DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
Abstract: Current unified multimodal models for image generation and editing typically rely on massive parameter scales (e.g., >10B), entailing prohibitive training costs and deployment footprints. In this work, we present DeepGen 1.0, a lightweight 5B unified model that achieves comprehensive capabilities competitive with or surpassing much larger counterparts. To overcome the limitations of compact models in semantic understanding and fine-grained control, we introduce Stacked Channel Bridging (SCB), a deep alignment framework that extracts hierarchical features from multiple VLM layers and fuses them with learnable 'think tokens' to provide the generative backbone with structured, reasoning-rich guidance. We further design a data-centric training strategy spanning three progressive stages: (1) Alignment Pre-training on large-scale image-text pairs and editing triplets to synchronize VLM and DiT representations, (2) Joint Supervised Fine-tuning on a high-quality mixture of generation, editing, and reasoning tasks to foster omni-capabilities, and (3) Reinforcement Learning with MR-GRPO, which leverages a mixture of reward functions and supervision signals, resulting in substantial gains in generation quality and alignment with human preferences, while maintaining stable training progress and avoiding visual artifacts. Despite being trained on only ~50M samples, DeepGen 1.0 achieves leading performance across diverse benchmarks, surpassing the 80B HunyuanImage by 28% on WISE and the 27B Qwen-Image-Edit by 37% on UniREditBench. By open-sourcing our training code, weights, and datasets, we provide an efficient, high-performance alternative to democratize unified multimodal research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces DeepGen 1.0, a small but powerful AI model that can both create new images from text and edit existing images based on instructions. Unlike many other strong models that are huge and expensive to train, DeepGen 1.0 is compact (about 5 billion parameters) yet competes with or beats much larger models. It does this by combining smart architecture choices with a careful training plan so it can understand complex instructions, reason about the world, and produce high-quality, accurate pictures.
Objectives: What questions were the researchers trying to answer?
The researchers set out to explore the following goals in simple terms:
- Can a smaller model generate and edit images as well as (or better than) much larger models?
- How can we make the “understanding” part of the model (which reads and reasons) communicate better with the “drawing” part (which creates the image)?
- How do we train the model efficiently so it learns to follow instructions, reason, and edit without needing billions of examples?
- How do we align the model with what people prefer (for example, clearer images and accurate text in images) without breaking its other skills?
Methods: How did they build and train the model?
Think of DeepGen 1.0 as a two-person creative team connected by a smart bridge:
- The “reader” and “thinker”: a Vision-LLM (VLM). This part reads the text, looks at any input images, understands the meaning, and reasons about what should be in the final picture.
- The “artist”: a Diffusion Transformer (DiT). This part takes the plan and draws the final image, making sure it looks realistic and follows the instructions.
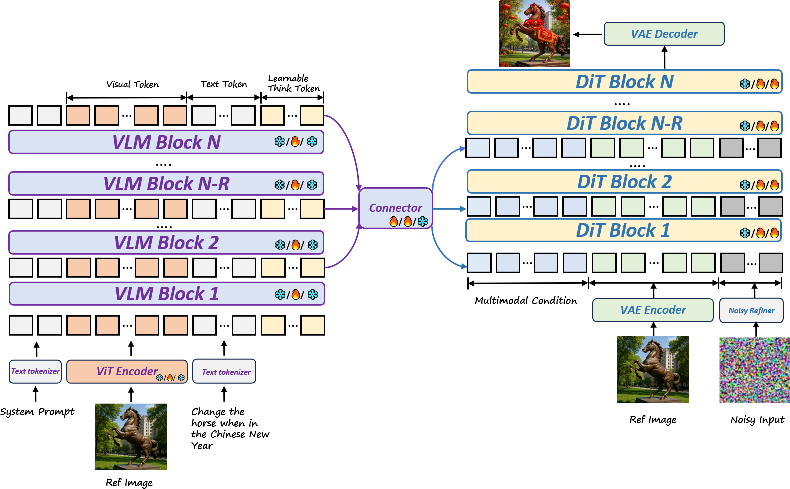
To help these two parts work together, the paper introduces a new idea called Stacked Channel Bridging (SCB), plus a special training strategy.
