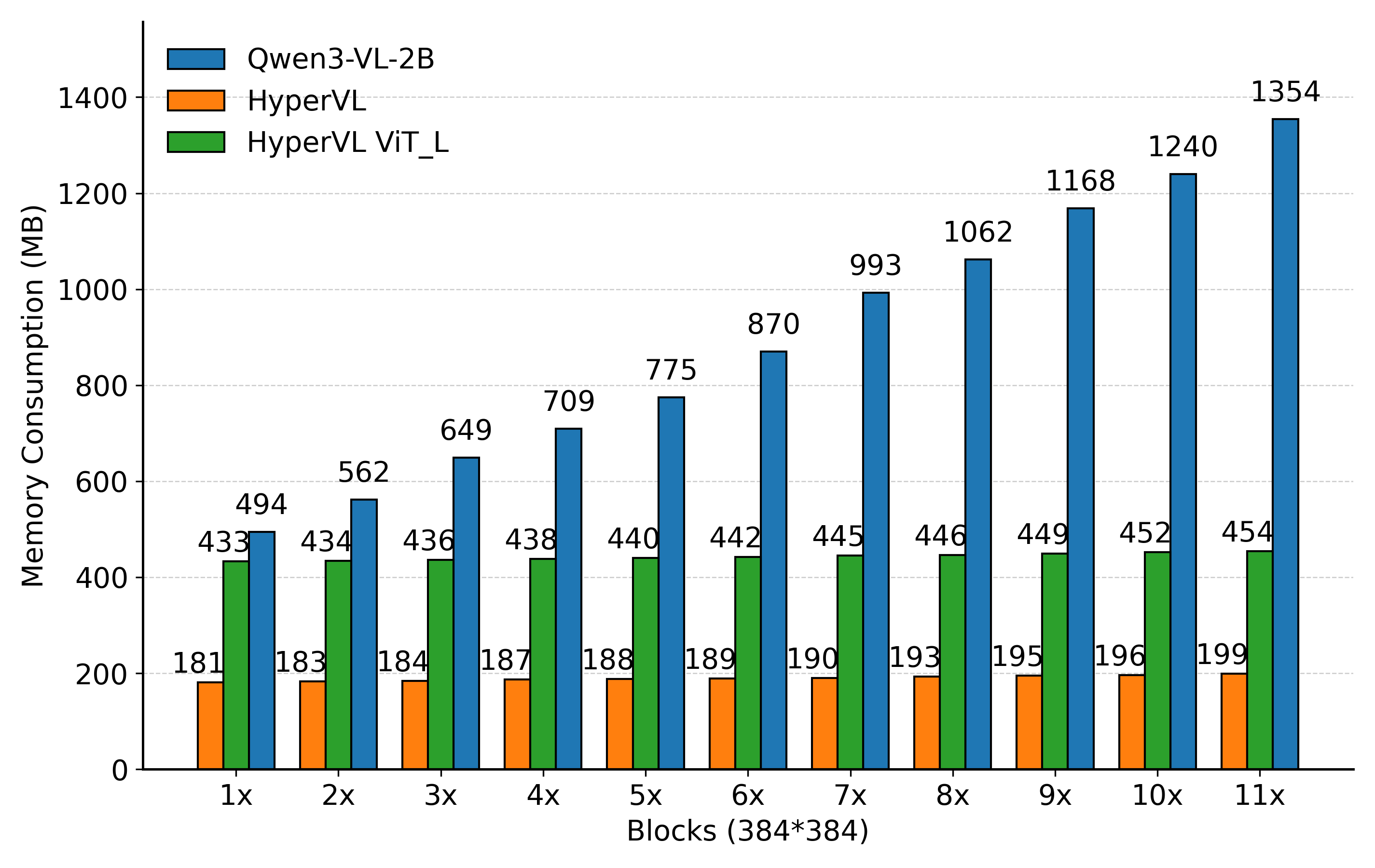
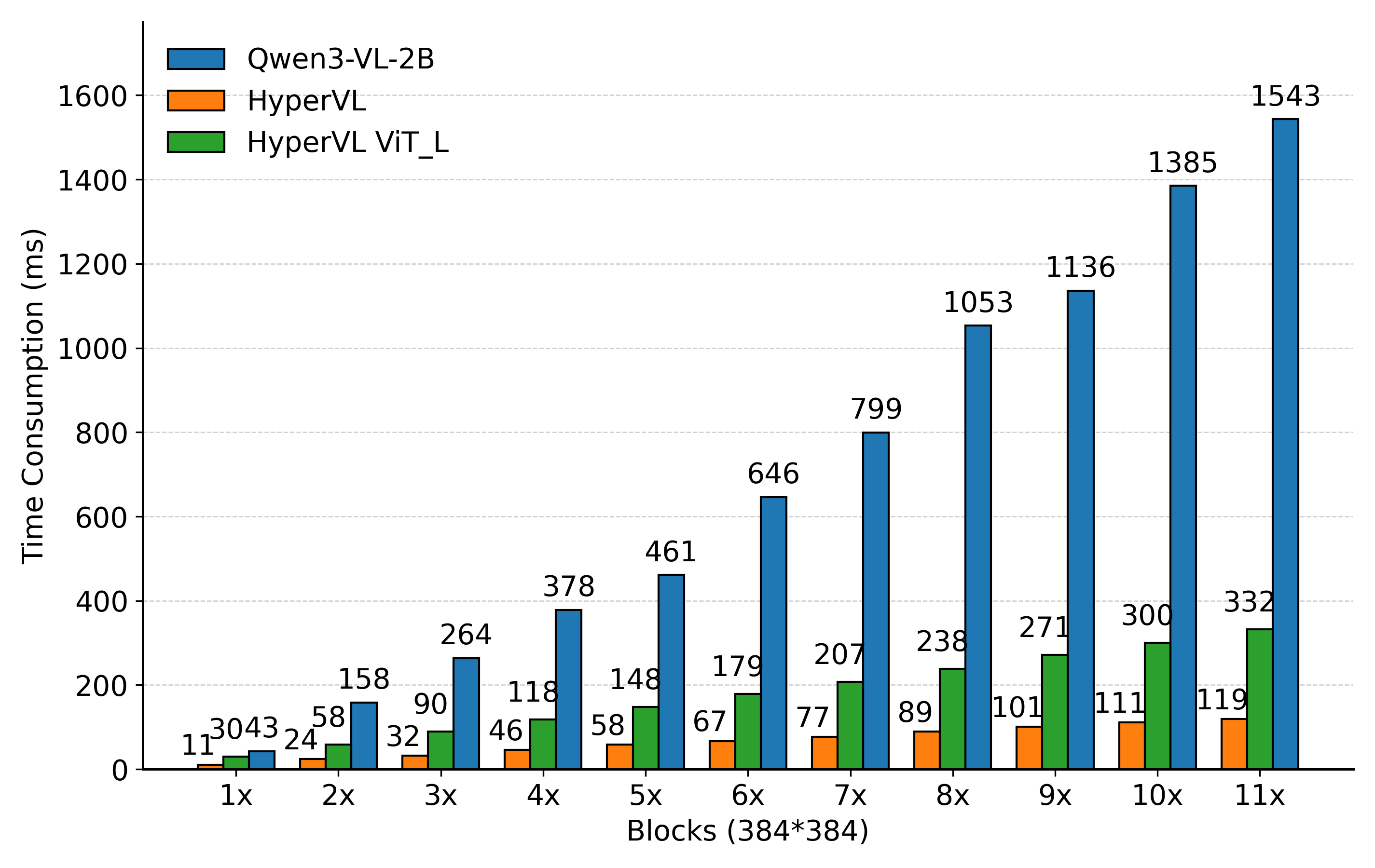
Figure 5: Comparative memory and inference latency for ViT models on Qualcomm 8750, showing the constant memory and linear scaling achieved by HyperVL’s tiling approach.
- Inference Latency: HyperVL ensures a 12.9× reduction in latency for high-resolution images versus standard ViT baselines, maintaining real-time performance on typical edge chips.
- DRAM/VRAM Footprint: The tiling and VRC design yield 6.8× peak memory reduction, with constant per-chunk resource allocation versus exponential growth in vanilla ViTs.
- Quantization Robustness: Minimal degradation (<0.1 points in DocVQA) under W4A16 quantization verifies suitability for commercial NPUs where 4–8b weight/activation precision is now the norm.
Practical and Theoretical Implications
HyperVL’s architecture and training methodology substantiate that robust, general-purpose multimodal reasoning can be realized at edge-viable parameter scales without resorting to severe perceptual capacity trade-offs. Its content-adaptive VRC and DCL framework represent a step toward truly dynamic, resource-aware MLLMs.
Future research is anticipated in token-level sparsity, attention pruning, and domain-adaptive compression policies. Extensions to video and interactive agent scenarios are natural next steps, exploiting the tiling and dynamic resolution framework for spatiotemporal modality handling. Further, the pipeline positions multimodal models as deployable privacy-preserving system components, rather than cloud-tethered services.
Conclusion
HyperVL operationalizes multimodal AI for edge devices via modular, scalable architectural innovations and a dynamic, content-adaptive inference pipeline, achieving state-of-the-art results at high efficiency. This work demonstrates that targeted architectural decoupling, semantically aligned multi-branch encoding, and corpus-level data governance together unlock practical, high-quality multimodal inference under strict on-device constraints. Future AI deployments—especially in privacy-critical and interactive settings—will benefit from building atop such low-latency, parameter-efficient foundations.