- The paper presents a progressive training framework and modular architecture that enable efficient multimodal understanding with moderate parameter scales.
- The model leverages a high-quality data curation pipeline and synthetic VQA generation to enhance visual grounding and diverse reasoning tasks.
- Empirical results show that SAIL-VL2 achieves state-of-the-art performance across 106 benchmarks, challenging the need for massive parameter counts.
SAIL-VL2: An Open-Suite Vision-Language Foundation Model for Efficient Multimodal Understanding and Reasoning
Introduction
SAIL-VL2 represents a significant advancement in the design and training of vision-LLMs (LVMs), targeting efficient yet high-performing multimodal understanding and reasoning at moderate parameter scales (2B, 8B, and MoE variants). The model suite is distinguished by three core innovations: a large-scale, quality-focused data curation pipeline; a progressive, multi-stage training framework; and architectural advances including both dense and sparse Mixture-of-Experts (MoE) LLM backbones. SAIL-VL2 achieves state-of-the-art results across 106 benchmarks, including challenging reasoning tasks such as MMMU and MathVista, and leads the OpenCompass leaderboard for open-source models under 4B parameters.
Model Architecture
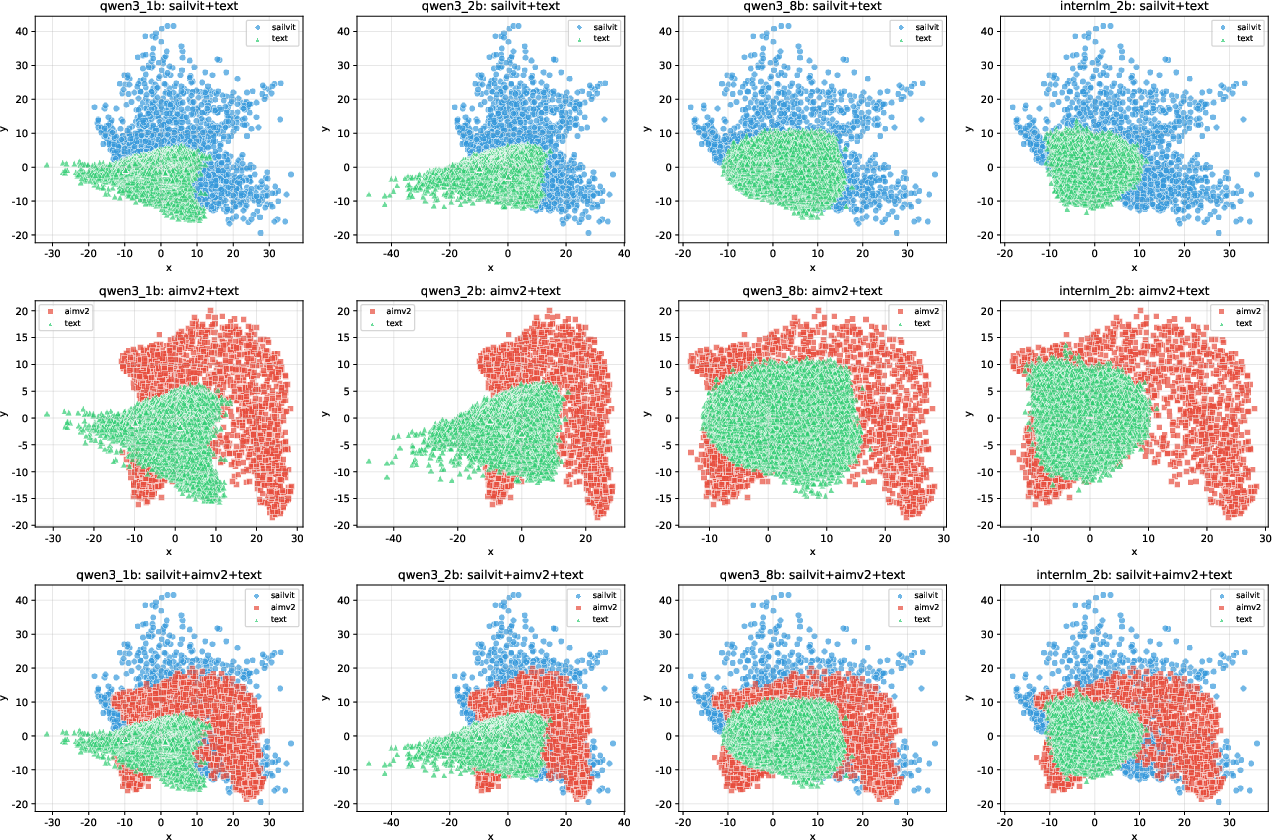
SAIL-VL2 adopts a modular architecture comprising a vision encoder (SAIL-ViT), a lightweight vision-language adapter, and a flexible LLM backbone (Qwen3 series, both dense and MoE). The vision encoder is based on a progressively trained ViT, designed to align visual features with the LLM's representation space. The adapter, a two-layer MLP, projects visual embeddings into the language domain, facilitating joint multimodal processing.