Stacked Channel Bridging (SCB): a smarter bridge
- Why it’s needed: If you only use the last layer of the “reader” to guide the “artist,” you might lose fine details (like textures or small object parts). SCB collects information from multiple layers (low, mid, high) of the “reader,” so both fine details and big-picture meaning are preserved.
- “Think tokens”: The model adds a set of learnable “think tokens,” like sticky notes inside the “reader” that help it reason more clearly. These notes mix with the text and image information, forming a kind of internal “chain of thought.”
- How it fuses information: SCB stacks features from different layers side-by-side (like combining multiple camera zooms into one rich view), then passes them through a light connector to prepare a clean, structured guide for the “artist.”
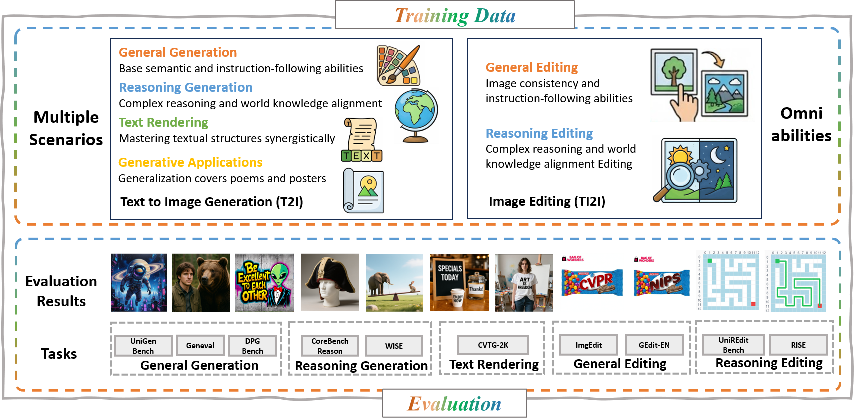
Training in three simple stages
The researchers used a “data-centric” plan that focuses on good data and stable learning, especially important for smaller models.
- Stage 1: Alignment Pre-training
- Only the bridge (connector) and the “think tokens” are trained.
- Purpose: Teach the “reader” and “artist” to speak the same language.
- Data: Large sets of text–image pairs and editing examples.
- Stage 2: Joint Supervised Fine-tuning (SFT)
- The whole model trains together.
- The “reader” is tuned gently using LoRA (think of LoRA as adding small adjustable knobs, instead of rebuilding the whole machine).
- Data mix: general image generation, image editing, reasoning-based tasks (harder instructions), and text rendering (writing readable words inside images).
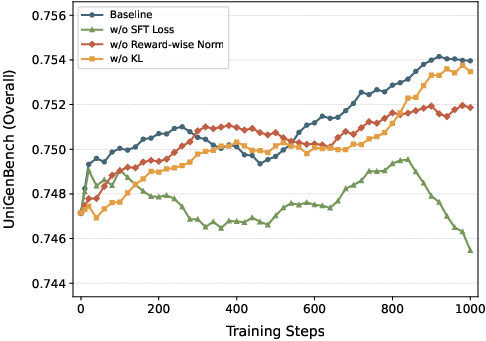
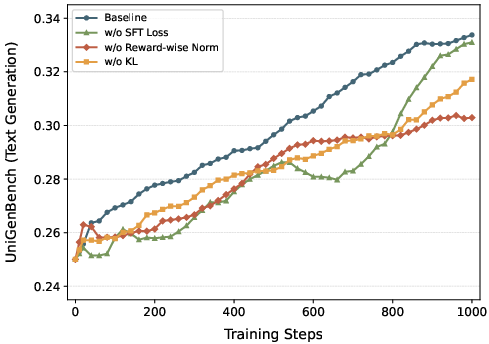
- Stage 3: Reinforcement Learning (RL) with MR-GRPO
- The model generates multiple images per prompt and gets scored by several “reward” signals (for quality, alignment to text, and accurate text in images).
- It then adjusts itself to do better next time, like learning by trial and error.
- To keep the model stable and avoid losing skills, they add:
- A KL penalty (keeps it close to a trusted reference),
- An extra supervised loss (anchors it to the good results learned in SFT),
- Careful reward balancing so one reward (like looks) doesn’t overpower another (like following instructions).
Findings: What did the model achieve and why is it important?
DeepGen 1.0 did extremely well across several tests, even against much larger models:
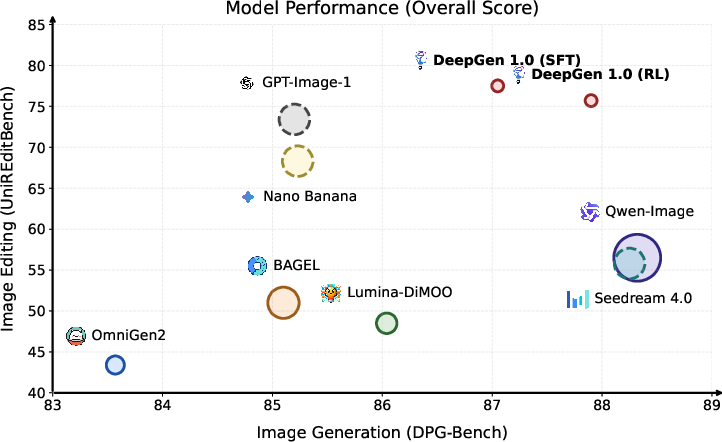
- General instruction following (DPG-Bench): DeepGen scored 87.90, beating bigger systems like HunyuanImage 3.0.
- Reasoning-heavy generation (WISE benchmark): DeepGen reached 0.73, outperforming an 80B model (HunyuanImage 3.0 at 0.57) by about 28%.
- Image editing (UniREditBench): DeepGen scored 77.5, surpassing a 27B specialist model (Qwen-Image-Edit at 56.5) by over 37%.
- Training efficiency: It learned these skills using around 50 million samples, while some competitors needed hundreds of millions to billions.
Why this matters:
- It shows that smart design and training can beat sheer size.
- It proves a single compact model can handle generation, editing, text rendering, and reasoning together.
- It means lower costs and easier deployment for real-world use.
Implications: What could this research change?
DeepGen 1.0 suggests a new path for building strong, practical image tools:
- Affordable and accessible: Small models that still perform great can be trained and run by more teams, not just big tech companies.
- Unified workflows: One model that both understands and creates can simplify apps for artists, designers, educators, and researchers.
- Better controllability: SCB and “think tokens” help the model follow complex instructions more precisely, which is useful for professional design and careful edits.
- Open-source impact: By releasing code, weights, and key datasets, the authors make it easier for others to learn from, improve, and adapt this approach for different needs.
In short, DeepGen 1.0 shows that with the right connections (SCB), thoughtful training, and balanced rewards, smaller models can be smart, skilled, and reliable—pushing image generation and editing forward without the heavy cost of giant systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored in the paper, framed as concrete directions future researchers can act on:
- Resolution and scaling limits: The model is trained and evaluated primarily at 512×512. It is unclear how quality, text fidelity, and reasoning scale to 1024–4096 px, or with tiled/latent upscaling. Evaluate high‑resolution performance and memory/runtime behavior.
- Inference efficiency and deployment: No latency, throughput, or memory figures are reported across GPUs/CPUs. Quantify the real deployment footprint (e.g., tokens per second, VRAM on A10/A100/consumer GPUs) and the overhead introduced by SCB and longer conditioning sequences.
- Missing ablations for SCB: There is no systematic study of SCB design choices. Run controlled ablations on:
- number and selection of VLM layers (e.g., 1/3/6/12; low/mid/high),
- number of think tokens (e.g., 0/32/64/128/256),
- connector depth/width and choice of visual encoder (SigLIP vs CLIP vs EVA),
- channel concatenation vs learned weighted fusion or cross‑attention,
- final/penultimate‑layer only vs multi‑layer fusion.