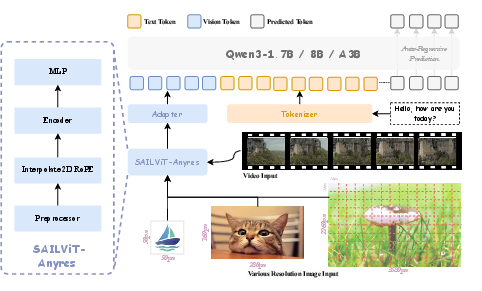
Figure 2: SAIL-VL2 framework: SAIL-ViT encodes visual inputs, the adapter projects them into the LLM space, and the LLM processes both modalities for unified reasoning.
The architecture supports both fixed-resolution and arbitrary-resolution visual inputs, with SAIL-ViT-AnyRes employing interpolation-based positional embeddings for flexible input handling. The LLM backbone is instantiated with Qwen3-Instruct (dense) or Qwen3-MoE, with the latter leveraging sparse expert activation for parameter-efficient scaling.
Data Curation and Pre-Training
A central innovation in SAIL-VL2 is the data curation pipeline, which systematically scores and filters multimodal corpora for quality and diversity. SAIL-Caption2, the primary caption dataset, is refined using judge models trained to assess Visual Information Richness (VIR) and Image-Text Alignment (ITA), resulting in a high-quality corpus of 250M general and 1.69M chart captions. Synthetic VQA data is generated by transforming captions into QA pairs using LLMs, further expanding the training distribution.
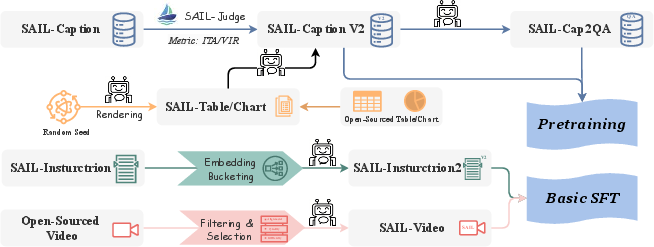
Figure 1: SAIL-VL2 data construction pipeline: open-source and synthetic data are curated, filtered, and organized for different training stages.
Pre-training proceeds in two stages: basic multimodal pre-training (alignment and captioning/OCR tasks) and multi-task pre-training (instruction tuning, VQA, math reasoning). AdaLRS, a dynamic learning rate scheduler, is employed to optimize convergence during the initial stage. Data resampling at both dataset and linguistic levels mitigates distributional bias and enhances diversity.
Scaling experiments demonstrate monotonic performance improvements with increased data volume, particularly when synthetic VQA data is included, underscoring the importance of large, diverse corpora for robust multimodal alignment.
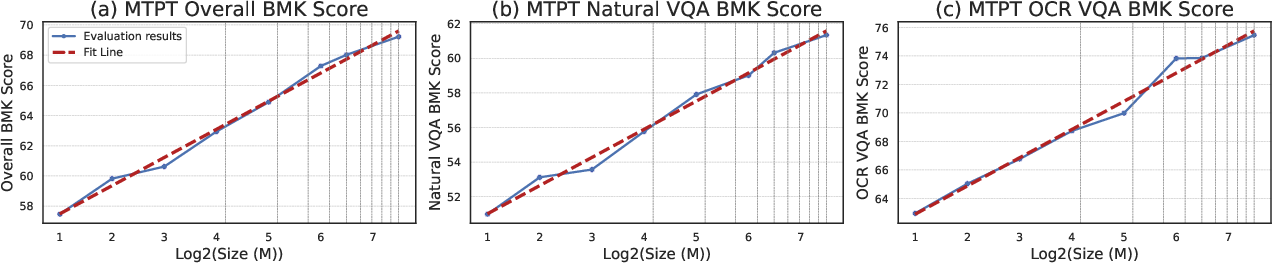
Figure 3: Scaling curves for SAIL-VL2-2B during multi-task pre-training, showing consistent gains across benchmarks as data volume increases.