- Interpretability and function of think tokens: The paper assumes think tokens encode “implicit CoT” but provides no evidence. Probe and visualize attention/activation patterns, test token ablations at inference, and evaluate whether think tokens improve reasoning on controlled testbeds or simply increase capacity.
- RL design clarity and sensitivity: MR-GRPO details (exact reward models, weights, group size G, sampling temperature/schedule) are deferred. Provide:
- explicit reward definitions and datasets used to train reward models,
- sensitivity analyses to reward weights and group size,
- failure modes and “reward hacking” diagnostics,
- comparisons to alternative on-policy/off-policy methods (e.g., DPO, RLHF variants, PPO with different KL schedules).
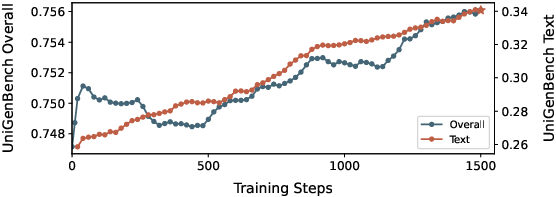
- RL stability and forgetting at scale: The paper notes degradation beyond ~1k RL steps and proposes an auxiliary SFT loss, but long‑horizon stability across diverse tasks is not quantified. Measure task‑wise retention (reasoning, editing, text rendering) over 10k+ steps, varying λ, KL β, and sampling noise.
- Which modules are updated during RL: It is unclear whether RL updates DiT only, DiT+connector, or also VLM (LoRA/full). Disentangle the effects of updating each component and assess understanding drift when the VLM participates in RL.
- Editing interfaces and controllability: The model’s support for masks, bounding boxes, keypoints, or multi-reference conditioning is unspecified. Benchmark localized edits (inpainting/outpainting, region‑specific modifications), control precision, and leakage outside masked regions.
- Text rendering robustness: Beyond aggregate scores, OCR‑based evaluation (accuracy, edit distance) across fonts, sizes, curved text, multi-line layout, and non‑Latin scripts (Chinese, Arabic) is missing. Test multilingual text rendering and robustness to long strings.
- Multilingual instruction following: Training/evaluation appears English‑centric. Assess cross‑lingual prompts (both understanding and generation), code‑switching, and mixed‑script instructions.
- Compositional and adversarial robustness: No tests on long, compositional, ambiguous, or adversarially perturbed prompts (typos, homophones, negations). Construct robustness suites and measure failure modes.
- Out‑of‑distribution generalization: Evaluate performance on domains underrepresented in training (e.g., medical imagery, scientific diagrams, floor plans, niche cultural artifacts) to assess true generalization.
- Human evaluation and statistical significance: Results rely on benchmarks and (likely) automated/LLM‑judge metrics. Include human preference studies with confidence intervals and inter‑rater agreement, and report statistical significance for claimed gains.
- Data transparency and contamination: The in‑house 10M and other mixtures risk overlap with benchmarks (e.g., WISE/CoREBench). Provide de‑duplication/contamination audits, provenance, and licensing status; quantify performance with/without proprietary data.
- Safety, bias, and responsible release: No analysis of demographic biases, harmful content generation, jailbreak resilience, or safety filters. Establish safety evaluations, content moderation strategies, and watermark/provenance mechanisms.
- Training cost and reproducibility: Compute budget (GPU hours, energy), hardware setup, and training time are not reported. Share training logs, seeds, and reproducible recipes; study performance variability across seeds.
- Positional encoding and token mixing in DiT: The paper notes special positional encodings for distinguishing reference vs target tokens but lacks details and ablations. Examine multi‑reference scenarios, token order effects, and leakage between conditioning and target tokens.
- Scalability laws: The paper argues “intelligent design over raw scale” but provides no scaling curves. Study performance vs parameters (e.g., 3B/5B/8B) and data size (~10M/50M/200M) to identify efficient frontiers and diminishing returns.
- Connector architecture choices: The connector uses a SigLIP encoder + 6 transformer layers without justification. Compare to alternatives (e.g., cross‑attentional bridges, FiLM, residual adapters) under equal parameter budgets.
- Aspect ratio handling: Dynamic resizing to 512 may distort content. Quantify faithfulness and artifacts across native aspect ratios and evaluate AR‑preserving training/inference.
- Identity preservation and edit consistency: No metrics for identity consistency in edits (e.g., faces/persons) or consistency across multi‑step edits. Introduce identity scores (face/ID embeddings) and measure drift across editing sequences.
- Multi‑image and multi‑turn workflows: The unified interface suggests potential for multi‑reference or iterative editing, but multi‑turn instruction retention and history‑aware editing are not tested.
- Reward‑model bias and evaluation coupling: Using family‑related evaluators (e.g., Qwen‑based judges) can bias scores. Cross‑validate with independent reward models and human studies to avoid evaluator overfitting.
- Theoretical understanding of SCB: No analysis explains why channel concatenation + shallow fusion should outperform other schemes. Develop probing tasks and theoretical/empirical analyses of information transfer and layer complementarity.
- Extension to video/3D: The approach targets images. Assess how SCB and the DiT backbone would extend to video generation/editing (temporal consistency) or 3D/NeRF‑like outputs, including training data and architectural changes.
- Long‑text and layout grounding: Capabilities for precise layout control (grids, tables, UI mocks) and long‑form prompt adherence are not evaluated; add layout‑grounded benchmarks and constraints (e.g., region‑aware generation).
Glossary
- Alignment Pre-Training: An initial training phase focused on synchronizing representations between modules before full fine-tuning. "Alignment Pre-training on large-scale image-text pairs and editing triplets to synchronize VLM and DiT representations"
- Average Pooling: A feature aggregation method that computes the mean across representations, often reducing detail. "aggregate hidden states from multiple VLM layers using average pooling."
- Auxiliary Supervised Diffusion Loss: An additional supervised loss used during RL to anchor the model to supervised capabilities and prevent degradation. "we introduce an auxiliary supervised diffusion loss"
- Chain-of-Thought (CoT): A reasoning technique that models intermediate steps of thought; here implemented via special tokens. "explicit reasoning tokens can further act as implicit Chains of Thought (CoT)."
- Channel-wise Concatenation: Combining multiple feature tensors by stacking them along the channel dimension before projection/fusion. "These multi-source features are then channel-wise concatenated and fused via a lightweight connector"
- Connector Module: A lightweight alignment network that maps VLM features into the DiT’s input space. "Feature alignment is achieved via a streamlined connector module, which instantiates a SigLIP visual encoder followed by six transformer layers"
- Cross-Modal Alignment: Consistency of representations across modalities (e.g., text and images) to enable effective conditioning. "with well cross-modal alignment"
- Decoupled Advantage Normalization: An RL technique that normalizes advantages per reward to preserve signal granularity in multi-reward settings. "enhancing it with decoupled advantage normalization to better preserve multi-reward granularity."
- Denoising Trajectories: The sequence of intermediate states produced by a diffusion/flow model as it iteratively denoises from noise to image. "the corresponding denoising trajectories {xi_T, xi_{T-1}, \ldots, xi_0}"
- Diffusion Transformer (DiT): A transformer-based generative backbone for diffusion/flow-based image synthesis. "The DiT serves as a high-fidelity generation decoder guided by multimodal conditional inputs extracted from the VLM."
- Editing Triplets: Training samples for image editing that include an input image, an instruction, and a target edited image. "image-text pairs and editing triplets"
- Flow Matching: A training framework for generative models that learns a continuous flow from noise to data using matching objectives. "extends Group Relative Policy Optimization (GRPO) to flow matching models"
- Flow Model: A generative model that transforms noise into data along a learned continuous trajectory. "the flow model samples a group of G images"
- Group Relative Policy Optimization (GRPO): A policy optimization algorithm that compares samples within a group to compute relative advantages. "Group Relative Policy Optimization (GRPO)"
- Importance Ratio: In policy optimization, the ratio between current and reference policy probabilities used for stable updates. "is the per-step importance ratio."