Progressive Training and Post-Training Paradigms
The training pipeline is highly progressive, beginning with vision encoder adaptation (adapter-only tuning), followed by fine-grained alignment (vision encoder and adapter), and culminating in joint multimodal reasoning (all parameters unfrozen). This staged approach enables stepwise knowledge injection and robust cross-modal alignment.
Post-training consists of supervised fine-tuning (SFT) on curated instruction datasets (SAIL-Instruction2), followed by a "thinking-fusion" paradigm that combines SFT with reinforcement learning (RL) using both verifiable and mixed reward systems. Chain-of-Thought (CoT) data and RL with verifiable rewards are used to explicitly incentivize step-by-step reasoning, while think-fusion SFT and RL with mixed rewards further enhance logical coherence and output structure.
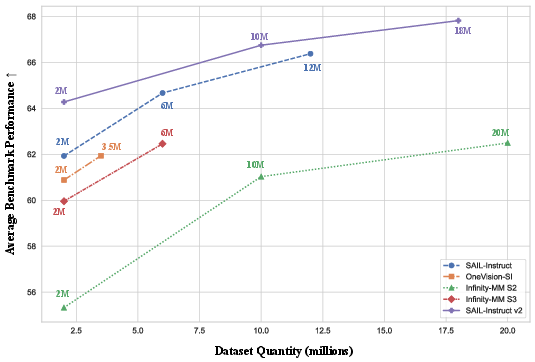
Figure 4: Analysis of instruction data quality and scale: SAIL-Instruction2 consistently yields superior SFT results, validating the data curation pipeline.
Architectural and Training Infrastructure
SAIL-VL2 incorporates several infrastructure optimizations to maximize training efficiency:
- Stream Packing: Online packing of variable-length language and vision tokens minimizes padding, maximizes GPU utilization, and balances workloads across devices. Visual packing ensures balanced computation for the vision encoder, especially in AnyRes settings.
- MoE Infrastructure: For MoE models, kernel fusion and hardware-adapted distributed frameworks (Megatron on Ascend, DeepSpeed ZeRO-2 on NVIDIA) address computational and communication bottlenecks, enabling efficient scaling to 30B+ parameters with sparse activation.
Empirical Results
SAIL-VL2 demonstrates strong empirical performance across a wide spectrum of benchmarks:
Theoretical and Practical Implications
The SAIL-VL2 framework demonstrates that high-quality data curation, progressive training, and efficient architectural design can yield compact LVMs with performance rivaling or surpassing much larger models. The staged training paradigm, particularly the integration of CoT and RL-based post-training, is shown to be critical for advanced reasoning capabilities. The MoE variant provides a practical path for scaling without prohibitive computational costs, maintaining high performance with sparse activation.
The empirical results challenge the prevailing assumption that only massive parameter counts can deliver state-of-the-art multimodal reasoning, highlighting the importance of data quality, alignment strategies, and targeted post-training.
Future Directions
Potential future developments include:
- Further architectural efficiency via more advanced MoE routing and expert specialization.
- Expansion of the data curation pipeline to cover additional modalities (e.g., audio, 3D).
- Enhanced RL paradigms for more nuanced reward modeling and self-improvement.
- Broader deployment in resource-constrained environments, leveraging the efficiency of SAIL-VL2's design.
Conclusion
SAIL-VL2 establishes a new standard for efficient, high-performing open-source vision-LLMs. Through innovations in data curation, progressive training, and architectural design, it achieves state-of-the-art results across a comprehensive suite of benchmarks, including challenging reasoning tasks. The model suite demonstrates that with careful design, compact LVMs can deliver robust multimodal understanding and reasoning, providing a scalable and extensible foundation for the open-source community and future research in multimodal AI.