- KL-Divergence Regularization: A penalty that constrains the learned policy to remain close to a reference policy by minimizing KL divergence. "The KL-divergence regularization is computed in velocity space:"
- Latent Space: The compressed representation space where models align or operate on features (e.g., VAE or DiT latents). "align VLM representations with the DiT's latent space"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that inserts low-rank adapters into pretrained models. "we apply LoRA to the VLM for end-to-end optimization."
- MR-GRPO: A multi-reward extension of GRPO that optimizes with a mixture of reward models and supervision signals. "We propose the MR-GRPO framework"
- Multimodal Conditions: Conditioning signals derived from multiple modalities provided to the generator for guided synthesis. "Multimodal conditions derived from the VLM, together with reference-image VAE latents, are concatenated"
- Noise-Preserving Stochastic Sampling: A sampling strategy that maintains noise characteristics to produce cleaner outputs and better rewards during RL. "a noise-preserving stochastic sampling strategy that produces cleaner samples and more accurate reward signals"
- On-Policy Stochastic Sampling: Sampling from the current policy during RL to compute updates based on fresh, on-policy data. "by performing on-policy stochastic sampling and evaluating each generated image"
- Reinforcement Learning (RL): An optimization paradigm that improves a model via reward-driven updates, aligning outputs with preferences. "Finally, we employ Reinforcement Learning (RL) to further align the model with human preferences."
- Self-Attention: A mechanism allowing tokens to attend to each other within a sequence, enabling contextualized representations. "via self-attention"
- Shared Attention: A fusion approach where attention layers are shared across modules (e.g., VLM and DiT) to tightly couple representations. "introducing shared attention between the VLM and DiT at every layer."
- SigLIP Visual Encoder: A vision encoder trained with a sigmoid loss for language-image pretraining, used here in the connector. "instantiates a SigLIP visual encoder"
- Stacked Channel Bridging (SCB): A feature fusion framework that aggregates multi-layer VLM features (plus think tokens) via channel stacking and a connector. "we introduce Stacked Channel Bridging (SCB), a deep alignment framework"
- Supervised Fine-Tuning (SFT): Fine-tuning with labeled data/tasks to improve instruction-following and synthesis quality. "Joint Supervised Fine-tuning (SFT)"
- Text Rendering: The capability to correctly synthesize legible and accurate text within generated images. "simultaneously enhances text rendering fidelity and general generation quality."
- Think Tokens: Learnable tokens injected into the VLM input to encourage implicit reasoning and structured guidance. "we inject learnable ``think tokens'' that act as an implicit chain of thoughts."
- Transformer-Encoder-Based Connector: A connector architecture using transformer encoder layers to fuse and project conditioning features. "fed into a Transformer-encoder-based connector to deeply fuse information across layers"
- VAE Latents: Compressed latent representations produced by a variational autoencoder used as conditioning or generative inputs. "reference-image VAE latents"
- Velocity Space: The parameterization domain (v-space) in diffusion/flow models where losses or regularizers (e.g., KL) are computed. "computed in velocity space:"
- ViT Encoder: A Vision Transformer-based encoder that extracts high-level semantics from images. "a ViT encoder captures high-level semantics for the VLM"
- Vision-LLM (VLM): A model jointly processing visual and textual inputs for multimodal understanding and reasoning. "vision-LLMs (VLMs)"
- VLM-DiT Paradigm: A unified architecture coupling a VLM for understanding with a DiT for generation within one pipeline. "adopts a unified VLM-DiT paradigm"
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage DeepGen 1.0’s unified generation–editing, reasoning-aware guidance (via SCB and “think tokens”), text rendering, and lightweight footprint.
- Advertising, Media, and Design: Prompt-driven campaign visuals and precise edits (layout changes, brand colors, legal disclaimers) — Generate and iteratively edit ad creatives, social posts, and OOH mockups that follow complex instructions (“move logo to upper-left, add bilingual disclaimer, keep ISO-blue background”). Tools/Workflows: Adobe/Figma plug-in, “DeepGen Studio” web app, DAM-integrated API for batch creative variants. Assumptions/Dependencies: brand-style prompts must be explicit; human QA for compliance; font licensing; GPU for near-real-time inference (single 16–24 GB VRAM GPU is typically sufficient).
- E-commerce and Retail: Scalable product image generation/editing with reasoning-guided consistency — Produce colorways, backgrounds, shadows, and label updates across catalogs; enforce uniform lighting and angles (“match hero image lighting across all variants”). Tools/Workflows: PIM/DAM pipeline integration; Shopify/BigCommerce apps; batch microservices. Assumptions/Dependencies: accurate product metadata; approved fonts/assets; guardrails to prevent misleading visuals; prompt templates aligned to brand rules.
- Localization and Packaging: Multilingual text-on-image rendering for signage, packaging, and UI screenshots — Place translated copy on images with correct positioning and hierarchy (“Arabic title top-right, English subtitle below”). Tools/Workflows: Localization pipeline combining LLM translation + DeepGen rendering; automated font selection. Assumptions/Dependencies: script shaping support (Arabic, Indic, CJK); font availability and licensing; human review for linguistic correctness; right-to-left layout handling.
- Photo Editing and Consumer Apps: Object removal/replacement, background edits, and style transfer from natural language — “Remove the person behind the subject, keep reflections consistent.” Tools/Workflows: desktop/mobile editing plug-ins; chat-based assistant; on-prem kiosk software. Assumptions/Dependencies: content safety filters; user controls for reversible edits; device compute (cloud or high-end local GPU).
- Education (K–12 and Higher Ed): Curriculum-aligned visualizations and annotated diagrams from prompts — Generate step-by-step diagrams for physics/biology, historical reconstructions, or labeled scenes with reasoning (“show light refraction at three indices; annotate rays”). Tools/Workflows: LMS plug-in; teacher-facing lesson visualizer; worksheet generator. Assumptions/Dependencies: fact-checking and pedagogy review; age-appropriate content filters; licensed illustrations templates.
- Software and Platforms: Cost-efficient image generation/editing API for developers — Offer unified endpoints for T2I, editing, and text rendering with strong instruction following. Tools/Workflows: containerized microservice; serverless jobs; CI/CD with safety and logging; prompt libraries. Assumptions/Dependencies: cloud GPU availability; rate limiting; watermarking options for provenance; usage monitoring for abuse.
- Synthetic Data for Computer Vision: Rare-case augmentation and domain shifts with precise constraints — Create controlled variations (“low-light, occlusions, partial labels”) to improve model robustness. Tools/Workflows: synthetic generator + labeling harness; evaluation with domain-gap metrics. Assumptions/Dependencies: photorealism sufficient for target tasks; careful prompt design to avoid artifacts; distribution matching to downstream domains.
- Journalism and Policy Comms (On-Prem): Secure, private visual generation/editing for sensitive topics — On-prem deployments reduce data exposure while enabling compliant visuals (e.g., anonymized scenes, policy explainers). Tools/Workflows: enterprise deployment with access controls; compliance audit logs; templated “safe prompt” library. Assumptions/Dependencies: organizational guardrails; watermarking for transparency; editorial review.
- Academic Research: Reproducible baseline for unified multimodal generation — SCB, MR-GRPO, and the data-centric three-stage pipeline are ready to replicate and extend; benchmarks show strong reasoning performance. Tools/Workflows: training scripts, open weights/datasets, ablation suites. Assumptions/Dependencies: compute for SFT/RL; dataset licensing adherence; consistent evaluation with WISE/CoREBench/DPG-Bench.
- Accessibility and Inclusive Design: High-contrast, readable visual assets and alt-version images — Generate accessible variants (contrast-safe palettes, larger text overlays) via clear instructions. Tools/Workflows: design-system assistant; WCAG-aware prompt templates. Assumptions/Dependencies: accessibility audits; font scaling and legibility checks; designer oversight.
Long-Term Applications
These applications will benefit from further research, scaling, or engineering to reach production-grade robustness and breadth.
- Edge/Mobile Inference: On-device unified image generation/editing — Quantization, distillation, and memory-optimized connectors could enable real-time mobile use. Tools/Workflows: Edge SDK; hardware-aware inference; mixed-precision kernels. Assumptions/Dependencies: aggressive model compression; battery and thermal constraints; on-device safety filters.
- Video Generation and Editing: Extending SCB and unified conditioning to spatiotemporal diffusion — Reasoning-aware text overlays, consistent edits across frames, and instruction-driven shot changes. Tools/Workflows: video diffusion training; temporal consistency rewards; NLE plug-ins. Assumptions/Dependencies: large video datasets; compute-intensive training; motion/text coherence metrics.
- Compliance-Aware Generative Workflows: Embedded policy, watermarking, and rights management — Combine preference-aligned RL with policy constraints (brand rules, legal copy). Tools/Workflows: policy engines; provenance watermarks; audit dashboards. Assumptions/Dependencies: robust safety classifiers; standardized watermark tech; governance processes.
- Robotics and Autonomy Simulation: Physics-aware synthetic scenes for perception and planning — Generate diverse environments with reasoning-aligned constraints (“low-friction floor, partial occlusion of tools”). Tools/Workflows: sim integration (ROS/Gazebo/Unreal); procedural scene generator; domain adaptation loops. Assumptions/Dependencies: physics fidelity; sim-to-real transfer; cross-sensor realism.
- Domain-Specific Fine-Tuning (Healthcare, AEC, Manufacturing): Specialized visual generation and edits under strict constraints — E.g., procedural diagrams, safety signage, and assembly instructions. Tools/Workflows: vertical datasets; expert-in-the-loop QA; constrained prompting. Assumptions/Dependencies: rigorous data curation; regulatory compliance; clear separation from clinical-image generation unless vetted.
- Co-Creative Multi-Agent Studios: Planning + rendering agents with iterative reasoning — Chain-of-thought “think tokens” plus tool-use to break down multi-step creative briefs (moodboards → drafts → polish). Tools/Workflows: orchestration layer; versioning; human-in-the-loop approvals. Assumptions/Dependencies: reliable multi-turn memory; prompt decomposition quality; safety checks.
- Multilingual Typography at Scale: Advanced script shaping and typographic correctness — Accurate kerning, ligatures, and layout across complex writing systems. Tools/Workflows: font engines; script-specific validators; localization QA. Assumptions/Dependencies: comprehensive font libraries; typographic rules; culturally sensitive review.
- 3D and CAD Asset Generation: Cross-modal extension from images/text to 3D shapes and scene layouts — SCB-like feature fusion for 3D diffusion/NeRF pipelines. Tools/Workflows: CAD plug-ins; mesh/texture validators; physics-aware scene assembly. Assumptions/Dependencies: large 3D datasets; geometry correctness; downstream toolchain integration.
- Curriculum-Aware Visual Tutoring: Adaptive visual explanations with external verifiers — Combine reasoning generation with fact-checkers for reliable instructional visuals. Tools/Workflows: verifier APIs; curriculum mapping; educator feedback loops. Assumptions/Dependencies: knowledge-grounding; correctness metrics; progressive disclosure for students.
- Green AI Policy and Procurement: Energy-efficient generative systems as a standard — Codify smaller, high-performing unified models in procurement criteria; report compute and energy use. Tools/Workflows: energy dashboards; standardized benchmarking (WISE/CoREBench); policy templates. Assumptions/Dependencies: agreed measurement standards; stakeholder buy-in; vendor transparency.
- Content Authenticity and Misuse Mitigation: Robust provenance and detection ecosystem — Pair generation with detection and reporting tools to curb deepfakes. Tools/Workflows: provenance metadata; classifier ensembles; incident response playbooks. Assumptions/Dependencies: interoperable standards; legal frameworks; community oversight.
Collections
Sign up for free to add this paper to one or more collections.

